Efficient Traffic Forecasting on Large-Scale Road Network by Regularized Adaptive Graph Convolution
Pith reviewed 2026-05-19 11:05 UTC · model grok-4.3
The pith
A cosine-similarity operator on learned embeddings lets graph models forecast traffic on large road networks in linear time while keeping high accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
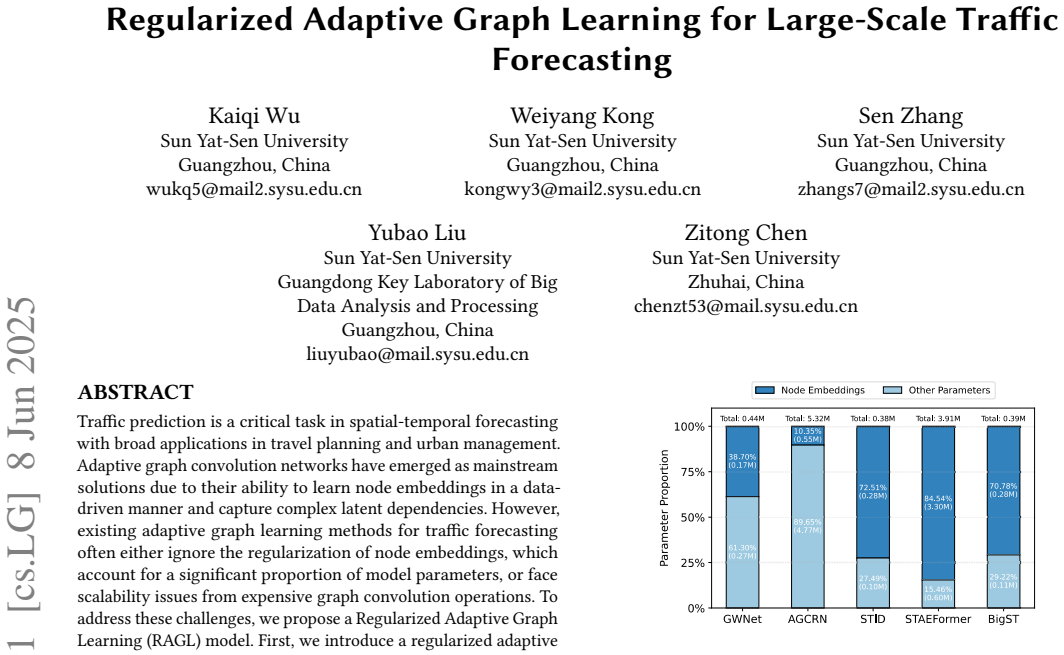
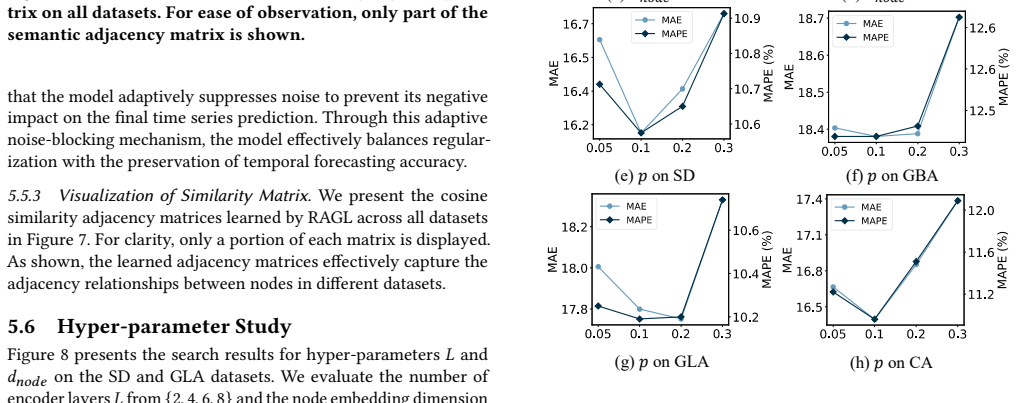
The Regularized Adaptive Graph Convolution (RAGC) model uses an Efficient Cosine Operator (ECO) to perform graph convolution via cosine similarity of node embeddings at linear complexity, integrated with Stochastic Shared Embedding and a residual adaptive convolution mechanism to produce high-quality embeddings that support accurate spatial-temporal traffic forecasts on large-scale networks.
What carries the argument
The Efficient Cosine Operator (ECO), which substitutes traditional quadratic graph convolution with a linear-time computation of cosine similarities between learned node embeddings.
If this is right
- Traffic forecasting becomes feasible on road networks several times larger than those handled by previous STGCN variants.
- The regularization components allow embedding quality to improve without increasing the asymptotic cost of each layer.
- Competitive run times support repeated forecasting cycles needed for dynamic routing or signal control.
- Outperformance holds across multiple real datasets, indicating the design is not tied to one city's traffic pattern.
Where Pith is reading between the lines
- The same linear operator could be tested on other large spatial graphs such as power grids or sensor networks for similar efficiency gains.
- If embedding similarities prove stable, the approach may reduce reliance on manual spatial partitioning in future graph forecasting work.
- Extending the residual mechanism to longer temporal horizons could address multi-step prediction without extra quadratic terms.
Load-bearing premise
Cosine similarity among the learned node embeddings captures the essential spatial dependencies in traffic data closely enough that the approximation does not meaningfully reduce prediction quality.
What would settle it
Run both the proposed operator and a standard full graph convolution on a network small enough for the full version to finish, then compare their mean absolute errors to see whether the accuracy gap exceeds random variation.
Figures






read the original abstract
Traffic prediction is a critical task in spatial-temporal forecasting with broad applications in travel planning and urban management. To model the complex spatial-temporal dependencies in traffic data, Spatial-Temporal Graph Convolutional Networks (STGCNs) have been widely employed, achieving advanced performance. However, when applied to large-scale road networks, the quadratic computational complexity of traditional graph convolution operations severely limits their scalability. Several methods attempt to address this issue through approximation, compression, or spatial partitioning. Nevertheless, these methods often either fail to achieve sufficient computational efficiency or compromise prediction accuracy. To address these challenges, we propose a Regularized Adaptive Graph Convolution (RAGC) model. First, to ensure scalability on large road networks, we develop the Efficient Cosine Operator (ECO), which performs graph convolution based on the cosine similarity of node embeddings with linear time complexity. Second, we introduce a regularized adaptive graph convolution framework that combines Stochastic Shared Embedding (SSE) and adaptive graph convolution through a residual difference mechanism. This design enables the model to learn high-quality node embeddings, thereby improving prediction accuracy while maintaining computational efficiency. Extensive experiments on four large-scale real-world traffic datasets show that RAGC consistently outperforms state-of-the-art methods in terms of prediction accuracy and exhibits competitive computational efficiency. The code is available at: https://github.com/wkq-wukaiqi/RAGC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Regularized Adaptive Graph Convolution (RAGC) model for traffic forecasting on large-scale road networks. It develops the Efficient Cosine Operator (ECO) to perform graph convolution via cosine similarity of learned node embeddings in linear time, and introduces a regularized adaptive framework that integrates Stochastic Shared Embedding (SSE) with adaptive graph convolution through a residual difference mechanism. This is claimed to improve embedding quality and prediction accuracy while ensuring scalability. Extensive experiments on four large-scale real-world traffic datasets reportedly show consistent outperformance over state-of-the-art methods in accuracy with competitive computational efficiency.
Significance. If the central claims hold, the work could meaningfully advance scalable spatial-temporal forecasting by replacing quadratic graph convolutions with an efficient cosine-based operator, enabling applications on very large road networks. The regularization via SSE and residual mechanism offers a practical way to learn adaptive structures from data, and code availability aids reproducibility. The multi-dataset evaluation strengthens the empirical case, though significance hinges on confirming that the linear approximation preserves sufficient long-range dependencies without hidden costs to accuracy.
major comments (3)
- [§3.2] §3.2 (ECO definition and complexity): The claim of linear time complexity for the Efficient Cosine Operator relies on cosine similarity of node embeddings, but the manuscript provides no derivation, pseudocode, or analysis showing how quadratic pairwise computation is avoided (e.g., via low-rank factorization or sampling). This is load-bearing for the scalability claim, as any unverified approximation risks discarding heterogeneous or long-range traffic dependencies.
- [Experiments] Experiments section (results tables): The reported outperformance on four datasets lacks error bars, standard deviations across runs, or statistical significance tests. Without these, the consistency of gains over STGCN baselines cannot be rigorously assessed and may not survive variability in training.
- [§3.3] §3.3 (residual difference mechanism): The residual difference mechanism is introduced to combine SSE and adaptive convolution, yet no ablation isolates its effect and no derivation shows it restores information potentially lost in the cosine approximation. This leaves the circularity concern (embeddings learned from the same traffic data used for prediction) unaddressed.
minor comments (2)
- [Abstract] Abstract: The statement of 'linear time complexity' would benefit from explicit big-O notation and a direct comparison to the quadratic cost of standard graph convolution.
- [Notation] Notation throughout: Define the node embedding matrix and the exact form of the cosine operator with numbered equations to clarify how the adaptive adjacency is constructed from embeddings.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We have carefully considered each major comment and provide detailed responses below. We will incorporate clarifications, additional analyses, and experimental improvements in the revised manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (ECO definition and complexity): The claim of linear time complexity for the Efficient Cosine Operator relies on cosine similarity of node embeddings, but the manuscript provides no derivation, pseudocode, or analysis showing how quadratic pairwise computation is avoided (e.g., via low-rank factorization or sampling). This is load-bearing for the scalability claim, as any unverified approximation risks discarding heterogeneous or long-range traffic dependencies.
Authors: We appreciate this observation on the need for explicit justification. The Efficient Cosine Operator first projects nodes into a low-dimensional embedding space and then computes normalized dot products via vectorized operations that avoid materializing a full N×N similarity matrix, achieving O(Nd) complexity where d is the embedding dimension. We acknowledge that the current manuscript lacks a formal derivation and pseudocode. In the revision we will add both to §3.2, together with a brief discussion of how the learned embeddings retain sufficient long-range spatial structure for traffic forecasting. revision: yes
-
Referee: [Experiments] Experiments section (results tables): The reported outperformance on four datasets lacks error bars, standard deviations across runs, or statistical significance tests. Without these, the consistency of gains over STGCN baselines cannot be rigorously assessed and may not survive variability in training.
Authors: We agree that reporting variability and statistical significance is essential for rigorous evaluation. We will rerun all experiments with multiple random seeds (at least five), report mean performance together with standard deviations, and include paired t-tests or Wilcoxon tests against the strongest baselines in the revised results tables and text. revision: yes
-
Referee: [§3.3] §3.3 (residual difference mechanism): The residual difference mechanism is introduced to combine SSE and adaptive convolution, yet no ablation isolates its effect and no derivation shows it restores information potentially lost in the cosine approximation. This leaves the circularity concern (embeddings learned from the same traffic data used for prediction) unaddressed.
Authors: We thank the referee for pointing out these gaps. We will add an ablation study that isolates the residual difference mechanism and quantify its contribution to accuracy. We will also include a short derivation in §3.3 explaining how the residual term compensates for information that may be attenuated by the cosine operator. On the circularity issue, the embeddings are learned end-to-end, yet the combination of SSE regularization and the residual connection is explicitly designed to encourage embeddings that generalize beyond the immediate prediction objective; we will clarify this design rationale in the revised section. revision: yes
Circularity Check
Node embeddings learned from target traffic data used to define cosine-based graph convolution
specific steps
-
fitted input called prediction
[Abstract (model description)]
"we develop the Efficient Cosine Operator (ECO), which performs graph convolution based on the cosine similarity of node embeddings with linear time complexity. [...] we introduce a regularized adaptive graph convolution framework that combines Stochastic Shared Embedding (SSE) and adaptive graph convolution through a residual difference mechanism. This design enables the model to learn high-quality node embeddings, thereby improving prediction accuracy while maintaining computational efficiency."
Node embeddings are optimized directly on the traffic forecasting objective; cosine similarity derived from those embeddings then defines the linear operator used for the same forecasting task. The reported accuracy improvement is therefore partly achieved by construction through fitting the embeddings to the target data rather than through an independent structural derivation.
full rationale
The paper's core efficiency claim rests on the ECO operator that computes graph convolution via cosine similarity of node embeddings. These embeddings are learned jointly from the same traffic datasets used for the downstream prediction task. While experiments on four real-world datasets provide external validation of accuracy gains, the design does not include a parameter-free derivation or external benchmark showing that the cosine operator preserves spatial-temporal structure independently of the fitted embeddings. This matches the fitted-input-called-prediction pattern at a moderate level without fully reducing the entire result to a tautology.
Axiom & Free-Parameter Ledger
free parameters (2)
- regularization weight
- embedding dimension
axioms (1)
- domain assumption Cosine similarity between node embeddings can substitute for standard graph convolution while preserving necessary spatial dependencies.
invented entities (2)
-
Efficient Cosine Operator (ECO)
no independent evidence
-
Residual difference mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce ECO, a linear-complexity graph convolution operator that leverages cosine similarity... S = Ê_g Ê_g^T ... A_adp = D^{-1} S ... rewritten as D^{-1} (Ê_g (Ê_g^T H))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
regularized adaptive graph learning framework that synergizes Stochastic Shared Embedding (SSE) and adaptive graph convolution via a residual difference mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mahdi Abavisani, Liwei Wu, Shengli Hu, Joel Tetreault, and Alejandro Jaimes
-
[2]
Multimodal Categorization of Crisis Events in Social Media. In CVPR
-
[3]
Lei Bai, Lina Yao, Can Li, Xianzhi Wang, and Can Wang. 2020. Adaptive graph convolutional recurrent network for traffic forecasting. In NeurIPS
work page 2020
-
[4]
Zhanxing Zhu Bing Yu, Haoteng Yin. 2018. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. In IJCAI
work page 2018
-
[5]
Yunyao Cheng, Peng Chen, Chenjuan Guo, Kai Zhao, Qingsong Wen, Bin Yang, and Christian S Jensen. 2023. Weakly Guided Adaptation for Robust Time Series Forecasting. In VLDB
work page 2023
-
[6]
Jeongwhan Choi, Hwangyong Choi, Jeehyun Hwang, and Noseong Park. 2022. Graph Neural Controlled Differential Equations for Traffic Forecasting. InAAAI
work page 2022
-
[7]
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. 2021. Rethinking Attention with Performers. In ICLR
work page 2021
-
[8]
Zheng Dong, Renhe Jiang, Haotian Gao, Hangchen Liu, Jinliang Deng, Qingsong Wen, and Xuan Song. 2024. Heterogeneity-informed meta-parameter learning for spatiotemporal time series forecasting. In SIGKDD
work page 2024
-
[9]
Harris Drucker, Christopher J Burges, Linda Kaufman, Alex Smola, and Vladimir Vapnik. 1996. Support Vector Regression Machines. In NeurIPS
work page 1996
-
[10]
Wenying Duan, Xiaoxi He, Zimu Zhou, Lothar Thiele, and Hong Rao. 2023. Localised Adaptive Spatial-Temporal Graph Neural Network. In SIGKDD
work page 2023
-
[11]
Yuchen Fang, Yuxuan Liang, Bo Hui, Zezhi Shao, Liwei Deng, Xu Liu, Xinke Jiang, and Kai Zheng. 2025. Efficient Large-Scale Traffic Forecasting with Transformers: A Spatial Data Management Perspective. In SIGKDD. 12
work page 2025
-
[12]
Yuchen Fang, Yanjun Qin, Haiyong Luo, Fang Zhao, Bingbing Xu, Liang Zeng, and Chenxing Wang. 2023. When Spatio-Temporal Meet Wavelets: Disentangled Traffic Forecasting via Efficient Spectral Graph Attention Networks. In ICDE
work page 2023
-
[13]
Zheng Fang, Qingqing Long, Guojie Song, and Kunqing Xie. 2021. Spatial- Temporal Graph ODE Networks for Traffic Flow Forecasting. In SIGKDD
work page 2021
-
[14]
Kan Guo, Yongli Hu, Yanfeng Sun, Sean Qian, Junbin Gao, and Baocai Yin. 2021. Hierarchical graph convolution network for traffic forecasting. In AAAI
work page 2021
-
[15]
James D Hamilton. 2020. Time Series Analysis. Princeton university press
work page 2020
-
[16]
Jindong Han, Weijia Zhang, Hao Liu, Tao Tao, Naiqiang Tan, and Hui Xiong
-
[17]
BigST: Linear Complexity Spatio-Temporal Graph Neural Network for Traffic Forecasting on Large-Scale Road Networks. In VLDB
-
[18]
Rongzhou Huang, Chuyin Huang, Yubao Liu, Genan Dai, and Weiyang Kong
- [19]
-
[20]
Jiawei Jiang, Chengkai Han, Wayne Xin Zhao, and Jingyuan Wang. 2023. PDFormer: Propagation Delay-Aware Dynamic Long-Range Transformer for Traffic Flow Prediction. In AAAI
work page 2023
-
[21]
Renhe Jiang, Zhaonan Wang, Jiawei Yong, Puneet Jeph, Quanjun Chen, Yasumasa Kobayashi, Xuan Song, Shintaro Fukushima, and Toyotaro Suzumura. 2023. Spatio-Temporal Meta-Graph Learning for Traffic Forecasting. InAAAI
work page 2023
-
[22]
Wenzhao Jiang, Jindong Han, Hao Liu, Tao Tao, Naiqiang Tan, and Hui Xiong
- [23]
-
[24]
Weiyang Kong, Ziyu Guo, and Yubao Liu. 2024. Spatio-Temporal Pivotal Graph Neural Networks for Traffic Flow Forecasting. In AAAI
work page 2024
- [25]
-
[26]
Shiyong Lan, Yitong Ma, Weikang Huang, Wenwu Wang, Hongyu Yang, and Pyang Li. 2022. DSTAGNN: Dynamic Spatial-Temporal Aware Graph Neural Network for Traffic Flow Forecasting. In ICML
work page 2022
-
[27]
Fuxian Li, Jie Feng, Huan Yan, Guangyin Jin, Fan Yang, Funing Sun, Depeng Jin, and Yong Li. 2023. Dynamic Graph Convolutional Recurrent Network for Traffic Prediction: Benchmark and Solution. ACM Transactions on Knowledge Discovery from Data 17, 1 (2023), 1–21
work page 2023
-
[28]
Mengzhang Li and Zhanxing Zhu. 2021. Spatial-Temporal Fusion Graph Neural Networks for Traffic Flow Forecasting. In AAAI
work page 2021
-
[29]
Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. 2018. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. In ICLR
work page 2018
-
[30]
Hangchen Liu, Zheng Dong, Renhe Jiang, Jiewen Deng, Jinliang Deng, Quanjun Chen, and Xuan Song. 2023. STAEformer: Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting. InCIKM
work page 2023
-
[31]
Xu Liu, Yutong Xia, Yuxuan Liang, Junfeng Hu, Yiwei Wang, Lei Bai, Chao Huang, Zhenguang Liu, Bryan Hooi, and Roger Zimmermann. 2023. Largest: A Benchmark Dataset for Large-Scale Traffic Forecasting. In NeruIPS
work page 2023
-
[32]
Zezhi Shao, Zhao Zhang, Fei Wang, Wei Wei, and Yongjun Xu. 2022. Spatial- Temporal Identity: A Simple Yet Effective Baseline for Multivariate Time Series Forecasting. In CIKM
work page 2022
-
[33]
Zezhi Shao, Zhao Zhang, Wei Wei, Fei Wang, Yongjun Xu, Xin Cao, and Chris- tian S. Jensen. 2022. Decoupled Dynamic Spatial-Temporal Graph Neural Net- work for Traffic Forecasting. In VLDB
work page 2022
-
[34]
David I Shuman, Sunil K Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. 2013. The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains. IEEE signal processing magazine 30, 3 (2013), 83–98
work page 2013
-
[35]
Hongjun Wang, Jiyuan Chen, Tong Pan, Zipei Fan, Xuan Song, Renhe Jiang, Lingyu Zhang, Yi Xie, Zhongyi Wang, and Boyuan Zhang. 2023. Easy Begun Is Half Done: Spatial-Temporal Graph Modeling with ST-Curriculum Dropout. In AAAI
work page 2023
-
[36]
Leye Wang, Di Chai, Xuanzhe Liu, Liyue Chen, and Kai Chen. 2021. Exploring the Generalizability of Spatio-Temporal Traffic Prediction: Meta-Modeling and an Analytic Framework. IEEE Transactions on Knowledge and Data Engineering 35, 4 (2021), 3870–3884
work page 2021
-
[37]
Billy M Williams and Lester A Hoel. 2003. Modeling and Forecasting Vehicular Traffic Flow as a Seasonal ARIMA Process: Theoretical Basis and Empirical Results. Journal of transportation engineering 129, 6 (2003), 664–672
work page 2003
-
[38]
Liwei Wu, Shuqing Li, Cho-Jui Hsieh, and James Sharpnack. 2020. SSE-PT: Sequential Recommendation Via Personalized Transformer. In RecSys
work page 2020
-
[39]
Liwei Wu, Shuqing Li, Cho-Jui Hsieh, and James L Sharpnack. 2019. Stochas- tic Shared Embeddings: Data-driven Regularization of Embedding Layers. In NeurIPS
work page 2019
-
[40]
Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, Xiaojun Chang, and Chengqi Zhang. 2020. Connecting the dots: Multivariate time series forecasting with graph neural networks. In SIGKDD
work page 2020
-
[41]
Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, and Chengqi Zhang. 2019. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. InIJCAI
work page 2019
-
[42]
Chin-Chia Michael Yeh, Yujie Fan, Xin Dai, Uday Singh Saini, Vivian Lai, Prince Osei Aboagye, Junpeng Wang, Huiyuan Chen, Yan Zheng, Zhongfang Zhuang, et al. 2024. RPMixer: Shaking Up Time Series Forecasting with Random Projections for Large Spatial-Temporal Data. In SIGKDD
work page 2024
-
[43]
Xueyan Yin, Genze Wu, Jinze Wei, Yanming Shen, Heng Qi, and Baocai Yin. 2021. Deep learning on Traffic Prediction: Methods, Analysis and Future Directions. IEEE Transactions on Intelligent Transportation Systems 23, 6 (2021), 4927–4943
work page 2021
-
[44]
Hongyuan Yu, Ting Li, Weichen Yu, Jianguo Li, Yan Huang, Liang Wang, and Alex Liu. 2022. Regularized Graph Structure Learning with Semantic Knowledge for Multi-variates Time-Series Forecasting. In IJCAI
work page 2022
-
[45]
Junbo Zhang, Yu Zheng, and Dekang Qi. 2017. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction. In AAAI
work page 2017
-
[46]
Junbo Zhang, Yu Zheng, Dekang Qi, Ruiyuan Li, and Xiuwen Yi. 2016. DNN- Based Prediction Model for Spatio-Temporal Data. In SIGSPATIAL. 13
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.