Pre-trained Large Language Models Learn Hidden Markov Models In-context
Pith reviewed 2026-05-19 10:29 UTC · model grok-4.3
The pith
Pre-trained LLMs infer Hidden Markov Model structure directly from examples in a prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On a diverse set of synthetic HMMs, pre-trained LLMs achieve predictive accuracy approaching the theoretical optimum through in-context learning, and the same method yields competitive results on real-world animal decision-making tasks compared with models built by human experts.
What carries the argument
In-context learning, the process by which the LLM extracts transition and emission probabilities from a small set of example sequences placed inside the prompt.
If this is right
- Researchers can treat LLMs as ready-made sequence predictors for any data suspected to follow Markovian hidden-state dynamics.
- The observed scaling trends with model size and prompt length supply practical rules for choosing how many examples to include when analyzing new sequential datasets.
- ICL performance on HMM tasks offers a new benchmark for measuring how well language models capture latent probabilistic structure.
Where Pith is reading between the lines
- The same prompt-based recovery might extend to other latent-variable models such as linear dynamical systems or partially observable Markov decision processes.
- If the scaling trends hold, increasing context length could substitute for explicit parameter estimation in many scientific time-series problems.
- This capability suggests LLMs could serve as quick first-pass analyzers before committing resources to specialized fitting algorithms.
Load-bearing premise
The provided in-context examples contain enough information for the LLM to recover the underlying transition and emission structure of the HMM without any further training.
What would settle it
Run the same prompt format on a new family of HMMs whose parameters are known exactly, and check whether the LLM's next-token prediction error remains strictly above the Bayes-optimal error computed from the true model.
Figures









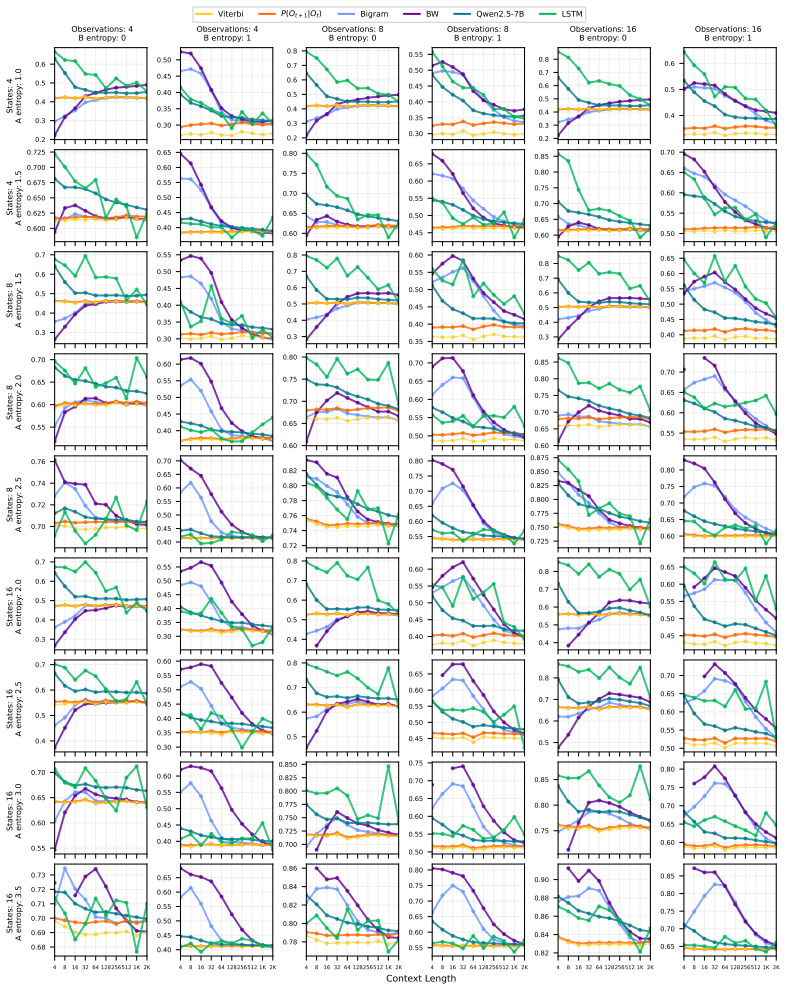

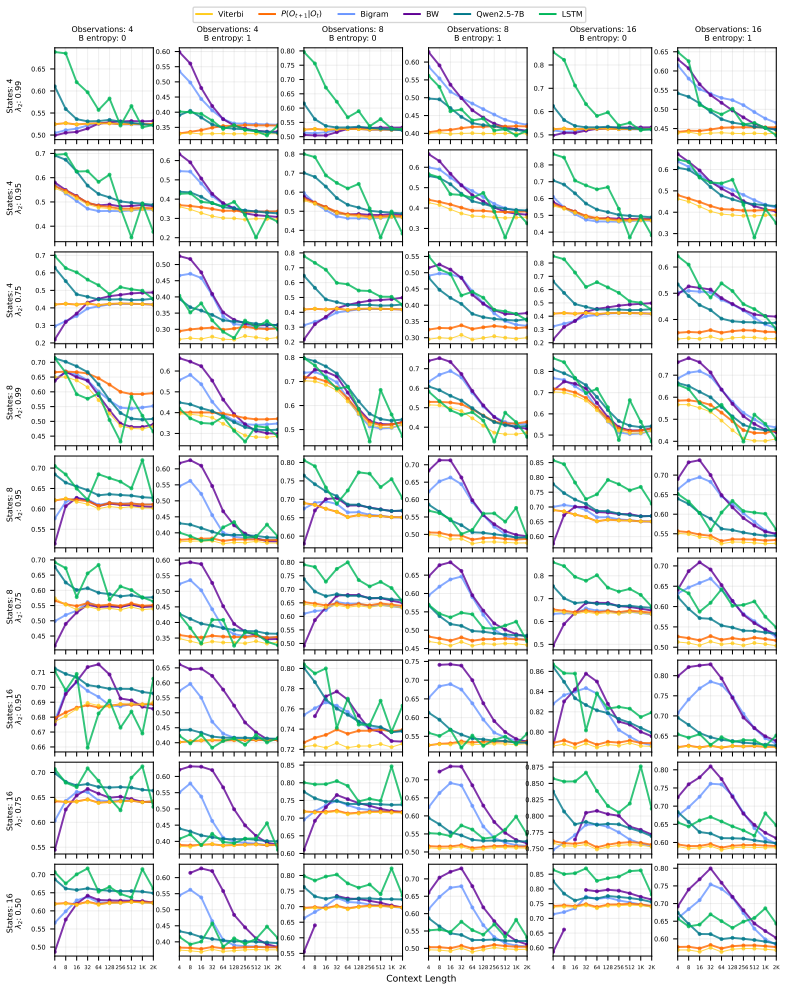


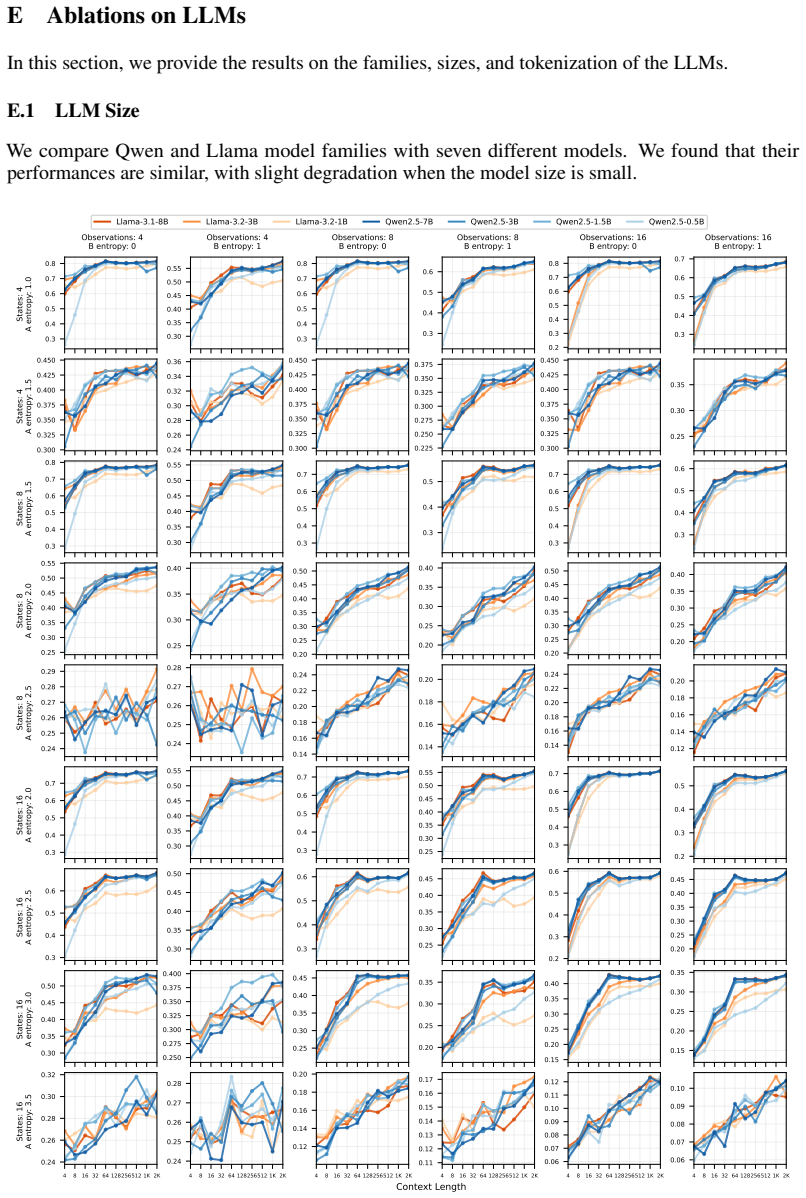



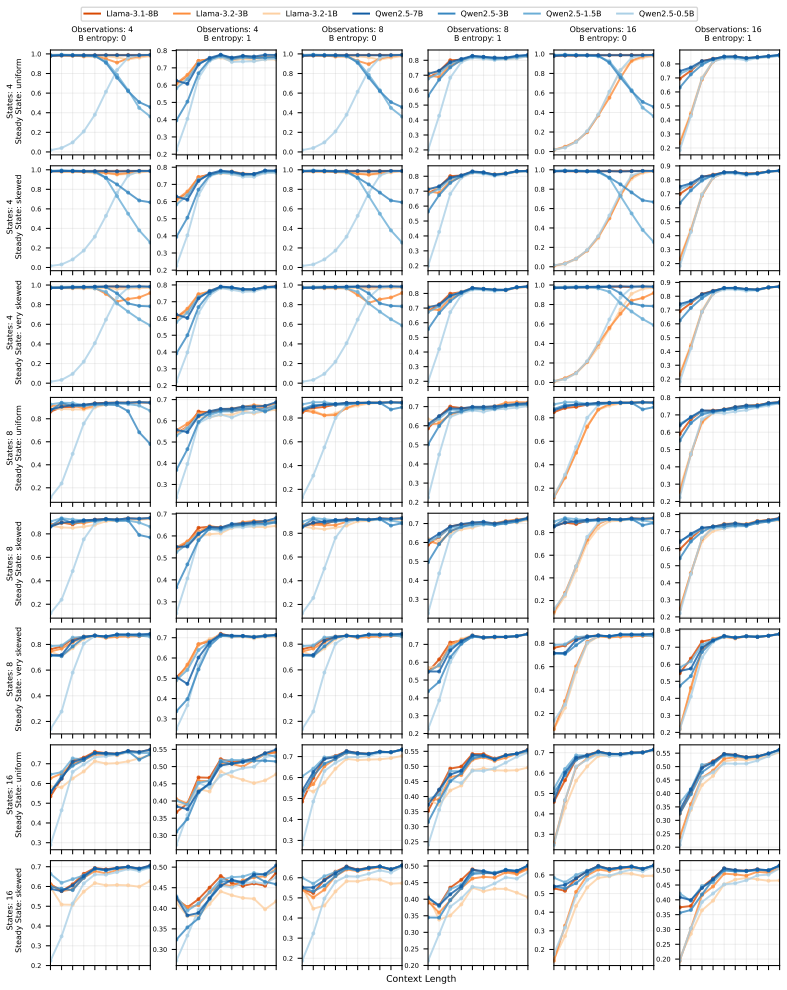



read the original abstract
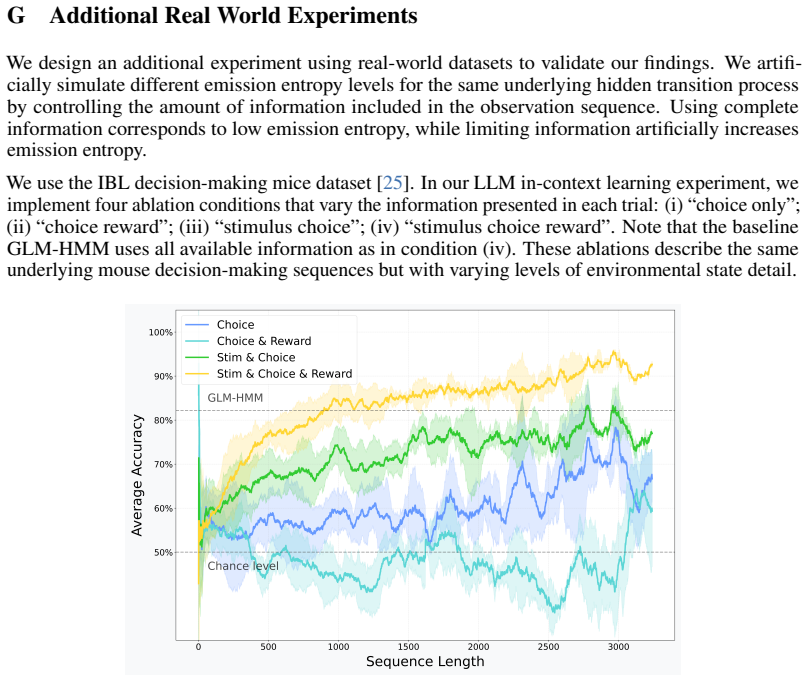
Hidden Markov Models (HMMs) are foundational tools for modeling sequential data with latent Markovian structure, yet fitting them to real-world data remains computationally challenging. In this work, we show that pre-trained large language models (LLMs) can effectively model data generated by HMMs via in-context learning (ICL)$\unicode{x2013}$their ability to infer patterns from examples within a prompt. On a diverse set of synthetic HMMs, LLMs achieve predictive accuracy approaching the theoretical optimum. We uncover novel scaling trends influenced by HMM properties, and offer theoretical conjectures for these empirical observations. We also provide practical guidelines for scientists on using ICL as a diagnostic tool for complex data. On real-world animal decision-making tasks, ICL achieves competitive performance with models designed by human experts. To our knowledge, this is the first demonstration that ICL can learn and predict HMM-generated sequences$\unicode{x2013}$an advance that deepens our understanding of in-context learning in LLMs and establishes its potential as a powerful tool for uncovering hidden structure in complex scientific data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pre-trained large language models (LLMs) can effectively model data generated by Hidden Markov Models (HMMs) via in-context learning (ICL). On a diverse set of synthetic HMMs, LLMs achieve predictive accuracy approaching the theoretical optimum. The work uncovers novel scaling trends influenced by HMM properties, offers theoretical conjectures, provides practical guidelines for using ICL as a diagnostic tool, and demonstrates competitive performance on real-world animal decision-making tasks.
Significance. If the empirical findings are robust and the theoretical optimum is confirmed to be the exact marginal predictive distribution from the ground-truth HMM, this would represent a significant advance in understanding in-context learning. It suggests LLMs can perform implicit Bayesian filtering on latent Markov chains, which has implications for both LLM theory and applications in scientific data analysis. The controlled synthetic experiments and real-world validation are positive aspects. The paper also earns credit for exploring scaling behaviors and providing guidelines.
major comments (2)
- [Experimental Evaluation] The definition of the 'theoretical optimum' requires clarification. The paper should specify in the methods or experimental section whether this is computed as the exact next-token probability using the forward algorithm with the known transition matrix A and emission matrix B on the prompt sequence. If it relies on an approximate method like fitting an HMM to the examples or using a non-marginalized baseline, the claim that LLMs approach the HMM optimum and thus learn the hidden structure does not fully hold. This is central to validating the main result.
- [Theoretical Conjectures] The conjectures for the observed scaling trends (e.g., dependence on number of hidden states or transition entropy) should be stated more precisely, ideally with a supporting derivation or connection to ICL literature, rather than purely empirical observation.
minor comments (2)
- [Abstract] Consider adding a brief mention of the models tested (e.g., specific LLM families) and the range of HMM complexities to give readers a quicker sense of the scope.
- [Figures] Improve clarity of plots showing scaling trends by including error bars from multiple runs and clearly labeling what the 'optimum' line represents.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments and constructive feedback. We address each major comment point by point below, with revisions planned where appropriate.
read point-by-point responses
-
Referee: [Experimental Evaluation] The definition of the 'theoretical optimum' requires clarification. The paper should specify in the methods or experimental section whether this is computed as the exact next-token probability using the forward algorithm with the known transition matrix A and emission matrix B on the prompt sequence. If it relies on an approximate method like fitting an HMM to the examples or using a non-marginalized baseline, the claim that LLMs approach the HMM optimum and thus learn the hidden structure does not fully hold. This is central to validating the main result.
Authors: We thank the referee for highlighting this point. In the experiments, the theoretical optimum is computed exactly as the next-token probability via the forward algorithm using the known transition matrix A and emission matrix B on the full prompt sequence, corresponding to the exact marginal predictive distribution of the ground-truth HMM. We agree that the methods section did not make this explicit enough. We will revise the manuscript to include a precise description of this computation, along with the relevant equations, to confirm it is the exact optimum rather than an approximation. revision: yes
-
Referee: [Theoretical Conjectures] The conjectures for the observed scaling trends (e.g., dependence on number of hidden states or transition entropy) should be stated more precisely, ideally with a supporting derivation or connection to ICL literature, rather than purely empirical observation.
Authors: We appreciate this recommendation. The conjectures in the current manuscript are based on systematic empirical observations across varied HMM parameters. We will revise the relevant section to formulate the conjectures more precisely and to draw explicit connections to existing ICL literature on implicit Bayesian inference and transformer scaling behaviors. A complete theoretical derivation lies outside the scope of this work, but the revision will strengthen the presentation and grounding of these observations. revision: partial
Circularity Check
No circularity: empirical performance claims use independent ground-truth HMM benchmark
full rationale
The paper reports empirical results on synthetic HMM sequences where LLM in-context predictions are compared to the theoretical optimum defined by the known transition and emission matrices via the forward algorithm. No equations, derivations, or fitted parameters are presented that reduce to self-definition or self-citation by construction. Scaling trends and conjectures are offered as post-hoc interpretations of observed performance, not as load-bearing premises. The central claim is externally falsifiable against the ground-truth HMM predictor and does not rely on any self-referential loop or ansatz smuggled through prior work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On a diverse set of synthetic HMMs, LLMs achieve predictive accuracy approaching the theoretical optimum... scaling trends influenced by HMM properties... spectral learning algorithm
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Informal) ... t ≳ 1/(1-λ₂(A)) ... Hellinger distance ≤ ε
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A method of moments for mixture models and hidden markov models
Animashree Anandkumar, Daniel Hsu, and Sham M Kakade. A method of moments for mixture models and hidden markov models. In Conference on learning theory , pages 33–1. JMLR Workshop and Conference Proceedings, 2012
work page 2012
-
[3]
Mice alternate between discrete strategies during perceptual decision-making
Zoe C Ashwood, Nicholas A Roy, Iris R Stone, International Brain Laboratory, Anne E Urai, Anne K Churchland, Alexandre Pouget, and Jonathan W Pillow. Mice alternate between discrete strategies during perceptual decision-making. Nature Neuroscience, 25(2):201–212, 2022
work page 2022
-
[4]
Vector- based navigation using grid-like representations in artificial agents
Andrea Banino, Caswell Barry, Benigno Uria, Charles Blundell, Timothy Lillicrap, Piotr Mirowski, Alexander Pritzel, Martin J Chadwick, Thomas Degris, Joseph Modayil, et al. Vector- based navigation using grid-like representations in artificial agents. Nature, 557(7705):429–433, 2018
work page 2018
-
[5]
Leonard E Baum, Ted Petrie, George Soules, and Norman Weiss. A maximization technique occurring in the statistical analysis of probabilistic functions of markov chains. The annals of mathematical statistics, 41(1):164–171, 1970
work page 1970
-
[6]
Birth of a transformer: A memory viewpoint
Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herve Jegou, and Leon Bottou. Birth of a transformer: A memory viewpoint. Advances in Neural Information Processing Systems, 36: 1560–1588, 2023
work page 2023
-
[7]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[8]
Olivier Cappé, Eric Moulines, and Tobias Rydén.Inference in Hidden Markov Models. Springer Series in Statistics. Springer, New York, NY , 1st edition, 2005. ISBN 978-0-387-40264-2. doi: 10.1007/0-387-28982-8
-
[9]
George Casella and Edward I. George. Explaining the gibbs sampler, 1992
work page 1992
-
[10]
Discovering symbolic cognitive models from human and animal behavior
Pablo Samuel Castro, Nenad Tomasev, Ankit Anand, Navodita Sharma, Rishika Mohanta, Aparna Dev, Kuba Perlin, Siddhant Jain, Kyle Levin, Noémi Éltet ˝o, Will Dabney, Alexan- der Novikov, Glenn C Turner, Maria K Eckstein, Nathaniel D Daw, Kevin J Miller, and Kimberly L Stachenfeld. Discovering symbolic cognitive models from human and animal behavior. bioRxiv...
-
[11]
Stephanie C. Y . Chan, Adam Santoro, Andrew K. Lampinen, Jane X. Wang, Aaditya Singh, Pierre H. Richemond, Jay McClelland, and Felix Hill. Data distributional properties drive emergent in-context learning in transformers, 2022. URL https://arxiv.org/abs/2205. 05055
work page 2022
-
[12]
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory (Wiley Series in Telecom- munications and Signal Processing). Wiley-Interscience, USA, 2006. ISBN 0471241954
work page 2006
-
[13]
Edelman, Ezra Edelman, Surbhi Goel, Eran Malach, and Nikolaos Tsilivis
Benjamin L. Edelman, Ezra Edelman, Surbhi Goel, Eran Malach, and Nikolaos Tsilivis. The evolution of statistical induction heads: In-context learning markov chains, 2024. URL https: //arxiv.org/abs/2402.11004
-
[14]
Y . Ephraim and N. Merhav. Hidden markov processes. IEEE Transactions on Information Theory, 48(6):1518–1569, 2002. doi: 10.1109/TIT.2002.1003838
-
[15]
Robert G Gallager. Discrete stochastic processes. Journal of the Operational Research Society, 48(1):103–103, 1997
work page 1997
-
[16]
Stochastic relaxation, gibbs distributions, and the bayesian restoration of images
Stuart Geman and Donald Geman. Stochastic relaxation, gibbs distributions, and the bayesian restoration of images. IEEE Transactions on pattern analysis and machine intelligence, (6): 721–741, 1984. 11
work page 1984
-
[17]
Hidden markov models: Pitfalls and opportunities in ecology
Richard Glennie, Timo Adam, Vianey Leos-Barajas, Théo Michelot, Theoni Photopoulou, and Brett T McClintock. Hidden markov models: Pitfalls and opportunities in ecology. Methods in Ecology and Evolution, 14(1):43–56, 2023
work page 2023
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Large language models are zero-shot time series forecasters, 2024
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew Gordon Wilson. Large language models are zero-shot time series forecasters, 2024. URL https://arxiv.org/abs/2310.07820
-
[20]
Enough coin flips can make llms act bayesian
Ritwik Gupta, Rodolfo Corona, Jiaxin Ge, Eric Wang, Dan Klein, Trevor Darrell, and David M Chan. Enough coin flips can make llms act bayesian. arXiv preprint arXiv:2503.04722, 2025
-
[21]
A spectral algorithm for learning hidden markov models
Daniel Hsu, Sham M Kakade, and Tong Zhang. A spectral algorithm for learning hidden markov models. Journal of Computer and System Sciences, 78(5):1460–1480, 2012
work page 2012
-
[22]
Yibo Jiang, Goutham Rajendran, Pradeep Ravikumar, and Bryon Aragam. Do llms dream of elephants (when told not to)? latent concept association and associative memory in transformers,
- [23]
-
[24]
Michael I. Jordan. Attractor dynamics and parallelism in a connectionist sequential machine, page 112–127. IEEE Press, 1990. ISBN 0818620153
work page 1990
-
[25]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URL https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[26]
Standardized and reproducible measurement of decision-making in mice
The International Brain Laboratory, Valeria Aguillon-Rodriguez, Dora Angelaki, Hannah Bayer, Niccolo Bonacchi, Matteo Carandini, Fanny Cazettes, Gaelle Chapuis, Anne K Churchland, Yang Dan, Eric Dewitt, Mayo Faulkner, Hamish Forrest, Laura Haetzel, Michael Häusser, Sonja B Hofer, Fei Hu, Anup Khanal, Christopher Krasniak, Ines Laranjeira, Zachary F Mainen...
-
[27]
Markov chains and mixing times , volume 107
David A Levin and Yuval Peres. Markov chains and mixing times , volume 107. American Mathematical Soc., 2017
work page 2017
-
[28]
Trans- formers as algorithms: Generalization and stability in in-context learning
Yingcong Li, Muhammed Emrullah Ildiz, Dimitris Papailiopoulos, and Samet Oymak. Trans- formers as algorithms: Generalization and stability in in-context learning. In International conference on machine learning, pages 19565–19594. PMLR, 2023
work page 2023
-
[29]
Andrew R Liu and Robert R Bitmead. Observability and reconstructibility of hidden markov models: Implications for control and network congestion control. In 49th IEEE Conference on Decision and Control (CDC), pages 918–923. IEEE, 2010
work page 2010
- [30]
- [31]
-
[32]
Xiaoyuan Ma and Jordan Rodu. Bridging the usability gap: Theoretical and methodological advances for spectral learning of hidden markov models. arXiv preprint arXiv:2302.07437, 2023. 12
-
[33]
How hidden are hidden processes? a primer on crypticity and entropy convergence
John R Mahoney, Christopher J Ellison, Ryan G James, and James P Crutchfield. How hidden are hidden processes? a primer on crypticity and entropy convergence. Chaos: An Interdisciplinary Journal of Nonlinear Science, 21(3), 2011
work page 2011
-
[34]
Attention with markov: A framework for principled analysis of transformers via markov chains, 2024
Ashok Vardhan Makkuva, Marco Bondaschi, Adway Girish, Alliot Nagle, Martin Jaggi, Hyeji Kim, and Michael Gastpar. Attention with markov: A framework for principled analysis of transformers via markov chains, 2024. URL https://arxiv.org/abs/2402.04161
-
[35]
Uncovering ecological state dynamics with hidden markov models
Brett T McClintock, Roland Langrock, Olivier Gimenez, Emmanuelle Cam, David L Borchers, Richard Glennie, and Toby A Patterson. Uncovering ecological state dynamics with hidden markov models. Ecology letters, 23(12):1878–1903, 2020
work page 1903
-
[36]
Bernstein inequality and moderate deviations under strong mixing conditions
Florence Merlevède, Magda Peligrad, and Emmanuel Rio. Bernstein inequality and moderate deviations under strong mixing conditions. In High dimensional probability V: the Luminy volume, volume 5, pages 273–293. Institute of Mathematical Statistics, 2009
work page 2009
-
[37]
Kevin J. Miller, Matthew M. Botvinick, and Carlos D. Brody. From predictive models to cognitive models: Separable behavioral processes underlying reward learning in the rat.bioRxiv,
-
[38]
URL https://www.biorxiv.org/content/early/2021/02/ 19/461129
doi: 10.1101/461129. URL https://www.biorxiv.org/content/early/2021/02/ 19/461129
-
[39]
Optimal regularization can mitigate double descent
Preetum Nakkiran, Prayaag Venkat, Sham Kakade, and Tengyu Ma. Optimal regularization can mitigate double descent. arXiv preprint arXiv:2003.01897, 2020
-
[40]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious. arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
A tutorial on hidden markov models and selected applications in speech recognition
Lawrence R Rabiner. A tutorial on hidden markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2):257–286, 1989
work page 1989
-
[42]
Transformers on markov data: Constant depth suffices, 2024
Nived Rajaraman, Marco Bondaschi, Kannan Ramchandran, Michael Gastpar, and Ashok Vard- han Makkuva. Transformers on markov data: Constant depth suffices, 2024. URL https: //arxiv.org/abs/2407.17686
-
[43]
An analysis of tokenization: Trans- formers under markov data
Nived Rajaraman, Jiantao Jiao, and Kannan Ramchandran. An analysis of tokenization: Trans- formers under markov data. Advances in Neural Information Processing Systems, 37:62503– 62556, 2024
work page 2024
-
[44]
Spectral estimation of hidden Markov models
Jordan Rodu. Spectral estimation of hidden Markov models. University of Pennsylvania, 2014
work page 2014
-
[45]
Mice in a labyrinth show rapid learning, sudden insight, and efficient exploration
Matthew Rosenberg, Tony Zhang, Pietro Perona, and Markus Meister. Mice in a labyrinth show rapid learning, sudden insight, and efficient exploration. eLife, 10:e66175, jul 2021. ISSN 2050-084X. doi: 10.7554/eLife.66175. URL https://doi.org/10.7554/eLife.66175
-
[46]
Cristina Segalin, Jalani Williams, Tomomi Karigo, May Hui, Moriel Zelikowsky, Jennifer J Sun, Pietro Perona, David J Anderson, and Ann Kennedy. The mouse action recognition system (mars) software pipeline for automated analysis of social behaviors in mice. eLife, 10:e63720, nov 2021. ISSN 2050-084X. doi: 10.7554/eLife.63720. URL https://doi.org/10.7554/ e...
-
[47]
Improper learning for non-stochastic control
Max Simchowitz, Karan Singh, and Elad Hazan. Improper learning for non-stochastic control. In Conference on Learning Theory, pages 3320–3436. PMLR, 2020
work page 2020
-
[48]
Sun, Ann Kennedy, Eric Zhan, David J
Jennifer J. Sun, Ann Kennedy, Eric Zhan, David J. Anderson, Yisong Yue, and Pietro Perona. Task programming: Learning data efficient behavior representations, 2021. URL https: //arxiv.org/abs/2011.13917
-
[49]
Fitzgerald, and Nelson Spruston
Weinan Sun, Johan Winnubst, Maanasa Natrajan, Chongxi Lai, Koichiro Kajikawa, Michalis Michaelos, Rachel Gattoni, James E. Fitzgerald, and Nelson Spruston. Learning produces a hippocampal cognitive map in the form of an orthogonalized state machine. bioRxiv, 2023. doi: 10.1101/2023.08.03.551900. URL https://www.biorxiv.org/content/early/2023/ 08/07/2023.0...
-
[50]
Facemap: a framework for modeling neural activity based on orofacial tracking
Atika Syeda, Lin Zhong, Renee Tung, Will Long, Marius Pachitariu, and Carsen Stringer. Facemap: a framework for modeling neural activity based on orofacial tracking. Nature neuroscience, 27(1):187–195, 2024
work page 2024
-
[51]
Mingtian Tan, Mike Merrill, Vinayak Gupta, Tim Althoff, and Tom Hartvigsen. Are language models actually useful for time series forecasting? Advances in Neural Information Processing Systems, 37:60162–60191, 2024
work page 2024
-
[52]
Diego Vidaurre, Laurence T Hunt, Andrew J. Quinn, Benjamin A.E. Hunt, Matthew J. Brookes, Anna C. Nobre, and Mark W. Woolrich. Spontaneous cortical activity transiently organises into frequency specific phase-coupling networks. bioRxiv, 2017. doi: 10.1101/150607. URL https://www.biorxiv.org/content/early/2017/10/20/150607
-
[53]
A. Viterbi. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Transactions on Information Theory, 13(2):260–269, 1967. doi: 10.1109/TIT. 1967.1054010
work page doi:10.1109/tit 1967
-
[54]
Xinyi Wang, Wanrong Zhu, Michael Saxon, Mark Steyvers, and William Yang Wang. Large language models are latent variable models: Explaining and finding good demonstrations for in-context learning, 2024. URL https://arxiv.org/abs/2301.11916
-
[55]
Larger language models do in-context learning differently, 2023
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. Larger language models do in-context learning differently, 2023. URL https://arxiv.org/abs/2303.03846
-
[56]
Wills, Colin Lever, Francesca Cacucci, Neil Burgess, and John O’Keefe
Thomas J. Wills, Colin Lever, Francesca Cacucci, Neil Burgess, and John O’Keefe. Attractor dynamics in the hippocampal representation of the local environment. Science, 308:873 – 876,
-
[57]
URL https://api.semanticscholar.org/CorpusID:13909368
-
[58]
An explanation of in- context learning as implicit bayesian inference, 2022
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in- context learning as implicit bayesian inference, 2022. URL https://arxiv.org/abs/2111. 02080
work page 2022
-
[59]
Fanny Yang, Sivaraman Balakrishnan, and Martin J. Wainwright. Statistical and computa- tional guarantees for the baum-welch algorithm, 2015. URL https://arxiv.org/abs/1512. 08269
work page 2015
-
[60]
Walter Zucchini and Peter Guttorp. A hidden markov model for space-time precipitation. Water Resources Research, 27(8):1917–1923, 1991. 14 Appendices Table of Contents • Appendix A: Additional Background on HMMs • Appendix B: Additional Details of Experimental Setup • Appendix C: Details of Benchmark Models • Appendix D: Additional Synthetic Experiment Re...
work page 1917
-
[61]
showed that, with probability at least 1 − δ, we have, ∥ ˆP(⊥) 1 − P1∥ ≲ q log(1/δ) ¯N + q 1 ¯N . In the following, we will upper bound the term ∥ ˆP1 − ˆP(⊥) 1 ∥ by considering entry-wise concentration of each ℓ-th subtrajectory as follows: We have [ ˆP(ℓ) 1 ]i − [ ˆP(⊥) 1 ]i = P ¯N k=1 1{okT −ℓ=i} − 1{o(k) T =i} ¯N . (8) First, we observe that E h 1{okT...
-
[62]
Moreover, |1{okT −ℓ=i} − 1{o(k) T =i}| ≤ 1, almost surely. However, the summation in(8) has weakly dependent terms. Therefore, we use the Bernstein type inequality for a class of weakly dependent and bounded random variables proposed in [35]. Before that, we need to upper bound the variance of the summation in (8). Observing that E h [ ˆP(ℓ) 1 ]i − [ ˆP(⊥...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.