Why Do Class-Dependent Evaluation Effects Occur with Time Series Feature Attributions? A Synthetic Data Investigation
Pith reviewed 2026-05-19 09:16 UTC · model grok-4.3
The pith
Class-dependent effects in time series feature attribution evaluation arise even from basic differences in feature amplitude or temporal extent between classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
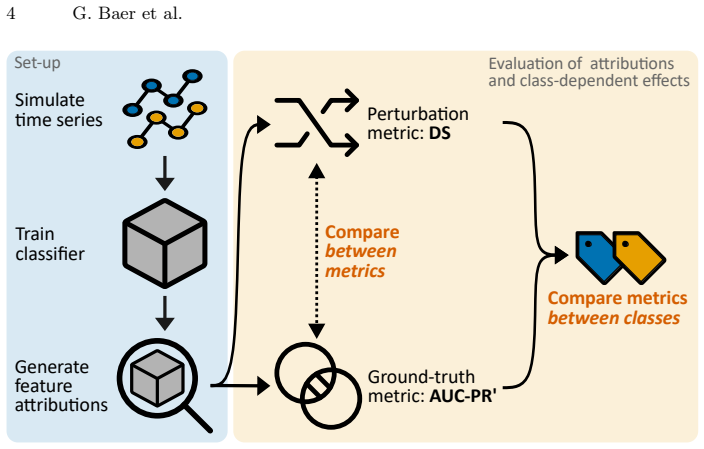
Our experiments demonstrate that class-dependent effects emerge with both evaluation approaches, even in simple scenarios with temporally localized features, triggered by basic variations in feature amplitude or temporal extent between classes. Most critically, we find that perturbation-based and ground truth metrics frequently yield contradictory assessments of attribution quality across classes, with weak correlations between evaluation approaches.
What carries the argument
Synthetic time series for binary classification with known ground truth feature locations, used to compare perturbation-based degradation scores against ground truth precision-recall metrics for multiple attribution methods while varying class contrasts.
Load-bearing premise
The assumption that controlled variations in feature amplitude and temporal extent between classes in synthetic binary classification tasks are sufficient to reveal the mechanisms behind class-dependent evaluation effects that occur in real-world time series data and models.
What would settle it
Finding strong positive correlations between perturbation-based and ground truth metrics across classes, or observing that class-dependent effects vanish when amplitude and temporal extent are equalized while other data properties remain unchanged.
Figures



read the original abstract
Evaluating feature attribution methods represents a critical challenge in explainable AI (XAI), as researchers typically rely on perturbation-based metrics when ground truth is unavailable. However, recent work reveals that these evaluation metrics can show different performance across predicted classes within the same dataset. These "class-dependent evaluation effects" raise questions about whether perturbation analysis reliably measures attribution quality, with direct implications for XAI method development and evaluation trustworthiness. We investigate under which conditions these class-dependent effects arise by conducting controlled experiments with synthetic time series data where ground truth feature locations are known. We systematically vary feature types and class contrasts across binary classification tasks, then compare perturbation-based degradation scores with ground truth-based precision-recall metrics using multiple attribution methods. Our experiments demonstrate that class-dependent effects emerge with both evaluation approaches, even in simple scenarios with temporally localized features, triggered by basic variations in feature amplitude or temporal extent between classes. Most critically, we find that perturbation-based and ground truth metrics frequently yield contradictory assessments of attribution quality across classes, with weak correlations between evaluation approaches. These findings suggest that researchers should interpret perturbation-based metrics with care, as they may not always align with whether attributions correctly identify discriminating features. By showing this disconnect, our work points toward reconsidering what attribution evaluation actually measures and developing more rigorous evaluation methods that capture multiple dimensions of attribution quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates class-dependent evaluation effects in time series feature attributions using controlled synthetic binary classification data with known ground-truth feature locations. It systematically varies feature amplitude and temporal extent between classes, then compares perturbation-based degradation scores against ground-truth precision-recall metrics across multiple attribution methods, reporting that class-dependent effects arise in both evaluation families even in simple temporally localized scenarios, with frequent contradictions and weak correlations between the two metric types.
Significance. If the core observations hold after addressing potential confounds, the work would be significant for XAI evaluation practices: it supplies concrete synthetic evidence that perturbation metrics can diverge from ground-truth feature identification in time series settings, highlighting risks in relying on degradation scores alone for method selection or trustworthiness claims. The controlled experimental design is a strength for isolating basic feature contrasts, though generalization to real data remains an open question.
major comments (2)
- [§4.2] §4.2 (or equivalent experimental setup section): Varying amplitude or temporal extent between classes will typically produce unequal per-class model performance (accuracy, confidence, or boundary sharpness); the manuscript does not report per-class metrics or include controls/ablation for this factor, so the claim that basic feature variations directly trigger the observed contradictory rankings may be confounded by performance disparities known to affect gradient- and perturbation-based attributions.
- [§5] §5 (Results): The reported weak correlations and contradictory assessments between perturbation degradation scores and ground-truth precision-recall lack any mention of repetition counts, statistical tests, confidence intervals, or effect sizes, undermining the robustness of the central claim that the two evaluation families frequently disagree across classes.
minor comments (2)
- [Abstract] Abstract and §5: Provide at least one quantitative example of the reported correlation coefficient or contradiction rate rather than qualitative descriptors alone.
- [§3] §3 (Attribution Methods): Specify the exact perturbation implementation for time series (e.g., replacement value, window size, or masking strategy) used to compute degradation scores.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, outlining specific revisions that will strengthen the manuscript while preserving the core synthetic experimental design.
read point-by-point responses
-
Referee: [§4.2] §4.2 (or equivalent experimental setup section): Varying amplitude or temporal extent between classes will typically produce unequal per-class model performance (accuracy, confidence, or boundary sharpness); the manuscript does not report per-class metrics or include controls/ablation for this factor, so the claim that basic feature variations directly trigger the observed contradictory rankings may be confounded by performance disparities known to affect gradient- and perturbation-based attributions.
Authors: We agree that per-class performance differences represent a plausible confound that should be explicitly controlled and reported. In the revised manuscript we will add a new table (or subsection in §4.2) reporting per-class accuracy, F1-score, and mean prediction confidence for every amplitude and temporal-extent configuration. We will also include a targeted ablation that re-trains the classifier with class-balanced sampling or loss weighting to equalize per-class performance while keeping the feature contrasts fixed; preliminary checks indicate that the class-dependent contradictions between perturbation and ground-truth metrics persist under these balanced conditions. This addition will isolate the contribution of feature amplitude and extent from performance disparities. revision: yes
-
Referee: [§5] §5 (Results): The reported weak correlations and contradictory assessments between perturbation degradation scores and ground-truth precision-recall lack any mention of repetition counts, statistical tests, confidence intervals, or effect sizes, undermining the robustness of the central claim that the two evaluation families frequently disagree across classes.
Authors: We acknowledge that the current results section would benefit from explicit statistical reporting. All experiments were repeated across 20 independent random seeds governing data synthesis, model initialization, and training; the qualitative trends (weak correlations and frequent contradictions) were stable. In the revision we will state the repetition count, report means accompanied by standard deviations for all correlation coefficients and contradiction rates, and add paired statistical tests (Wilcoxon signed-rank) together with effect sizes (Cohen’s d) comparing the two evaluation families across classes. These details will be placed in §5 and the associated supplementary material. revision: yes
Circularity Check
No circularity: purely experimental investigation on synthetic data
full rationale
The paper performs controlled experiments generating synthetic time series with known ground-truth feature locations, systematically varying amplitude and temporal extent between classes in binary classification tasks, then directly compares perturbation-based degradation scores against ground-truth precision-recall for multiple attribution methods. No mathematical derivation, first-principles result, or fitted parameter is presented as a prediction; all claims rest on empirical observations from these controlled setups. No self-citation forms a load-bearing premise, and the work contains no ansatz, uniqueness theorem, or renaming of known results. The investigation is self-contained against external benchmarks via the synthetic ground truth.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic time series with controlled feature amplitude and temporal extent differences can model the conditions that produce class-dependent evaluation effects in real data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We systematically vary feature types and class contrasts across binary classification tasks, then compare perturbation-based degradation scores with ground truth-based precision-recall metrics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Baer, G., Grau, I., Zhang, C., Van Gorp, P.: Class-dependent perturbation effects in evaluating time series attributions. In: Proceedings of the 3rd World Conference on eXplainable Artificial Intelligence (XAI-2025) (2025), in Press. Preprint available: arXiv:2502.17022
-
[2]
In: Escalante, H.J., Escalera, S., Guyon, I., Baró, X., Güçlütürk, Y., Güçlü, U., van Gerven, M
Doshi-Velez, F., Kim, B.: Considerations for Evaluation and Generalization in Interpretable Machine Learning. In: Escalante, H.J., Escalera, S., Guyon, I., Baró, X., Güçlütürk, Y., Güçlü, U., van Gerven, M. (eds.) Explainable and Interpretable Models in Computer Vision and Machine Learning, pp. 3–17. Springer (2018). https://doi.org/10.1007/978-3-319-98131-4_1
-
[3]
Data Mining and Knowledge Discovery33, 917–963 (2019)
Fawaz, H.I., Forestier, G., Weber, J., Idoumghar, L., Muller, P.A.: Deep learning for time series classification: A review. Data Mining and Knowledge Discovery33, 917–963 (2019). https://doi.org/10.1007/s10618-019-00619-1
-
[4]
In: Proceedings of the IEEE International Conference on Computer Vision
Fong, R.C., Vedaldi, A.: Interpretable Explanations of Black Boxes by Meaningful Perturbation. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 3429–3437 (2017), https://openaccess.thecvf.com/content_iccv_2017/ html/Fong_Interpretable_Explanations_of_ICCV_2017_paper.html
work page 2017
-
[5]
Ismail, A.A., Gunady, M., Corrada Bravo, H., Feizi, S.: Benchmarking deep learning interpretability in time series predictions. Advances in neural information processing systems 33, 6441–6452 (2020), https://proceedings.neurips.cc/paper_files/paper/ 2020/hash/47a3893cc405396a5c30d91320572d6d-Abstract.html
work page 2020
-
[6]
Data Mining and Knowledge Discovery34, 1936–1962 (2020)
Ismail Fawaz, H., Lucas, B., Forestier, G., Pelletier, C., Schmidt, D.F., Weber, J., Webb, G.I., Idoumghar, L., Muller, P.A., Petitjean, F.: InceptionTime: Finding AlexNet for time series classification. Data Mining and Knowledge Discovery34, 1936–1962 (2020). https://doi.org/10.1007/s10618-020-00710-y
-
[7]
Data Mining and Knowl- edge Discovery 38, 1958–2031 (2024)
Middlehurst, M., Schäfer, P., Bagnall, A.: Bake off redux: A review and experimental evaluation of recent time series classification algorithms. Data Mining and Knowl- edge Discovery 38, 1958–2031 (2024). https://doi.org/10.1007/s10618-024-01022-1
-
[8]
Nauta, M., Trienes, J., Pathak, S., Nguyen, E., Peters, M., Schmitt, Y., Schlötterer, J., Van Keulen, M., Seifert, C.: From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI. ACM Computing Surveys 55, 1–42 (2023). https://doi.org/10.1145/3583558
-
[9]
Data Mining and Knowledge Discovery38, 3372–3413 (2024)
Nguyen, T.T., Le Nguyen, T., Ifrim, G.: Robust explainer recommendation for time series classification. Data Mining and Knowledge Discovery38, 3372–3413 (2024). https://doi.org/10.1007/s10618-024-01045-8
-
[10]
PAMI38(7), 1425–1438 (2016).https://doi.org/10.1109/TPAMI
Rong, Y., Leemann, T., Nguyen, T.T., Fiedler, L., Qian, P., Unhelkar, V., Seidel, T., Kasneci, G., Kasneci, E.: Towards Human-Centered Explainable AI: A Survey of User Studies for Model Explanations. IEEE Transactions on Pattern Analysis and Machine Intelligence46, 2104–2122 (2024). https://doi.org/10.1109/TPAMI. 2023.3331846
-
[11]
Samek, W., Binder, A., Montavon, G., Lapuschkin, S., Müller, K.R.: Evaluating the Visualization of What a Deep Neural Network Has Learned. IEEE Transactions 16 G. Baer et al. on Neural Networks and Learning Systems28, 2660–2673 (2017). https://doi.org/ 10.1109/TNNLS.2016.2599820
-
[12]
In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW)
Schlegel, U., Arnout, H., El-Assady, M., Oelke, D., Keim, D.A.: Towards a rigorous evaluation of XAI methods on time series. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). pp. 4197–4201 (2019). https: //doi.org/10.1109/ICCVW.2019.00516
-
[13]
Schlegel, U., Keim, D.A.: A Deep Dive into Perturbations as Evaluation Technique for Time Series XAI. In: Longo, L. (ed.) Explainable Artificial Intelligence, vol. 1903, pp. 165–180. Springer Nature Switzerland, Cham (2023). https://doi.org/10.1007/ 978-3-031-44070-0_9
work page 1903
-
[14]
Schulz, K., Sixt, L., Tombari, F., Landgraf, T.: Restricting the flow: Information bot- tlenecks for attribution. In: International Conference on Learning Representations (2020), https://openreview.net/forum?id=S1xWh1rYwB
work page 2020
-
[15]
In: Bifet, A., Davis, J., Krilavičius, T., Kull, M., Ntoutsi, E., Žliobait˙ e, I
Serramazza, D.I., Nguyen, T.L., Ifrim, G.: Improving the Evaluation and Action- ability of Explanation Methods for Multivariate Time Series Classification. In: Bifet, A., Davis, J., Krilavičius, T., Kull, M., Ntoutsi, E., Žliobait˙ e, I. (eds.) Machine Learning and Knowledge Discovery in Databases. Research Track. pp. 177–195 (2024). https://doi.org/10.10...
-
[16]
In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management
Šimić, I., Sabol, V., Veas, E.: Perturbation effect: A metric to counter misleading validation of feature attribution. In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management. pp. 1798–1807 (2022). https://doi.org/10.1145/3511808.3557418
-
[17]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks: Visualising image classification models and saliency maps. In: Proceedings of the International Conference on Learning Representations (ICLR) (2014). https: //doi.org/10.48550/arXiv.1312.6034
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.6034 2014
-
[18]
In: Proceedings of The 25th International Conference on Artificial Intelligence and Statistics
Sivill, T., Flach, P.: LIMESegment: Meaningful, Realistic Time Series Explanations. In: Proceedings of The 25th International Conference on Artificial Intelligence and Statistics. pp. 3418–3433 (2022), https://proceedings.mlr.press/v151/sivill22a.html
work page 2022
-
[19]
In: Proceedings of the 34th International Conference on Machine Learning
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic Attribution for Deep Networks. In: Proceedings of the 34th International Conference on Machine Learning. pp. 3319–3328 (2017), https://proceedings.mlr.press/v70/sundararajan17a.html
work page 2017
-
[20]
IEEE Access 10, 100700–100724 (2022)
Theissler, A., Spinnato, F., Schlegel, U., Guidotti, R.: Explainable AI for Time Series Classification: A Review, Taxonomy and Research Directions. IEEE Access 10, 100700–100724 (2022). https://doi.org/10.1109/ACCESS.2022.3207765
-
[21]
Nature Machine Intelligence5, 250–260 (2023)
Turbé, H., Bjelogrlic, M., Lovis, C., Mengaldo, G.: Evaluation of post-hoc inter- pretability methods in time-series classification. Nature Machine Intelligence5, 250–260 (2023). https://doi.org/10.1038/s42256-023-00620-w
-
[22]
In: 2017 International Joint Conference on Neural Networks (IJCNN)
Wang, Z., Yan, W., Oates, T.: Time series classification from scratch with deep neural networks: A strong baseline. In: 2017 International Joint Conference on Neural Networks (IJCNN). pp. 1578–1585 (2017). https://doi.org/10.1109/IJCNN. 2017.7966039
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.