Taking the GP Out of the Loop
Pith reviewed 2026-05-19 09:02 UTC · model grok-4.3
The pith
Bayesian optimization scales to 50,000 observations by replacing Gaussian-process surrogates with nearest-neighbor uncertainty estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
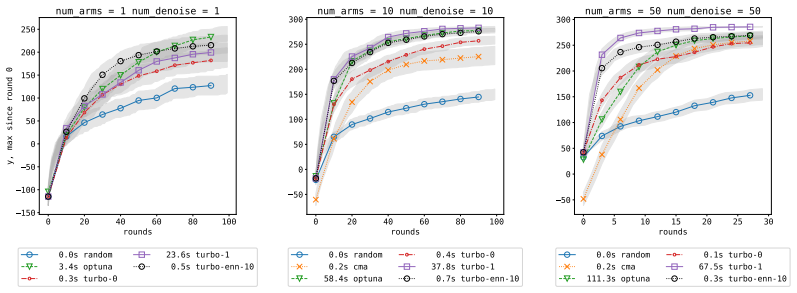
TuRBO-ENN substitutes an Epistemic Nearest Neighbors surrogate for the Gaussian process in TuRBO, estimates function value and uncertainty from K-nearest-neighbor observations, and uses an upper-confidence-bound acquisition function built from those estimates; the resulting method reduces proposal time by one to two orders of magnitude while preserving performance up to 50,000 observations.
What carries the argument
Epistemic Nearest Neighbors (ENN), a surrogate that forms its mean prediction and two uncertainty components by averaging distances and values among the K nearest observed points.
If this is right
- Proposal time (fitting plus acquisition) falls by one to two orders of magnitude relative to TuRBO at large observation counts.
- Noise-free problems allow the fitting step to be dropped entirely by replacing UCB with a non-dominated sort over mean and uncertainty.
- The linear-time surrogate extends the practical reach of TuRBO to regimes where function evaluations are cheap and data accumulate rapidly.
- Upper-confidence-bound acquisition continues to balance exploration and exploitation without cubic-cost matrix operations.
Where Pith is reading between the lines
- Neighbor-based surrogates could be swapped into other Bayesian-optimization frameworks that currently rely on Gaussian processes.
- The same local-averaging idea might be combined with occasional global refits when the data distribution shifts.
- Linear scaling makes online or streaming Bayesian optimization feasible on continuous data feeds.
- Performance on problems where nearest-neighbor distances cease to be informative would reveal the limits of the approach.
Load-bearing premise
K-nearest-neighbor estimates of epistemic and aleatoric uncertainty stay accurate enough to steer the acquisition function on the tested problem classes and observation regimes.
What would settle it
Run TuRBO-ENN and standard TuRBO side-by-side on a high-dimensional multimodal test function and record whether ENN reaches a comparable optimum within the same evaluation budget.
Figures











read the original abstract
Bayesian optimization (BO) has traditionally solved black-box problems where function evaluation is expensive and, therefore, observations are few. Recently, however, there has been growing interest in applying BO to problems where function evaluation is cheaper and observations are more plentiful. In this regime, scaling to many observations $N$ is impeded by Gaussian-process (GP) surrogates: GP hyperparameter fitting scales as $\mathcal{O}(N^3)$ (reduced to roughly $\mathcal{O}(N^2)$ in modern implementations), and it is repeated at every BO iteration. Many methods improve scaling at acquisition time, but hyperparameter fitting still scales poorly, making it the bottleneck. We propose Epistemic Nearest Neighbors (ENN), a lightweight alternative to GPs that estimates function values and uncertainty (epistemic and aleatoric) from $K$-nearest-neighbor observations. ENN scales as $\mathcal{O}(N)$ for both fitting and acquisition. Our BO method, TuRBO-ENN, replaces the GP surrogate in TuRBO with ENN and its Thompson-sampling acquisition with $\mathrm{UCB} = \mu(x) + \sigma(x)$. For the special case of noise-free problems, we can omit fitting altogether by replacing $\mathrm{UCB}$ with a non-dominated sort over $\mu(x)$ and $\sigma(x)$. We show empirically that TuRBO-ENN reduces proposal time (i.e., fitting time + acquisition time) by one to two orders of magnitude compared to TuRBO at up to 50,000 observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Epistemic Nearest Neighbors (ENN), a K-nearest-neighbor surrogate that estimates function values along with epistemic and aleatoric uncertainty, as a drop-in replacement for Gaussian processes inside the TuRBO Bayesian optimization algorithm. ENN is claimed to scale as O(N) for both fitting and acquisition (versus O(N^3) or O(N^2) for GPs), with a special noise-free variant that avoids fitting entirely by using a non-dominated sort over μ and σ. The central empirical claim is that the resulting TuRBO-ENN method reduces proposal time (fitting plus acquisition) by one to two orders of magnitude relative to standard TuRBO for problem sizes up to 50,000 observations.
Significance. If the optimization performance of TuRBO-ENN is shown to be comparable to TuRBO, the work would provide a practical route to scaling Bayesian optimization into the large-N regime where GP hyperparameter fitting becomes the dominant cost. The explicit O(N) complexity statements and the noise-free non-dominated-sort shortcut are concrete strengths that could be cited by practitioners.
major comments (2)
- [Experiments] Experiments section (and associated figures/tables): the manuscript reports wall-clock proposal-time speedups but provides no direct comparison of optimization quality (simple regret, best observed value, or convergence curves) between TuRBO-ENN and TuRBO across the tested functions and observation regimes. Because the headline claim is that ENN remains a viable BO surrogate, the absence of these metrics leaves the load-bearing assumption that KNN-derived epistemic uncertainty guides acquisition effectively untested.
- [ENN definition] Section defining ENN and the UCB acquisition (Eq. for UCB = μ(x) + σ(x)): the epistemic uncertainty estimate is constructed from local K-nearest-neighbor distances/variances. The paper should explicitly address whether this local construction can under-estimate uncertainty in large unsampled regions or on high-dimensional manifolds, and whether any safeguards (e.g., distance-based inflation or fallback to global exploration) are used; without such discussion the claim that acquisition remains effective is unsupported.
minor comments (2)
- [Notation] Notation for aleatoric versus epistemic components should be introduced once and used consistently; currently the distinction is mentioned in the abstract but the precise formulas appear only later.
- [Algorithm] The special-case noise-free algorithm (non-dominated sort) is described briefly; a short pseudocode block or explicit statement of the sort criterion would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects for validating ENN as a practical surrogate. We address each major comment below and outline revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and associated figures/tables): the manuscript reports wall-clock proposal-time speedups but provides no direct comparison of optimization quality (simple regret, best observed value, or convergence curves) between TuRBO-ENN and TuRBO across the tested functions and observation regimes. Because the headline claim is that ENN remains a viable BO surrogate, the absence of these metrics leaves the load-bearing assumption that KNN-derived epistemic uncertainty guides acquisition effectively untested.
Authors: We agree that direct comparisons of optimization performance are necessary to substantiate the claim that ENN serves as a viable drop-in replacement. The original manuscript emphasized computational scaling because that was the primary bottleneck addressed, but we acknowledge this leaves the optimization efficacy untested in the presented results. In the revised manuscript we have added convergence plots and tables reporting best observed values and simple regret for TuRBO-ENN versus standard TuRBO on the benchmark functions, across the same observation regimes up to 50,000 points. These additions confirm that optimization quality remains comparable while proposal times are reduced by one to two orders of magnitude. revision: yes
-
Referee: [ENN definition] Section defining ENN and the UCB acquisition (Eq. for UCB = μ(x) + σ(x)): the epistemic uncertainty estimate is constructed from local K-nearest-neighbor distances/variances. The paper should explicitly address whether this local construction can under-estimate uncertainty in large unsampled regions or on high-dimensional manifolds, and whether any safeguards (e.g., distance-based inflation or fallback to global exploration) are used; without such discussion the claim that acquisition remains effective is unsupported.
Authors: We appreciate the referee drawing attention to the limitations of purely local uncertainty estimates. The local KNN construction can indeed under-estimate epistemic uncertainty far from observed data or in high-dimensional regions where nearest-neighbor distances become less informative. In the revised manuscript we have expanded the ENN definition section with a dedicated paragraph discussing this issue, including a simple distance-based inflation term added to σ(x) when the query point lies beyond a threshold distance from the nearest observation. We also note that TuRBO’s trust-region mechanism provides an implicit safeguard by restricting acquisition to local regions, and we report a brief ablation showing that the inflation term improves exploration without degrading the observed speedups. revision: yes
Circularity Check
No circularity: empirical runtime comparison is independent of any fitted or self-referential construction
full rationale
The paper's central claim is an empirical measurement of proposal-time speedup (fitting + acquisition) for TuRBO-ENN versus TuRBO up to N=50,000. ENN is introduced as an explicit K-nearest-neighbor estimator for μ(x) and σ(x) (epistemic and aleatoric), with O(N) scaling stated directly from the algorithm rather than derived from any quantity fitted inside the reported experiments. No equation or prediction is shown to equal its own inputs by construction, no self-citation chain is load-bearing for the speedup result, and the reported timing numbers are obtained from direct implementation rather than from any tautological renaming or ansatz. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Distance-based weighting or averaging of neighbor values yields a usable estimate of both mean and epistemic uncertainty.
Reference graph
Works this paper leans on
-
[1]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019
work page 2019
-
[2]
Simulation optimization: A review of algorithms and applications
Satyajith Amaran, Nikolaos V . Sahinidis, Bikram Sharda, and Scott J. Bury. Simulation optimization: A review of algorithms and applications. CoRR, abs/1706.08591, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. CoRR, abs/1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
William G. Cochran. The combination of estimates from different experiments. Biometrics, 10(1):101–129, 1954
work page 1954
-
[5]
Multi-objective bayesian optimization over high-dimensional search spaces
Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Multi-objective bayesian optimization over high-dimensional search spaces. CoRR, abs/2109.10964, 2021
-
[6]
George De Ath, Richard M. Everson, Alma A. M. Rahat, and Jonathan E. Fieldsend. Greed is good: Exploration and exploitation trade-offs in bayesian optimisation. ACM Trans. Evol. Learn. Optim., 1(1), April 2021
work page 2021
-
[7]
Gardner, Ryan Turner, and Matthias Poloczek
David Eriksson, Michael Pearce, Jacob R. Gardner, Ryan Turner, and Matthias Poloczek. Scalable global optimization via local bayesian optimization. CoRR, abs/1910.01739, 2019
- [8]
-
[9]
Gardner, Geoff Pleiss, David Bindel, Kilian Q
Jacob R. Gardner, Geoff Pleiss, David Bindel, Kilian Q. Weinberger, and Andrew Gordon Wilson. Gpytorch: blackbox matrix-matrix gaussian process inference with gpu acceleration. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, page 7587–7597, Red Hook, NY , USA, 2018. Curran Associates Inc
work page 2018
-
[10]
The cma evolution strategy: A tutorial, 2023
Nikolaus Hansen. The cma evolution strategy: A tutorial, 2023
work page 2023
-
[11]
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In Carlos A. Coello Coello, editor, Learning and Intelligent Optimization, pages 507–523, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg
work page 2011
-
[12]
Don R. Jones. Mopta08 automotive benchmark problem: Large-scale multi-disciplinary mass optimization in the auto industry. Presentation at the Modeling and Optimization: Theory and Applications (MOPTA) Conference, 2008. Slides and benchmark files available athttps: //www.miguelanjos.com/projects/3009-jones-benchmark, 2008. Accessed 11 May 2025
work page 2008
-
[13]
Asyn- chronous parallel bayesian optimisation via thompson sampling, 2017
Kirthevasan Kandasamy, Akshay Krishnamurthy, Jeff Schneider, and Barnabas Poczos. Asyn- chronous parallel bayesian optimisation via thompson sampling, 2017
work page 2017
-
[14]
Kim, Michael Jordan, Shankar Sastry, and Andrew Ng
H. Kim, Michael Jordan, Shankar Sastry, and Andrew Ng. Autonomous helicopter flight via reinforcement learning. In S. Thrun, L. Saul, and B. Schölkopf, editors, Advances in Neural Information Processing Systems, volume 16. MIT Press, 2003
work page 2003
-
[15]
Bayesian optimization in materials science: A survey
Lars Kotthoff, Hud Wahab, and Patrick Johnson. Bayesian optimization in materials science: A survey. ArXiv, abs/2108.00002, 2021
-
[16]
The evolutionary computation methods no one should use, 2023
Jakub Kudela. The evolutionary computation methods no one should use, 2023. 10
work page 2023
-
[17]
Simple random search of static linear policies is competitive for reinforcement learning
Horia Mania, Aurelia Guy, and Benjamin Recht. Simple random search of static linear policies is competitive for reinforcement learning. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
work page 2018
- [18]
-
[19]
Constant-Time Predictive Distributions for Gaussian Processes
Geoff Pleiss, Jacob R. Gardner, Kilian Q. Weinberger, and Andrew Gordon Wilson. Constant- time predictive distributions for gaussian processes. CoRR, abs/1803.06058, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
A/b testing: A systematic literature review
Federico Quin, Danny Weyns, Matthias Galster, and Camila Costa Silva. A/b testing: A systematic literature review. ArXiv, abs/2308.04929, 2023
-
[21]
Cylindrical Thompson sampling for high-dimensional Bayesian optimization
Bahador Rashidi, Kerrick Johnstonbaugh, and Chao Gao. Cylindrical Thompson sampling for high-dimensional Bayesian optimization. In Sanjoy Dasgupta, Stephan Mandt, and Yingzhen Li, editors, Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 of Proceedings of Machine Learning Research, pages 3502–3510. PML...
work page 2024
-
[22]
Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning. The MIT Press, 2006
work page 2006
-
[23]
Thomas J. Santner, Brian J. Williams, and William I. Notz. The Design and Analysis of Computer Experiments. Springer New York, NY , 2019
work page 2019
-
[24]
Mostofa Ali Patwary, Prabhat Prabhat, and Ryan P
Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md. Mostofa Ali Patwary, Prabhat Prabhat, and Ryan P. Adams. Scalable bayesian optimization using deep neural networks. In Proceedings of the 32nd International Conference on Interna- tional Conference on Machine Learning - Volume 37, ICML’15, page 2171–2180. JMLR.org, 2015
work page 2015
-
[25]
Virtual library of simulation experiments: Optimization test problems
Sonya Surjanovic and Derek Bingham. Virtual library of simulation experiments: Optimization test problems. http://www.sfu.ca/~ssurjano/optimization.html, 2013. Accessed: 2023-10-25
work page 2013
-
[26]
David Sweet. Experimentation for Engineers. Manning, 2023
work page 2023
-
[27]
Bayesian optimization in a billion dimensions via random embeddings, 2016
Ziyu Wang, Frank Hutter, Masrour Zoghi, David Matheson, and Nando de Freitas. Bayesian optimization in a billion dimensions via random embeddings, 2016
work page 2016
-
[28]
Shuhei Watanabe. Tree-structured parzen estimator: Understanding its algorithm components and their roles for better empirical performance, 2023. A Ablations Our acquisition method (Section 4.2) relies on both the ENN mean µ(x) and its uncertainty σ(x). To test whether each component is necessary, we evaluate three ablations of turbo-enn-10: • turbo-enn-m...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.