Beyond Blur: A Fluid Perspective on Generative Diffusion Models
Pith reviewed 2026-05-19 08:10 UTC · model grok-4.3
The pith
Coupling advection from fluid flows with diffusion generalizes corruption processes in generative image models and improves output diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
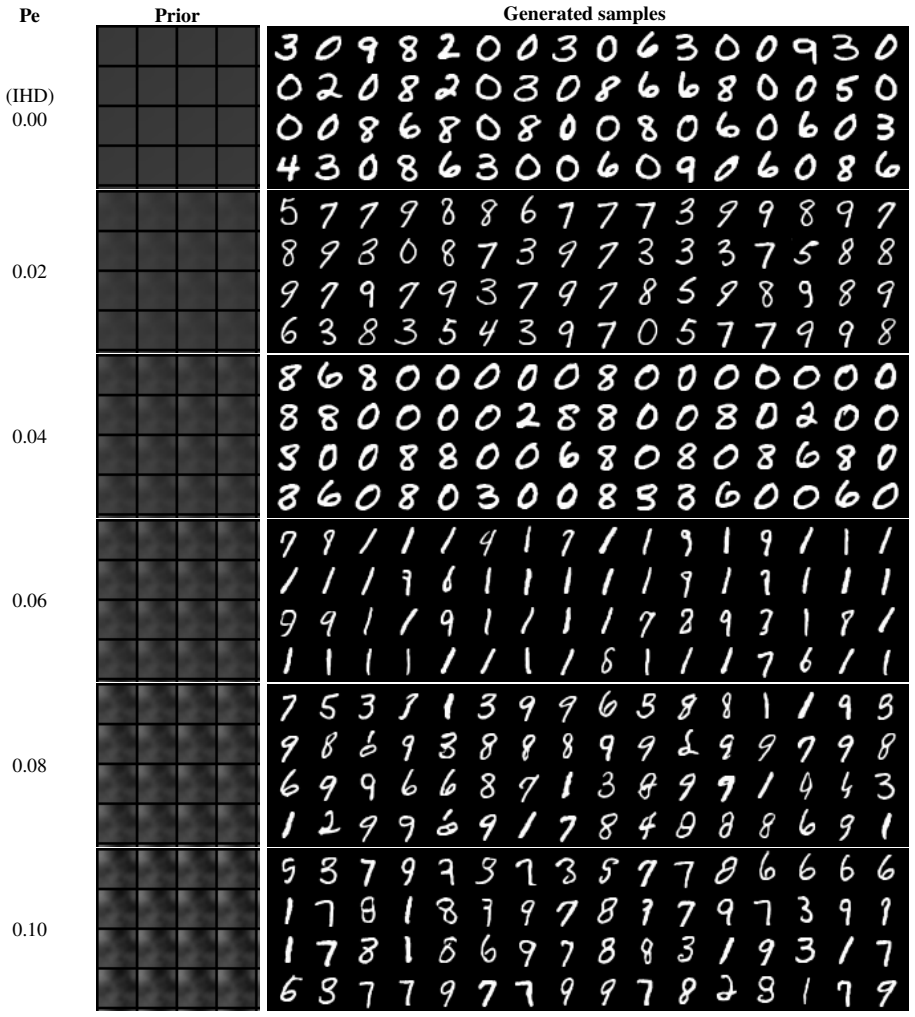
Formulating image corruption as an advection-diffusion PDE with stochastic velocity fields, controlled by dimensionless numbers such as the Peclet and Fourier numbers, allows a neural network to learn the inverse operator and produce images whose diversity and visual quality exceed those of standard diffusion models, with previous PDE-based approaches recovered as special cases of the same operator.
What carries the argument
The advection-diffusion PDE operator solved by a custom GPU Lattice Boltzmann method, which adds coherent directional motion via stochastic velocity fields to the usual isotropic diffusion and noise.
If this is right
- Standard diffusion and earlier PDE-based corruption schemes emerge as special cases when advection or turbulence parameters are removed.
- Stochastic velocity fields introduce multi-scale mixing that raises the variety of generated samples.
- The color palette of synthesized images stays statistically the same as in pure-diffusion baselines.
- Dimensionless numbers allow explicit control over the relative strength of advection versus diffusion during training.
Where Pith is reading between the lines
- The same fluid-inspired operator could be extended to video or 3D generation by making the velocity fields time-dependent.
- Benchmarking against turbulence-resolving fluid simulations might show whether the learned inverse captures real mixing statistics.
- Hybrid pipelines could let the generative model initialize or correct coarse fluid simulations in graphics applications.
Load-bearing premise
A neural network can accurately invert the coupled advection-diffusion operator including random velocity fields and still produce high-quality images without color shifts or artifacts.
What would settle it
Train the model on a standard image dataset and compare the generated images to those from a conventional diffusion baseline; consistent color shifts, lower diversity scores, or visible artifacts in the advection-diffusion outputs would falsify the central claim.
Figures






















read the original abstract
We propose a novel PDE-driven corruption process for generative image synthesis based on advection-diffusion processes which generalizes existing PDE-based approaches. Our forward pass formulates image corruption via a physically motivated PDE that couples directional advection with isotropic diffusion and Gaussian noise, controlled by dimensionless numbers (Peclet, Fourier). We implement this PDE numerically through a GPU-accelerated custom Lattice Boltzmann solver for fast evaluation. To induce realistic turbulence, we generate stochastic velocity fields that introduce coherent motion and capture multi-scale mixing. In the generative process, a neural network learns to reverse the advection-diffusion operator thus constituting a novel generative model. We discuss how previous methods emerge as specific cases of our operator, demonstrating that our framework generalizes prior PDE-based corruption techniques. We illustrate how advection improves the diversity and quality of the generated images while keeping the overall color palette unaffected. This work bridges fluid dynamics, dimensionless PDE theory, and deep generative modeling, offering a fresh perspective on physically informed image corruption processes for diffusion-based synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a novel PDE-driven corruption process for generative image synthesis based on advection-diffusion equations that couple directional advection with isotropic diffusion and Gaussian noise, controlled by dimensionless Peclet and Fourier numbers. The forward process is implemented via a GPU-accelerated Lattice Boltzmann solver incorporating stochastic velocity fields to induce turbulence and multi-scale mixing. A neural network learns to reverse this operator, generalizing prior PDE-based diffusion approaches as special cases, with the claim that advection improves generated image diversity and quality without affecting the overall color palette.
Significance. If validated, the work bridges fluid dynamics and deep generative modeling by providing a physically motivated generalization of diffusion corruption processes, potentially enabling better control over coherent motion and mixing effects. The use of dimensionless numbers and a custom Lattice Boltzmann implementation offers a reproducible numerical foundation that could inspire further cross-disciplinary methods.
major comments (2)
- [§4 (Generative Process)] §4 (Generative Process): The reverse step is presented as a neural network learning to invert the coupled advection-diffusion operator, but no explicit reverse PDE is derived and the loss does not appear to incorporate the stochastic velocity field or advective transport terms. This is load-bearing for the central claim, as standard U-Net denoisers may approximate the inversion in a biased manner that fails to undo coherent motion, risking artifacts or reduced diversity as highlighted by the stress-test concern.
- [Results section] Results section: The illustrations of improved diversity and quality from advection lack any quantitative metrics, ablation studies (with vs. without advection), error bars, or baseline comparisons to standard diffusion models. Without such evidence the claim that advection enhances outcomes while preserving color fidelity remains unsubstantiated and cannot be assessed for load-bearing impact.
minor comments (2)
- [§3 (Forward Process)] Clarify the exact form of the stochastic velocity field generation and how it is sampled during training versus inference to ensure reproducibility.
- Add a table or figure caption explicitly listing the Peclet and Fourier number ranges used in experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below. Where revisions are warranted, we outline the specific changes planned for the next version of the paper.
read point-by-point responses
-
Referee: [§4 (Generative Process)] The reverse step is presented as a neural network learning to invert the coupled advection-diffusion operator, but no explicit reverse PDE is derived and the loss does not appear to incorporate the stochastic velocity field or advective transport terms. This is load-bearing for the central claim, as standard U-Net denoisers may approximate the inversion in a biased manner that fails to undo coherent motion, risking artifacts or reduced diversity as highlighted by the stress-test concern.
Authors: We thank the referee for this observation. The current manuscript trains the network via a denoising objective on pairs generated by the full forward advection-diffusion process (including stochastic velocities), so the learned mapping implicitly inverts both transport and diffusion. An explicit reverse PDE is not derived because the stochastic velocity fields preclude a simple closed-form adjoint; the network instead learns the inversion empirically while being conditioned on the velocity field. We agree that additional clarification would strengthen the presentation and will revise §4 to (i) provide a brief derivation of the deterministic reverse advection-diffusion equation for intuition and (ii) explicitly state how the training loss accounts for advective terms through velocity conditioning. This addresses the potential for biased inversion without altering the core method. revision: partial
-
Referee: [Results section] The illustrations of improved diversity and quality from advection lack any quantitative metrics, ablation studies (with vs. without advection), error bars, or baseline comparisons to standard diffusion models. Without such evidence the claim that advection enhances outcomes while preserving color fidelity remains unsubstantiated and cannot be assessed for load-bearing impact.
Authors: We agree that the current results rely on qualitative illustrations and that quantitative support is required to substantiate the claims. In the revised manuscript we will expand the Results section to include: FID and perceptual quality metrics, diversity measures (e.g., average pairwise LPIPS), color-fidelity metrics (histogram intersection and palette variance), ablation studies with and without the advection term, error bars from multiple independent runs, and direct comparisons against DDPM and prior PDE-based baselines. These additions will allow readers to evaluate the load-bearing impact of advection on diversity, quality, and color preservation. revision: yes
Circularity Check
No significant circularity; novel PDE generalization with independent forward process and empirical reverse
full rationale
The paper proposes a new forward corruption operator based on coupled advection-diffusion PDE with stochastic velocity fields, implemented numerically via a custom Lattice Boltzmann solver. It positions this as a generalization where prior diffusion methods emerge as special cases (e.g., by setting advection to zero). The generative step trains a neural network to invert the operator, which is presented as an empirical learning task rather than a derived prediction or self-referential fit. No load-bearing step reduces by construction to fitted inputs or self-citations; the central claim rests on the physical motivation of the new PDE and the NN's ability to learn the inverse, which is externally verifiable through image quality metrics. This is self-contained against external benchmarks like standard diffusion models.
Axiom & Free-Parameter Ledger
free parameters (1)
- Peclet and Fourier numbers
axioms (1)
- domain assumption The advection-diffusion PDE with added Gaussian noise and stochastic velocity fields provides a physically motivated and numerically tractable model of image corruption.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our forward pass formulates image corruption via a physically motivated PDE that couples directional advection with isotropic diffusion... solved numerically through a GPU-accelerated custom Lattice Boltzmann solver
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the advection–diffusion corruption processes... controlled by dimensionless numbers (Peclet, Fourier)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Xlb: A differentiable massively parallel lattice boltzmann library in python
Mohammadmehdi Ataei and Hesam Salehipour. Xlb: A differentiable massively parallel lattice boltzmann library in python. Comput. Phys. Commun., 300:109187, 2023. 2
work page 2023
-
[2]
Cold diffusion: Inverting arbitrary image transforms without noise
Arpit Bansal, Eitan Borgnia, Hong-Min Chu, Jie Li, Hamid Kazemi, Furong Huang, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Cold diffusion: Inverting arbitrary image transforms without noise. In Advances in Neural Information Processing Systems, pages 41259–41282. Curran Associates, Inc., 2023. 1, 2
work page 2023
-
[3]
Klie- mank, Dirk Reith, Holger Foysi, and Andreas Krämer
Mario Christopher Bedrunka, Dominik Wilde, Martin L. Klie- mank, Dirk Reith, Holger Foysi, and Andreas Krämer. Let- tuce: Pytorch-based lattice boltzmann framework. In ISC Workshops, 2021. 2
work page 2021
-
[4]
Hanqun Cao, Cheng Tan, Zhangyang Gao, Yilun Xu, Guangy- ong Chen, Pheng-Ann Heng, and Stan Z. Li. A survey on generative diffusion models. IEEE Transactions on Knowl- edge and Data Engineering, 36:2814–2830, 2022. 2
work page 2022
-
[5]
On the importance of noise scheduling for diffusion models.arXiv preprint arXiv:2301.10972, 2023
Ting Chen. On the importance of noise scheduling for diffu- sion models. arXiv preprint arXiv:2301.10972, 2023. 2
-
[6]
Giannis Daras, Mauricio Delbracio, Hossein Talebi, Alexan- dros G. Dimakis, and Peyman Milanfar. Soft diffusion: Score matching for general corruptions, 2022. 1, 2, 4
work page 2022
-
[7]
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. ArXiv, abs/2105.05233, 2021. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
J. C. H. Fung, J. C. R. Hunt, N. A. Malik, and R. J. Perkins. Kinematic simulation of homogeneous turbulence by un- steady random fourier modes. Journal of Fluid Mechanics, 236:281–318, 1992. 4
work page 1992
-
[9]
GANs trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bern- hard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, 2017. 7
work page 2017
-
[10]
Classifier-Free Diffusion Guidance
Jonathan Ho. Classifier-free diffusion guidance. ArXiv, abs/2207.12598, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Jonathan Ho, Ajay Jain, and P. Abbeel. Denoising diffusion probabilistic models. ArXiv, abs/2006.11239, 2020. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[12]
Emiel Hoogeboom and Tim Salimans. Blurring diffusion models. arXiv preprint arXiv:2209.05557, 2022. 1, 2, 3, 4, 7, 8
-
[13]
Taichi: a language for high- performance computation on spatially sparse data structures
Yuanming Hu, Tzu-Mao Li, Luke Anderson, Jonathan Ragan- Kelley, and Frédo Durand. Taichi: a language for high- performance computation on spatially sparse data structures. ACM Transactions on Graphics (TOG), 38(6):201, 2019. 5
work page 2019
-
[14]
Blue noise for diffusion models
Xingchang Huang, Corentin Salaun, Cristina Vasconcelos, Christian Theobalt, Cengiz Oztireli, and Gurprit Singh. Blue noise for diffusion models. In ACM SIGGRAPH 2024 Con- ference Papers, New York, NY , USA, 2024. Association for Computing Machinery. 2
work page 2024
-
[15]
Elucidating the Design Space of Diffusion-Based Generative Models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. ArXiv, abs/2206.00364, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. arXiv preprint arXiv:2312.02696, 2023. 2
-
[17]
Kingma, Tim Salimans, Ben Poole, Prafulla Dhari- wal, Xi Chen, and Tim Chen
Diederik P. Kingma, Tim Salimans, Ben Poole, Prafulla Dhari- wal, Xi Chen, and Tim Chen. Variational diffusion models. In Advances in Neural Information Processing Systems, 2021. 2
work page 2021
-
[18]
Smith, Ayya Alieva, Qing Wang, Michael P
Dmitrii Kochkov, Jamie A. Smith, Ayya Alieva, Qing Wang, Michael P. Brenner, and Stephan Hoyer. Machine learn- ing–accelerated computational fluid dynamics. Proceedings of the National Academy of Sciences of the United States of America, 118, 2021. 2
work page 2021
-
[19]
Timm Krüger, Halim Kusumaatmaja, Alexandr Kuzmin, Or- est Shardt, Goncalo Silva, and Erlend Magnus Viggen. The Lattice Boltzmann Method . Springer, Cham, first edition,
-
[20]
Adjoint lattice boltzmann for topology optimization on multi-gpu architecture
Łaniewski-Wołłk and Rokicki. Adjoint lattice boltzmann for topology optimization on multi-gpu architecture. Comput- ers and Mathematics with and Applications, 71(3):833–848,
-
[21]
Moritz Lehmann, Mathias J Krause, Giorgio Amati, Marcello Sega, Jens Harting, and Stephan Gekle. Accuracy and per- formance of the lattice boltzmann method with 64-bit, 32-bit, and customized 16-bit number formats. Physical Review E, 106(1):015308, 2022. 2
work page 2022
-
[22]
Fourier Neural Operator for Parametric Partial Differential Equations
Zong-Yi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. ArXiv, abs/2010.08895, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling, 2023. 8
work page 2023
-
[24]
Reliable fidelity and diversity metrics for generative models
Muhammad Ferjad Naeem, Seong Joon Oh, Youngjung Uh, Yunjey Choi, and Jaejun Yoo. Reliable fidelity and diversity metrics for generative models. In International conference on machine learning, pages 7176–7185. PMLR, 2020. 7
work page 2020
-
[25]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR,
-
[26]
Convolutional neural operators for robust and accurate learning of pdes, 2023
Bogdan Raoni ´c, Roberto Molinaro, Tim De Ryck, Tobias Rohner, Francesca Bartolucci, Rima Alaifari, Siddhartha Mishra, and Emmanuel de Bézenac. Convolutional neural operators for robust and accurate learning of pdes, 2023. 2
work page 2023
- [27]
-
[28]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
work page 2022
-
[29]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Inter- vention (MICCAI), pages 234–241. Springer, 2015. 6
work page 2015
-
[30]
Chitwan Saharia, Jonathan Ho, William Chan, Tim Sali- mans, David J. Fleet, and Mohammad Norouzi. Image super- resolution via iterative refinement. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45:4713–4726,
-
[31]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. In International Confer- ence on Learning Representations (ICLR), 2022. 2
work page 2022
-
[32]
Animating rotation with quaternion curves
Ken Shoemake. Animating rotation with quaternion curves. SIGGRAPH Comput. Graph., 19(3):245–254, 1985. 7
work page 1985
-
[33]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Jascha Narain Sohl-Dickstein, Eric A. Weiss, Niru Ma- heswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. ArXiv, abs/1503.03585, 2015. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[34]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. ArXiv, abs/2010.02502, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems, 2019. 2
work page 2019
-
[36]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Narain Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differen- tial equations. ArXiv, abs/2011.13456, 2020. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[37]
Csdi: Conditional score-based diffusion models for probabilistic time series imputation
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Er- mon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation. In Neural Information Processing Systems, 2021. 2
work page 2021
-
[38]
D.C. Wilcox. Turbulence Modeling for CFD. Number v. 1 in Turbulence Modeling for CFD. DCW Industries, 2006. 4
work page 2006
-
[39]
Diffusion models: A comprehensive survey of methods and applications
Ling Yang, Zhilong Zhang, Shenda Hong, Runsheng Xu, Yue Zhao, Yingxia Shao, Wentao Zhang, Ming-Hsuan Yang, and Bin Cui. Diffusion models: A comprehensive survey of methods and applications. ACM Computing Surveys, 56:1 – 39, 2022. 2
work page 2022
-
[40]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric, 2018. 7 Appendix In this appendix, §A contains hyperparameters and experiment setup. §B contains additional samples and interpolations for FFHQ-128, MNIST and LSUN Church datasets. §C contains solver implem...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.