Accelerating Policy Synthesis in Large-Scale MDPs via Hierarchical Adaptive Refinement
Pith reviewed 2026-05-19 07:20 UTC · model grok-4.3
The pith
Hierarchical adaptive refinement produces near-optimal policies for million-state MDPs with up to 2x speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
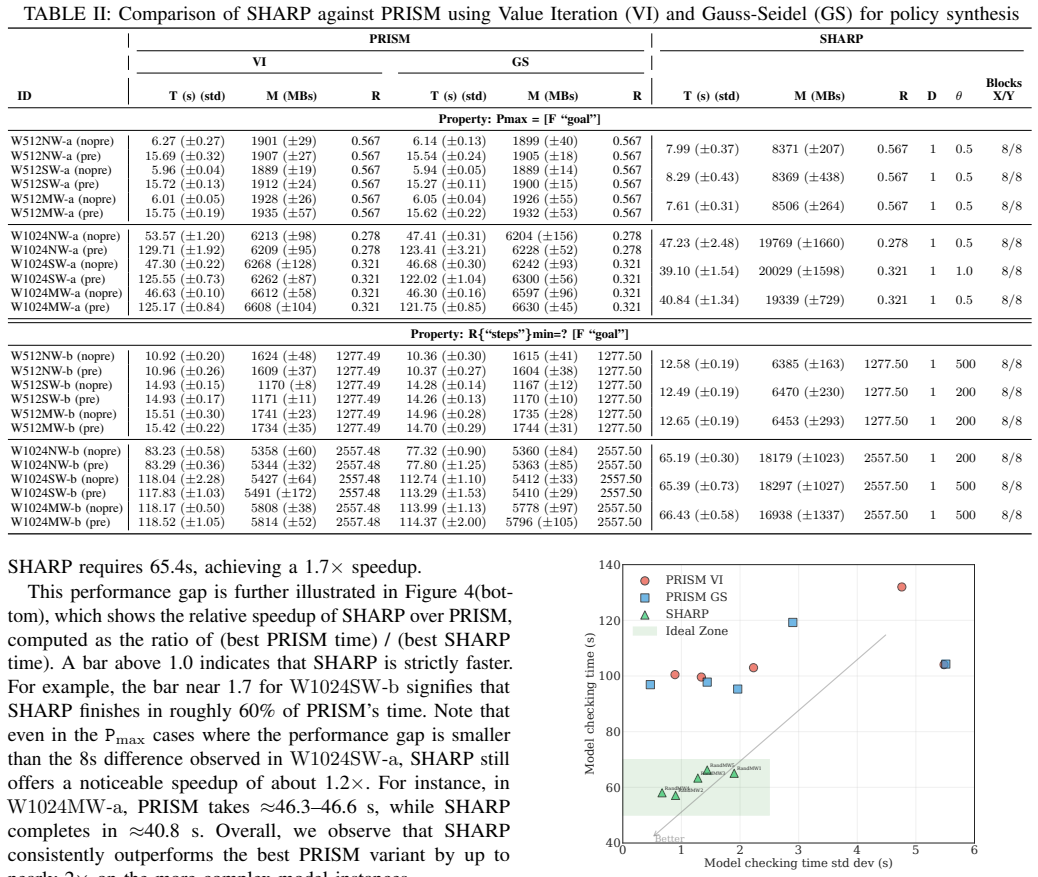
Core claim
By repeatedly locating fragile MDP regions and refining them hierarchically, the method solves local sub-problems exactly and stitches the results into a global policy. Under standard assumptions the composed policy remains near-optimal, with total error bounded by the local solver tolerance plus any boundary mismatch. Experiments across diverse case studies demonstrate up to twofold speedup over PRISM on MDPs reaching one million states.
What carries the argument
Hierarchical adaptive refinement, an iterative process that selects and subdivides the most fragile MDP regions for targeted local solving.
If this is right
- Policy synthesis becomes feasible for MDPs with up to one million states.
- The error of the returned policy stays within the local solver tolerance plus boundary mismatch.
- Refinement effort is spent only where it is needed, preserving efficiency.
- Speedups reach a factor of two relative to the PRISM tool on the tested benchmarks.
Where Pith is reading between the lines
- The same selective-refinement idea could be applied to other stochastic planning problems whose state spaces grow too large for monolithic solvers.
- Tighter control of boundary conditions at refinement interfaces would directly tighten the overall error bound.
- Real-time robotic controllers could invoke the method on demand when new uncertainty regions appear.
Load-bearing premise
A local solver must exist that can guarantee bounded error inside each refined sub-region and boundary mismatches between refined and coarse parts must stay small enough not to destroy the overall guarantee.
What would settle it
Apply the method to a concrete one-million-state MDP, compute the realized policy error, and check whether that error exceeds the sum of the local solver tolerance and the observed boundary mismatch.
Figures






read the original abstract
Software-intensive systems, such as software product lines and robotics, utilise Markov decision processes (MDPs) to capture uncertainty and analyse sequential decision-making problems. Despite the usefulness of conventional policy synthesis methods, they fail to scale to large state spaces. Our approach addresses this issue and accelerates policy synthesis in large MDPs by dynamically refining the MDP and iteratively selecting the most fragile MDP regions for refinement. This iterative procedure offers a balance between accuracy and efficiency, as refinement occurs only when necessary. We formally show that the composed policy is near-optimal under standard assumptions, with error bounded by the local solver tolerance and boundary mismatch. Across diverse case studies and MDPs up to 1M states, we demonstrate that our approach achieves up to $2\times$ speedup over PRISM, offering a competitive solution for real-world policy synthesis in large MDPs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical adaptive refinement algorithm for policy synthesis in large MDPs. It iteratively identifies and refines fragile sub-regions of the state space while maintaining a coarse skeleton, proves that the resulting composed policy is near-optimal under standard MDP assumptions with an error bound consisting of local solver tolerance plus boundary mismatch, and reports up to 2× speedup versus PRISM on MDPs with up to 1 M states across several case studies.
Significance. If the formal error analysis can be completed with an explicit, computable bound on boundary mismatch, the method would provide a principled way to trade accuracy for scalability in MDP policy synthesis, which is relevant for robotics and software product lines. The empirical scaling results on 1 M state models are a positive indicator, but the significance hinges on whether the refinement strategy remains effective when the mismatch term is rigorously controlled.
major comments (1)
- [Proof of near-optimality (abstract and §4)] The central near-optimality claim (abstract and presumably the proof in §4) states that total error is bounded by local solver tolerance plus boundary mismatch and that this remains below a user threshold. However, no quantitative bound is supplied on how boundary mismatch grows with the number of refinement iterations or with the geometry of the chosen sub-regions. Without such a bound the induction that keeps the composed policy near-optimal does not close; this is load-bearing for the formal result.
minor comments (2)
- [Abstract] The abstract refers to “standard assumptions” without enumerating them; a short list or pointer to the precise statement in the main text would help readers assess applicability.
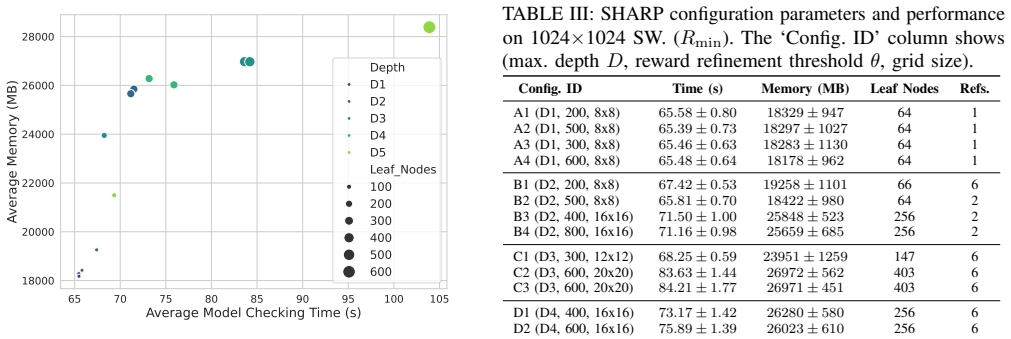
- [Experiments] The experimental section should report the exact tolerance values used for the local solver and the refinement threshold so that the claimed speed-up can be reproduced under the same error budget.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the empirical contributions on large-scale MDPs. The primary concern is the lack of a quantitative bound on boundary mismatch in the near-optimality proof. We address this directly below and commit to revisions that strengthen the formal result without altering the core claims or experimental findings.
read point-by-point responses
-
Referee: [Proof of near-optimality (abstract and §4)] The central near-optimality claim (abstract and presumably the proof in §4) states that total error is bounded by local solver tolerance plus boundary mismatch and that this remains below a user threshold. However, no quantitative bound is supplied on how boundary mismatch grows with the number of refinement iterations or with the geometry of the chosen sub-regions. Without such a bound the induction that keeps the composed policy near-optimal does not close; this is load-bearing for the formal result.
Authors: We agree that an explicit, computable bound on the boundary mismatch term is necessary to fully close the induction and make the overall guarantee practical. The current proof correctly decomposes the error into local solver tolerance (controlled by the user) plus boundary mismatch, but leaves the latter as a residual term. To address this, we will revise §4 by adding a new lemma that bounds the mismatch under standard assumptions (Lipschitz continuity of the value function, which is satisfied in the robotics and product-line MDPs we consider). The bound will be expressed in terms of sub-region diameter, number of boundary states, and the refinement threshold, allowing the user to select parameters that keep the total error below a desired threshold. We will also update the abstract and add a short discussion on how the bound scales with iterations. These changes will be included in the revised manuscript. revision: yes
Circularity Check
No circularity detected; derivation self-contained
full rationale
The paper presents an algorithmic hierarchical refinement procedure for MDPs and claims a formal proof that the composed policy is near-optimal under standard assumptions, with error bounded by local solver tolerance plus boundary mismatch. This is supported by external empirical comparisons to PRISM on MDPs up to 1M states. No equations, self-citations, or fitted parameters are shown in the abstract or description that reduce the error bound, speedup, or near-optimality claim to a definition or input taken from the paper's own results. The derivation relies on independent local solvers and standard MDP assumptions rather than internal construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions for MDP policy synthesis and near-optimality of composed policies
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SHARP is a hierarchical partition-based approach for MDP policy synthesis that adaptively refines MDP partitions only where needed... value spread criterion... boundary states... PROPAGATE ALLUP
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The composed policy is near-optimal under standard assumptions, with error bounded by the local solver tolerance and boundary mismatch.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Edge intelligence—research opportunities for distributed computing continuum systems,
V . C. Pujol, P. K. Donta, A. Morichetta, I. Murturi, and S. Dustdar, “Edge intelligence—research opportunities for distributed computing continuum systems,” IEEE Internet Computing , vol. 27, no. 4, pp. 53–74, 2023
work page 2023
-
[2]
A review of microservices autoscaling with formal verification perspective,
S. N. A. Jawaddi, M. H. Johari, and A. Ismail, “A review of microservices autoscaling with formal verification perspective,” Software: Practice and Experience, vol. 52, no. 11, pp. 2476–2495, 2022
work page 2022
-
[3]
Coordinating hundreds of cooperative, autonomous vehicles in warehouses,
P. R. Wurman, R. D’Andrea, and M. Mountz, “Coordinating hundreds of cooperative, autonomous vehicles in warehouses,” in Proceedings of the 19th National Conference on Innovative Applications of Artificial Intelligence - Volume 2, ser. IAAI’07. AAAI Press, 2007, p. 1752–1759
work page 2007
-
[4]
Probabilistic model checking of robots deployed in extreme environments,
X. Zhao, V . Robu, D. Flynn, F. Dinmohammadi, M. Fisher, and M. Webster, “Probabilistic model checking of robots deployed in extreme environments,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 8066–8074
work page 2019
-
[5]
An overview of verification and validation challenges for inspection robots,
M. Fisher, R. C. Cardoso, E. C. Collins, C. Dadswell, L. A. Dennis, C. Dixon, M. Farrell, A. Ferrando, X. Huang, M. Jump et al. , “An overview of verification and validation challenges for inspection robots,” Robotics, vol. 10, no. 2, p. 67, 2021
work page 2021
-
[6]
Uncertainty in self-adaptive systems: A research community perspective,
S. M. Hezavehi, D. Weyns, P. Avgeriou, R. Calinescu, R. Mirandola, and D. Perez-Palacin, “Uncertainty in self-adaptive systems: A research community perspective,”ACM Transactions on Autonomous and Adaptive Systems (TAAS), vol. 15, no. 4, pp. 1–36, 2021
work page 2021
-
[7]
Towards a research agenda for understanding and managing uncertainty in self-adaptive systems,
D. Weyns, R. Calinescu, R. Mirandola, K. Tei, M. Acosta, N. Bencomo, A. Bennaceur, N. Boltz, T. Bures, J. Camara et al., “Towards a research agenda for understanding and managing uncertainty in self-adaptive systems,” ACM SIGSOFT Software Engineering Notes , vol. 48, no. 4, pp. 20–36, 2023
work page 2023
-
[8]
M. L. Puterman, Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed. USA: John Wiley & Sons, Inc., 1994
work page 1994
-
[10]
Dynamic qos management and optimization in service- based systems,
R. Calinescu, L. Grunske, M. Kwiatkowska, R. Mirandola, and G. Tamburrelli, “Dynamic qos management and optimization in service- based systems,” IEEE Trans. Softw. Eng. , vol. 37, no. 3, p. 387–409, May 2011. [Online]. Available: https://doi.org/10.1109/TSE.2010.92
-
[11]
Family- based modeling and analysis for probabilistic systems — featuring profeat,
P. Chrszon, C. Dubslaff, S. Kl ¨uppelholz, and C. Baier, “Family- based modeling and analysis for probabilistic systems — featuring profeat,” in Proceedings of the 19th International Conference on Fundamental Approaches to Software Engineering - Volume 9633 . Berlin, Heidelberg: Springer-Verlag, 2016, p. 287–304. [Online]. Available: https://doi.org/10.10...
-
[12]
Multiple mobile robot task and motion planning: A survey,
L. Antonyshyn, J. Silveira, S. Givigi, and J. Marshall, “Multiple mobile robot task and motion planning: A survey,” ACM Comput. Surv., vol. 55, no. 10, Feb. 2023. [Online]. Available: https://doi.org/10.1145/3564696
-
[13]
E. M. Clarke, W. Klieber, M. Nov ´aˇcek, and P. Zuliani, Model Checking and the State Explosion Problem . Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 1–30. [Online]. Available: https://doi.org/10.1007/978-3-642-35746-6 1
-
[14]
C. Baier and J.-P. Katoen, Principles of model checking . MIT press, 2008
work page 2008
-
[15]
M. Kwiatkowska, G. Norman, and D. Parker, Stochastic Model Checking. Berlin, Heidelberg: Springer Berlin Heidelberg, 2007, pp. 220–270. [Online]. Available: https://doi.org/10.1007/978-3-540-72522-0 6
-
[16]
Abstraction-refinement for hierarchical probabilistic models,
S. Junges and M. T. Spaan, “Abstraction-refinement for hierarchical probabilistic models,” in International Conference on Computer Aided Verification. Springer, 2022, pp. 102–123
work page 2022
-
[17]
The 10,000 facets of mdp model checking,
C. Baier, H. Hermanns, and J.-P. Katoen, “The 10,000 facets of mdp model checking,” Computing and Software Science: State of the Art and Perspectives, pp. 420–451, 2019
work page 2019
-
[18]
On correctness, precision, and performance in quantitative verification,
C. E. Budde, A. Hartmanns, M. Klauck, J. K ˇret´ınsk´y, D. Parker, T. Quatmann, A. Turrini, and Z. Zhang, “On correctness, precision, and performance in quantitative verification,” in Leveraging Applications of Formal Methods, Verification and Validation: Tools and Trends , T. Margaria and B. Steffen, Eds. Cham: Springer International Publishing, 2021, pp...
work page 2021
-
[19]
PRISM 4.0: Verification of probabilistic real-time systems,
M. Kwiatkowska, G. Norman, and D. Parker, “PRISM 4.0: Verification of probabilistic real-time systems,” in Proc. 23rd International Conference on Computer Aided Verification (CAV’11), ser. LNCS, G. Gopalakrishnan and S. Qadeer, Eds., vol. 6806. Springer, 2011, pp. 585–591
work page 2011
-
[20]
The probabilistic model checker storm,
C. Hensel, S. Junges, J.-P. Katoen, T. Quatmann, and M. V olk, “The probabilistic model checker storm,” vol. 24, no. 4, p. 589–610, Aug
-
[21]
Available: https://doi.org/10.1007/s10009-021-00633-z
[Online]. Available: https://doi.org/10.1007/s10009-021-00633-z
-
[22]
Symbolic model checking of probabilistic processes using mtbdds and the kronecker representation,
L. d. Alfaro, M. Z. Kwiatkowska, G. Norman, D. Parker, and R. Segala, “Symbolic model checking of probabilistic processes using mtbdds and the kronecker representation,” in Proceedings of the 6th International Conference on Tools and Algorithms for Construction and Analysis of Systems: Held as Part of the European Joint Conferences on the Theory and Pract...
work page 2000
-
[23]
Explicit model checking of very large mdp using partitioning and secondary storage,
A. Hartmanns and H. Hermanns, “Explicit model checking of very large mdp using partitioning and secondary storage,” in Automated Technology for Verification and Analysis , B. Finkbeiner, G. Pu, and L. Zhang, Eds. Cham: Springer International Publishing, 2015, pp. 131–147
work page 2015
-
[24]
Statistical model checking for markov decision processes,
D. Henriques, J. G. Martins, P. Zuliani, A. Platzer, and E. M. Clarke, “Statistical model checking for markov decision processes,” in Proceedings of the 2012 Ninth International Conference on Quantitative Evaluation of Systems , ser. QEST ’12. USA: IEEE Computer Society, 2012, p. 84–93. [Online]. Available: https: //doi.org/10.1109/QEST.2012.19
-
[25]
H. Hansson and B. Jonsson, “A logic for reasoning about time and reliability,” Form. Asp. Comput., vol. 6, no. 5, p. 512–535, Sep. 1994. [Online]. Available: https://doi.org/10.1007/BF01211866
-
[26]
Model checking of probabilistic and nondeterministic systems,
A. Bianco and L. De Alfaro, “Model checking of probabilistic and nondeterministic systems,” in International Conference on Foundations of Software Technology and Theoretical Computer Science . Springer, 1995, pp. 499–513
work page 1995
-
[27]
K. Chatterjee and T. A. Henzinger, Value Iteration. Berlin, Heidelberg: Springer Berlin Heidelberg, 2008, pp. 107–138. [Online]. Available: https://doi.org/10.1007/978-3-540-69850-0 7
-
[28]
R. Bellman, Dynamic Programming. Princeton University Press, 1957
work page 1957
-
[29]
G. Fragapane, R. de Koster, F. Sgarbossa, and J. O. Strandhagen, “Planning and control of autonomous mobile robots for intralogistics: Literature review and research agenda,” European Journal of Operational Research, vol. 294, no. 2, pp. 405–426, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0377221721000217
work page 2021
-
[30]
Model minimization in markov decision processes,
T. Dean and R. Givan, “Model minimization in markov decision processes,” in Proceedings of the Fourteenth National Conference on Artificial Intelligence and Ninth Conference on Innovative Applications of Artificial Intelligence , ser. AAAI’97/IAAI’97. AAAI Press, 1997, p. 106–111
work page 1997
-
[31]
Reinforcement learning: a survey,
L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement learning: a survey,” J. Artif. Int. Res. , vol. 4, no. 1, p. 237–285, May 1996
work page 1996
-
[32]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,
R. S. Sutton, D. Precup, and S. Singh, “Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,” Artificial Intelligence, vol. 112, no. 1, pp. 181–211, 1999. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0004370299000521
work page 1999
-
[33]
J. Leike, M. Martic, V . Krakovna, P. A. Ortega, T. Everitt, A. Lefrancq, L. Orseau, and S. Legg, “AI safety gridworlds,” CoRR, vol. abs/1711.09883, 2017. [Online]. Available: http://arxiv.org/abs/1711. 09883
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Con- troller synthesis for omega-regular and steady-state specifications,
A. Velasquez, I. Alkhouri, A. Beckus, A. Trivedi, and G. Atia, “Con- troller synthesis for omega-regular and steady-state specifications,” in Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems , ser. AAMAS ’22. Richland, SC: International Foundation for Autonomous Agents and Multiagent Systems, 2022, p. 1310–1318
work page 2022
-
[35]
Multigain 2.0: Mdp controller synthesis for multiple mean-payoff, ltl and steady-state constraints,
S. Bals, A. Evangelidis, J. K ˇret´ınsk´y, and J. Waibel, “Multigain 2.0: Mdp controller synthesis for multiple mean-payoff, ltl and steady-state constraints,” in Proceedings of the 27th ACM International Conference on Hybrid Systems: Computation and Control , ser. HSCC ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Availabl...
-
[36]
Learning-based probabilistic ltl motion planning with environment and motion uncertainties,
M. Cai, H. Peng, Z. Li, and Z. Kan, “Learning-based probabilistic ltl motion planning with environment and motion uncertainties,” IEEE Transactions on Automatic Control , vol. 66, no. 5, pp. 2386–2392, 2021
work page 2021
-
[37]
Engineering trustworthy self-adaptive software with dynamic assurance cases,
R. Calinescu, D. Weyns, S. Gerasimou, M. U. Iftikhar, I. Habli, and T. Kelly, “Engineering trustworthy self-adaptive software with dynamic assurance cases,” IEEE Transactions on Software Engineering , vol. 44, no. 11, pp. 1039–1069, 2017
work page 2017
-
[38]
Synthesizing tradeoff spaces with quantitative guarantees for families of software systems,
J. C ´amara, D. Garlan, and B. Schmerl, “Synthesizing tradeoff spaces with quantitative guarantees for families of software systems,” Journal of Systems and Software , vol. 152, pp. 33–49, 2019
work page 2019
-
[39]
Markov decision process (mdp) framework for optimizing software on mobile phones,
T. L. Cheung, K. Okamoto, F. Maker, X. Liu, and V . Akella, “Markov decision process (mdp) framework for optimizing software on mobile phones,” in Proceedings of the Seventh ACM International Conference on Embedded Software , ser. EMSOFT ’09. New York, NY , USA: Association for Computing Machinery, 2009, p. 11–20. [Online]. Available: https://doi.org/10.1...
-
[40]
A markov decision process- based service migration procedure for follow me cloud,
A. Ksentini, T. Taleb, and M. Chen, “A markov decision process- based service migration procedure for follow me cloud,” in 2014 IEEE International Conference on Communications (ICC) , 2014, pp. 1350– 1354
work page 2014
-
[41]
Performance modelling and verification of cloud-based auto-scaling policies,
A. Evangelidis, D. Parker, and R. Bahsoon, “Performance modelling and verification of cloud-based auto-scaling policies,” Future Generation Computer Systems , vol. 87, pp. 629–638, 2018. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167739X17312475
work page 2018
-
[42]
Proactive self-adaptation under uncertainty: a probabilistic model checking approach,
G. A. Moreno, J. C ´amara, D. Garlan, and B. Schmerl, “Proactive self-adaptation under uncertainty: a probabilistic model checking approach,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering , ser. ESEC/FSE 2015. New York, NY , USA: Association for Computing Machinery, 2015, p. 1–12. [Online]. Available: https://doi.org...
-
[43]
Counterexample- guided abstraction refinement,
E. Clarke, O. Grumberg, S. Jha, Y . Lu, and H. Veith, “Counterexample- guided abstraction refinement,” in Computer Aided Verification, E. A. Emerson and A. P. Sistla, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2000, pp. 154–169
work page 2000
-
[44]
H. Hermanns, B. Wachter, and L. Zhang, “Probabilistic cegar,” in International Conference on Computer Aided Verification . Springer, 2008, pp. 162–175
work page 2008
-
[45]
A game- based abstraction-refinement framework for markov decision processes,
M. Kattenbelt, M. Kwiatkowska, G. Norman, and D. Parker, “A game- based abstraction-refinement framework for markov decision processes,” Formal Methods in System Design , vol. 36, pp. 246–280, 2010
work page 2010
-
[46]
Compositional proba- bilistic model checking with string diagrams of mdps,
K. Watanabe, C. Eberhart, K. Asada, and I. Hasuo, “Compositional proba- bilistic model checking with string diagrams of mdps,” in Computer Aided Verification - 35th International Conference, CAV 2023, Proceedings , ser. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), C. ...
work page 2023
-
[47]
C. A. C. Coello, Evolutionary algorithms for solving multi-objective problems. Springer, 2007
work page 2007
-
[48]
Search-based synthesis of probabilistic models for quality-of-service software engineering (t),
S. Gerasimou, G. Tamburrelli, and R. Calinescu, “Search-based synthesis of probabilistic models for quality-of-service software engineering (t),” in 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015, pp. 319–330
work page 2015
-
[49]
Synthesis of proba- bilistic models for quality-of-service software engineering,
S. Gerasimou, R. Calinescu, and G. Tamburrelli, “Synthesis of proba- bilistic models for quality-of-service software engineering,” Automated Software Engg., vol. 25, no. 4, p. 785–831, Dec. 2018
work page 2018
-
[50]
Haiq: Synthesis of software design spaces with structural and probabilistic guarantees,
J. C ´amara, “Haiq: Synthesis of software design spaces with structural and probabilistic guarantees,” in Proceedings of the 8th International Conference on Formal Methods in Software Engineering , 2020, pp. 22– 33
work page 2020
-
[51]
Targeting requirements violations of autonomous driving systems by dynamic evolutionary search
S. Gerasimou, J. C ´amara, R. Calinescu, N. Alasmari, F. Alhwikem, and X. Fang, “Evolutionary-guided synthesis of verified pareto- optimal mdp policies,” in Proceedings of the 36th IEEE/ACM International Conference on Automated Software Engineering , ser. ASE ’21. IEEE Press, 2022, p. 842–853. [Online]. Available: https://doi.org/10.1109/ASE51524.2021.9678727
-
[52]
Feudal reinforcement learning,
P. Dayan and G. E. Hinton, “Feudal reinforcement learning,” in Advances in Neural Information Processing Systems , S. Hanson, J. Cowan, and C. Giles, Eds., vol. 5. Morgan-Kaufmann, 1992. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 1992/file/d14220ee66aeec73c49038385428ec4c-Paper.pdf
work page 1992
-
[53]
Hierarchical reinforcement learning with the maxq value function decomposition,
T. G. Dietterich, “Hierarchical reinforcement learning with the maxq value function decomposition,” J. Artif. Int. Res. , vol. 13, no. 1, p. 227–303, Nov. 2000
work page 2000
-
[54]
Abstract value iteration for hierarchical reinforcement learning,
K. Jothimurugan, O. Bastani, and R. Alur, “Abstract value iteration for hierarchical reinforcement learning,” in Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , ser. Proceedings of Machine Learning Research, A. Banerjee and K. Fukumizu, Eds., vol. 130. PMLR, 13–15 Apr 2021, pp. 1162–1170. [Online]. Available: h...
work page 2021
-
[55]
Markovian state and action abstractions for mdps via hierarchical mcts,
A. Bai, S. Srivastava, and S. Russell, “Markovian state and action abstractions for mdps via hierarchical mcts,” in Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence , ser. IJCAI’16. AAAI Press, 2016, p. 3029–3037
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.