PDF Retrieval Augmented Question Answering
Pith reviewed 2026-05-19 08:13 UTC · model grok-4.3
The pith
Refining how non-textual elements like images and tables are processed in PDFs lets a RAG system answer complex questions that mix multiple data types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By refining approaches to processing and integrating non-textual elements in PDFs into the RAG framework to derive precise and relevant answers, as well as fine-tuning large language models to better adapt to our system, the RAG-based QA system effectively addresses complex multimodal questions.
What carries the argument
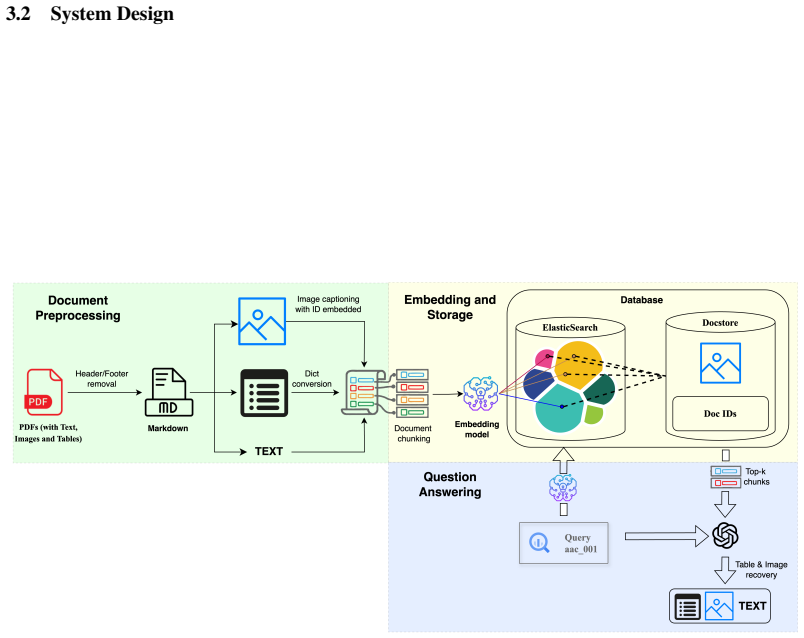
Retrieval-Augmented Generation (RAG) framework with refined integration of non-textual PDF elements including images, vector diagrams, graphs, and tables.
Load-bearing premise
That refining the processing and integration of non-textual elements in PDFs, together with fine-tuning LLMs, will produce precise and relevant answers for multimodal queries.
What would settle it
A test case where the proposed system is applied to a PDF with a known multimodal question and the answer accuracy is compared to existing text-focused RAG methods; if it does not improve, the claim is falsified.
Figures



read the original abstract
This paper presents an advancement in Question-Answering (QA) systems using a Retrieval Augmented Generation (RAG) framework to enhance information extraction from PDF files. Recognizing the richness and diversity of data within PDFs--including text, images, vector diagrams, graphs, and tables--poses unique challenges for existing QA systems primarily designed for textual content. We seek to develop a comprehensive RAG-based QA system that will effectively address complex multimodal questions, where several data types are combined in the query. This is mainly achieved by refining approaches to processing and integrating non-textual elements in PDFs into the RAG framework to derive precise and relevant answers, as well as fine-tuning large language models to better adapt to our system. We provide an in-depth experimental evaluation of our solution, demonstrating its capability to extract accurate information that can be applied to different types of content across PDFs. This work not only pushes the boundaries of retrieval-augmented QA systems but also lays a foundation for further research in multimodal data integration and processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents an advancement in Question-Answering (QA) systems using a Retrieval Augmented Generation (RAG) framework to enhance information extraction from PDF files. It recognizes challenges posed by multimodal content (text, images, vector diagrams, graphs, and tables) and proposes refining approaches to process and integrate non-textual elements into the RAG framework, combined with fine-tuning large language models, to handle complex multimodal questions. The authors claim an in-depth experimental evaluation demonstrating accurate information extraction across different PDF content types.
Significance. If the refinements to multimodal integration and the experimental results hold, the work could meaningfully extend standard RAG techniques to practical document QA scenarios involving real-world PDFs with figures and tables, providing a foundation for further multimodal data processing research.
major comments (2)
- [Abstract] Abstract: The abstract asserts an 'in-depth experimental evaluation' and 'demonstrating its capability to extract accurate information', but the manuscript supplies no methods, metrics, baselines, datasets, or quantitative results with error bars. This is load-bearing for the central claim that the refinements yield precise answers.
- [Approach] Approach description: The specific pipeline for processing and integrating non-textual elements (e.g., parsing vector diagrams, linearizing table structure, choice of vision encoder or layout model, or multimodal retrieval mechanism) is not described. Without these details the claimed improvements over text-only RAG cannot be evaluated or reproduced.
minor comments (1)
- [Abstract] The abstract would be clearer with one concrete example of a multimodal query combining text and a graph or table.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving the clarity and completeness of our work on multimodal PDF RAG for question answering. We address each major comment below and commit to a revised manuscript that incorporates the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts an 'in-depth experimental evaluation' and 'demonstrating its capability to extract accurate information', but the manuscript supplies no methods, metrics, baselines, datasets, or quantitative results with error bars. This is load-bearing for the central claim that the refinements yield precise answers.
Authors: We agree that the abstract's claims about experimental results require stronger grounding. The full manuscript includes a dedicated evaluation section with datasets, metrics (e.g., accuracy, F1), baselines (text-only RAG variants), and quantitative results, but these were not sufficiently summarized in the abstract. We will revise the abstract to explicitly reference the evaluation methodology, key metrics, and main findings with confidence intervals where applicable, while ensuring the results section provides full details including error bars. revision: yes
-
Referee: [Approach] Approach description: The specific pipeline for processing and integrating non-textual elements (e.g., parsing vector diagrams, linearizing table structure, choice of vision encoder or layout model, or multimodal retrieval mechanism) is not described. Without these details the claimed improvements over text-only RAG cannot be evaluated or reproduced.
Authors: We acknowledge that the approach section would benefit from greater specificity on the multimodal pipeline. The current description outlines the high-level integration of non-textual elements into the RAG framework and LLM fine-tuning, but we agree it lacks explicit steps for diagram parsing, table linearization, vision encoder selection, and the multimodal retrieval mechanism. We will expand this section with these technical details, including model choices and processing steps, to support reproducibility and direct comparison to text-only baselines. revision: yes
Circularity Check
No circularity: claims rest on proposed refinements and experiments, not self-referential definitions or reductions
full rationale
The manuscript advances a RAG-based QA system for multimodal PDF content by describing refinements to non-textual element processing plus LLM fine-tuning, then reports experimental results. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central assertions are not equivalent to their inputs by construction; they depend on the (unspecified in the excerpt) technical pipeline and external experimental outcomes rather than tautological redefinitions or ansatzes smuggled via prior work. This is a standard applied systems paper whose validity hinges on implementation details and benchmarks, not on circular reasoning patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ DBSCAN ... Marker ... GTE-large ... RAPTOR ... RAG-Llama3-70B with LoRA ... image captioning via LLaVA
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/abs/2407.21783. Aman Gupta, Anup Shirgaonkar, Angels de Luis Balaguer, Bruno Silva, Daniel Holstein, Dawei Li, Jennifer Marsman, Leonardo O Nunes, Mahsa Rouzbahman, Morris Sharp, et al. Rag vs fine-tuning: Pipelines, tradeoffs, and a case study on agriculture. arXiv preprint arXiv:2401.08406,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Revolutionizing retrieval-augmented generation with enhanced pdf structure recognition
Demiao Lin. Revolutionizing retrieval-augmented generation with enhanced pdf structure recognition. arXiv preprint arXiv:2401.12599,
-
[6]
Improved baselines with visual instruction tuning, 2023a
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023a. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023b. 10 Zihan Liu, Wei Ping, Rajarshi Roy, Peng Xu, Mohammad Shoeybi, and Bryan Catanzaro. Chatqa: Building gpt-4 level conversational qa models. ...
-
[7]
arXiv preprint arXiv:2305.14283 , year=
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283,
-
[8]
Chain-of-action: Faithful and multimodal question answering through large language models
Zhenyu Pan, Haozheng Luo, Manling Li, and Han Liu. Chain-of-action: Faithful and multimodal question answering through large language models. arXiv preprint arXiv:2403.17359,
-
[9]
URL https://journal.hexmos.com/marker-pdf-document-ai/ . Last visited December 10,2023. Hossein Rajabzadeh, Suyuchen Wang, Hyock Ju Kwon, and Bang Liu. Multimodal multi-hop question answering through a conversation between tools and efficiently finetuned large language models. arXiv preprint arXiv:2309.08922,
-
[10]
Pdftriage: question answering over long, structured documents
Jon Saad-Falcon, Joe Barrow, Alexa Siu, Ani Nenkova, Ryan A Rossi, and Franck Dernoncourt. Pdftriage: question answering over long, structured documents. arXiv preprint arXiv:2309.08872,
-
[11]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. Raptor: Recursive abstractive processing for tree-organized retrieval. arXiv preprint arXiv:2401.18059,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Kunal Sawarkar, Abhilasha Mangal, and Shivam Raj Solanki. Blended rag: Improving rag (retriever-augmented generation) accuracy with semantic search and hybrid query-based retrievers. arXiv preprint arXiv:2404.07220,
-
[13]
Heydar Soudani, Evangelos Kanoulas, and Faegheh Hasibi. Fine tuning vs. retrieval augmented generation for less popular knowledge. arXiv preprint arXiv:2403.01432,
-
[14]
Baize: An open-source chat model with parameter-efficient tuning on self-chat data
Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. arXiv preprint arXiv:2304.01196,
-
[15]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Mm-llms: Recent advances in multimodal large language models
Duzhen Zhang, Yahan Yu, Chenxing Li, Jiahua Dong, Dan Su, Chenhui Chu, and Dong Yu. Mm-llms: Recent advances in multimodal large language models. arXiv preprint arXiv:2401.13601,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.