FeDa4Fair: Client-Level Federated Datasets for Fairness Evaluation
Pith reviewed 2026-05-19 08:04 UTC · model grok-4.3
The pith
FeDa4Fair supplies client-level datasets that expose how federated models can appear fair on average while discriminating at individual clients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce FeDa4Fair, the first benchmarking framework designed to stress-test fairness methods under these heterogeneous conditions of attribute-bias and value-bias. The library creates datasets tailored to evaluating fair FL methods under heterogeneous client bias; we also release a benchmark suite generated by the FeDa4Fair library and provide ready-to-use functions for evaluating fairness outcomes for these datasets.
What carries the argument
FeDa4Fair library, which generates federated datasets that embed attribute-bias across clients and value-bias within the same attribute to create controlled heterogeneous bias conditions for fairness testing.
If this is right
- Researchers can now run controlled, reproducible tests of fairness methods on datasets that contain conflicting client biases rather than uniform bias.
- Fairness evaluation in federated learning will move from server-average metrics to explicit client-level checks.
- New fairness algorithms can be compared directly on a shared benchmark that includes both attribute-bias and value-bias cases.
- Standardized datasets make it possible to quantify how much existing single-attribute methods degrade under realistic client heterogeneity.
Where Pith is reading between the lines
- The framework could be extended to include dynamic client arrival or changing bias patterns over time.
- Practitioners deploying federated models in regulated domains might adopt client-level fairness audits as a routine step.
- Methods that learn to reconcile differing client biases on the fly could become a natural next research target.
Load-bearing premise
The two identified bias scenarios are the primary realistic cases that single-attribute fairness methods fail to handle, and the datasets produced by the library faithfully reproduce those conditions.
What would settle it
An experiment in which standard fairness methods achieve consistent fairness at both the global and every client level when trained and tested on FeDa4Fair datasets would show that the new framework does not address a genuine gap.
Figures














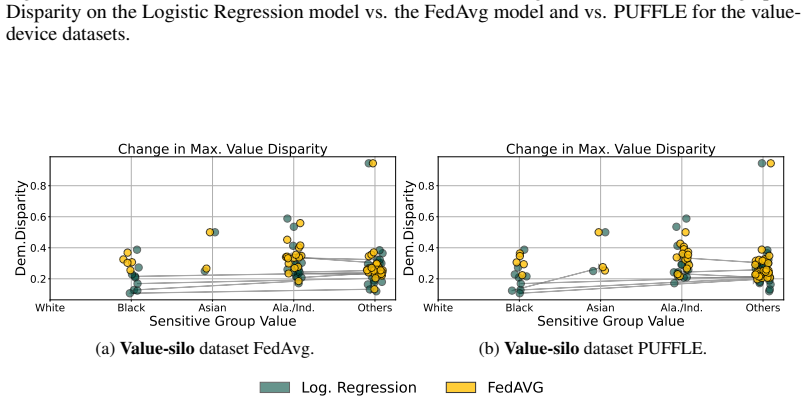






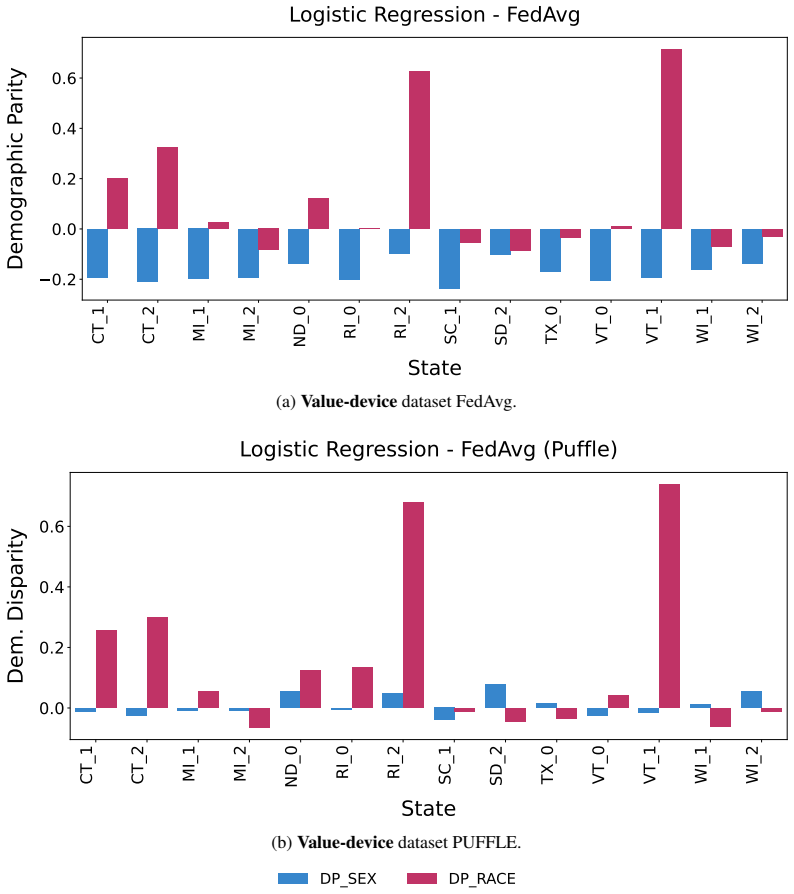
read the original abstract
Federated Learning (FL) enables collaborative training while preserving privacy, yet it introduces a critical challenge: the "illusion of fairness''. A global model, usually evaluated on the server, appears fair on average while keeping persistent discrimination at the client level. Current fairness-enhancing FL solutions often fall short, as they typically mitigate biases for a single, usually binary, sensitive attribute, while ignoring two realistic and conflicting scenarios: attribute-bias (where clients are unfair toward different sensitive attributes) and value-bias (where clients exhibit conflicting biases toward different values of the same attribute). To support more robust and reproducible fairness research in FL, we introduce FeDa4Fair, the first benchmarking framework designed to stress-test fairness methods under these heterogeneous conditions. Our contributions are three-fold: (1) We introduce FeDa4Fair, a library designed to create datasets tailored to evaluating fair FL methods under heterogeneous client bias; (2) we release a benchmark suite generated by the FeDa4Fair library to standardize the evaluation of fair FL methods; (3) we provide ready-to-use functions for evaluating fairness outcomes for these datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FeDa4Fair, a library for generating client-level federated datasets that incorporate heterogeneous fairness biases, specifically attribute-bias (clients unfair toward different sensitive attributes) and value-bias (conflicting biases toward different values of the same attribute). It releases a benchmark suite generated by the library and provides ready-to-use evaluation functions to support testing of fairness methods in federated learning beyond single-attribute settings.
Significance. If the library's data-generation procedure is shown to produce client distributions with the claimed per-client bias heterogeneity, the work would offer a useful standardized benchmark for FL fairness research, helping address the 'illusion of fairness' in global models. The release of the library, benchmark suite, and evaluation functions supports reproducibility and is a concrete strength.
major comments (2)
- [Abstract] Abstract and contributions list: the central claim that FeDa4Fair supplies the first benchmark for stress-testing under attribute-bias and value-bias is load-bearing on the unverified premise that the generated datasets actually yield measurable client-level differences (e.g., distinct per-client DP or EO gaps). No such client-level fairness statistics, ablation on bias-injection parameters, or baseline degradation results are reported.
- [Contributions (1) and (2)] Library and benchmark description: without reported verification that the partitioning/sampling rules produce statistically heterogeneous client fairness outcomes (as opposed to remaining homogeneous from the perspective of existing single-attribute methods), the utility of the released suite for the stated purpose cannot be assessed.
minor comments (2)
- [Library design] The description of the two bias scenarios could include a brief formal definition or pseudocode for how attribute-bias versus value-bias is injected at the client level to improve clarity.
- [Benchmark suite] Consider adding a table summarizing the released benchmark datasets (number of clients, sensitive attributes, bias parameters used) for quick reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for empirical verification of client-level heterogeneity in the generated datasets. We address each major comment below and commit to strengthening the manuscript with additional analyses in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and contributions list: the central claim that FeDa4Fair supplies the first benchmark for stress-testing under attribute-bias and value-bias is load-bearing on the unverified premise that the generated datasets actually yield measurable client-level differences (e.g., distinct per-client DP or EO gaps). No such client-level fairness statistics, ablation on bias-injection parameters, or baseline degradation results are reported.
Authors: We acknowledge that the current version of the manuscript does not report explicit client-level fairness statistics, parameter ablations, or baseline degradation results. In the revised manuscript we will add a dedicated experimental subsection that computes and reports per-client DP and EO gaps across the benchmark suite, includes ablations varying bias-injection strength, and shows how global models exhibit client-level fairness degradation even when server-level metrics appear acceptable. These additions will directly support the central claim. revision: yes
-
Referee: [Contributions (1) and (2)] Library and benchmark description: without reported verification that the partitioning/sampling rules produce statistically heterogeneous client fairness outcomes (as opposed to remaining homogeneous from the perspective of existing single-attribute methods), the utility of the released suite for the stated purpose cannot be assessed.
Authors: The library's partitioning and sampling procedures are explicitly constructed to assign distinct sensitive attributes to different clients (attribute-bias) and conflicting value preferences for the same attribute (value-bias). We agree that the manuscript would benefit from explicit verification. In the revision we will include statistical summaries (e.g., variance and range of per-client fairness gaps) and direct comparisons against standard single-attribute federated partitions to demonstrate that the resulting client distributions are measurably heterogeneous under both attribute-bias and value-bias regimes. revision: yes
Circularity Check
No circularity: library and benchmark release with no derived quantities or self-referential reductions
full rationale
The paper introduces FeDa4Fair as a library for generating client-level federated datasets and releases a benchmark suite, with contributions limited to the tooling, the generated datasets, and evaluation functions. No equations, fitted parameters, predictions, or first-principles derivations are present that could reduce to inputs by construction. The central claim rests on the release of the framework itself rather than any self-citation load-bearing step, ansatz, or renaming of known results. This is a standard software contribution paper whose validity is independent of internal fitting loops or author-overlapping uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous client biases (attribute-bias and value-bias) are realistic and conflicting scenarios that single-attribute fairness methods fail to address.
Reference graph
Works this paper leans on
-
[1]
A. Abay et al. Mitigating Bias in Federated Learning. 2020. URL: https://arxiv.org/ abs/2012.02447
-
[2]
Barocas et al. “Fairness in machine learning”. In: NeurIPS tutorial 1.2 (2017)
work page 2017
- [3]
-
[4]
J. R. Biden. Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. 2023
work page 2023
-
[5]
Benchmarking and survey of explanation methods for black box models
F. Bodria et al. “Benchmarking and survey of explanation methods for black box models”. In: Data Mining and Knowledge Discovery 37.5 (2023), pp. 1719–1778
work page 2023
-
[6]
S. Caldas et al. LEAF: A Benchmark for Federated Settings . 2019. arXiv: 1812.01097 [cs.LG]. URL:https://arxiv.org/abs/1812.01097
-
[7]
Fairness in Machine Learning: A Survey
S. Caton et al. “Fairness in Machine Learning: A Survey”. In:ACM Comput. Surv. 56.7 (Apr. 2024). ISSN : 0360-0300. DOI: 10.1145/3616865 . URL: https://doi.org/10.1145/ 3616865
-
[8]
Bias propagation in federated learning
H. Chang et al. “Bias propagation in federated learning”. In:ArXiv preprint abs/2309.02160 (2023). URL:https://arxiv.org/abs/2309.02160
-
[9]
T. Chen et al. “XGBoost: A Scalable Tree Boosting System”. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’16. San Francisco, California, USA: Association for Computing Machinery, 2016, 785–794. ISBN : 9781450342322. DOI: 10.1145/2939672.2939785 . URL: https://doi.org/10. 1145/2939672.2939785
-
[10]
E. Commission. Ethics guidelines for trustworthy AI. Publications Office, 2019. DOI:doi/10. 2759/346720
work page 2019
-
[11]
Benefits of the Federation? Analyzing the Impact of Fair Federated Learning at the Client Level
L. Corbucci et al. “Benefits of the Federation? Analyzing the Impact of Fair Federated Learning at the Client Level”. In: Proceedings of the ACM Conference on Fairness, Accountability, and Transparency. FAccT ’25. 2025, 2232–2248.DOI:10.1145/3715275.3732152
-
[12]
PUFFLE: Balancing Privacy, Utility, and Fairness in Federated Learning
L. Corbucci et al. “PUFFLE: Balancing Privacy, Utility, and Fairness in Federated Learning”. In: ECAI 2024 - 27th European Conference on Artificial Intelligence, 19-24 October 2024, Santiago de Compostela, Spain - Including 13th Conference on Prestigious Applications of Intelligent Systems (PAIS 2024) . Ed. by U. Endriss et al. V ol. 392. Frontiers in Art...
-
[13]
The regression analysis of binary sequences
D. R. Cox. “The regression analysis of binary sequences”. In: Journal of the Royal Statistical Society: Series B (Methodological) 20.2 (1958), pp. 215–232
work page 1958
-
[14]
K. Crenshaw. “Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory and antiracist politics”. In: Feminist legal theories. Routledge, 2013, pp. 23–51
work page 2013
-
[15]
Retiring Adult: New Datasets for Fair Machine Learning
F. Ding et al. “Retiring Adult: New Datasets for Fair Machine Learning”. In: Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual. Ed. by M. Ranzato et al. 2021, pp. 6478–6490. URL: https://proceedings.neurips.cc/paper/2021/ hash/32e54441e6382a7fba...
work page 2021
-
[16]
Towards predicting client benefit and contribution in federated learning from data imbalance
C. Düsing et al. “Towards predicting client benefit and contribution in federated learning from data imbalance”. In: Proceedings of the 3rd International Workshop on Distributed Machine Learning. 2022, pp. 23–29
work page 2022
-
[17]
M. Fontana et al. “Monitoring fairness in HOLDA”. In: HHAI2022: Augmenting Human Intellect. IOS Press, 2022, pp. 246–248
work page 2022
- [18]
-
[19]
Equality of Opportunity in Supervised Learning
M. Hardt et al. “Equality of Opportunity in Supervised Learning”. In: Advances in Neu- ral Information Processing Systems 29: Annual Conference on Neural Information Pro- cessing Systems 2016, December 5-10, 2016, Barcelona, Spain . Ed. by D. D. Lee et al. 2016, pp. 3315–3323. URL: https://proceedings.neurips.cc/paper/2016/hash/ 9d2682367c3935defcb1f9e247...
work page 2016
-
[20]
group on how AI principles should be implemented
E. group on how AI principles should be implemented. AI Governance in Japan. 2023
work page 2023
-
[21]
G. D. M. Jimenez et al. “FedArtML: A Tool to Facilitate the Generation of Non-IID Datasets in a Controlled Way to Support Federated Learning Research”. In:IEEE Access (2024)
work page 2024
-
[22]
Federated learning on non-iid data silos: An experimental study
Q. Li et al. “Federated learning on non-iid data silos: An experimental study”. In: 2022 IEEE 38th international conference on data engineering (ICDE). IEEE. 2022, pp. 965–978
work page 2022
-
[23]
When Machine Learning Meets Privacy: A Survey and Outlook
B. Liu et al. “When Machine Learning Meets Privacy: A Survey and Outlook”. In: ACM Comput. Surv. 54.2 (Mar. 2021). ISSN : 0360-0300. DOI: 10.1145/3436755 . URL: https: //doi.org/10.1145/3436755
-
[24]
Federated Learning With Non-IID Data: A Survey
Z. Lu et al. “Federated Learning With Non-IID Data: A Survey”. In:IEEE Internet of Things Journal 11.11 (2024), pp. 19188–19209. DOI:10.1109/JIOT.2024.3376548
-
[25]
T. Madiega. “Artificial intelligence act”. In:European Parliament: European Parliamentary Research Service (2021)
work page 2021
-
[26]
Communication-Efficient Learning of Deep Networks from Decentralized Data
B. McMahan et al. “Communication-Efficient Learning of Deep Networks from Decentralized Data”. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 20-22 April 2017, Fort Lauderdale, FL, USA. Ed. by A. Singh et al. V ol. 54. Proceedings of Machine Learning Research. PMLR, 2017, pp. 1273–1282. URL: h...
work page 2017
-
[27]
A Survey on Bias and Fairness in Machine Learning
N. Mehrabi et al. “A Survey on Bias and Fairness in Machine Learning”. In:ACM Comput. Surv. 54.6 (2021). ISSN : 0360-0300. DOI:10.1145/3457607. URL:https://doi.org/10. 1145/3457607
-
[28]
Minimax Demographic Group Fairness in Federated Learning
A. Papadaki et al. “Minimax Demographic Group Fairness in Federated Learning”. In: FAccT ’22: 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, June 21 - 24, 2022. ACM, 2022, pp. 142–159. DOI:10.1145/3531146.3533081. URL:https://doi.org/10.1145/3531146.3533081
-
[29]
FeLebrities: A User-Centric Assessment of Federated Learning Frameworks
W. Riviera et al. “FeLebrities: A User-Centric Assessment of Federated Learning Frameworks”. In: IEEE Access 11 (2023), pp. 96865–96878. DOI:10.1109/ACCESS.2023.3312579
-
[30]
The Chinese approach to artificial intelligence: an analysis of policy, ethics, and regulation
H. Roberts et al. “The Chinese approach to artificial intelligence: an analysis of policy, ethics, and regulation”. In: AI & society (2021)
work page 2021
-
[31]
T. Salazar et al. A Survey on Group Fairness in Federated Learning: Challenges, Taxonomy of Solutions and Directions for Future Research. 2024. URL:https://arxiv.org/abs/2410. 03855
work page 2024
-
[32]
The Current State and Challenges of Fairness in Federated Learning
S. Vucinich et al. “The Current State and Challenges of Fairness in Federated Learning”. In: IEEE Access 11 (2023), pp. 80903–80914. DOI:10.1109/ACCESS.2023.3295412
-
[33]
Salvaging federated learning by local adaptation
T. Yu et al. “Salvaging federated learning by local adaptation”. In: ArXiv preprint abs/2002.04758 (2020). URL:https://arxiv.org/abs/2002.04758. 12 A FeDa4Fair general setup We rely on several parameters as a general setup, which are independent of fairness specifications. Specifically, this implies that FeDa4Fair can also generate data for analyzing stan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.