VIDEE: Visual and Interactive Decomposition, Execution, and Evaluation of Text Analytics with Intelligent Agents
Pith reviewed 2026-05-19 09:32 UTC · model grok-4.3
The pith
VIDEE lets entry-level analysts perform advanced text analytics by collaborating with agents across decomposition, execution, and evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VIDEE supports entry-level data analysts to conduct advanced text analytics with intelligent agents through a human-agent collaboration workflow of decomposition, execution, and evaluation. The decomposition stage incorporates a human-in-the-loop Monte-Carlo Tree Search algorithm to support generative reasoning with human feedback. Execution generates an executable text analytics pipeline while Evaluation integrates LLM-based evaluation and visualizations to support user validation of execution results.
What carries the argument
The human-agent collaboration workflow whose decomposition stage uses a human-in-the-loop Monte-Carlo Tree Search algorithm that folds user feedback into generative reasoning to produce task breakdowns for text analytics.
If this is right
- Entry-level users generate executable pipelines for standard text tasks such as summarization and extraction.
- Quantitative runs expose recurring agent errors that appear during decomposition and execution.
- User studies surface distinct interaction patterns that vary with the participant's prior NLP experience.
- The three-stage structure supplies concrete design implications for other human-agent text analytics tools.
Where Pith is reading between the lines
- The same decomposition-plus-evaluation loop could transfer to non-text analysis domains that currently require expert oversight.
- Wider use might reduce the amount of formal NLP training analysts need before they can produce reliable results.
- The visualization layer could be generalized to give feedback on other kinds of agent-generated pipelines.
Load-bearing premise
User feedback fed into the Monte-Carlo Tree Search produces decompositions that are useful enough to improve the overall text analytics outcome for people without NLP training.
What would settle it
A side-by-side test in which non-expert participants complete the same analytics tasks at similar speed and accuracy using only direct large-language-model prompting without the VIDEE workflow or its feedback loop.
Figures





read the original abstract
Text analytics has traditionally required specialized knowledge in Natural Language Processing (NLP) or text analysis, which presents a barrier for entry-level analysts. Recent advances in large language models (LLMs) have changed the landscape of NLP by enabling more accessible and automated text analysis (e.g., topic detection, summarization, information extraction, etc.). We introduce VIDEE, a system that supports entry-level data analysts to conduct advanced text analytics with intelligent agents. VIDEE instantiates a human-agent collaroration workflow consisting of three stages: (1) Decomposition, which incorporates a human-in-the-loop Monte-Carlo Tree Search algorithm to support generative reasoning with human feedback, (2) Execution, which generates an executable text analytics pipeline, and (3) Evaluation, which integrates LLM-based evaluation and visualizations to support user validation of execution results. We conduct two quantitative experiments to evaluate VIDEE's effectiveness and analyze common agent errors. A user study involving participants with varying levels of NLP and text analytics experience -- from none to expert -- demonstrates the system's usability and reveals distinct user behavior patterns. The findings identify design implications for human-agent collaboration, validate the practical utility of VIDEE for non-expert users, and inform future improvements to intelligent text analytics systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VIDEE, a system that enables entry-level data analysts to perform advanced text analytics via intelligent agents. It describes a three-stage human-agent collaboration workflow: (1) decomposition using a human-in-the-loop Monte-Carlo Tree Search algorithm to support generative reasoning with user feedback, (2) execution to produce an executable text analytics pipeline, and (3) evaluation integrating LLM-based assessment and visualizations. Effectiveness is assessed via two quantitative experiments that analyze agent errors, plus a user study with participants ranging from no NLP experience to experts; the work claims to demonstrate usability, reveal user behavior patterns, and yield design implications for human-agent systems.
Significance. If the empirical claims hold, the work could meaningfully lower barriers to text analytics for non-experts by demonstrating a practical interactive workflow that combines agentic decomposition with human oversight and visual feedback. The focus on human-in-the-loop MCTS for generative reasoning and the identification of distinct user patterns offer a concrete contribution to human-AI collaboration research in NLP, with potential to inform future accessible analytics tools.
major comments (2)
- [Quantitative experiments section] Quantitative experiments section: no metrics are reported on decomposition quality (e.g., success rate of generated trees, inter-rater agreement, or comparison against non-interactive baselines such as plain LLM prompting or standard search). This directly affects the central claim that the human-in-the-loop MCTS produces useful generative reasoning that entry-level users could not achieve otherwise.
- [User study section] User study section: the manuscript provides no details on sample size, participant recruitment or demographics, statistical tests, controls, or error analysis. Without these, the usability conclusions for non-expert users cannot be rigorously assessed and remain difficult to replicate or generalize.
minor comments (2)
- [Abstract] Abstract: 'collaroration' is a typographical error and should read 'collaboration'.
- [System description] System description: the human-in-the-loop MCTS procedure would benefit from pseudocode or a clear algorithmic outline to support reproducibility, as the current high-level description leaves implementation details ambiguous.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that additional metrics on decomposition quality and fuller reporting of the user study will strengthen the empirical sections. We respond to each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Quantitative experiments section] Quantitative experiments section: no metrics are reported on decomposition quality (e.g., success rate of generated trees, inter-rater agreement, or comparison against non-interactive baselines such as plain LLM prompting or standard search). This directly affects the central claim that the human-in-the-loop MCTS produces useful generative reasoning that entry-level users could not achieve otherwise.
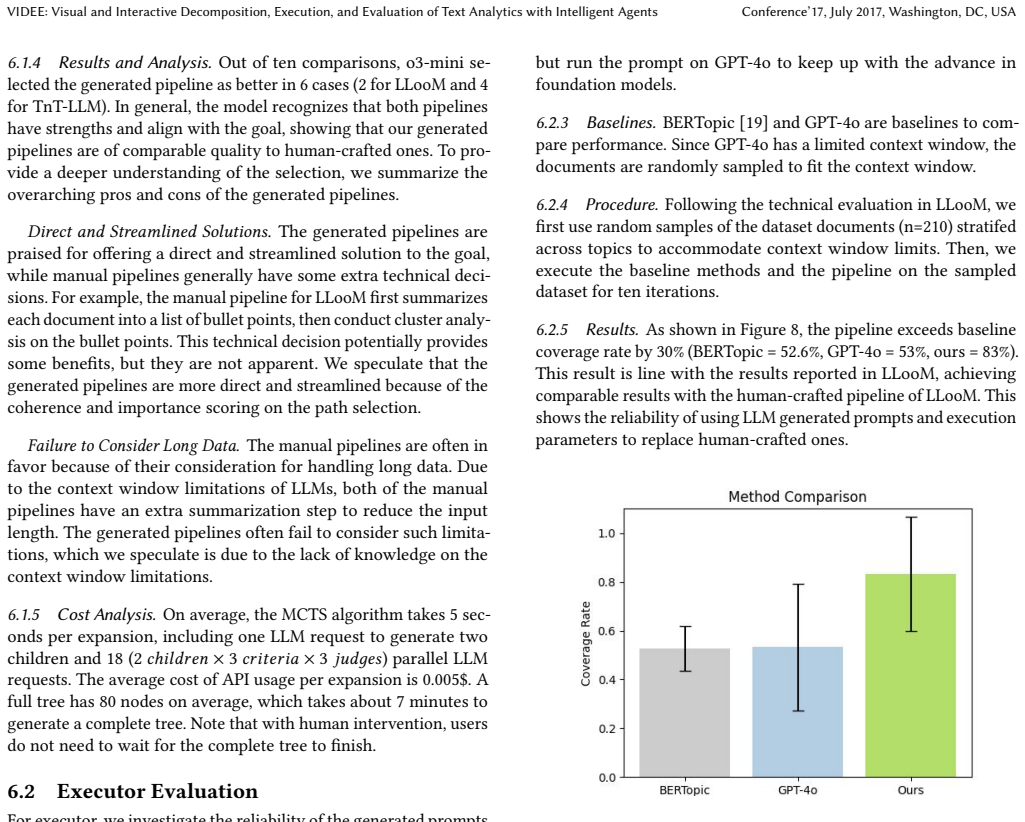
Authors: Our two quantitative experiments focus on systematically categorizing and analyzing common agent errors across decomposition and execution stages to reveal failure patterns. We acknowledge that explicit metrics such as success rates for generated trees and direct comparisons to non-interactive baselines would more directly support claims about the value of human-in-the-loop MCTS. In the revision we will add these comparisons (plain LLM prompting and standard search) with reported success rates where feasible. Inter-rater agreement is difficult to apply given the generative and interactive character of the process; we will instead expand discussion of how user feedback measurably reduces observed errors. These additions will be made without altering the existing error-analysis focus. revision: yes
-
Referee: [User study section] User study section: the manuscript provides no details on sample size, participant recruitment or demographics, statistical tests, controls, or error analysis. Without these, the usability conclusions for non-expert users cannot be rigorously assessed and remain difficult to replicate or generalize.
Authors: We regret the omission of these methodological details. In the revised manuscript we will expand the user-study section to report the sample size, recruitment procedures, participant demographics, statistical tests performed, study controls (e.g., task randomization), and a more granular error analysis of user interactions. These additions will improve transparency, replicability, and the strength of the usability conclusions for non-expert users. revision: yes
Circularity Check
No circularity: empirical systems paper with no derivations or self-referential reductions
full rationale
The paper presents VIDEE as a human-agent collaboration system for text analytics, describing a workflow of decomposition (via human-in-the-loop MCTS), execution, and evaluation, supported by quantitative experiments and a user study. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. Claims rest on empirical results rather than reducing to inputs by construction, self-citations, or ansatzes. The absence of any load-bearing self-referential steps makes the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Decomposition, which incorporates a human-in-the-loop Monte-Carlo Tree Search algorithm to support generative reasoning with human feedback
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use LLMs as judges to evaluate each step... complexity, coherence, and importance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2024. Claude. https://docs.anthropic.com/en/docs/about-claude/ models Accessed: 2025-04-09
work page 2024
-
[2]
Mohammad Beigi, Sijia Wang, Ying Shen, Zihao Lin, Adithya Kulkarni, Jian- feng He, Feng Chen, Ming Jin, Jin-Hee Cho, Dawei Zhou, Chang-Tien Lu, and Lifu Huang. 2024. Rethinking the Uncertainty: A Critical Review and Analysis in the Era of Large Language Models. doi:10.48550/arXiv.2410.20199 arXiv:2410.20199 [cs.AI]
-
[3]
Steven Bird and Edward Loper. 2004. NLTK: The Natural Language Toolkit. In Proceedings of the ACL Interactive Poster and Demonstration Sessions . Association for Computational Linguistics, 214–217. https://aclanthology.org/P04-3031/
work page 2004
-
[4]
Yuzhe Cai, Shaoguang Mao, Wenshan Wu, Zehua Wang, Yaobo Liang, Tao Ge, Chenfei Wu, Wang You, Ting Song, Yan Xia, Jonathan Tien, Nan Duan, and Furu Wei. 2024. Low-code LLM: Graphical User Interface over Large Language Models. doi:10.48550/arXiv.2304.08103 arXiv:2304.08103 [cs.CL]
- [5]
-
[6]
In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23)
Breaking Out of the Ivory Tower: A Large-scale Analysis of Patent Citations to HCI Research. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Article 760, 24 pages. doi:10.1145/3544548.3581108
-
[7]
and Yang, Qiang and Xie, Xing , title =
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2024. A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol. 15, 3, Article 39 (2024), 45 pages. doi:10.1145/3641289
-
[9]
Nan Chen, Yuge Zhang, Jiahang Xu, Kan Ren, and Yuqing Yang. 2025. VisEval: A Benchmark for Data Visualization in the Era of Large Language Models. IEEE Transactions on Visualization and Computer Graphics 31, 1 (2025), 1301–1311. doi:10.1109/TVCG.2024.3456320
-
[10]
Furui Cheng, Vilém Zouhar, Simran Arora, Mrinmaya Sachan, Hendrik Strobelt, and Mennatallah El-Assady. 2024. RELIC: Investigating Large Language Model Responses using Self-Consistency. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24) . Article 647, 18 pages. doi:10. 1145/3613904.3641904
-
[11]
Cheng-Han Chiang and Hung-yi Lee. 2023. Can Large Language Models Be an Al- ternative to Human Evaluations?. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 15607–15631...
-
[12]
Rémi Coulom. 2007. Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search. In Computers and Games, H. Jaap van den Herik, Paolo Ciancarini, and H. H. L. M. (Jeroen) Donkers (Eds.). Springer Berlin Heidelberg, 72–83
work page 2007
-
[13]
Shih-Chieh Dai, Aiping Xiong, and Lun-Wei Ku. 2023. LLM-in-the-loop: Leverag- ing Large Language Model for Thematic Analysis. doi:10.48550/arXiv.2310.15100 arXiv:2310.15100 [cs.CL]
-
[14]
DAIR.AI. [n. d.]. Prompt Engineering guide . https://www.promptingguide.ai/ Accessed: 2025-04-09
work page 2025
-
[15]
Chadha Degachi, Siddharth Mehrotra, Mireia Yurrita, Evangelos Niforatos, and Myrthe Lotte Tielman. 2024. Practising Appropriate Trust in Human-Centred AI VIDEE: Visual and Interactive Decomposition, Execution, and Evaluation of Text Analytics with Intelligent Agents Conference’17, July 2017, Washington, DC, USA Design. In Extended Abstracts of the CHI Con...
-
[16]
Victor Dibia, Jingya Chen, Gagan Bansal, Suff Syed, Adam Fourney, Erkang Zhu, Chi Wang, and Saleema Amershi. 2024. AUTOGEN STUDIO: A No-Code Developer Tool for Building and Debugging Multi-Agent Systems. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 72–79. doi:10.18653/v1/2024.emnlp-demo.8
-
[17]
Jakub Drápal, Hannes Westermann, and Jaromir Savelka. 2023. Using Large Language Models to Support Thematic Analysis in Empirical Legal Studies. doi:10.48550/arXiv.2310.18729 arXiv:2310.18729 [cs.AI]
-
[18]
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. ChatGPT outper- forms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences 120, 30 (2023), e2305016120. doi:10.1073/pnas.2305016120 arXiv:https://www.pnas.org/doi/pdf/10.1073/pnas.2305016120
-
[19]
Google. 2025. Gemini Model. https://gemini.google.com/app Accessed: 2025-04- 09
work page 2025
-
[20]
Maarten Grootendorst. 2022. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794 (2022). doi:10.48550/arXiv. 2203.05794
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2022
-
[21]
Peiling Jiang, Jude Rayan, Steven P. Dow, and Haijun Xia. 2023. Graphologue: Exploring Large Language Model Responses with Interactive Diagrams. In Pro- ceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Article 3, 20 pages. doi:10.1145/3586183.3606737
-
[22]
S. Jänicke, G. Franzini, M. F. Cheema, and G. Scheuermann. 2017. Visual Text Anal- ysis in Digital Humanities. Computer Graphics Forum 36, 6 (2017), 226–250. doi:10. 1111/cgf.12873 arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/cgf.12873
-
[23]
Majeed Kazemitabaar, Jack Williams, Ian Drosos, Tovi Grossman, Austin Zachary Henley, Carina Negreanu, and Advait Sarkar. 2024. Improving Steering and Verification in AI-Assisted Data Analysis with Interactive Task Decomposition. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). Article 92, 19 pages. doi...
-
[24]
Tae Soo Kim, Yoonjoo Lee, Jamin Shin, Young-Ho Kim, and Juho Kim. 2024. EvalLM: Interactive Evaluation of Large Language Model Prompts on User- Defined Criteria. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Article 306, 21 pages. doi:10.1145/3613904.3642216
-
[25]
Levente Kocsis and Csaba Szepesvári. 2006. Bandit Based Monte-Carlo Planning. In Machine Learning: ECML 2006 , Johannes Fürnkranz, Tobias Scheffer, and Myra Spiliopoulou (Eds.). Springer Berlin Heidelberg, 282–293
work page 2006
-
[26]
and Teoh, Janice and Landay, James A
Michelle S. Lam, Janice Teoh, James A. Landay, Jeffrey Heer, and Michael S. Bernstein. 2024. Concept Induction: Analyzing Unstructured Text with High- Level Concepts Using LLooM. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24) (Honolulu, HI, USA). Article 766, 28 pages. doi:10.1145/3613904.3642830
-
[27]
LangGraph. 2025. https://www.langchain.com/langgraph/. Accessed: 2025-04-09
work page 2025
-
[28]
LangSmith. 2025. https://www.langchain.com/langsmith/. Accessed: 2025-04-09
work page 2025
-
[29]
Sam Yu-Te Lee, Aryaman Bahukhandi, Dongyu Liu, and Kwan-Liu Ma. 2025. Towards Dataset-Scale and Feature-Oriented Evaluation of Text Summarization in Large Language Model Prompts. IEEE Transactions on Visualization and Computer Graphics 31, 1 (2025), 481–491. doi:10.1109/TVCG.2024.3456398
-
[30]
Sam Yu-Te Lee, Cheng-Wei Hung, Mei-Hua Yuan, and Kwan-Liu Ma. 2025. Visual Text Mining with Progressive Taxonomy Construction for Environmental Studies. doi:10.48550/arXiv.2502.05731 arXiv:2502.05731 [cs.HC]
-
[31]
Hippolyte Lefebvre, Christine Legner, and Martin Fadler. 2021. Data democ- ratization: toward a deeper understanding.. In Proceedings of the International Conference on Information Systems (ICIS)
work page 2021
-
[32]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems (NI...
- [33]
-
[34]
Shixia Liu, Xiting Wang, Christopher Collins, Wenwen Dou, Fangxin Ouyang, Mennatallah El-Assady, Liu Jiang, and Daniel A. Keim. 2019. Bridging Text Visu- alization and Mining: A Task-Driven Survey. IEEE Transactions on Visualization and Computer Graphics 25, 7 (2019), 2482–2504. doi:10.1109/TVCG.2018.2834341
-
[35]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). 2511–2522. doi:10. 18653/v1/2023.emnlp-main.153
work page 2023
-
[36]
Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. 2023. Calibrating LLM-Based Evaluator. doi:10.48550/arXiv.2309.13308 arXiv:2309.13308 [cs.CL]
-
[37]
Damien Masson, Sylvain Malacria, Géry Casiez, and Daniel Vogel. 2024. Direct- GPT: A Direct Manipulation Interface to Interact with Large Language Models. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Article 975, 16 pages. doi:10.1145/3613904.3642462
-
[38]
Microsoft. 2023. Data Wrangler Extension for Visual Studio Code. https://devblogs.microsoft.com/python/announcing-github-copilot-in- data-wrangler/ Accessed: 2025-04-09
work page 2023
-
[39]
Kazuo Misue, Peter Eades, Wei Lai, and Kozo Sugiyama. 1995. Layout Adjustment and the Mental Map. Journal of Visual Languages & Computing 6, 2 (1995), 183–
work page 1995
-
[40]
doi:10.1006/jvlc.1995.1010
-
[41]
OpenAI. 2024. GPT-4 Technical Report. doi:10.48550/arXiv.2303.08774 arXiv:2303.08774 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2024
-
[42]
OpenAI. 2025. o3-mini reasoning model. https://platform.openai.com/docs/ models/o3-mini. Accessed: 2025-04-09
work page 2025
-
[43]
Samir Passi and Mihaela Vorvoreanu. 2022. Overreliance on AI: Literature Review . Technical Report MSR-TR-2022-12. Microsoft. https://www.microsoft.com/en- us/research/publication/overreliance-on-ai-literature-review/
work page 2022
-
[44]
Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer
-
[45]
doi:10.48550/ arXiv.2311.01449 arXiv:2311.01449 [cs.CL]
TopicGPT: A Prompt-based Topic Modeling Framework. doi:10.48550/ arXiv.2311.01449 arXiv:2311.01449 [cs.CL]
-
[46]
Zeeshan Rasheed, Muhammad Waseem, Aakash Ahmad, Kai-Kristian Kemell, Wang Xiaofeng, Anh Nguyen Duc, and Pekka Abrahamsson. 2024. Can Large Lan- guage Models Serve as Data Analysts? A Multi-Agent Assisted Approach for Qual- itative Data Analysis. doi:10.48550/arXiv.2402.01386 arXiv:2402.01386 [cs.SE]
-
[47]
Zamfirescu-Pereira, Bjoern Hartmann, Aditya Parameswaran, and Ian Arawjo
Shreya Shankar, J.D. Zamfirescu-Pereira, Bjoern Hartmann, Aditya Parameswaran, and Ian Arawjo. 2024. Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). Article 131, 14 pages. doi:10.1145/3654777.3676450
-
[48]
Lin Shi, Chiyu Ma, Wenhua Liang, Weicheng Ma, and Soroush Vosoughi. 2024. Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge. doi:10.48550/arXiv.2406.07791 arXiv:2406.07791 [cs.CL]
-
[49]
Hari Subramonyam, Roy Pea, Christopher Pondoc, Maneesh Agrawala, and Colleen Seifert. 2024. Bridging the Gulf of Envisioning: Cognitive Challenges in Prompt Based Interactions with LLMs (CHI ’24). In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems . Article 1039, 19 pages. doi:10.1145/3613904.3642754
-
[50]
Sangho Suh, Bryan Min, Srishti Palani, and Haijun Xia. 2023. Sensecape: En- abling Multilevel Exploration and Sensemaking with Large Language Models. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Article 1, 18 pages. doi:10.1145/3586183.3606756
-
[51]
Ramzan Talib, Muhammad Kashif Hanif, Shaeela Ayesha, and Fakeeha Fatima
-
[52]
International Journal of Advanced Computer Science and Applications 7, 11 (2016)
Text Mining: Techniques, Applications and Issues. International Journal of Advanced Computer Science and Applications 7, 11 (2016). doi:10.14569/IJACSA. 2016.071153
-
[53]
Lev Tankelevitch, Viktor Kewenig, Auste Simkute, Ava Elizabeth Scott, Advait Sarkar, Abigail Sellen, and Sean Rintel. 2024. The Metacognitive Demands and Opportunities of Generative AI. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24) . Article 680, 24 pages. doi:10. 1145/3613904.3642902
-
[54]
Yuan Tian, Weiwei Cui, Dazhen Deng, Xinjing Yi, Yurun Yang, Haidong Zhang, and Yingcai Wu. 2025. ChartGPT: Leveraging LLMs to Generate Charts From Abstract Natural Language. IEEE Transactions on Visualization and Computer Graphics 31, 3 (2025), 1731–1745. doi:10.1109/TVCG.2024.3368621
- [55]
-
[56]
White, Longqi Yang, Reid Andersen, Georg Buscher, Dhruv Joshi, and Nagu Rangan
Mengting Wan, Tara Safavi, Sujay Kumar Jauhar, Yujin Kim, Scott Counts, Jennifer Neville, Siddharth Suri, Chirag Shah, Ryen W. White, Longqi Yang, Reid Andersen, Georg Buscher, Dhruv Joshi, and Nagu Rangan. 2024. TnT-LLM: Text Mining at Scale with Large Language Models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Minin...
-
[57]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. doi:10.48550/arXiv.2203.11171 arXiv:2203.11171 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2023
-
[58]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. doi:10.48550/arXiv.2308.08155 arXiv:2308.08155 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08155 2023
-
[59]
Liwenhan Xie, Chengbo Zheng, Haijun Xia, Huamin Qu, and Chen Zhu-Tian
-
[60]
In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24)
WaitGPT: Monitoring and Steering Conversational LLM Agent in Data Analysis with On-the-Fly Code Visualization. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). Association for Computing Machinery, New York, NY, USA, Article 119, 14 pages. doi:10. 1145/3654777.3676374 Conference’17, July 2017, Washington...
-
[61]
Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, James Xu Zhao, Min-Yen Kan, Junxian He, and Michael Xie. 2023. Self-Evaluation Guided Beam Search for Reason- ing. In Advances in Neural Information Processing Systems , A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Asso- ciates, Inc., 41618–41650. https://proceedings.neu...
work page 2023
-
[62]
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, and Enhong Chen. 2024. Large language models for generative information extraction: A survey. Frontiers of Computer Science 18, 6 (2024), 186357. doi:10.1007/s11704-024-40555-y
-
[63]
Zamfirescu-Pereira, Richmond Y
J.D. Zamfirescu-Pereira, Richmond Y. Wong, Bjoern Hartmann, and Qian Yang
-
[64]
Association for Computing Machinery, New York, NY, USA, Article 437, 21 pages
Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Article 437, 21 pages. doi:10.1145/3544548.3581388
-
[65]
Bowen Zhang and Harold Soh. 2024. Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction. doi:10.48550/arXiv.2404.03868 arXiv:2404.03868 [cs.CL]
-
[66]
Yuheng Zhao, Junjie Wang, Linbin Xiang, Xiaowen Zhang, Zifei Guo, Cagatay Turkay, Yu Zhang, and Siming Chen. 2024. LightVA: Lightweight Visual Analytics with LLM Agent-Based Task Planning and Execution. IEEE Transactions on Visu- alization and Computer Graphics (2024), 1–13. doi:10.1109/TVCG.2024.3496112 VIDEE: Visual and Interactive Decomposition, Execut...
-
[67]
The ids of each formulated NLP task must be unique. The "label" field in your output MUST ONLY use one of these exact labels from the primitive task list. {examples for ids and labels}
-
[68]
STRICTLY enforce input/output compatibility between primitive tasks: {requirement details}
A single semantic task often requires MULTIPLE primitive tasks chained together. STRICTLY enforce input/output compatibility between primitive tasks: {requirement details}
-
[69]
Correctly handle dependencies WITHIN the current step. {requirement details}
-
[70]
MAXIMIZE REUSE of existing primitive tasks from PREVIOUS steps. {requirement details}
-
[71]
DO NOT GENERATE PRIMITIVE TASKS FOR FUTURE SEMANTIC TASKS. {requirement details} ** Examples of Common Task Chains ** {examples} Reply with the following JSON format: { "primitive_tasks": [ { "solves": (string) id, "label": (string) (MUST be one of {supported_labels}), "id": (str) (a unique id for the task), "description": (string), "explanation": (string...
-
[72]
Context: Give instructions on what the user is trying to do
-
[73]
Task: Give instructions on how to analyze the text
-
[74]
Requirements: Provide any specific requirements or constraints for the prompt
-
[75]
The key name of JSON_format should be DIFFERENT from any following keys: [ {all_keys_str} ]
JSON_format: A JSON object with one key, the key name should be suitable to store the result of the prompt, and value should be a valid JSON format for representing the output. The key name of JSON_format should be DIFFERENT from any following keys: [ {all_keys_str} ]
-
[76]
output_schema: The "output_schema" key should provide a detailed description of the output structure defined for the key in JSON_format, using the clearer schema notation. {output_schema examples} Reply with this JSON format: { "prompt": { "Context": str, "Task": str, "Requirements": str "JSON_format": str }, "output_schema": str } (4). Identify and gener...
work page 2017
-
[77]
kmeans - K-means clustering (requires number of clusters) {k_means_description_and_parameters}
-
[78]
dbscan - Density-Based Spatial Clustering (doesn’t require number of clusters) {dbscan_description_and_parameters}
-
[79]
agglomerative - Hierarchical clustering {agglomerative_description_and_parameters}
-
[80]
gaussian_mixture - Gaussian Mixture Model {gaussian_mixture_description_and_parameters}
-
[81]
hdbscan - Hierarchical DBSCAN {hdbscan_description_and_parameters}
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.