PrefPaint: Enhancing Medical Image Inpainting through Expert Human Feedback
Pith reviewed 2026-05-19 08:27 UTC · model grok-4.3
The pith
Expert feedback through a simple interface and efficient fine-tuning improves anatomical accuracy in generated polyp images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
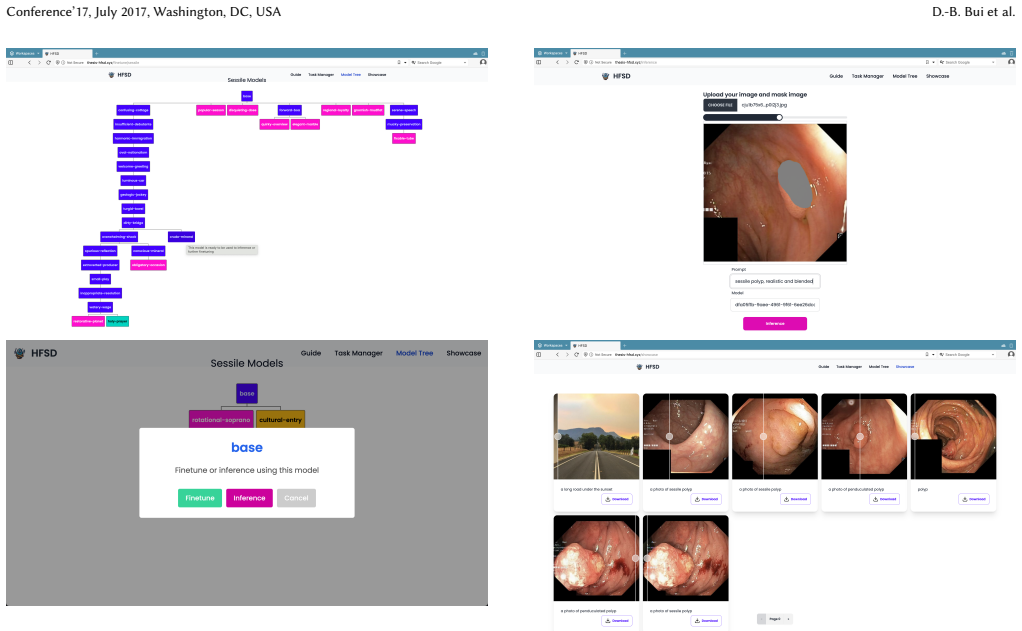
PrefPaint is an interactive system that incorporates expert human feedback into Stable Diffusion Inpainting. By using D3PO for fine-tuning instead of full reward-model training and adding a web-based interface with Model Tree versioning, the method generates highly realistic and anatomically accurate polyp images. User studies confirm it outperforms existing inpainting techniques by reducing visual inconsistencies and producing outputs suitable for clinical AI applications.
What carries the argument
The Model Tree versioning interface that lets experts manage and iterate on fine-tuned inpainting models within a web platform, paired with D3PO to incorporate feedback efficiently.
If this is right
- Generated polyp images show reduced visual inconsistencies compared with prior inpainting techniques.
- The outputs achieve higher anatomical accuracy as judged by domain experts.
- The system operates without computationally expensive reward models, suiting clinical settings with limited resources.
- The resulting images support training and evaluation of clinical AI models more effectively.
- The Model Tree interface simplifies expert participation in the fine-tuning loop.
Where Pith is reading between the lines
- The same feedback-driven interface could extend to inpainting tasks in other medical specialties such as radiology or pathology.
- Smaller clinics might use the approach to build custom synthetic datasets tailored to local patient populations.
- Wider adoption could raise overall trust in synthetic medical data by tying image quality directly to specialist judgment.
- The versioning concept might generalize to other interactive machine-learning tools that need to track incremental expert refinements.
Load-bearing premise
That collecting expert ratings through the proposed web interface and applying D3PO fine-tuning will produce reliable gains in anatomical accuracy and clinical utility without large-scale validation or full reward models.
What would settle it
A blinded rating study in which gastroenterologists score anatomical correctness of PrefPaint-generated polyp images against those from baseline inpainting methods, or a test of downstream polyp-detection model accuracy when trained on the new synthetic data versus conventional data.
Figures









read the original abstract
Inpainting, the process of filling missing or corrupted image parts, has broad applications in medical imaging. However, generating anatomically accurate synthetic polyp images for clinical AI is a largely underexplored problem. In specialized fields like gastroenterology, inaccuracies in generated images can lead to false patterns and significant errors in downstream diagnosis. To ensure reliability, models require direct feedback from domain experts like oncologists. We propose PrefPaint, an interactive system that incorporates expert human feedback into Stable Diffusion Inpainting. By using D3PO instead of full RLHF, our approach bypasses the need for computationally expensive reward models, making it a highly practical choice for resource-constrained clinical settings. Furthermore, we introduce a streamlined web-based interface to facilitate this expert-in-the-loop training. Central to this platform is the Model Tree versioning interface, a novel HCI concept that visualizes the evolutionary progression of fine-tuned models. This interactive interface provides a smooth and intuitive user experience, making it easier to offer feedback and manage the fine-tuning process. User studies show that PrefPaint outperforms existing methods, reducing visual inconsistencies and generating highly realistic, anatomically accurate polyp images suitable for clinical AI applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PrefPaint, an interactive system that incorporates expert human feedback into Stable Diffusion Inpainting via D3PO (instead of full RLHF) to generate anatomically accurate synthetic polyp images. It introduces a web-based interface featuring a novel Model Tree versioning concept for managing fine-tuned models, and claims via user studies that the approach reduces visual inconsistencies and produces images suitable for clinical AI applications in gastroenterology.
Significance. If the user-study claims are supported by quantitative metrics and downstream evaluations, the work could offer a practical, resource-efficient method for expert-in-the-loop fine-tuning of generative models in medical imaging, potentially improving synthetic data quality for clinical AI without the overhead of full RLHF pipelines. The Model Tree HCI element may also contribute to better interfaces for iterative model development.
major comments (2)
- [Abstract] Abstract: The central claim that 'User studies show that PrefPaint outperforms existing methods' and produces 'highly realistic, anatomically accurate polyp images suitable for clinical AI applications' is unsupported, as no metrics, baselines, statistical tests, or details on anatomical accuracy measurement are provided.
- [User studies / Experiments] User studies / Experiments section: No downstream task evaluations (e.g., polyp detection or segmentation performance using the generated images) are reported, leaving the leap from subjective preference data to clinical utility unsupported.
minor comments (1)
- [Abstract / Method] The expansion of the D3PO acronym and its precise relation to the fine-tuning objective should be stated explicitly on first use for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'User studies show that PrefPaint outperforms existing methods' and produces 'highly realistic, anatomically accurate polyp images suitable for clinical AI applications' is unsupported, as no metrics, baselines, statistical tests, or details on anatomical accuracy measurement are provided.
Authors: We agree that the abstract would be strengthened by including supporting details from the user studies. The experiments section reports results from a study with gastroenterologists using Likert-scale ratings for anatomical accuracy and visual fidelity, pairwise comparisons against baselines such as standard Stable Diffusion inpainting, and statistical significance via paired tests. We will revise the abstract to concisely reference these elements, for example by noting the expert preference rates and significance levels. revision: yes
-
Referee: [User studies / Experiments] User studies / Experiments section: No downstream task evaluations (e.g., polyp detection or segmentation performance using the generated images) are reported, leaving the leap from subjective preference data to clinical utility unsupported.
Authors: We acknowledge the value of downstream evaluations for demonstrating clinical utility. The current work centers on the expert-in-the-loop generation process and direct validation by gastroenterologists, who assessed images specifically for anatomical correctness and applicability to clinical AI training. This expert assessment provides a targeted measure of suitability rather than general preference. We have added a dedicated paragraph in the revised experiments section discussing potential benefits for downstream polyp detection based on expert qualitative feedback, while noting full quantitative downstream experiments as future work. revision: partial
Circularity Check
No circularity: claims rest on user studies and external benchmarks
full rationale
The paper introduces PrefPaint as an interactive system combining Stable Diffusion inpainting with D3PO fine-tuning and a web-based expert feedback interface. Central claims concern improved visual realism and anatomical accuracy for polyp images, validated via user studies. No equations, derivations, or first-principles predictions appear in the provided text. Performance assertions are tied to human evaluations rather than any fitted parameter renamed as a prediction or self-citation chain that reduces the result to its own inputs. The approach is self-contained against the reported user studies and does not invoke uniqueness theorems or ansatzes from prior self-work in a load-bearing way.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ a training solution based on Direct Preference for Denoising Diffusion Policy Optimization (D3PO) [30] ... bypassing the conventional requirement for a reward model.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
User studies show that PrefPaint outperforms existing methods, reducing visual inconsistencies and generating highly realistic, anatomically accurate polyp images
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anurag Ajay, Yilun Du, Abhi Gupta, Joshua Tenenbaum, Tommi Jaakkola, and Pulkit Agrawal. 2022. Is conditional generative modeling all you need for decision- making? arXiv preprint arXiv:2211.15657 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
AI Anthropic. 2023. Introducing claude
work page 2023
-
[3]
Ömer Aydın. 2023. Google Bard generated literature review: metaverse. Journal of AI 7, 1 (2023), 1–14
work page 2023
-
[4]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Róbert Busa-Fekete, Balázs Szörényi, Paul Weng, Weiwei Cheng, and Eyke Hüller- meier. 2014. Preference-based reinforcement learning: evolutionary direct policy search using a preference-based racing algorithm. Machine learning 97 (2014), 327–351
work page 2014
-
[6]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. 2023. Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems 30 (2017)
work page 2017
-
[8]
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. 2016. Density estimation using real nvp. arXiv preprint arXiv:1605.08803 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Miroslav Dudík, Katja Hofmann, Robert E Schapire, Aleksandrs Slivkins, and Masrour Zoghi. 2015. Contextual dueling bandits. In Conference on Learning Theory. PMLR, 563–587
work page 2015
-
[10]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. Advances in neural information processing systems 27 (2014)
work page 2014
-
[11]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, Conference’17, July 2017, Washington, DC, USA D.-B. Bui et al. SDiDreamBoothSD2iOurs Figure 12: Qualitative comparison of inpainting results on polyps. et al. 2022. Imagen video: High definition video generatio...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840–6851
work page 2020
-
[13]
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 8110–8119
work page 2020
-
[14]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Lu, Thomas Mesnard, Colton Bishop, Victor Carbune, and Abhinav Rastogi. 2023. Rlaif: Scaling re- inforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Ronghui Li, Junfan Zhao, Yachao Zhang, Mingyang Su, Zeping Ren, Han Zhang, Yansong Tang, and Xiu Li. 2023. FineDance: A Fine-grained Choreography Dataset for 3D Full Body Dance Generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 10234–10243
work page 2023
-
[16]
Hongyu Liu, Bin Jiang, Yibing Song, Wei Huang, and Chao Yang. 2020. Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16 . Springer, 725–741
work page 2020
-
[17]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
R OpenAI. 2023. Gpt-4 technical report. arxiv 2303.08774. View in Article 2, 5 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2024. Direct preference optimization: Your language SDiDreamBoothSD2iOurs Figure 13: Qualitative comparison of outpainting results on landscape. model is secretly a reward model. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[20]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[21]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1, 2 (2022), 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. In International conference on machine learning . Pmlr, 8821–8831
work page 2021
-
[23]
Danilo Rezende and Shakir Mohamed. 2015. Variational inference with normaliz- ing flows. In International conference on machine learning . PMLR, 1530–1538
work page 2015
-
[24]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
work page 2022
- [25]
-
[26]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems 35 (2022), 36479–36494
work page 2022
-
[27]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli
-
[28]
In International conference on machine learning
Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning . PMLR, 2256–2265
-
[29]
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback. Advances in Neural Information Processing PrefPaint: Enhancing Image Inpainting through Expert Human Feedback Conference’17, July 2017, Washington, DC, USA Systems 33 (2020), ...
work page 2020
-
[30]
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. 2021. Resolution-robust Large Mask Inpainting with Fourier Convolutions. arXiv preprint arXiv:2109.07161 (2021)
-
[31]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Weihan Shen, Xiaolong Zhu, and Xiu Li. 2024. Using human feedback to fine-tune diffusion models without any reward model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 8941–8951
work page 2024
-
[33]
Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang
-
[34]
In Proceedings of the IEEE/CVF International Conference on Computer Vision
Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 4471–4480
-
[35]
Yisong Yue, Josef Broder, Robert Kleinberg, and Thorsten Joachims. 2012. The k-armed dueling bandits problem. J. Comput. System Sci. 78, 5 (2012), 1538–1556
work page 2012
- [36]
-
[37]
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.