SynMotion: Semantic-Visual Adaptation for Motion Customized Video Generation
Pith reviewed 2026-05-19 07:56 UTC · model grok-4.3
The pith
SynMotion disentangles subject and motion embeddings while adding visual adapters to customize actions in generated videos from few samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing dual-embedding semantic comprehension that separates subject and motion concepts and by inserting parameter-efficient motion adapters into a frozen video diffusion backbone, together with an alternate optimization schedule on the manually built Subject Prior Video dataset, SynMotion produces higher-fidelity motion transfer in both text-to-video and image-to-video settings while avoiding semantic confusion and preserving subject generalization.
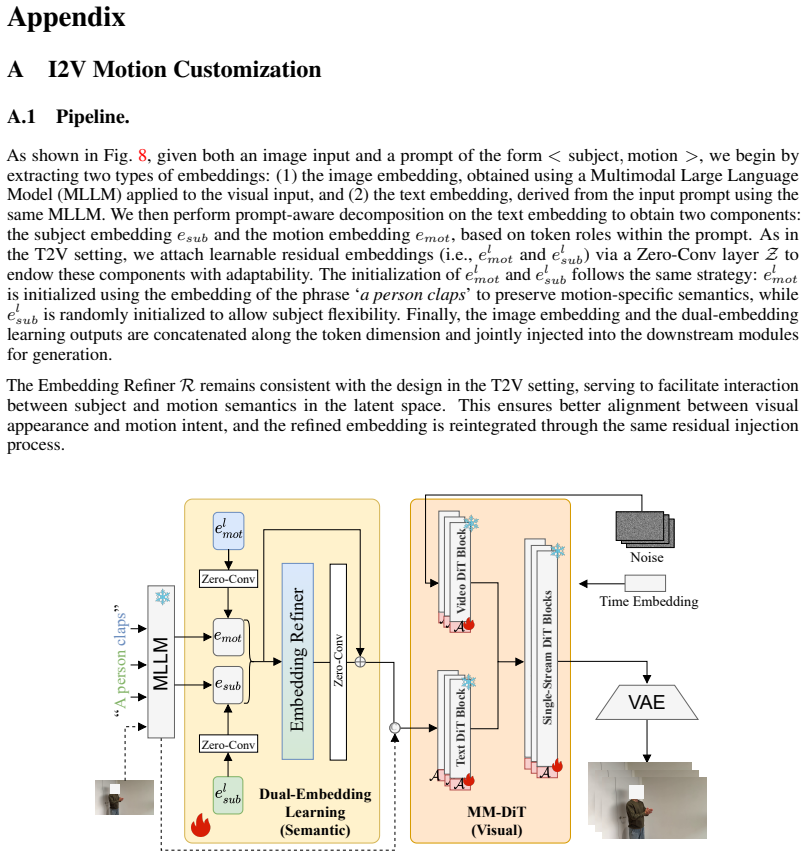
What carries the argument
Dual-embedding semantic comprehension that disentangles subject and motion representations, paired with parameter-efficient motion adapters and an alternate-optimization schedule over the Subject Prior Video dataset.
If this is right
- Customized motions can be transferred to arbitrary subjects described by text or shown in an image while keeping visual quality and temporal coherence.
- The model maintains its original ability to generate diverse subjects rather than overfitting to the few training videos.
- Both text-to-video and image-to-video pipelines benefit from the same joint semantic-visual design.
- A new benchmark, MotionBench, supplies standardized diverse motion patterns for future comparisons.
Where Pith is reading between the lines
- The same separation of motion and subject signals could be tested on longer video sequences or multi-person interactions where timing errors compound quickly.
- If the adapters remain lightweight, the method might be combined with other conditioning signals such as audio or depth maps without retraining the full model.
- The alternate-optimization idea could be applied to other customization tasks, such as learning specific camera motions or object interactions.
Load-bearing premise
Alternately optimizing separate subject and motion embeddings on the manually constructed Subject Prior Video dataset will increase motion specificity without creating semantic confusion or overfitting to the limited training clips.
What would settle it
A side-by-side comparison on MotionBench showing that videos generated with the dual-embedding plus adapter model receive lower motion accuracy scores from human raters or automated metrics than the best baseline when the same motion prompt is applied to previously unseen subjects.
Figures















read the original abstract
Diffusion-based video motion customization facilitates the acquisition of human motion representations from a few video samples, while achieving arbitrary subjects transfer through precise textual conditioning. Existing approaches often rely on semantic-level alignment, expecting the model to learn new motion concepts and combine them with other entities (e.g., ''cats'' or ''dogs'') to produce visually appealing results. However, video data involve complex spatio-temporal patterns, and focusing solely on semantics cause the model to overlook the visual complexity of motion. Conversely, tuning only the visual representation leads to semantic confusion in representing the intended action. To address these limitations, we propose SynMotion, a new motion-customized video generation model that jointly leverages semantic guidance and visual adaptation. At the semantic level, we introduce the dual-embedding semantic comprehension mechanism which disentangles subject and motion representations, allowing the model to learn customized motion features while preserving its generative capabilities for diverse subjects. At the visual level, we integrate parameter-efficient motion adapters into a pre-trained video generation model to enhance motion fidelity and temporal coherence. Furthermore, we introduce a new embedding-specific training strategy which \textbf{alternately optimizes} subject and motion embeddings, supported by the manually constructed Subject Prior Video (SPV) training dataset. This strategy promotes motion specificity while preserving generalization across diverse subjects. Lastly, we introduce MotionBench, a newly curated benchmark with diverse motion patterns. Experimental results across both T2V and I2V settings demonstrate that \method outperforms existing baselines. Project page: https://lucaria-academy.github.io/SynMotion/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SynMotion, a diffusion-based approach for motion-customized video generation that jointly uses semantic guidance via a dual-embedding semantic comprehension mechanism to disentangle subject and motion representations and visual adaptation via parameter-efficient motion adapters. It introduces an embedding-specific training strategy that alternately optimizes subject and motion embeddings on a manually constructed Subject Prior Video (SPV) dataset, along with a new MotionBench benchmark. The central claim is that this combination outperforms existing baselines in both T2V and I2V settings by improving motion fidelity, temporal coherence, and subject generalization without semantic confusion.
Significance. If the empirical results hold under rigorous validation, the work offers a practical engineering advance in balancing motion specificity with subject transfer in video diffusion models, potentially informing future adapter-based customization techniques. The introduction of MotionBench could provide a reusable resource for standardized evaluation in motion customization tasks.
major comments (2)
- [§4 (Training Strategy)] §4 (Training Strategy) and abstract: The load-bearing claim that alternately optimizing subject and motion embeddings on the manually constructed SPV dataset 'promotes motion specificity while preserving generalization across diverse subjects' without semantic confusion or overfitting requires stronger support. The manuscript should include ablations comparing alternation to joint optimization, quantitative measures of embedding leakage (e.g., motion cues in subject embeddings), and analysis of how limited SPV video count affects generalization to arbitrary subjects.
- [Experimental results section (e.g., Tables 1-3)] Experimental results section (e.g., Tables 1-3): Reported outperformance in T2V and I2V settings is attributed to the joint semantic-visual mechanism, yet the presentation lacks error bars across multiple seeds, statistical significance tests, or dataset statistics for SPV and MotionBench. This weakens confidence that improvements are not sensitive to post-hoc choices or limited training data.
minor comments (2)
- [Abstract] Abstract: The phrase 'precise textual conditioning' is used without clarifying its distinction from standard text encoders in baselines; a brief comparison would improve clarity.
- [Method] Notation: Ensure consistent use of symbols for subject embedding (e.g., E_s) and motion embedding (e.g., E_m) across sections describing the dual-embedding mechanism.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments in detail below and indicate the revisions we intend to make to improve the paper.
read point-by-point responses
-
Referee: [§4 (Training Strategy)] §4 (Training Strategy) and abstract: The load-bearing claim that alternately optimizing subject and motion embeddings on the manually constructed SPV dataset 'promotes motion specificity while preserving generalization across diverse subjects' without semantic confusion or overfitting requires stronger support. The manuscript should include ablations comparing alternation to joint optimization, quantitative measures of embedding leakage (e.g., motion cues in subject embeddings), and analysis of how limited SPV video count affects generalization to arbitrary subjects.
Authors: We appreciate the referee's emphasis on providing stronger empirical validation for our training strategy. While the current manuscript presents results supporting the effectiveness of alternate optimization, we acknowledge that direct comparisons and additional analyses would be beneficial. In the revised version, we will add ablations that compare alternate optimization of subject and motion embeddings against joint optimization. These will include quantitative evaluations of motion fidelity and subject consistency. To measure embedding leakage, we will introduce metrics such as the correlation between subject embeddings and motion features extracted from generated videos, or use probing classifiers to detect motion information in subject embeddings. For the impact of SPV video count, we will conduct experiments varying the number of videos in the SPV dataset and report how generalization to unseen subjects is affected, including cases with fewer videos to address concerns about limited data. These results will be added to Section 4 and the appendix. revision: yes
-
Referee: [Experimental results section (e.g., Tables 1-3)] Experimental results section (e.g., Tables 1-3): Reported outperformance in T2V and I2V settings is attributed to the joint semantic-visual mechanism, yet the presentation lacks error bars across multiple seeds, statistical significance tests, or dataset statistics for SPV and MotionBench. This weakens confidence that improvements are not sensitive to post-hoc choices or limited training data.
Authors: We agree that including variability measures and dataset details will increase confidence in our experimental results. We will revise the experimental section to include error bars computed over multiple training seeds (e.g., 3-5 runs) for the metrics reported in Tables 1-3. Statistical significance will be assessed using appropriate tests such as the Wilcoxon signed-rank test or t-tests between our method and baselines, with p-values reported. Additionally, we will provide comprehensive dataset statistics for both SPV and MotionBench, detailing the number of subjects, motion types, video lengths, and diversity metrics. This information will clarify the scope of the datasets and support the generalizability of our findings. These changes will be implemented in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical engineering contribution
full rationale
The paper proposes SynMotion as an empirical method combining dual-embedding semantic comprehension and parameter-efficient motion adapters, trained via alternating optimization on a manually constructed SPV dataset. No mathematical derivation chain, equations, or first-principles predictions are presented that reduce to inputs by construction. Claims of improved motion specificity and generalization are framed as design choices validated through T2V/I2V experiments and the new MotionBench benchmark, with no self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central result. The contribution remains self-contained as a practical adaptation technique.
Axiom & Free-Parameter Ledger
free parameters (2)
- motion adapter parameters
- embedding-specific training schedule
axioms (2)
- domain assumption Pre-trained video diffusion models already encode sufficient generative capability for diverse subjects that can be preserved while adding motion adapters.
- domain assumption Spatio-temporal patterns in video can be disentangled into subject and motion representations via separate embeddings.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce the dual-embedding semantic comprehension mechanism which disentangles subject and motion representations... alternately optimizes subject and motion embeddings, supported by the manually constructed Subject Prior Video (SPV) training dataset
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Ming-omni: A unified multimodal model for perception and generation
Inclusion AI, Biao Gong, Cheng Zou, Chuanyang Zheng, Chunluan Zhou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong Wang, et al. Ming-omni: A unified multimodal model for perception and generation. Technical Report, 2025
work page 2025
-
[3]
Ming-lite-uni: Advancements in unified architecture for natural multimodal interaction
Inclusion AI, Biao Gong, Cheng Zou, Dandan Zheng, Hu Yu, Jingdong Chen, Jianxin Sun, Junbo Zhao, Jun Zhou, Kaixiang Ji, et al. Ming-lite-uni: Advancements in unified architecture for natural multimodal interaction. Technical Report, 2025
work page 2025
-
[4]
A neural space-time representation for text-to-image personalization
Yuval Alaluf, Elad Richardson, Gal Metzer, and Daniel Cohen-Or. A neural space-time representation for text-to-image personalization. ACM TOG, 42(6):1–10, 2023
work page 2023
-
[5]
Latent- shift: Latent diffusion with temporal shift for efficient text-to-video generation
Jie An, Songyang Zhang, Harry Yang, Sonal Gupta, Jia-Bin Huang, Jiebo Luo, and Xi Yin. Latent- shift: Latent diffusion with temporal shift for efficient text-to-video generation. arXiv preprint arXiv:2304.08477, 2023
-
[6]
Domain-agnostic tuning-encoder for fast personalization of text-to-image models
Moab Arar, Rinon Gal, Yuval Atzmon, Gal Chechik, Daniel Cohen-Or, Ariel Shamir, and Amit H Bermano. Domain-agnostic tuning-encoder for fast personalization of text-to-image models. arXiv preprint arXiv:2307.06925, 2023
-
[7]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Customttt: Motion and appearance customized video generation via test-time training
Xiuli Bi, Jian Lu, Bo Liu, Xiaodong Cun, Yong Zhang, Weisheng Li, and Bin Xiao. Customttt: Motion and appearance customized video generation via test-time training. arXiv preprint arXiv:2412.15646, 2024
-
[10]
Pix2video: Video editing using image diffusion
Duygu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. Pix2video: Video editing using image diffusion. In ICCV, pages 23206–23217, 2023
work page 2023
-
[11]
Stablevideo: Text-driven consistency-aware diffusion video editing
Wenhao Chai, Xun Guo, Gaoang Wang, and Yan Lu. Stablevideo: Text-driven consistency-aware diffusion video editing. In ICCV, pages 23040–23050, 2023
work page 2023
-
[12]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7310–7320, 2024. 10
work page 2024
-
[14]
Disenbooth: Disentangled parameter-efficient tuning for subject-driven text-to-image generation
Hong Chen, Yipeng Zhang, Xin Wang, Xuguang Duan, Yuwei Zhou, and Wenwu Zhu. Disenbooth: Disentangled parameter-efficient tuning for subject-driven text-to-image generation. arXiv preprint arXiv:2305.03374, 2023
-
[15]
Custom-edit: Text-guided image editing with customized diffusion models
Jooyoung Choi, Yunjey Choi, Yunji Kim, Junho Kim, and Sungroh Yoon. Custom-edit: Text-guided image editing with customized diffusion models. arXiv preprint arXiv:2305.15779, 2023
-
[16]
Xtuner: A toolkit for efficiently fine-tuning llm
XTuner Contributors. Xtuner: A toolkit for efficiently fine-tuning llm. https://github.com/ InternLM/xtuner, 2023
work page 2023
-
[17]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[18]
Ranni: Taming text-to-image diffusion for accurate instruction following
Yutong Feng, Biao Gong, Di Chen, Yujun Shen, Yu Liu, and Jingren Zhou. Ranni: Taming text-to-image diffusion for accurate instruction following. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4744–4753, 2024
work page 2024
-
[19]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Encoder- based domain tuning for fast personalization of text-to-image models
Rinon Gal, Moab Arar, Yuval Atzmon, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. Encoder- based domain tuning for fast personalization of text-to-image models. ACM TOG, 2023
work page 2023
-
[21]
Customizing text-to-image generation with inverted interaction
Mengmeng Ge, Xu Jia, Takashi Isobe, Xiaomin Li, Qinghe Wang, Jing Mu, Dong Zhou, Li Wang, Huchuan Lu, Lu Tian, et al. Customizing text-to-image generation with inverted interaction. In Proceed- ings of the 32nd ACM International Conference on Multimedia, pages 10901–10909, 2024
work page 2024
-
[22]
Chatglm: A family of large language models from glm-130b to glm-4 all tools, 2024
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, ...
work page 2024
-
[23]
Check locate rectify: A training-free layout calibration system for text-to-image generation
Biao Gong, Siteng Huang, Yutong Feng, Shiwei Zhang, Yuyuan Li, and Yu Liu. Check locate rectify: A training-free layout calibration system for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6624–6634, 2024
work page 2024
-
[24]
Biao Gong, Shuai Tan, Yutong Feng, Xiaoying Xie, Yuyuan Li, Chaochao Chen, Kecheng Zheng, Yujun Shen, and Deli Zhao. Uknow: A unified knowledge protocol with multimodal knowledge graph datasets for reasoning and vision-language pre-training. Advances in Neural Information Processing Systems, 37:9612–9633, 2024
work page 2024
-
[25]
Talecrafter: Interactive story visualization with multiple characters
Yuan Gong, Youxin Pang, Xiaodong Cun, Menghan Xia, Haoxin Chen, Longyue Wang, Yong Zhang, Xintao Wang, Ying Shan, and Yujiu Yang. Talecrafter: Interactive story visualization with multiple characters. arXiv preprint arXiv:2305.18247, 2023
-
[26]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Svdiff: Compact parameter space for diffusion fine-tuning
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. Svdiff: Compact parameter space for diffusion fine-tuning. arXiv preprint arXiv:2303.11305, 2023
-
[28]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. NeurIPS, 33:6840– 6851, 2020
work page 2020
-
[29]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. Advances in Neural Information Processing Systems, 35:8633–8646, 2022
work page 2022
-
[30]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In ICLR, 2022. 11
work page 2022
-
[32]
Learning disentangled identifiers for action-customized text-to-image generation
Siteng Huang, Biao Gong, Yutong Feng, Xi Chen, Yuqian Fu, Yu Liu, and Donglin Wang. Learning disentangled identifiers for action-customized text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7797–7806, 2024
work page 2024
-
[33]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognit...
work page 2024
-
[34]
Reversion: Diffusion-based relation inversion from images
Ziqi Huang, Tianxing Wu, Yuming Jiang, Kelvin CK Chan, and Ziwei Liu. Reversion: Diffusion-based relation inversion from images. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[35]
Vmc: Video motion customization using temporal attention adaption for text-to-video diffusion models
Hyeonho Jeong, Geon Yeong Park, and Jong Chul Ye. Vmc: Video motion customization using temporal attention adaption for text-to-video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9212–9221, 2024
work page 2024
-
[36]
Pomp: Physics-consistent motion generative model through phase manifolds
Bin Ji, Ye Pan, Zhimeng Liu, Shuai Tan, Xiaogang Jin, and Xiaokang Yang. Pomp: Physics-consistent motion generative model through phase manifolds. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22690–22701, 2025
work page 2025
-
[37]
Sport: From zero-shot prompts to real-time motion generation
Bin Ji, Ye Pan, Zhimeng Liu, Shuai Tan, and Xiaokang Yang. Sport: From zero-shot prompts to real-time motion generation. IEEE Transactions on Visualization and Computer Graphics, 2025
work page 2025
-
[38]
Stylevr: Stylizing character animations with normalizing flows
Bin Ji, Ye Pan, Yichao Yan, Ruizhao Chen, and Xiaokang Yang. Stylevr: Stylizing character animations with normalizing flows. IEEE Transactions on Visualization and Computer Graphics, 2023
work page 2023
-
[39]
Chan, Yandong Li, Han Zhang, Boqing Gong, Tingbo Hou, Huisheng Wang, and Yu-Chuan Su
Xuhui Jia, Yang Zhao, Kelvin C.K. Chan, Yandong Li, Han Zhang, Boqing Gong, Tingbo Hou, Huisheng Wang, and Yu-Chuan Su. Taming encoder for zero fine-tuning image customization with text-to-image diffusion. 2023
work page 2023
-
[40]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. arXiv preprint arXiv:2210.09276, 2022
-
[41]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Divya Kothandaraman, Kuldeep Kulkarni, Sumit Shekhar, Balaji Vasan Srinivasan, and Dinesh Manocha. Imposter: Text and frequency guidance for subject driven action personalization using diffusion models. arXiv preprint arXiv:2409.15650, 2024
-
[43]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. arXiv preprint arXiv:2212.04488, 2022
-
[44]
PKU-Yuan Lab and Tuzhan AI etc. Open-sora-plan, April 2024
work page 2024
-
[45]
Dongxu Li, Junnan Li, and Steven CH Hoi. Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing. arXiv preprint arXiv:2305.14720, 2023
-
[46]
Generate anything anywhere in any scene
Yuheng Li, Haotian Liu, Yangming Wen, and Yong Jae Lee. Generate anything anywhere in any scene. arXiv preprint arXiv:2306.17154, 2023
-
[47]
Fan Lu, Wei Wu, Kecheng Zheng, Shuailei Ma, Biao Gong, Jiawei Liu, Wei Zhai, Yang Cao, Yujun Shen, and Zheng-Jun Zha. Benchmarking large vision-language models via directed scene graph for comprehensive image captioning. CVPR 2025, 2025
work page 2025
-
[48]
Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning
Jian Ma, Junhao Liang, Chen Chen, and Haonan Lu. Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning. arXiv preprint arXiv:2307.11410, 2023
-
[49]
Motionflow: Attention- driven motion transfer in video diffusion models
Tuna Han Salih Meral, Hidir Yesiltepe, Connor Dunlop, and Pinar Yanardag. Motionflow: Attention- driven motion transfer in video diffusion models. arXiv preprint arXiv:2412.05275, 2024
- [50]
-
[51]
OpenAI. GPT-4 technical report. ArXiv, abs/2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Ye Pan, Chang Liu, Sicheng Xu, Shuai Tan, and Jiaolong Yang. Vasa-rig: Audio-driven 3d facial animation with ‘live’mood dynamics in virtual reality.IEEE Transactions on Visualization and Computer Graphics, 2025. 12
work page 2025
-
[53]
Ye Pan, Shuai Tan, Shengran Cheng, Qunfen Lin, Zijiao Zeng, and Kenny Mitchell. Expressive talking avatars. IEEE Transactions on Visualization and Computer Graphics, 2024
work page 2024
-
[54]
Ye Pan, Ruisi Zhang, Shengran Cheng, Shuai Tan, Yu Ding, Kenny Mitchell, and Xubo Yang. Emotional voice puppetry. IEEE Transactions on Visualization and Computer Graphics, 29(5):2527–2535, 2023
work page 2023
-
[55]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[56]
Mos: Modeling object-scene associations in generalized category discovery
Zhengyuan Peng, Jinpeng Ma, Zhimin Sun, Ran Yi, Haichuan Song, Xin Tan, and Lizhuang Ma. Mos: Modeling object-scene associations in generalized category discovery. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 15118–15128, 2025
work page 2025
-
[57]
Generalized category discovery in semantic segmentation
Zhengyuan Peng, Qijian Tian, Jianqing Xu, Yizhang Jin, Xuequan Lu, Xin Tan, Yuan Xie, and Lizhuang Ma. Generalized category discovery in semantic segmentation. arXiv preprint arXiv:2311.11525, 2023
-
[58]
Hierarchical spatio-temporal decoupling for text-to-video generation
Zhiwu Qing, Shiwei Zhang, Jiayu Wang, Xiang Wang, Yujie Wei, Yingya Zhang, Changxin Gao, and Nong Sang. Hierarchical spatio-temporal decoupling for text-to-video generation. arXiv preprint arXiv:2312.04483, 2023
-
[59]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763, 2021
work page 2021
-
[60]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[61]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, pages 10684–10695, 2022
work page 2022
-
[63]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. arXiv preprint arXiv:2208.12242, 2022
-
[64]
Hyperdreambooth: Hypernetworks for fast personalization of text-to- image models
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Wei Wei, Tingbo Hou, Yael Pritch, Neal Wadhwa, Michael Rubinstein, and Kfir Aberman. Hyperdreambooth: Hypernetworks for fast personalization of text-to- image models. In CVPR, 2024
work page 2024
-
[65]
Photorealistic text-to- image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding. NeurIPS, 35:36479–36494, 2022
work page 2022
-
[66]
D She, Mushui Liu, Jingxuan Pang, Jin Wang, Zhen Yang, Wanggui He, Guanghao Zhang, Yi Wang, Qihan Huang, Haobin Tang, et al. Customvideox: 3d reference attention driven dynamic adaptation for zero-shot customized video diffusion transformers. arXiv preprint arXiv:2502.06527, 2025
-
[67]
Relationbooth: Towards relation-aware customized object generation
Qingyu Shi, Lu Qi, Jianzong Wu, Jinbin Bai, Jingbo Wang, Yunhai Tong, Xiangtai Li, and Ming- Husan Yang. Relationbooth: Towards relation-aware customized object generation. arXiv preprint arXiv:2410.23280, 2024
-
[68]
Shuwei Shi, Biao Gong, Xi Chen, Dandan Zheng, Shuai Tan, Zizheng Yang, Yuyuan Li, Jingwen He, Kecheng Zheng, Jingdong Chen, et al. Motionstone: Decoupled motion intensity modulation with diffusion transformer for image-to-video generation. CVPR 2025, 2025
work page 2025
-
[69]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. ICLR, 2023
work page 2023
-
[70]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In ICLR, 2021
work page 2021
-
[71]
Stable Diffusion 2.0 Release, 2022
stability.ai. Stable Diffusion 2.0 Release, 2022. 13
work page 2022
-
[72]
Hunyuan-large: An open-source moe model with 52 billion activated parameters by tencent, 2024
Xingwu Sun, Yanfeng Chen, Yiqing Huang, Ruobing Xie, Jiaqi Zhu, Kai Zhang, Shuaipeng Li, Zhen Yang, Jonny Han, Xiaobo Shu, Jiahao Bu, Zhongzhi Chen, Xuemeng Huang, Fengzong Lian, Saiyong Yang, Jianfeng Yan, Yuyuan Zeng, Xiaoqin Ren, Chao Yu, Lulu Wu, Yue Mao, Tao Yang, Suncong Zheng, Kan Wu, Dian Jiao, Jinbao Xue, Xipeng Zhang, Decheng Wu, Kai Liu, Dengpe...
work page 2024
-
[73]
Mimir: Improving video diffusion models for precise text understanding
Shuai Tan, Biao Gong, Yutong Feng, Kecheng Zheng, Dandan Zheng, Shuwei Shi, Yujun Shen, Jingdong Chen, and Ming Yang. Mimir: Improving video diffusion models for precise text understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 23978–23988, 2025
work page 2025
-
[74]
Animate-x: Universal character image animation with enhanced motion representation
Shuai Tan, Biao Gong, Xiang Wang, Shiwei Zhang, Dandan Zheng, Ruobing Zheng, Kecheng Zheng, Jingdong Chen, and Ming Yang. Animate-x: Universal character image animation with enhanced motion representation. In ICLR 2025, 2025
work page 2025
-
[75]
Edtalk: Efficient disentanglement for emotional talking head synthesis
Shuai Tan, Bin Ji, Mengxiao Bi, and Ye Pan. Edtalk: Efficient disentanglement for emotional talking head synthesis. In European Conference on Computer Vision, pages 398–416. Springer, 2025
work page 2025
-
[76]
Shuai Tan, Bin Ji, Yu Ding, and Ye Pan. Say anything with any style. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5088–5096, 2024
work page 2024
-
[77]
Emmn: Emotional motion memory network for audio-driven emotional talking face generation
Shuai Tan, Bin Ji, and Ye Pan. Emmn: Emotional motion memory network for audio-driven emotional talking face generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22146–22156, 2023
work page 2023
-
[78]
Shuai Tan, Bin Ji, and Ye Pan. Flowvqtalker: High-quality emotional talking face generation through normalizing flow and quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26317–26327, 2024
work page 2024
-
[79]
Style2talker: High-resolution talking head generation with emotion style and art style
Shuai Tan, Bin Ji, and Ye Pan. Style2talker: High-resolution talking head generation with emotion style and art style. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5079–5087, 2024
work page 2024
-
[80]
Genmo Team. Mochi 1. https://github.com/genmoai/models, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.