mGRADE: Minimal Recurrent Gating Meets Delay Convolutions for Lightweight Sequence Modeling
Pith reviewed 2026-05-19 05:48 UTC · model grok-4.3
The pith
mGRADE combines learnable delay embeddings with minimal gated recurrence to model fast and slow sequence dynamics inside a fixed memory budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
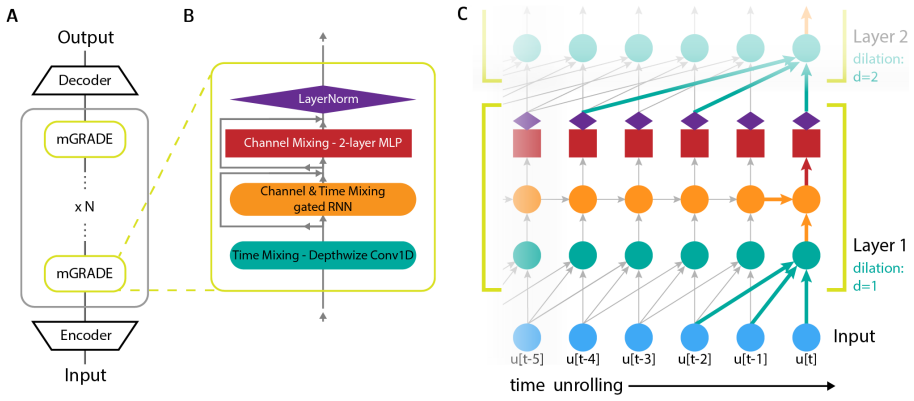
mGRADE integrates a convolution with learnable temporal spacings, proven equivalent to a delay embedding, and a minimally gated recurrent component; this combination reconstructs fast dynamics parameter-efficiently while selectively retaining long-range context, all within a constant memory footprint that is up to eight times smaller than existing models on long-range tasks.
What carries the argument
The learnable temporal spacings inside the delay convolution, shown to be equivalent to a delay embedding that enables parameter-efficient reconstruction of fast dynamics, together with the minimal gated recurrent unit that maintains long-range context.
If this is right
- Models can now handle both fast local dynamics and slow global context without expanding memory footprint.
- Parameter count for fast-dynamics reconstruction drops because the delay-embedding equivalence removes the need for explicit high-dimensional state.
- Long-range selectivity is preserved by the gated recurrent unit while memory overhead stays near-constant.
- The architecture scales to edge-device constraints where prior constant-memory models had to sacrifice either speed or range.
Where Pith is reading between the lines
- Similar delay-convolution plus minimal-gating blocks could be inserted into existing transformers to reduce their KV-cache size on long sequences.
- The equivalence to delay embeddings suggests analytic stability bounds might be derivable for the combined system.
- On streaming sensor data the same inductive bias could allow accurate reconstruction from sparse, irregularly timed observations.
Load-bearing premise
The theoretical equivalence between learnable temporal spacings and delay embeddings will produce real gains in reconstruction accuracy and memory use without hidden costs to training stability or generalization on real data.
What would settle it
An experiment on the Long-Range Arena where mGRADE either exceeds the memory budget of competing models or shows clearly lower accuracy when both are forced to the same small memory limit.
Figures



read the original abstract
Multi-timescale sequence modeling relies on capturing both local fast dynamics and global slow context; yet, maintaining these capabilities under the strict memory constraints common to edge devices remains an open challenge. Current State-of-the-Art models with constant memory footprints trade off long-range selectivity and high-precision modeling of fast dynamics. To overcome this trade-off within a fixed memory budget, we propose mGRADE (minimally Gated Recurrent Architecture with Delay Embedding), a hybrid-memory system that introduces inductive biases across timescales by integrating a convolution with learnable temporal spacings with a lightweight gated recurrent component. We show theoretically that the learnable spacings are equivalent to a delay embedding, enabling parameter-efficient reconstruction of partially-observed fast dynamics, while the gated recurrent component selectively maintains long-range context with minimal memory overhead. On the challenging Long-Range Arena benchmark and 35-way Google Speech Commands raw audio classification task, mGRADE reduces the memory footprint by up to a factor of 8 compared to other State-of-the-Art models, while maintaining competitive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces mGRADE, a hybrid sequence model that pairs a convolution with learnable temporal spacings and a lightweight gated recurrent component. It asserts a theoretical equivalence between the learnable spacings and delay embeddings that enables parameter-efficient reconstruction of partially observed fast dynamics, while the recurrent gate maintains long-range context under tight memory budgets. Competitive accuracy is reported on the Long-Range Arena benchmark and the 35-way Google Speech Commands raw-audio task, together with up to 8× memory reduction relative to prior constant-memory SOTA models.
Significance. If the claimed equivalence is rigorously established and the reconstruction benefit is observable in practice, the architecture could meaningfully advance memory-constrained multi-timescale modeling. The hybrid inductive bias directly targets a recognized trade-off between long-range selectivity and high-precision fast dynamics. The absence of a derivation, ablation evidence, and direct reconstruction metrics, however, leaves the central efficiency argument unverified at present.
major comments (2)
- [Abstract / §3] Abstract and §3 (theoretical claim): the statement that 'the learnable spacings are equivalent to a delay embedding' is presented as a theoretical result enabling parameter-efficient reconstruction, yet no derivation, proof sketch, or set of embedding conditions (dimension, separation, attractor coverage) is supplied. Because this equivalence is load-bearing for the headline memory-efficiency argument, its absence prevents assessment of whether the learned spacings satisfy the necessary conditions or merely approximate them.
- [§4] §4 (experiments): only end-task accuracy and memory footprint are reported on LRA and Speech Commands. No ablation isolating the delay-embedding component, no error bars across random seeds, and no direct reconstruction-error measurements on partially observed trajectories are provided. Without these, it is impossible to confirm that the theoretical equivalence yields measurable reconstruction gains rather than incidental performance.
minor comments (2)
- [Title / Abstract] The acronym expansion in the title ('Minimal Recurrent Gating Meets Delay Convolutions') differs slightly from the abstract ('minimally Gated Recurrent Architecture with Delay Embedding'); a consistent expansion would improve clarity.
- [§2 / §3] Notation for the learnable spacings and the gated recurrent state should be introduced once with explicit dimensions and update equations to avoid ambiguity when the two components are combined.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major point below, clarifying the theoretical equivalence and committing to strengthened experimental validation in the revision.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (theoretical claim): the statement that 'the learnable spacings are equivalent to a delay embedding' is presented as a theoretical result enabling parameter-efficient reconstruction, yet no derivation, proof sketch, or set of embedding conditions (dimension, separation, attractor coverage) is supplied. Because this equivalence is load-bearing for the headline memory-efficiency argument, its absence prevents assessment of whether the learned spacings satisfy the necessary conditions or merely approximate them.
Authors: We agree that an explicit derivation strengthens the central claim. Section 3 derives the equivalence by showing that convolution kernels with learnable spacings implement a non-uniform delay embedding: each output channel samples the input at a learned offset, reconstructing the unobserved fast state from partial observations under the conditions of Takens' theorem (sufficient embedding dimension and separation). We will add a concise proof sketch, the precise embedding-dimension bound, and a statement of the attractor-coverage assumption to §3 in the revision. revision: yes
-
Referee: [§4] §4 (experiments): only end-task accuracy and memory footprint are reported on LRA and Speech Commands. No ablation isolating the delay-embedding component, no error bars across random seeds, and no direct reconstruction-error measurements on partially observed trajectories are provided. Without these, it is impossible to confirm that the theoretical equivalence yields measurable reconstruction gains rather than incidental performance.
Authors: We accept that additional controls are needed. In the revision we will report mean and standard deviation over five random seeds for all LRA and Speech Commands results. We will also add an ablation that replaces learnable spacings with fixed uniform spacings while keeping the gated recurrent component unchanged, thereby isolating the delay-embedding contribution. Direct reconstruction error on synthetic partially observed trajectories will be included in an appendix to quantify the practical benefit of the equivalence. revision: yes
Circularity Check
Derivation chain is self-contained with no reduction to fitted inputs or self-citations
full rationale
The central theoretical claim is that learnable temporal spacings in the convolution are equivalent to a delay embedding, shown as a general mathematical result rather than derived from or fitted to the experimental outcomes. This equivalence is invoked to explain parameter efficiency for fast dynamics reconstruction, but the paper does not define the spacings in terms of the embedding or vice versa, nor does it rename a fitted quantity as a prediction. Benchmarks on LRA and Speech Commands report end-task metrics independently of any self-referential proof. No load-bearing step reduces by construction to the inputs; the derivation remains independent of the specific learned values and does not rely on self-citation chains for uniqueness or ansatz.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable temporal spacings
axioms (1)
- domain assumption Learnable spacings in convolution are mathematically equivalent to a delay embedding
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show theoretically that the learnable spacings are equivalent to a delay embedding, enabling parameter-efficient reconstruction of partially-observed fast dynamics
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
mGRADE-L stores the value after the last w in one part of its hidden state while the other merely reproduces the input. Learnable delays trigger updates...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
o ppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael K Kopp, G \
Maximilian Beck, Korbinian P \"o ppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael K Kopp, G \"u nter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. x LSTM : Extended long short-term memory. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=ARAxPPIAhq
work page 2024
-
[2]
Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5 0 (2): 0 157--166, 1994. doi:10.1109/72.279181
-
[3]
On the A bility and L imitations of T ransformers to R ecognize F ormal L anguages
Satwik Bhattamishra, Kabir Ahuja, and Navin Goyal. On the A bility and L imitations of T ransformers to R ecognize F ormal L anguages. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors, Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7096--7116, Online, November 2020. Association for Compu...
-
[4]
Sebastian Billaudelle, Laura Kriener, Filippo Moro, Tristan Torchet, and Melika Payvand. Minimalist: switched-capacitor circuits for efficient in-memory computation of gated recurrent units, 2025. URL https://arxiv.org/abs/2505.08599
- [5]
-
[6]
Quasi-recurrent neural networks
James Bradbury, Stephen Merity, Caiming Xiong, and Richard Socher. Quasi-recurrent neural networks. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=H1zJ-v5xl
work page 2017
-
[7]
JAX : composable transformations of P ython+ N um P y programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake Vander P las, Skye Wanderman- M ilne, and Qiao Zhang. JAX : composable transformations of P ython+ N um P y programs, 2018. URL http://github.com/jax-ml/jax
work page 2018
-
[8]
Learning phrase representations using RNN encoder– decoder for statistical machine translation
Kyunghyun Cho, Bart van Merri \"e nboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder -- decoder for statistical machine translation. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors, Proceedings of the 2014 Conference on Empirical Methods in Natural ...
-
[9]
Empirical evaluation of gated recurrent neural networks on sequence modeling
Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. In NIPS 2014 Workshop on Deep Learning, December 2014, 2014
work page 2014
-
[10]
Tri Dao, Daniel Y. Fu, Khaled Kamal Saab, Armin W. Thomas, Atri Rudra, and Christopher R \' e . Hungry hungry hippos: Towards language modeling with state space models. CoRR, abs/2212.14052, 2022. doi:10.48550/arXiv.2212.14052. URL https://doi.org/10.48550/arXiv.2212.14052
-
[11]
Were RNN s all we needed?, 2025
Leo Feng, Frederick Tung, Mohamed Osama Ahmed, Yoshua Bengio, and Hossein Hajimirsadeghi. Were RNN s all we needed?, 2025. URL https://openreview.net/forum?id=GrmFFxGnOR
work page 2025
-
[12]
Learning to forget: Continual prediction with lstm
Felix A. Gers, J \" u rgen Schmidhuber, and Fred A. Cummins. Learning to forget: Continual prediction with LSTM . Neural Comput., 12 0 (10): 0 2451--2471, 2000. doi:10.1162/089976600300015015. URL https://doi.org/10.1162/089976600300015015
-
[13]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher R\'e. Efficiently modeling long sequences with structured state spaces. In The International Conference on Learning Representations ( ICLR ) , 2022
work page 2022
-
[14]
Learning delays in spiking neural networks using dilated convolutions with learnable spacings
Ilyass Hammouamri, Ismail Khalfaoui-Hassani, and Timoth \'e e Masquelier. Learning delays in spiking neural networks using dilated convolutions with learnable spacings. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=4r2ybzJnmN
work page 2024
-
[15]
Dilated convolution with learnable spacings
Ismail Khalfaoui Hassani, Thomas Pellegrini, and Timoth \'e e Masquelier. Dilated convolution with learnable spacings. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Q3-1vRh3HOA
work page 2023
-
[16]
F lax: A neural network library and ecosystem for JAX , 2024
Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Z ee. F lax: A neural network library and ecosystem for JAX , 2024. URL http://github.com/google/flax
work page 2024
-
[17]
Sepp Hochreiter and J \"u rgen Schmidhuber. Long short-term memory. Neural computation, 9 0 (8): 0 1735--1780, 1997
work page 1997
-
[18]
Generalizations across filler-gap dependencies in neural language models
Katherine Howitt, Sathvik Nair, Allison Dods, and Robert Melvin Hopkins. Generalizations across filler-gap dependencies in neural language models. In Libby Barak and Malihe Alikhani, editors, Proceedings of the 28th Conference on Computational Natural Language Learning, pages 269--279, Miami, FL, USA, November 2024. Association for Computational Linguisti...
-
[19]
Rob J. Hyndman and Anne B. Koehler. Another look at measures of forecast accuracy. International Journal of Forecasting, 22 0 (4): 0 679--688, 2006. ISSN 0169-2070. doi:https://doi.org/10.1016/j.ijforecast.2006.03.001. URL https://www.sciencedirect.com/science/article/pii/S0169207006000239
-
[20]
Learning delays in spiking neural networks using dilated convolutions with learnable spacings
Ismail Khalfaoui-Hassani, Thomas Pellegrini, and Timoth \'e e Masquelier. Learning delays in spiking neural networks using dilated convolutions with learnable spacings. In Differentiable Almost Everything Workshop of the 40-th International Conference on Machine Learning, 2023. URL https://arxiv.org/abs/2306.00817
-
[21]
Algebraic theory of machines, 1965
Kenneth Krohn and John Rhodes. Algebraic theory of machines, 1965
work page 1965
-
[22]
MNIST handwritten digit database
Yann LeCun and Corinna Cortes. MNIST handwritten digit database. 2010. URL http://yann.lecun.com/exdb/mnist/
work page 2010
-
[23]
Yuhong Li, Tianle Cai, Yi Zhang, Deming Chen, and Debadeepta Dey. What makes convolutional models great on long sequence modeling? In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=TGJSPbRpJX-
work page 2023
-
[24]
Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang
Bingbin Liu, Jordan T. Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Exposing attention glitches with flip-flop language modeling. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=VzmpXQAn6E
work page 2023
-
[25]
Deterministic nonperiodic flow
Edward Norton Lorenz. Deterministic nonperiodic flow. Journal of the Atmospheric Sciences, 20: 0 130–141, 1963
work page 1963
-
[26]
Parallelizing linear recurrent neural nets over sequence length
Eric Martin and Chris Cundy. Parallelizing linear recurrent neural nets over sequence length. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings . OpenReview.net, 2018. URL https://openreview.net/forum?id=HyUNwulC-
work page 2018
-
[27]
Context dependent recurrent neural network language model
Tomas Mikolov and Geoffrey Zweig. Context dependent recurrent neural network language model. In 2012 IEEE Spoken Language Technology Workshop (SLT), pages 234--239, 2012. doi:10.1109/SLT.2012.6424228
-
[28]
Neural net architectures for temporal sequence processing
Michael Mozer. Neural net architectures for temporal sequence processing. Santa Fe Institute Studies in The Sciences of Complexity, 15: 0 243--243, 03 1993
work page 1993
-
[29]
Resurrecting recurrent neural networks for long sequences, 2023
Antonio Orvieto, Samuel L. Smith, Albert Gu, Anushan Fernando, C aglar G \" u l c ehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. CoRR, abs/2303.06349, 2023. doi:10.48550/arXiv.2303.06349. URL https://doi.org/10.48550/arXiv.2303.06349
-
[30]
Antonio Orvieto, Soham De, Caglar Gulcehre, Razvan Pascanu, and Samuel L. Smith. Universality of linear recurrences followed by non-linear projections: Finite-width guarantees and benefits of complex eigenvalues. In ICML, 2024. URL https://openreview.net/forum?id=47ahBl70xb
work page 2024
-
[31]
Delay embedding theory of neural sequence models
Mitchell Ostrow, Adam Eisen, and Ila Fiete. Delay embedding theory of neural sequence models. 2024. URL https://arxiv.org/abs/2406.11993v1
-
[32]
Regularization and nonlinearities for neural language models: when are they needed?
Marius Pachitariu and Maneesh Sahani. Regularization and nonlinearities for neural language models: when are they needed?, 2013. URL https://arxiv.org/abs/1301.5650
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[33]
Hierarchically gated recurrent neural network for sequence modeling
Zhen Qin, Songlin Yang, and Yiran Zhong. Hierarchically gated recurrent neural network for sequence modeling. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, ...
work page 2023
-
[34]
The expressive capacity of state space models: A formal language perspective
Yash Sarrof, Yana Veitsman, and Michael Hahn. The expressive capacity of state space models: A formal language perspective. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=eV5YIrJPdy
work page 2024
-
[35]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[36]
Large language models can be easily distracted by irrelevant context
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Sch\" a rli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. In Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org, 2023
work page 2023
-
[37]
12.4 Chemical chaos and attractor reconstruction
Steven Strogatz. 12.4 Chemical chaos and attractor reconstruction. CRC Press, 2015
work page 2015
-
[38]
Detecting strange attractors in turbulence
Floris Takens. Detecting strange attractors in turbulence. Dynamical Systems and Turbulence, Lecture Notes in Mathematics, 898: 0 366–381, 1981
work page 1981
-
[39]
Eugene Tan, Shannon Algar, Débora Corrêa, Michael Small, Thomas Stemler, and David Walker. Selecting embedding delays: An overview of embedding techniques and a new method using persistent homology. Chaos: An Interdisciplinary Journal of Nonlinear Science, 33 0 (3): 0 032101, 03 2023. ISSN 1054-1500. doi:10.1063/5.0137223. URL https://doi.org/10.1063/5.0137223
-
[40]
Long range arena : A benchmark for efficient transformers
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena : A benchmark for efficient transformers. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021. URL https://openreview.net...
work page 2021
-
[41]
WaveNet: A Generative Model for Raw Audio
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio, 2016. URL https://arxiv.org/abs/1609.03499
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL http...
work page 2017
-
[43]
A. Waibel, T. Hanazawa, G. Hinton, K. Shikano, and K.J. Lang. Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, 37 0 (3): 0 328--339, 1989. doi:10.1109/29.21701
-
[44]
Ethan Wilcox, Roger Levy, Takashi Morita, and Richard Futrell. What do RNN language models learn about filler -- gap dependencies? In Tal Linzen, Grzegorz Chrupa a, and Afra Alishahi, editors, Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP , pages 211--221, Brussels, Belgium, November 2018. Associ...
-
[45]
Masked feature prediction for self-supervised visual pre-training
Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. Metaformer is actually what you need for vision. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 , pages 10809--10819. IEEE , 2022. doi:10.1109/CVPR52688.2022.01055. URL https://doi.org/1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.