Variational Kolmogorov-Arnold Network
Pith reviewed 2026-05-19 05:46 UTC · model grok-4.3
The pith
InfinityKAN learns the number of basis functions in Kolmogorov-Arnold Networks automatically during training as a latent variable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present InfinityKAN, a variational inference framework that models the number of basis functions as a latent variable with a truncated exponential prior and introduces a differentiable weighting function that permits gradient-based optimization of this count. We establish the Lipschitz continuity of the variational objective to guarantee stable training dynamics. Experiments across 18 datasets in synthetic, image, tabular, and graph domains show that InfinityKAN matches or exceeds the performance of standard KANs without requiring manual selection of the number of bases for each layer.
What carries the argument
Variational inference treating basis count as a latent variable with truncated exponential prior, together with a differentiable weighting function that enables joint gradient optimization of capacity and weights.
If this is right
- Model capacity becomes a learned quantity rather than a fixed hyperparameter chosen before training.
- Gradient-based optimization can jointly adjust both network weights and the effective number of basis functions.
- Stable training is supported by the established Lipschitz continuity of the objective.
- Performance comparable to or better than manually tuned KANs is achieved across synthetic, image, tabular, and graph tasks without per-layer tuning.
Where Pith is reading between the lines
- The same latent-variable treatment of capacity could be transferred to other architectures where layer widths or feature counts are currently chosen by hand.
- The posterior distributions over learned basis counts may reveal how intrinsic complexity differs across data modalities.
- Alternative priors on the latent count or task-dependent regularization of the weighting function could further improve adaptation speed or final accuracy.
Load-bearing premise
The variational approximation using the truncated exponential prior on the latent basis count faithfully captures the posterior and produces a stable optimum without uncorrectable bias from the prior or weighting function.
What would settle it
A controlled experiment on additional datasets in which InfinityKAN consistently underperforms KANs whose basis counts were chosen by exhaustive search, or in which the learned counts vary sharply across random seeds, would show that the variational mechanism fails to identify suitable capacity.
Figures











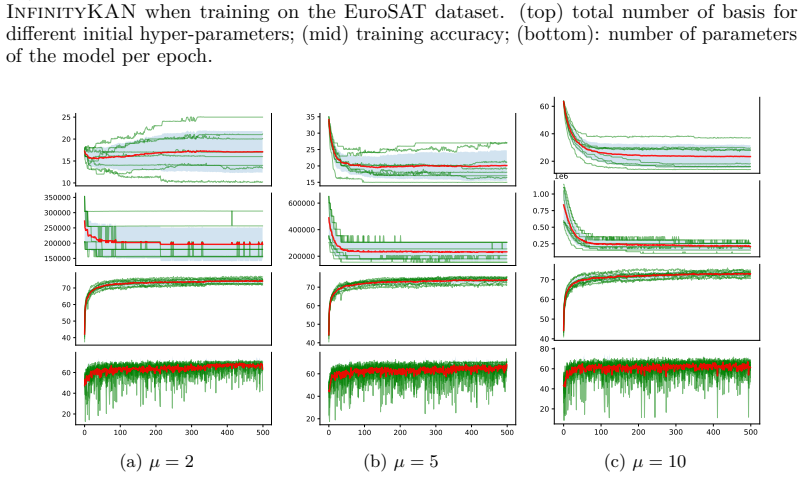











read the original abstract
Kolmogorov-Arnold Networks (KANs) offer a theoretically grounded alternative to multi-layer perceptrons by representing multivariate functions as compositions of univariate basis functions. However, a critical limitation of KANs is the need to manually specify the number of basis functions per layer -- a hyperparameter that directly controls model capacity and substantially impacts performance, yet whose optimal value varies unpredictably across tasks. We present InfinityKAN, a variational inference framework that eliminates this design choice by learning the number of basis functions during training. Our approach models the basis count as a latent variable with a truncated exponential prior, introducing a differentiable weighting function that enables gradient-based optimization. We establish the Lipschitz continuity of the variational objective, ensuring stable training dynamics. Experiments across 18 datasets spanning synthetic, image, tabular, and graph domains demonstrate that InfinityKAN matches or exceeds the performance of KANs while requiring no manual selection of the number of bases for each layer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InfinityKAN, a variational inference framework for Kolmogorov-Arnold Networks that models the number of basis functions per layer as a latent variable equipped with a truncated exponential prior. A differentiable weighting function is proposed to enable gradient-based optimization of this discrete count, thereby removing the need for manual hyperparameter selection. The authors establish Lipschitz continuity of the resulting variational objective and report that the method matches or exceeds the performance of standard KANs across 18 datasets spanning synthetic, image, tabular, and graph domains.
Significance. If the variational construction reliably recovers task-appropriate basis counts without substantial bias from the prior or the continuous relaxation, the work would meaningfully reduce the practical burden of capacity tuning in KANs. The multi-domain experimental results provide preliminary support for usability, and the Lipschitz-continuity claim is a positive technical contribution that could aid stable training. However, the overall significance hinges on whether the learned counts demonstrably outperform or match carefully tuned fixed baselines rather than simply reflecting a convenient default capacity.
major comments (2)
- [Abstract and variational objective] Abstract and variational objective section: the claim that the truncated exponential prior together with the differentiable weighting function yields task-optimal basis counts (rather than prior-driven or degenerate solutions) is load-bearing for the central contribution. Because the count is discrete, the weighting function is necessarily an approximation; the exponential prior further biases toward smaller values. It is unclear whether the ELBO fully corrects this bias or whether gradient artifacts remain, and no direct diagnostic (e.g., posterior vs. prior comparison or ablation against oracle-tuned fixed counts) is provided to confirm unbiased recovery of optimal capacity.
- [Experiments] Experiments section: performance is reported to match or exceed KANs on 18 datasets, yet the manuscript provides neither error bars, details on how the variational objective is optimized in practice, nor an ablation that isolates the effect of the learned counts versus a reasonable fixed default. Without these, it is difficult to determine whether the method truly eliminates manual selection or merely substitutes one form of capacity choice for another.
minor comments (1)
- [Method] Notation for the differentiable weighting function and its relation to the truncated exponential prior could be made more explicit to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript introducing InfinityKAN. We address each of the major comments below and indicate the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and variational objective] Abstract and variational objective section: the claim that the truncated exponential prior together with the differentiable weighting function yields task-optimal basis counts (rather than prior-driven or degenerate solutions) is load-bearing for the central contribution. Because the count is discrete, the weighting function is necessarily an approximation; the exponential prior further biases toward smaller values. It is unclear whether the ELBO fully corrects this bias or whether gradient artifacts remain, and no direct diagnostic (e.g., posterior vs. prior comparison or ablation against oracle-tuned fixed counts) is provided to confirm unbiased recovery of optimal capacity.
Authors: We agree that demonstrating the recovery of task-optimal basis counts is central to our contribution. The truncated exponential prior does bias towards smaller counts, but the variational posterior is optimized to maximize the ELBO, which incorporates the data likelihood and can thus shift the distribution away from the prior when beneficial for the task. The differentiable weighting function approximates the discrete selection in a way that allows gradients to flow, and we have proven Lipschitz continuity to ensure stable training. To directly address concerns about bias and approximation quality, we will revise the manuscript to include: (i) visualizations and quantitative comparisons of the learned posterior distributions versus the prior for representative datasets, and (ii) an ablation study comparing InfinityKAN performance to KANs with fixed basis counts tuned via oracle search on a validation set. These additions will provide evidence on whether the method recovers optimal capacities without substantial bias. revision: yes
-
Referee: [Experiments] Experiments section: performance is reported to match or exceed KANs on 18 datasets, yet the manuscript provides neither error bars, details on how the variational objective is optimized in practice, nor an ablation that isolates the effect of the learned counts versus a reasonable fixed default. Without these, it is difficult to determine whether the method truly eliminates manual selection or merely substitutes one form of capacity choice for another.
Authors: We acknowledge the importance of these experimental details for validating the claims. In the revised version, we will add error bars computed from multiple independent runs with different random seeds to all performance tables and figures. We will also expand the experimental section with a detailed description of the optimization procedure for the variational objective, including the choice of optimizer, learning rate schedule, number of epochs, and any techniques used to handle the continuous relaxation. Furthermore, we will include an ablation study that compares InfinityKAN to standard KANs using a fixed default number of basis functions (e.g., the value commonly used in prior KAN literature or the median across our experiments). This will help isolate the benefits of learning the counts adaptively. We believe these changes will clarify that InfinityKAN effectively removes the need for manual per-task tuning. revision: yes
Circularity Check
Minor self-citation risk but central variational construction remains independent of prior author work
full rationale
The paper introduces a new variational inference framework (InfinityKAN) that treats basis count as a latent variable with a truncated exponential prior and a differentiable weighting function. This construction is presented as original and does not reduce by definition or by self-citation chain to any fitted quantity or ansatz from the authors' prior publications. The Lipschitz continuity claim and experimental results on 18 datasets are derived from the new ELBO and weighting mechanism rather than being forced by construction. A low-level self-citation risk exists for background KAN material but is not load-bearing for the central claim of automatic basis selection.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The variational objective remains Lipschitz continuous under the introduced weighting function.
- ad hoc to paper A truncated exponential prior on the number of basis functions is appropriate for modeling capacity across tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
models the basis count as a latent variable with a truncated exponential prior, introducing a differentiable weighting function w_λ(x) = (1 + e^{-βλ + βγ|x|})^{-1}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
A Practitioner's Guide to Kolmogorov-Arnold Networks
A systematic review of Kolmogorov-Arnold Networks that maps their relation to Kolmogorov superposition theory, MLPs, and kernels, examines basis-function design choices, summarizes performance advances, and supplies a...
Reference graph
Works this paper leans on
-
[1]
Geometric Kolmogorov-Arnold Superposition Theorem, 2025
Francesco Alesiani, Takashi Maruyama, Henrik Christiansen, and Viktor Zaverkin. Geometric Kolmogorov-Arnold Superposition Theorem, 2025. URL http://arxiv. org/abs/2502.16664
-
[2]
Wav-KAN: Wavelet Kolmogorov-Arnold networks,
Zavareh Bozorgasl and Hao Chen. Wav-kan: Wavelet kolmogorov-arnold networks, 2024. URL https://arxiv.org/abs/2405.12832. 9
-
[3]
Kolmogorov- arnold graph neural networks,
Gianluca De Carlo, Andrea Mastropietro, and Aris Anagnostopoulos. Kolmogorov-arnold graph neural networks, 2024. URLhttps://arxiv.org/abs/2406.18354
-
[4]
Federico Errica, Henrik Christiansen, Viktor Zaverkin, Takashi Maruyama, Mathias Niepert, and Francesco Alesiani. Adaptive message passing: A general framework to mitigate oversmoothing, oversquashing, and underreaching.arXiv preprint, 2024
work page 2024
-
[5]
Federico Errica, Henrik Christiansen, Viktor Zaverkin, Takashi Maruyama, Mathias Niepert, and Francesco Alesiani. Adaptive message passing: A general framework to mitigate oversmoothing, oversquashing, and underreaching. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
work page 2025
-
[6]
Adaptive width neural networks, 2025
Federico Errica, Henrik Christiansen, Viktor Zaverkin, Mathias Niepert, and Francesco Alesiani. Adaptive width neural networks, 2025. URLhttps://arxiv.org/abs/2501. 15889
work page 2025
-
[7]
The cascade-correlation learning architecture
Scott Fahlman and Christian Lebiere. The cascade-correlation learning architecture. In Proceedings of the 3rd Conference on Neural Information Processing Systems (NIPS), 1989
work page 1989
-
[8]
Niles, Ken Pathak, and Steven Sloan
Md Meftahul Ferdaus, Mahdi Abdelguerfi, Elias Ioup, David Dobson, Kendall N. Niles, Ken Pathak, and Steven Sloan. KANICE: Kolmogorov-Arnold Networks with Interactive Convolutional Elements, October 2024
work page 2024
-
[9]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019
work page 2019
-
[10]
Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
work page 1989
-
[11]
EKAN: Equivariant Kolmogorov-Arnold Networks, October 2024
Lexiang Hu, Yisen Wang, and Zhouchen Lin. EKAN: Equivariant Kolmogorov-Arnold Networks, October 2024
work page 2024
-
[12]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational conference on machine learning, pages 448–456. pmlr, 2015
work page 2015
-
[13]
Kevin Jarrett, Koray Kavukcuoglu, Marc’Aurelio Ranzato, and Yann LeCun. What is the best multi-stage architecture for object recognition? In2009 IEEE 12th international conference on computer vision, pages 2146–2153. IEEE, 2009
work page 2009
-
[14]
An introduction to variational methods for graphical models.Machine learning, 37:183–233, 1999
Michael I Jordan, Zoubin Ghahramani, Tommi S Jaakkola, and Lawrence K Saul. An introduction to variational methods for graphical models.Machine learning, 37:183–233, 1999
work page 1999
-
[15]
American Mathematical Society, 1961
Andrei Nikolaevich Kolmogorov.On the representation of continuous functions of several variables by superpositions of continuous functions of a smaller number of variables. American Mathematical Society, 1961
work page 1961
-
[16]
On the training of a kolmogorov network
Mario Köppen. On the training of a kolmogorov network. InArtificial Neural Net- works—ICANN 2002: International Conference Madrid, Spain, August 28–30, 2002 Proceedings 12, pages 474–479. Springer, 2002
work page 2002
-
[17]
Vladik Kreinovich, Hung T. Nguyen, and David A. Sprecher. Normal Forms For Fuzzy Logic — An Application Of Kolmogorov’S Theorem.International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 04(04):331–349, August 1996. ISSN 0218-4885, 1793-6411. doi: 10.1142/S0218488596000196
-
[18]
Learning multiple layers of features from tiny images.Master’s thesis, University of Toronto, 2009
Alex Krizhevsky. Learning multiple layers of features from tiny images.Master’s thesis, University of Toronto, 2009. 10
work page 2009
-
[19]
Kolmogorov’s theorem and multilayer neural networks.Neural networks, 5(3):501–506, 1992
Věra K˘ urková. Kolmogorov’s theorem and multilayer neural networks.Neural networks, 5(3):501–506, 1992
work page 1992
-
[20]
A superposition theorem of Kolmogorov type for bounded continuous functions
Miklós Laczkovich. A superposition theorem of Kolmogorov type for bounded continuous functions. Journal of Approximation Theory, 269:105609, 2021
work page 2021
-
[21]
Ming-Jun Lai and Zhaiming Shen. The kolmogorov superposition theorem can break the curse of dimensionality when approximating high dimensional functions.arXiv preprint arXiv:2112.09963, 2021
-
[22]
The mnist database of handwritten digits.http://yann
Yann LeCun. The mnist database of handwritten digits.http://yann. lecun. com/exd- b/mnist/, 1998
work page 1998
-
[23]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y. Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks. (arXiv:2404.19756), June 2024. doi: 10.48550/arXiv.2404.19756. URLhttp://arxiv. org/abs/2404.19756. arXiv:2404.19756 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.19756 2024
-
[24]
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y. Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks, 2024
work page 2024
-
[25]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Self expanding neural networks
Rupert Mitchell, Martin Mundt, and Kristian Kersting. Self expanding neural networks. arXiv preprint, 2023
work page 2023
-
[27]
Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann
Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs. InICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020), 2020. URL www.graphlearning.io
work page 2020
-
[28]
Epi-ckans: Elasto-plasticity informed kolmogorov-arnold networks using chebyshev polynomials, 2024
Farinaz Mostajeran and Salah A Faroughi. Epi-ckans: Elasto-plasticity informed kolmogorov-arnold networks using chebyshev polynomials, 2024. URLhttps://arxiv. org/abs/2410.10897
-
[29]
Variational inference for infinitely deep neural networks
Achille Nazaret and David Blei. Variational inference for infinitely deep neural networks. In Proceedings of the 39th International Conference on Machine Learning (ICML), 2022
work page 2022
-
[30]
Tomaso Poggio. How deep sparse networks avoid the curse of dimensionality: Efficiently computable functions are compositionally sparse.CBMM Memo, 10:2022, 2022
work page 2022
-
[31]
A Survey on Kolmogorov-Arnold Network, November 2024
Shriyank Somvanshi, Syed Aaqib Javed, Md Monzurul Islam, Diwas Pandit, and Subasish Das. A Survey on Kolmogorov-Arnold Network, November 2024
work page 2024
-
[32]
Sidharth SS, Keerthana AR, Gokul R, and Anas KP. Chebyshev polynomial-based kolmogorov-arnold networks: An efficient architecture for nonlinear function approxima- tion, 2024. URL https://arxiv.org/abs/2405.07200
-
[33]
Splitting steepest descent for growing neural architectures
Lemeng Wu, Dilin Wang, and Qiang Liu. Splitting steepest descent for growing neural architectures. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[34]
Firefly neural architecture descent: a general approach for growing neural networks
Lemeng Wu, Bo Liu, Peter Stone, and Qiang Liu. Firefly neural architecture descent: a general approach for growing neural networks. InProceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS), volume 33, 2020
work page 2020
-
[35]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [36]
-
[37]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In7th International Conference on Learning Representations (ICLR), 2019
work page 2019
-
[38]
Are kan effective for identifying and tracking concept drift in time series?, 2024
Kunpeng Xu, Lifei Chen, and Shengrui Wang. Are kan effective for identifying and tracking concept drift in time series?, 2024. URLhttps://arxiv.org/abs/2410.10041
-
[39]
Kolmogorov-Arnold Transformer, September 2024
Xingyi Yang and Xinchao Wang. Kolmogorov-Arnold Transformer, September 2024
work page 2024
-
[40]
Lifelong learning with dynamically expandable networks
Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks. In6th International Conference on Learning Representations (ICLR), 2018. 12 A Supplementary Material of Variational Kolmogorov-Arnold Network B Theorems, Proofs, and Definitions Definition B.1. (Uniformly continuous function)f is uniformly co...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.