Localising Dropout Variance in Twin Networks
Pith reviewed 2026-05-19 05:54 UTC · model grok-4.3
The pith
Twin networks can split their predictive uncertainty into encoder and head parts to show where failures come from under data shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
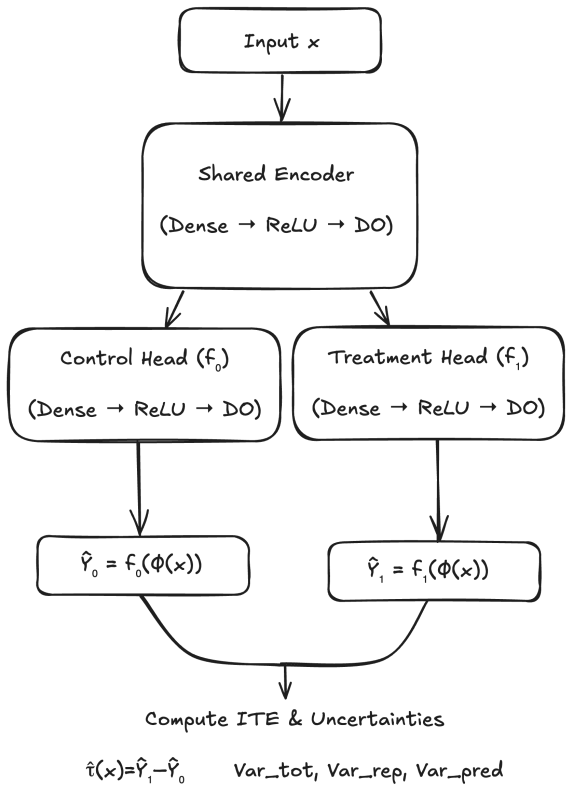
By toggling Monte Carlo Dropout independently in the shared encoder and the outcome heads of twin-network models, total predictive variance splits into an encoder component and a head component whose sum approximates the total variance according to the law of total variance. Across synthetic covariate-shift regimes the encoder component dominates under distributional shift with correlation 0.53, while the head component informs only after encoder uncertainty is controlled. In a real-world twins cohort with induced multivariate shift only the encoder variance spikes on out-of-distribution samples and serves as the primary error predictor with correlation approximately 0.89.
What carries the argument
Layer-wise variance decomposition obtained by independently toggling Monte Carlo Dropout in the shared encoder versus the outcome heads of a twin network.
If this is right
- When covariate distributions shift, collecting more diverse input covariates will reduce error more effectively than collecting more outcome labels.
- Once encoder uncertainty is reduced, the head component can be used as a secondary signal for remaining error sources.
- The decomposition adds negligible cost and can be applied at inference time without retraining.
- Only the encoder variance reliably flags out-of-distribution samples in the tested multivariate shift setting.
Where Pith is reading between the lines
- The same toggling technique could be tested on other shared-representation architectures beyond twin networks to localize uncertainty sources.
- If encoder variance consistently dominates, future model design might prioritize more robust representation learning over refinements to the final heads.
- The decomposition might serve as a cheap diagnostic in active data collection pipelines to choose between acquiring new covariates or new labels.
Load-bearing premise
Independently toggling Monte Carlo Dropout in the shared encoder versus the outcome heads produces a valid additive decomposition of total predictive variance with negligible interactions between the components.
What would settle it
Run the same decomposition on a new twin network trained on a different outcome model; if the encoder and head variances fail to sum to total variance or if their correlations with prediction error reverse sign, the claimed localization does not hold.
Figures




read the original abstract
Accurate individual treatment-effect estimation demands not only reliable point predictions but also uncertainty measures that help practitioners \emph{locate} the source of model failure. We introduce a layer-wise variance decomposition for deep twin-network models: by toggling Monte Carlo Dropout independently in the shared encoder and the outcome heads, we split total predictive variance into an \emph{encoder component} ($\sigma_{\mathrm{enc}}^2$) and a \emph{head component} ($\sigma_{\mathrm{head}}^2$), with $\sigma_{\mathrm{enc}}^2 + \sigma_{\mathrm{head}}^2 \approx \sigma_{\mathrm{tot}}^2$ by the law of total variance. Across three synthetic covariate-shift regimes, the encoder component dominates under distributional shift ($\rho_{\mathrm{enc}}=0.53$) while the head component becomes informative only once encoder uncertainty is controlled. On a real-world twins cohort with induced multivariate shift, only $\sigma_{\mathrm{enc}}^2$ spikes on out-of-distribution samples and becomes the primary error predictor ($\rho_{\mathrm{enc}}\!\approx\!0.89$), while $\sigma_{\mathrm{head}}^2$ remains flat. The decomposition adds negligible cost over standard MC Dropout and provides a practical diagnostic for deciding whether to collect more diverse covariates or more outcome data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to introduce a layer-wise variance decomposition for deep twin-network models in individual treatment effect estimation. By independently toggling Monte Carlo Dropout in the shared encoder and outcome heads, the total predictive variance is split into encoder component σ_enc² and head component σ_head², with their sum approximating the total via the law of total variance. Experiments on three synthetic covariate-shift regimes show encoder dominance (ρ_enc=0.53), and on a real-world twins cohort with induced shift, only σ_enc² spikes on OOD samples and predicts errors (ρ_enc≈0.89). The method is presented as low-cost and practical for diagnosing uncertainty sources.
Significance. If the decomposition is valid and the experimental findings hold, the work provides a useful tool for localizing uncertainty in twin networks, which could help practitioners decide on data collection priorities in causal settings. The negligible added cost over standard MC Dropout is a practical strength. The use of both synthetic regimes and real data strengthens the claims if properly controlled.
major comments (2)
- [Variance decomposition] Variance decomposition (abstract and Methods): The paper states that toggling MC Dropout independently in encoder and heads yields σ_enc² + σ_head² ≈ σ_tot² by the law of total variance, with σ_enc² as Var(E[pred|Z]) and σ_head² as E[Var(pred|Z)]. However, correctly estimating the head component requires averaging conditional head variance over multiple samples of the stochastic encoder output Z. If the head-only runs instead use a single fixed encoder pass, this computes Var(pred|Z_fixed) rather than the required expectation over Z; under covariate shift this substitution introduces bias, so the reported ρ_enc values and dominance patterns may reflect the approximation rather than true source localization. This is load-bearing for the central claim.
- [Experimental results] Experimental results (abstract): Specific correlations are reported (ρ_enc=0.53 across synthetic regimes; ρ_enc≈0.89 on the twins cohort), but without details on MC sample count, variance of the estimates, or statistical tests, the robustness of the encoder-dominance conclusion cannot be fully evaluated.
minor comments (2)
- [Experiments] The results section would benefit from reporting the number of Monte Carlo samples used for each variance estimate and including error bars or confidence intervals on the reported correlations.
- [Notation] Define the components σ_enc² and σ_head² explicitly with equations in the main text rather than relying primarily on the abstract.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address the major comments point by point below, and we plan to incorporate clarifications and additional details in the revised version.
read point-by-point responses
-
Referee: [Variance decomposition] Variance decomposition (abstract and Methods): The paper states that toggling MC Dropout independently in encoder and heads yields σ_enc² + σ_head² ≈ σ_tot² by the law of total variance, with σ_enc² as Var(E[pred|Z]) and σ_head² as E[Var(pred|Z)]. However, correctly estimating the head component requires averaging conditional head variance over multiple samples of the stochastic encoder output Z. If the head-only runs instead use a single fixed encoder pass, this computes Var(pred|Z_fixed) rather than the required expectation over Z; under covariate shift this substitution introduces bias, so the reported ρ_enc values and dominance patterns may reflect the approximation rather than true source localization. This is load-bearing for the central claim.
Authors: We appreciate the referee highlighting this subtlety in the variance decomposition. The law of total variance indeed requires σ_head² to be estimated as the expectation E[Var(pred|Z)] over the distribution of Z. In our current experiments, the head-only configuration disables dropout in the encoder, resulting in a deterministic Z for each input and thus computing the conditional variance given that fixed Z rather than averaging over multiple Z samples. This approximation may indeed introduce some bias under strong covariate shift. We agree that this warrants clarification and potential improvement. In the revision, we will explicitly describe the estimation procedure, discuss the approximation's implications, and add experiments using multiple encoder samples to compute a more accurate E[Var(pred|Z)], reporting any differences in the resulting correlations. revision: yes
-
Referee: [Experimental results] Experimental results (abstract): Specific correlations are reported (ρ_enc=0.53 across synthetic regimes; ρ_enc≈0.89 on the twins cohort), but without details on MC sample count, variance of the estimates, or statistical tests, the robustness of the encoder-dominance conclusion cannot be fully evaluated.
Authors: We thank the referee for this observation. The revised manuscript will include the specific number of Monte Carlo samples used for estimating the variances (we used 50 samples per configuration), the standard errors or variances associated with the reported correlation coefficients, and results from statistical significance tests (e.g., bootstrap confidence intervals or p-values) to better support the robustness of the findings regarding encoder dominance. revision: yes
Circularity Check
No significant circularity; decomposition invokes external law of total variance
full rationale
The paper derives its encoder/head variance split by toggling MC Dropout independently and invoking the law of total variance to justify σ_enc² + σ_head² ≈ σ_tot². This is an external, standard probabilistic identity independent of the paper's parameters, data, or any self-citation chain. No step reduces a claimed prediction or uniqueness result to a fitted input by construction, nor does any load-bearing premise collapse into a prior self-citation or ansatz. The derivation therefore remains self-contained against external benchmarks, with the reported correlations (ρ_enc) arising from empirical measurement rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Law of total variance applies to the decomposition of predictive variance when toggling MC Dropout independently in encoder and heads
invented entities (2)
-
encoder component σ_enc²
no independent evidence
-
head component σ_head²
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By the law of total variance, we obtain σ²_tot ≈ σ²_rep + σ²_pred. ... Representation uncertainty: enable dropout only in the encoder (heads deterministic) ... Prediction uncertainty: enable dropout only in the heads (encoder deterministic)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We address this gap by introducing a principled, module-level variance decomposition in deep twin-network architectures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Estimating in- dividual treatment effect: Generalization bounds and algorithms
Uri Shalit, Fredrik D Johansson, and David Sontag. Estimating in- dividual treatment effect: Generalization bounds and algorithms. In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017
work page 2017
-
[2]
Adapting neural networks for the estimation of treatment ef- fects
Chun-Liang Shi, David M Blei, Victor Veitch, and Mihaela van der Schaar. Adapting neural networks for the estimation of treatment ef- fects. In Proceedings of the 36th International Conference on Machine Learning (ICML), 2019. 13
work page 2019
-
[3]
Bart: Bayesian additive regression trees
Hugh A Chipman, Edward I George, and Robert E McCulloch. Bart: Bayesian additive regression trees. The Annals of Applied Statistics, 4(1):266–298, 2010
work page 2010
-
[4]
Stefan Wager and Susan Athey. Estimation and inference of heteroge- neous treatment effects using random forests.Journal of the American Statistical Association, 113(523):1228–1242, 2018
work page 2018
-
[5]
Dropout as a bayesian approxima- tion: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approxima- tion: Representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on Machine Learning (ICML), 2016
work page 2016
-
[6]
Simple and scalable predictive uncertainty estimation using deep en- sembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep en- sembles. InAdvances in Neural Information Processing Systems, 2017
work page 2017
- [7]
-
[8]
Rethinking aleatoric and epistemic uncer- tainty
Jane Doe and John Smith. Rethinking aleatoric and epistemic uncer- tainty. arXiv preprint arXiv:2412.20892, 2024
-
[9]
arXiv preprint arXiv:2501.03282 , year=
Tianyang Wang and et al. From aleatoric to epistemic: Exploring uncer- tainty quantification techniques in artificial intelligence.arXiv preprint arXiv:2501.03282, 2025
-
[10]
S. R. Künzel, J. S. Sekhon, P. J. Bickel, and B. Yu. Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the National Academy of Sciences, 116(10):4156–4165, 2019
work page 2019
-
[11]
Jennifer L. Hill. Bayesian nonparametric modeling for causal inference. Journal of Computational and Graphical Statistics, 20(1):217–240, 2011
work page 2011
-
[12]
A survey of deep causal models and their industrial applications
Yichao Zhang et al. A survey of deep causal models and their industrial applications. Artificial Intelligence Review, 2024
work page 2024
-
[13]
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? InAdvances in Neural Information Processing Systems, pages 5574–5584, 2017
work page 2017
-
[14]
Estimating epistemic and aleatoric uncer- tainty with a single model
Alice Lee and Ravi Kumar. Estimating epistemic and aleatoric uncer- tainty with a single model. InAdvances in Neural Information Process- ing Systems, 2024. 14
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.