Text to model via SysML: Automated generation of dynamical system computational models from unstructured natural language text via enhanced System Modeling Language diagrams
Pith reviewed 2026-05-19 05:12 UTC · model grok-4.3
The pith
A five-step pipeline with SysML diagrams and language tools converts unstructured text into working dynamical system models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
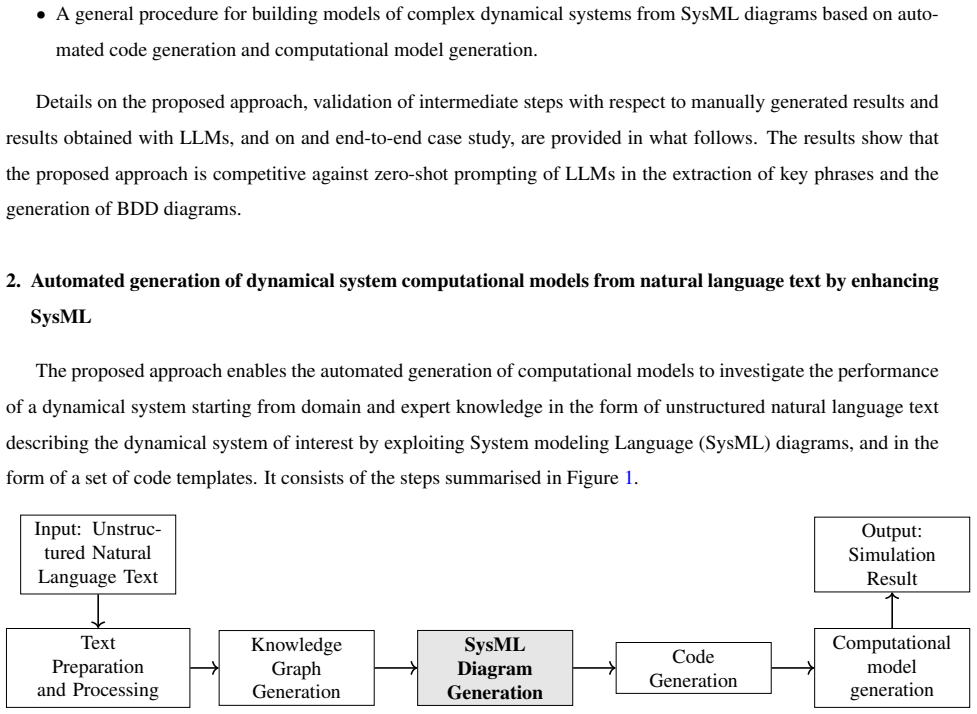
The paper claims that a five-step strategy, which first creates enhanced SysML diagrams from text with the help of NLP and LLMs, then uses those diagrams plus equation templates to generate code and computational models, produces dynamical system models with improved performance over zero-shot LLM output, as demonstrated by an end-to-end example of a simple pendulum.
What carries the argument
The five-step strategy that extracts nouns, relationships, attributes, and operations from text to build SysML block definition diagrams, then generates code and models from those diagrams.
If this is right
- Expert knowledge enters the process through reusable equation implementation templates rather than through hand-coded models.
- The approach works across different dynamical systems and is not tied to one simulation platform.
- NLP handles summarization during code generation while LLMs are used only for validation.
- The same pipeline can be applied to any corpus of documents describing a dynamical system.
Where Pith is reading between the lines
- If extraction accuracy holds, the method could shorten the time between writing a system specification and running its first simulation.
- Scalability to larger systems will depend on how well current language tools handle longer or more technical documents.
- The diagrams created as an intermediate step could serve as human-readable documentation that engineers can inspect and correct before code is produced.
Load-bearing premise
NLP strategies and large language models can reliably extract lists of key nouns, relationships, attributes, and operations from unstructured text to produce correct SysML diagrams without domain errors or invented details.
What would settle it
Apply the full pipeline to the simple pendulum description and verify whether the generated model yields the standard pendulum equations of motion and matching simulation trajectories.
Figures













read the original abstract
This paper contributes to speeding up the design and deployment of engineering dynamical systems by proposing a strategy for exploiting domain and expert knowledge for the automated generation of a dynamical system computational model starting from a corpus of documents relevant to the dynamical system of interest and an input document describing the specific system. This strategy is implemented in five steps and, crucially, it uses system modeling language diagrams (SysML) to extract accurate information about the dependencies, attributes, and operations of components. Natural Language Processing (NLP) strategies and Large Language Models (LLMs) are employed in specific tasks to improve intermediate outputs of the SySML diagrams automated generation, such as: list of key nouns; list of extracted relationships; list of key phrases and key relationships; block attribute values; block relationships; and BDD diagram generation. The applicability of automated SysML diagram generation is illustrated with different case studies. The computational models of complex dynamical systems from SysML diagrams are then obtained via code generation and computational model generation steps. In the code generation step, NLP strategies are used for summarization, while LLMs are used for validation only. The proposed approach is not limited to a specific system, domain, or computational software. Domain and expert knowledge is integrated by providing a set of equation implementation templates. This work represents one of the first attempts to build an automatic pipeline for this area. The applicability of the proposed approach is shown via an end-to-end example from text to model of a simple pendulum, showing improved performance compared to results yielded by LLMs only in zero-shot mode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a five-step pipeline for generating computational models of dynamical systems directly from unstructured natural language text. The approach uses NLP strategies and LLMs to extract key nouns, relationships, attributes, and operations, which are then assembled into SysML Block Definition Diagrams (BDDs). These diagrams serve as an intermediate structured representation from which code is generated and computational models are produced, with domain knowledge injected via provided equation implementation templates. LLMs are used for validation only in the code-generation step. The method is illustrated via an end-to-end example of a simple pendulum, with the claim that it yields improved performance relative to zero-shot LLM prompting.
Significance. If the extraction and diagram-generation steps prove reliable, the work could meaningfully accelerate the translation of expert textual descriptions into executable dynamical-system models, reducing manual modeling effort in engineering domains. The explicit use of SysML as an intermediate formal layer is a constructive choice that may improve traceability and reduce hallucinations compared with direct LLM code generation. The integration of reusable equation templates is also a practical strength for embedding domain knowledge without requiring the LLM to derive physics from scratch. At present, however, these benefits remain prospective because the manuscript supplies only a single qualitative demonstration.
major comments (2)
- [Abstract and §3] Abstract and §3 (five-step strategy): the central claim that the pipeline produces faithful computational models with improved performance over zero-shot LLMs rests on the unmeasured accuracy of the NLP/LLM extraction of nouns, relationships, attributes, and operations into correct SysML BDDs. No precision, recall, or error-rate figures are reported for any extraction sub-task, so it is impossible to determine whether domain-specific relations (e.g., torque = I·α or the nonlinear sin(θ) term) survive the pipeline without omission or hallucination.
- [§4] §4 (pendulum case study): the reported improvement is supported solely by a qualitative end-to-end walkthrough. No quantitative metrics—such as diagram fidelity scores, simulation error against ground-truth equations, or comparison of generated code correctness—are provided, rendering the performance claim difficult to evaluate or generalize beyond this single example.
minor comments (2)
- [Abstract] The abstract states that applicability is shown via 'different case studies' for SysML diagram generation yet presents only the pendulum as a full text-to-model example; clarifying how many additional systems were tested and whether they received the same end-to-end validation would improve transparency.
- [§3] Notation for the intermediate lists (key nouns, relationships, block attributes, etc.) is introduced at a high level; providing a small table that maps each list to the corresponding SysML element it populates would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, acknowledging where quantitative support is currently limited and outlining targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (five-step strategy): the central claim that the pipeline produces faithful computational models with improved performance over zero-shot LLMs rests on the unmeasured accuracy of the NLP/LLM extraction of nouns, relationships, attributes, and operations into correct SysML BDDs. No precision, recall, or error-rate figures are reported for any extraction sub-task, so it is impossible to determine whether domain-specific relations (e.g., torque = I·α or the nonlinear sin(θ) term) survive the pipeline without omission or hallucination.
Authors: We agree that quantitative metrics for the extraction sub-tasks would allow readers to better assess the reliability of the intermediate SysML BDDs. The current manuscript emphasizes the overall pipeline architecture and its use of SysML as a traceable intermediate representation, with the pendulum example serving as an end-to-end illustration rather than a comprehensive benchmark. In the revised version we will add a new subsection to §3 that reports precision and recall for noun extraction, relationship extraction, and attribute identification on the pendulum description, obtained via manual comparison against ground-truth annotations derived from the input text. This will directly address whether key physical relations such as the torque equation and the sin(θ) nonlinearity are preserved. revision: yes
-
Referee: [§4] §4 (pendulum case study): the reported improvement is supported solely by a qualitative end-to-end walkthrough. No quantitative metrics—such as diagram fidelity scores, simulation error against ground-truth equations, or comparison of generated code correctness—are provided, rendering the performance claim difficult to evaluate or generalize beyond this single example.
Authors: We concur that reliance on a single qualitative walkthrough limits the strength of the performance claims. The example demonstrates that the pipeline produces a runnable model containing the nonlinear term, whereas zero-shot prompting frequently omits it, but this remains illustrative. In the revision we will augment §4 with quantitative results: (i) a diagram fidelity score obtained by expert review of the generated BDD against the expected structure, (ii) the root-mean-square error between trajectories simulated from the generated model and the analytical ground-truth solution over a fixed time horizon, and (iii) a correctness check of the generated code against the provided equation templates. We will also add an explicit limitations paragraph noting that broader multi-example evaluation is planned for future work. revision: yes
Circularity Check
No circularity: pipeline uses external NLP/LLM tools and provided templates; central claim rests on illustrative example rather than self-referential definitions or fits.
full rationale
The paper describes a five-step methodological pipeline that invokes external NLP strategies, LLMs for specific subtasks (e.g., list extraction, validation), and user-supplied equation templates to produce SysML diagrams and then code. The performance claim is supported by a single end-to-end pendulum demonstration rather than any parameter fitting, self-defined quantities, or load-bearing self-citations. No equations, uniqueness theorems, or ansatzes are introduced that reduce to quantities defined inside the paper itself. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NLP strategies and LLMs can produce accurate lists of key nouns, relationships, attributes, and operations from unstructured domain text.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The proposed approach ... uses system modeling language diagrams (SysML) to extract accurate information about the dependencies, attributes, and operations of components. Natural Language Processing (NLP) strategies and Large Language Models (LLMs) are employed ...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Code Generation: The BDD diagram is used to generate code that models each component ... equation implementation templates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Schoukens, L. Ljung, Nonlinear system identification: a user-oriented road map, IEEE Control Systems 39 (6) (2019) 28–99.doi:10.1109/MCS.2019.2938121
-
[2]
T. Söderström, P. Stoica, System identification, Prentice-Hall, Inc., USA, 1988
work page 1988
-
[3]
D. Dori, N. Korda, A. Soffer, S. Cohen, Smart: System model acquisition from requirements text, in: J. Desel, B. Pernici, M. Weske (Eds.), Business Process Management, Springer Berlin Heidelberg, Berlin, Heidelberg, 2004, pp. 179–194, Lecture Notes in Computer Science, vol 3080.doi:10.1007/978-3-540-25970-1_12
-
[4]
P. Sawyer, P. Rayson, K. Cosh, Shallow knowledge as an aid to deep understanding in early phase requirements engineering, IEEE Transactions on Software Engineering 31 (11) (2005) 969–981, electronic ISSN: 1939-3520. INSPEC Accession Number: 8727391.doi:10.1109/TSE.2005.129
-
[5]
A. Arellano, E. Zontek-Carney, M. A. Austin, Frameworks for natural language processing of textual require- ments, International Journal On Advances in Systems and Measurements 8 (2015) 230–240
work page 2015
- [6]
-
[7]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, D. Amodei,...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y . Zhou, S. Savarese, C. Xiong, Codegen: An open large language model for code with multi-turn program synthesis (2023).arXiv:2203.13474. URLhttps://arxiv.org/abs/2203.13474
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Y . Wang, H. Le, A. D. Gotmare, N. D. Q. Bui, J. Li, S. C. H. Hoi, Codet5+: Open code large language models for code understanding and generation (2023).arXiv:2305.07922. URLhttps://arxiv.org/abs/2305.07922
work page internal anchor Pith review arXiv 2023
-
[10]
Code Llama: Open Foundation Models for Code
B. Rozière, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remez, J. Rapin, A. Kozhevnikov, I. Evtimov, J. Bitton, M. Bhatt, C. C. Ferrer, A. Grattafiori, W. Xiong, A. Défossez, J. Copet, F. Azhar, H. Touvron, L. Martin, N. Usunier, T. Scialom, G. Synnaeve, Code llama: Open foundation models for codearXiv:2308.129...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950
-
[11]
S. Rupprecht, Y . Hounat, M. Kumar, G. Lastrucci, A. M. Schweidtmann, Text2model: Generating dynamic chemical reactor models using large language models (llms), arXiv preprint arXiv:2503.17004
-
[12]
Face, meta-llama/llama-3.1-8b-instruct
H. Face, meta-llama/llama-3.1-8b-instruct. URLhttps://huggingface.co/meta-llama/Llama-3.1-8B-Instruct
-
[13]
A. Kossiakoff, W. Sweet, S. Seymour, S. Biemer, Systems Engineering Principles and Practice, 2nd Edition, John Wiley & Sons, Ltd, 2011.doi:doi.org/10.1002/9781118001028
-
[14]
S. Friedenthal, A. Moore, R. Steiner, A Practical Guide to SysML, Third Edition: The Systems Modeling Language, 3rd Edition, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2014.doi:https:// doi.org/10.1016/C2013-0-14457-1
-
[15]
L. E. Hart, Introduction to model-based system engineering (mbse) and sysml, in: Delaware Valley INCOSE Chapter Meeting, V ol. 30, Ramblewood Country Club Mount Laurel, New Jersey, 2015
work page 2015
-
[16]
L. Delligatti, SysML Distilled: A Brief Guide to the Systems Modeling Language, 1st Edition, Addison-Wesley Professional, 2013
work page 2013
-
[17]
E. Huang, R. Ramamurthy, L. F. McGinnis, System and simulation modeling using sysml, in: 2007 Winter Simulation Conference, IEEE, 2007, pp. 796–803, ISBN=978-1-4244-1305-8. ISSN=1558-4305. INSPEC Accession Number=9847802.doi:10.1109/WSC.2007.4419675. 40
-
[18]
D. Jurafsky, J. H. Martin, Speech and Language Processing (2nd Edition), Prentice-Hall, Inc., USA, 2009, ISBN =0131873210
work page 2009
-
[19]
Object Management Group, OMG System Modeling Language Version 1.6, Standard, Object Management Group (OMG) (Dec. 2019). URLhttps://www.omg.org/spec/SysML/1.6
work page 2019
-
[20]
S. Friedenthal, A. Moore, R. Steiner, OMG Systems Modeling Language (OMG SysML) Tutorial, INCOSE International Symposium 18 (2008) 1731–1862.doi:10.1002/j.2334-5837.2008.tb00914.x
-
[21]
Hause, The SysML Modelling Language, in: Fifteenth European Systems Engineering Conference, 2006
M. Hause, The SysML Modelling Language, in: Fifteenth European Systems Engineering Conference, 2006
work page 2006
-
[22]
J. L. Santos, L. E. G. Martins, J. S. Molléri, Requirements extraction from model-based systems engineering: A systematic literature review, Journal of Systems and Software 226 (2025) 112407.doi:https://doi.org/ 10.1016/j.jss.2025.112407. URLhttps://www.sciencedirect.com/science/article/pii/S0164121225000755
- [23]
-
[24]
W. J. Jackman, T. H. Russell, O. Chanute, Flying machines: construction and operation, Charles C. Thompson Company, 1912
work page 1912
- [25]
-
[26]
Norvig, Natural language corpus data, Beautiful data (2009) 219–242
P. Norvig, Natural language corpus data, Beautiful data (2009) 219–242
work page 2009
-
[27]
Sondej, Spelling corrector in python, Github repository (January 2021)
F. Sondej, Spelling corrector in python, Github repository (January 2021). URLhttps://github.com/filyp/autocorrect
work page 2021
-
[28]
J. R. Hobbs, Coherence and coreference, Cognitive science 3 (1) (1979) 67–90
work page 1979
-
[29]
R. P. Hudson, Coreferee: A python library for coreference resolution, GitHub repository (May 2022). URLhttps://github.com/msg-systems/coreferee?tab=readme-ov-file
work page 2022
-
[30]
S. Bird, E. Klein, E. Loper, Natural language processing with Python: analyzing text with the natural language toolkit, O’Reilly Media, Inc., 2009
work page 2009
-
[31]
T. Kiss, J. Strunk, Unsupervised Multilingual Sentence Boundary Detection, Computational Linguistics 32 (4) (2006) 485–525.arXiv:https://direct.mit.edu/coli/article-pdf/32/4/485/1798345/ coli.2006.32.4.485.pdf,doi:10.1162/coli.2006.32.4.485. URLhttps://doi.org/10.1162/coli.2006.32.4.485 41
-
[32]
S. Saha, V . Adlakha, Open information extraction (openie5.1), GitHub repository (January 2024). URLhttps://github.com/dair-iitd/OpenIE-standalone
work page 2024
-
[33]
J. Christensen, Mausam, S. Soderland, O. Etzioni, An analysis of open information extraction based on semantic role labeling, in: Proceedings of the Sixth International Conference on Knowledge Capture, K-CAP ’11, Asso- ciation for Computing Machinery, New York, NY , USA, 2011, p. 113–120.doi:10.1145/1999676.1999697
-
[34]
Pal, Mausam, Demonyms and compound relational nouns in nominal open IE, in: J
H. Pal, Mausam, Demonyms and compound relational nouns in nominal open IE, in: J. Pujara, T. Rocktaschel, D. Chen, S. Singh (Eds.), Proceedings of the 5th Workshop on Automated Knowledge Base Construction, As- sociation for Computational Linguistics, San Diego, CA, 2016, pp. 35–39.doi:10.18653/v1/W16-1307. URLhttps://aclanthology.org/W16-1307/
-
[35]
S. Saha, H. Pal, Mausam, Bootstrapping for numerical open IE, in: R. Barzilay, M.-Y . Kan (Eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers), Asso- ciation for Computational Linguistics, Vancouver, Canada, 2017, pp. 317–323.doi:10.18653/v1/P17-2050. URLhttps://aclanthology.org/P17-2050/
-
[36]
A. Pauls, D. Klein, Faster and smaller<i>n</i>-gram language models, in: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies - V olume 1, HLT ’11, Association for Computational Linguistics, USA, 2011, p. 258–267
work page 2011
-
[37]
Fellbaum, WordNet: An electronic lexical database, MIT press, 1998
C. Fellbaum, WordNet: An electronic lexical database, MIT press, 1998
work page 1998
-
[38]
L. Zhao, W. Alhoshan, A. Ferrari, K. J. Letsholo, M. A. Ajagbe, E.-V . Chioasca, R. T. Batista-Navarro, Natural language processing for requirements engineering: A systematic mapping study, ACM Comput. Surv. 54 (3). doi:10.1145/3444689
-
[39]
O. A. Specification, Omg systems modeling language (omg sysml™), v1. 0, Object Management Group
- [40]
-
[41]
A. Brinkmann, R. Shraga, C. Bizer, Extractgpt: Exploring the potential of large language models for product at- tribute value extraction, in: International Conference on Information Integration and Web Intelligence, Springer, 2025, pp. 38–52
work page 2025
- [42]
-
[43]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remez, et al., Code llama: Open foundation models for code, arXiv preprint arXiv:2308.12950
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
R. Tarjan, Depth-first search and linear graph algorithms, SIAM journal on computing 1 (2) (1972) 146–160
work page 1972
- [45]
-
[46]
H. Xu, W. Wang, X. Mao, X. Jiang, M. Lan, Scaling up open tagging from tens to thousands: Comprehension empowered attribute value extraction from product title, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 5214–5223
work page 2019
-
[47]
F. Hausdorff, Set theory, V ol. 119, American Mathematical Soc., 2021
work page 2021
-
[48]
Ronacher, Jinja2 documentation, Welcome to Jinja2—Jinja2 Documentation (2.8-dev)
A. Ronacher, Jinja2 documentation, Welcome to Jinja2—Jinja2 Documentation (2.8-dev)
-
[49]
Rentsch, Object oriented programming, ACM Sigplan Notices 17 (9) (1982) 51–57
T. Rentsch, Object oriented programming, ACM Sigplan Notices 17 (9) (1982) 51–57
work page 1982
-
[50]
A. Mahajani, V . Pandya, I. Maria, D. Sharma, A comprehensive survey on extractive and abstractive techniques for text summarization, Ambient Communications and Computer Systems: RACCCS-2018 (2019) 339–351
work page 2018
-
[51]
R. Mihalcea, P. Tarau, Textrank: Bringing order into text, in: Proceedings of the 2004 conference on empirical methods in natural language processing, 2004, pp. 404–411
work page 2004
- [52]
- [53]
-
[54]
G. Tsialiamanis, D. J. Wagg, N. Dervilis, K. Worden, On generative models as the basis for digital twins, Data- Centric Engineering 2 (2021) e11.doi:10.1017/dce.2021.13
-
[55]
A. Cicirello, Physics-enhanced machine learning: a position paper for dynamical systems investigations, Journal of Physics: Conference Series 2909 (1) (2024) 012034.doi:10.1088/1742-6596/2909/1/012034. URLhttps://dx.doi.org/10.1088/1742-6596/2909/1/012034
-
[56]
Flying Machines: Construction and Operation
G. A. Veldhuis, D. Blok, M. H. de Boer, G. J. Kalkman, R. M. Bakker, R. P. van Waas, From text to model: Leveraging natural language processing for system dynamics model development, System Dynamics Review 40 (3) (2024) e1780.arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/sdr.1780,doi: https://doi.org/10.1002/sdr.1780. URLhttps://onlinelibrary.wile...
-
[57]
Most nouns found in en- gineering documents tend to represent significant compo- nents due to the terse writing style. Lphrase Lphrase >0 The maximum number of words allowed in a phrase in the BDD diagram 3-5 words depending on the engineering domain. σp 0< σ p <1 The minimum importance metric value (as defined in Section 3.2.3) required for a phrase to b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.