Robustness Measures in Distributionally Robust Optimization
Pith reviewed 2026-05-19 04:32 UTC · model grok-4.3
The pith
The regularizer that approximates distributionally robust optimization is exactly the worst-case sensitivity of expected cost to shifts away from the nominal model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
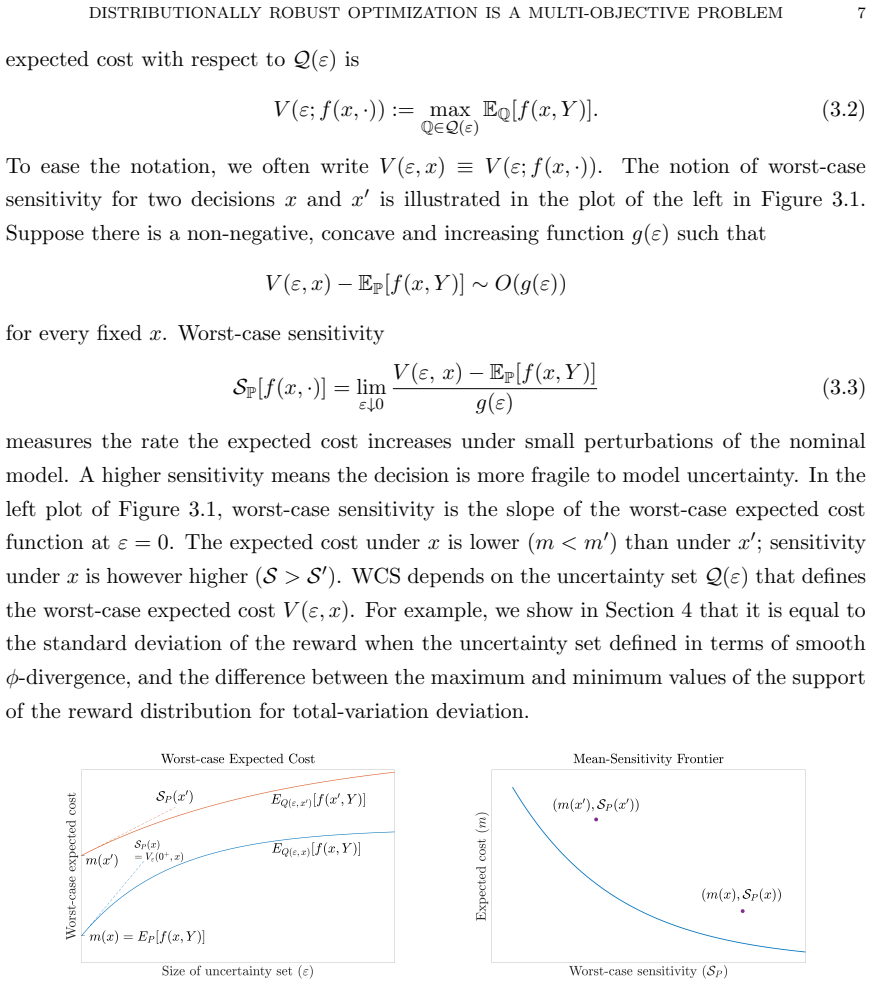
The central claim is that the regularizer arising in the approximation of distributionally robust optimization by a regularized nominal problem is identical to the worst-case sensitivity of the expected cost with respect to deviations from the nominal probability model. This equivalence supplies the regularizer with an interpretation as a robustness measure, so that DRO amounts to an explicit performance-robustness tradeoff whose form is fixed by the choice of uncertainty set. The resulting robustness measure identifies features of the cost distribution that govern sensitivity to misspecification, which in turn yields a systematic method for choosing uncertainty sets. Solutions obtained by a
What carries the argument
Worst-case sensitivity (WCS) of the expected cost to deviations from the nominal model; it supplies the explicit robustness measure that equals the regularizer in the DRO approximation.
If this is right
- DRO solutions trace a near Pareto-optimal performance-robustness frontier when the uncertainty set size is varied.
- The frontier identifies problem instances where the price of robustness is high and suggests system redesigns to lower that cost.
- Uncertainty sets can be chosen systematically according to the properties of the cost distribution that affect sensitivity.
- WCS can be derived explicitly for a collection of standard uncertainty sets used in DRO.
- The robustness measure reveals which features of a cost distribution make the solution sensitive to model misspecification.
Where Pith is reading between the lines
- Different uncertainty sets could be compared by the distinct robustness measures they induce on the same cost distribution.
- The frontier construction might be used to set the uncertainty-set size in applied problems by inspecting the marginal cost of added robustness.
- The same sensitivity perspective could be tested in sequential or multi-stage decision settings where model updates occur over time.
Load-bearing premise
The approximation of DRO by a regularized nominal problem must hold for the uncertainty sets under consideration.
What would settle it
Compute the worst-case sensitivity directly for a concrete cost function and uncertainty set, then check whether it equals the regularizer coefficient obtained from the DRO approximation; any material mismatch would refute the claimed equivalence.
Figures














read the original abstract
Distributionally Robust Optimization (DRO) is a worst-case approach to decision making when there is model uncertainty. It is also well known that for certain uncertainty sets, DRO is approximated by a regularized nominal problem. We show that the regularizer is not just a penalty function but the worst-case sensitivity (WCS) of the expected cost with respect to deviations from the nominal model, giving it the interpretation of a robustness measure. This has substantial consequences for robust modeling. It shows that DRO is fundamentally a tradeoff between performance and robustness, where the robustness measure is determined by the uncertainty set. The robustness measure reveals properties of a cost distribution that affect sensitivity to misspecification. This leads to a systematic approach to selecting uncertainty sets. The family of DRO solutions obtained by varying the size of the uncertainty set traces a near Pareto-optimal performance--robustness frontier that can be used to select its size. The frontier identifies problem instances where the price of robustness is high and provides insight into effective ways of redesigning the system to reduce this cost. We derive WCS for a collection of commonly used uncertainty sets, and illustrate these ideas in a number of applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for certain uncertainty sets, DRO can be approximated by a regularized nominal problem whose regularizer equals the worst-case sensitivity (WCS) of the expected cost to deviations from the nominal distribution. This interpretation frames the regularizer as a robustness measure, shows that DRO encodes a performance-robustness tradeoff determined by the uncertainty set, derives explicit WCS expressions for common sets, and introduces a performance-robustness frontier obtained by varying the uncertainty radius to guide set selection and system redesign.
Significance. If the central equivalence holds under the stated conditions, the work supplies a principled way to interpret and select uncertainty sets via their induced robustness measures, moving beyond ad-hoc choices. The explicit WCS derivations for standard sets and the frontier construction are concrete contributions that could inform both theory and applications in robust optimization.
major comments (1)
- [§3, Theorem 1] §3, Theorem 1 and surrounding derivation: the claimed exact identification of the regularizer with WCS is shown only after invoking the DRO-to-regularized approximation; the manuscript should state the precise conditions (e.g., twice-differentiability of the cost, small radius, or specific divergence) under which the approximation becomes an equality, because these conditions are load-bearing for the robustness-measure interpretation.
minor comments (2)
- [§2] Notation for the nominal distribution P_0 and the uncertainty ball radius is introduced late; moving the definitions to §2 would improve readability.
- [Figure 1] Figure 1 (performance-robustness frontier) lacks axis labels on the robustness measure; adding them would make the trade-off visually clearer.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comment on the conditions underlying the DRO-regularizer equivalence. We address the point below and will revise the manuscript to incorporate the requested clarification.
read point-by-point responses
-
Referee: [§3, Theorem 1] §3, Theorem 1 and surrounding derivation: the claimed exact identification of the regularizer with WCS is shown only after invoking the DRO-to-regularized approximation; the manuscript should state the precise conditions (e.g., twice-differentiability of the cost, small radius, or specific divergence) under which the approximation becomes an equality, because these conditions are load-bearing for the robustness-measure interpretation.
Authors: We agree that the identification of the regularizer with the worst-case sensitivity is established within the DRO-to-regularized approximation. The revised manuscript will explicitly delineate the conditions under which the approximation holds with equality or high accuracy, including sufficiently small uncertainty radii, twice continuous differentiability of the cost function with respect to the distribution parameter, and specific divergence choices (e.g., Kullback-Leibler or Wasserstein). This clarification will be added to the statement of Theorem 1 and the surrounding discussion in §3 to strengthen the robustness-measure interpretation. revision: yes
Circularity Check
No circularity: WCS interpretation derived from known DRO approximation
full rationale
The paper starts from the established fact that DRO approximates a regularized nominal problem for certain uncertainty sets, then derives that the regularizer equals the worst-case sensitivity (WCS) of expected cost to nominal deviations. This interpretive step and its consequences for performance-robustness tradeoffs are presented as following from the definitions and the approximation, without reducing to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The abstract and description indicate an independent derivation chain supported by external literature on the approximation, making the result self-contained rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption For certain uncertainty sets, DRO is approximated by a regularized nominal problem.
invented entities (1)
-
Worst-case sensitivity (WCS)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that the regularizer is not just a penalty function but the worst-case sensitivity (WCS) of the expected cost with respect to deviations from the nominal model... worst-case sensitivity is a generalized measure of deviation
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Sp(f) = lim ε↓0 [V(ε,x)−EP[f(x,Y)]] / g(ε) ... A(ε;f) is a generalized measure of deviation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Douglas Adams.The Hitchhiker’s Guide to the Galaxy: A Trilogy in Five Parts. Random House, 1995
work page 1995
-
[2]
Selin Damla Ahipasaoglu, Karthik Natarajan, and Dongjian Shi. Distributionally robust project crashing with partial or no correlation information.Networks, 74(1): 79–106, 2019
work page 2019
-
[3]
Edward Anderson and Andy Philpott. Improving sample average approximation using distributional robustness.INFORMS Journal on Optimization, 4(1):90–124, 2022
work page 2022
-
[4]
Gah-Yi Ban, Noureddine El Karoui, and Andrew E. B. Lim. Machine learning and portfolio optimization.Management Science, 64(3):1136–1154, 2016. URLhttps: //doi.org/10.1287/mnsc.2016.2644
-
[5]
Daniel Bartl, Samuel Drapeau, Jan Obloj, and Johannes Wiesel. Sensitivity analysis of Wasserstein distributionally robust optimization problems.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 477(20210176), 2021. doi: 10.1098/rspa.2021.0176
-
[6]
Robust convex optimization.Mathematics of Operations Research, 23(4):769–805, 1989
Aharon Ben-Tal and Arkadi Nemirovski. Robust convex optimization.Mathematics of Operations Research, 23(4):769–805, 1989
work page 1989
-
[7]
Robust solutions of optimization problems affected by uncertain probabilities
Aharon Ben-Tal, Dick den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. Robust solutions of optimization problems affected by uncertain probabilities. Management Science, 59(2):341–357, 2013
work page 2013
-
[8]
Dimitris Bertsimas and Martin S. Copenhaver. Characterization of the equivalence of robustification and regularization in linear and matrix regression.European Journal of Operational Research, 270(3):931–942, 2018. DISTRIBUTIONALLY ROBUST OPTIMIZATION IS A MULTI-OBJECTIVE PROBLEM 33
work page 2018
-
[9]
The price of robustness.Operations Research, 52 (1):35–53, 2004
Dimitris Bertsimas and Melvyn Sim. The price of robustness.Operations Research, 52 (1):35–53, 2004
work page 2004
-
[10]
Data-driven robust optimiza- tion.Mathematical Programming, 167(2):235–292, 2018
Dimitris Bertsimas, Vishal Gupta, and Nathan Kallus. Data-driven robust optimiza- tion.Mathematical Programming, 167(2):235–292, 2018
work page 2018
-
[11]
Robust sample average approx- imation.Mathematical Programming, 171(1-2):217–282, 2018
Dimitris Bertsimas, Vishal Gupta, and Nathan Kallus. Robust sample average approx- imation.Mathematical Programming, 171(1-2):217–282, 2018
work page 2018
-
[12]
Jose Blanchet, Yang Kang, and Karthyek Murthy. Robust Wasserstein profile inference and applications to machine learning.Journal of Applied Probability, 56(3):830–857, 2019
work page 2019
-
[13]
Brown, Enrico De Giorgi, and Melvyn Sim
David B. Brown, Enrico De Giorgi, and Melvyn Sim. Aspirational preferences and their representation by risk measures.Management Science, 58(11):2095–2113, 2012
work page 2095
-
[14]
Louis L. Chen and Johannes O. Royset. Rockafellian relaxation in optimization under uncertainty: Asymptotically exact formulations.arXiv:2204.04762, 2017. URLhttps: //arxiv.org/abs/2204.04762
-
[15]
Davide Chicco and Giuseppe Jurman. Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone.BMC Medical Informatics and Decision Making, 20(1):16, 2020
work page 2020
-
[16]
Bikramjit Das, Anulekha Dhara, and Karthik Natarajan. On the heavy-tail behavior of the distributionally robust newsvendor.Operations Research, 69(4):1077–1099, 2021
work page 2021
-
[17]
Erick Delage and Yinyu Ye. Distributionally robust optimization under moment uncer- tainty with application to data-driven problems.Management Science, 58(2):695–612, 2010
work page 2010
-
[18]
John C. Duchi and Hongseok Namkoong. Variance-based regularization with convex objectives.Journal of Machine Learning Research, 20(68):1–55, 2019
work page 2019
-
[19]
John C. Duchi, Peter W. Glynn, and Hongseok Namkoong. Statistics of robust op- timization: A generalized empirical likelihood approach.Mathematics of Operations Research, 46(3):946–969, 2021
work page 2021
-
[20]
Peyman Mohajerin Esfahani and Daniel Kuhn. Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable re- formulations.Mathematical Programming, 171(1-2):115–166, 2018
work page 2018
-
[21]
Kenneth R. French. Data library.http://mba.tuck.dartmouth.edu/pages/ faculty/ken.french/data_library.html, n.d
-
[22]
Rui Gao and Anton Kleywegt. Distributionally robust stochastic optimization with Wasserstein distance.Mathematics of Operations Research, 48(2):603–655, 2023
work page 2023
-
[23]
Rui Gao, Xi Chen, and Anton J Kleywegt. Wasserstein distributionally robust opti- mization and variation regularization.Operations Research, 72(3):1177–1191, 2024. 34 GOTOH, KIM, AND LIM
work page 2024
-
[24]
Jun-ya Gotoh, Michael Jong Kim, and Andrew E.B. Lim. Robust empirical optimiza- tion is almost the same as mean–variance optimization.Operations Research Letters, 46(4):448–452, 2018
work page 2018
-
[25]
Jun-ya Gotoh, Michael Jong Kim, and Andrew E.B. Lim. Calibration of distribu- tionally robust empirical optimization models.Operations Research, 69(5):1630–1650, 2021
work page 2021
-
[26]
Jun-ya Gotoh, Michael Jong Kim, and Andrew E.B. Lim. A data-driven approach to beating SAA out of sample.Operations Research, 73(2):829–841, 2023
work page 2023
-
[27]
V. Gupta. Near-Optimal Bayesian Ambiguity Sets for Distributionally Robust Opti- mization.Management Science, 65(9):4242–4260, 2019
work page 2019
-
[28]
Lars P. Hansen and Thomas J. Sargent.Robustness. Princeton University Press, 2008
work page 2008
-
[29]
Springer-Verlag, 2nd edition, 2009
Trevor Hastie, Robert Tibshirani, and Jerome Friedman.Elements of Statistical Learn- ing. Springer-Verlag, 2nd edition, 2009
work page 2009
-
[30]
Nan Jiang and Weijun Xie. Distributionally favorable optimization: A framework for data-driven decision-making with endogenous outliers.SIAM Journal on Optimization, 34(1), 2024. URLhttps://doi.org/10.1137/22M1528094
-
[31]
Michael Jong Kim and Andrew E.B. Lim. Robust multi-armed bandit problems.Man- agement Science, 62(1):264–285, 2015
work page 2015
-
[32]
Wasserstein Distributionally Robust Optimization: Theory and Applications in Machine Learning
Daniel Kuhn, Peyman Mohajerin Esfahani, Viet Anh Nguyen, and Soroosh Shafieezadeh-Abadeh. Wasserstein Distributionally Robust Optimization: Theory and Applications in Machine Learning. InINFORMS TutORials in Operations Research, pages 130–166. INFORMS, 2019
work page 2019
-
[33]
Distributionally robust optimization, 2025
Daniel Kuhn, Soroosh Shafiee, and Wolfram Wiesemann. Distributionally robust op- timization.arXiv preprint arXiv:2411.02549, 2024
-
[34]
Henry Lam. Robust sensitivity analysis for stochastic systems.Mathematics of Oper- ations Research, 41(4):1248–1275, 2016
work page 2016
-
[35]
Henry Lam and Zhou Enlu. The empirical likelihood approach to quantifying uncer- tainty in sample average approximation.Operations Research Letters, 45(4):301–307, 2017
work page 2017
- [36]
-
[37]
Andrew E.B. Lim, J. George Shanthikumar, and Zuo-Jun Shen. Model uncertainty, robust optimization, and learning.TutORials in Operations Research, 3:66–94, 2006
work page 2006
-
[38]
Andrew E.B. Lim, J. George Shanthikumar, and Gah-Yi Vahn. Conditional value-at- risk in portfolio optimization: Coherent but fragile.Operations Research Letters, 39 (3):163–171, 2011. DISTRIBUTIONALLY ROBUST OPTIMIZATION IS A MULTI-OBJECTIVE PROBLEM 35
work page 2011
-
[39]
Luenberger.Optimization by Vector Space Methods
David G. Luenberger.Optimization by Vector Space Methods. John Wiley & Sons, 1997
work page 1997
-
[40]
Viet Anh Nguyen, Soroosh Shafieezadeh-Abadeh, Man Chung Yue, Daniel Kuhn, and Wolfram Wiesemann. Optimistic distributionally robust optimization for nonparamet- ric likelihood approximation.Advances in Neural Information Processing Systems, 32: 15872 – 15882, 2019
work page 2019
-
[41]
Optimistic Robust Optimization With Applications To Machine Learning
Matthew Norton, Akiko Takeda, and Alexander Mafusalov. Optimistic robust op- timization with applications to machine learning.arXiv:1711.07511, 2017. URL https://arxiv.org/abs/1711.07511
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
W lodzimierz Ogryczak and Andrzej Ruszczynski. Dual stochastic dominance and re- lated mean–risk models.SIAM Journal on Optimization, 13(1):60–78, 2002
work page 2002
-
[43]
Ian R. Petersen, Matthew R. James, and Paul Dupuis. Minimax optimal control of stochastic uncertain systems with relative entropy constraints.IEEE Transactions on Automatic Control, 45:398–412, 2000
work page 2000
-
[44]
Some remarks on the value-at-risk and the conditional value-at-risk
Georg Ch Pflug. Some remarks on the value-at-risk and the conditional value-at-risk. InProbabilistic constrained optimization, pages 272–281. Springer, 2000
work page 2000
-
[45]
Distributionally robust optimization: A re- view.Open Journal of Mathematical Optimization, 2022
Hamed Rahimian and Sanjay Mehrotra. Distributionally robust optimization: A re- view.Open Journal of Mathematical Optimization, 2022
work page 2022
-
[46]
Hamed Rahimian, Guzin Bayraksan, and Tito Homem-de Mello. Controlling risk and demand ambiguity in newsvendor models.European Journal of Operational Research, 279:854–868, 2019
work page 2019
-
[47]
R. Terry Rockafellar, Johannes O. Royset, and Sofia I. Miranda. Superquantile regres- sion with applications to buffered reliability, uncertainty quantification, and conditional value-at-risk.European Journal of Operational Research, 234(1):140–154, 2014
work page 2014
-
[48]
R Tyrrell Rockafellar and Stanislav Uryasev. Conditional value-at-risk for general loss distributions.Journal of Banking & Binance, 26(7):1443–1471, 2002
work page 2002
-
[49]
Tyrrell Rockafellar, Stan Uryasev, and Michael Zabarankin
R. Tyrrell Rockafellar, Stan Uryasev, and Michael Zabarankin. Generalized deviations in risk analysis.Finance and Stochastics, 10(1):51–74, 2006
work page 2006
-
[50]
Dis- tributionally robust logistic regression
Soroosh Shafieezadeh-Abadeh, Peyman Mohajerin Esfahani, and Daniel Kuhn. Dis- tributionally robust logistic regression. InAdvances in Neural Information Processing Systems, pages 1576–1584, 2015
work page 2015
-
[51]
Bayesian distributionally robust opti- mization.SIAM Journal on Optimization, 33(2):1279–1304, 2023
Alexander Shapiro, Enlu Zhou, and Yifan Lin. Bayesian distributionally robust opti- mization.SIAM Journal on Optimization, 33(2):1279–1304, 2023
work page 2023
-
[52]
Ronald E. Shiffler and Phillip D. Harsha. Upper and lower bounds for the sample standard deviation.Teaching Statistics, 2(3):84–86, 1980
work page 1980
-
[53]
Yiu Man Tsang and Karmel S. Shehadeh. On the tradeoff between distributional belief and ambiguity: Conservatism, finite-sample guarantees, and asymptotic properties. 36 GOTOH, KIM, AND LIM INFORMS Journal on Optimization, 2025. URLhttps://doi.org/10.1287/ijoo. 2024.0047. DISTRIBUTIONALLY ROBUST OPTIMIZATION IS A MULTI-OBJECTIVE PROBLEM 37 AppendixA.Proofs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.