Is This Just Fantasy? Language Model Representations Reflect Human Judgments of Event Plausibility
Pith reviewed 2026-05-19 03:56 UTC · model grok-4.3
The pith
Language models encode modal categories in linear difference vectors that align with fine-grained human judgments of event plausibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
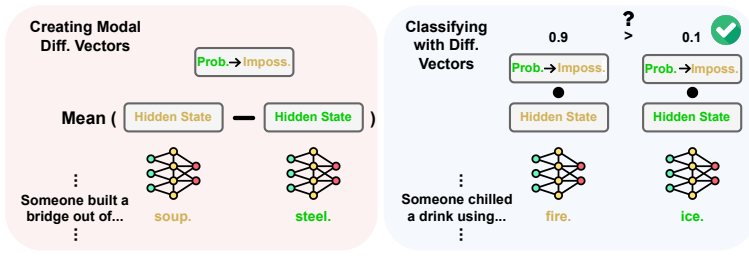
We identify linear representations that discriminate between modal categories within a variety of LMs, or modal difference vectors. Analysis of modal difference vectors reveals that LMs have access to more reliable modal categorization judgments than previously reported. Furthermore, we find that modal difference vectors emerge in a consistent order as models become more competent (i.e., through training steps, layers, and parameter count). Notably, we find that modal difference vectors identified within LM activations can be used to model fine-grained human categorization behavior by correlating projections along these vectors with human participants' ratings of interpretable features.
What carries the argument
Modal difference vectors: linear directions in LM activation space obtained by contrasting mean activations across modal categories of sentences, used both for classification and for predicting human feature ratings.
If this is right
- Modal difference vectors supply categorization accuracy higher than prior reports on the same task.
- The vectors appear in a fixed developmental order across training steps, network depth, and model scale.
- Projections of sentences onto the vectors correlate with human ratings on specific interpretable features of events.
- The approach links mechanistic interpretability methods directly to modeling human modal distinctions.
Where Pith is reading between the lines
- The same linear-projection technique could be tested on other conceptual distinctions such as causality or temporal order to see whether they also admit simple vector representations.
- If the vectors prove causal, targeted interventions along them might alter model outputs on plausibility-sensitive tasks without retraining.
- Consistent emergence order across model scales suggests a possible parallel to staged acquisition of modal concepts in human development.
Load-bearing premise
The extracted difference vectors genuinely capture the model's internal modal distinctions rather than arising as artifacts of the particular probe or sentence dataset.
What would settle it
A new test set of modal sentences on which projections along the reported difference vectors show no better-than-chance correlation with held-out human plausibility ratings.
Figures







read the original abstract
Language models (LMs) are used for a diverse range of tasks, from question answering to writing fantastical stories. In order to reliably accomplish these tasks, LMs must be able to discern the modal category of a sentence (i.e., whether it describes something that is possible, impossible, completely nonsensical, etc.). However, recent studies have called into question the ability of LMs to categorize sentences according to modality (Michaelov et al., 2025; Kauf et al., 2023). In this work, we identify linear representations that discriminate between modal categories within a variety of LMs, or modal difference vectors. Analysis of modal difference vectors reveals that LMs have access to more reliable modal categorization judgments than previously reported. Furthermore, we find that modal difference vectors emerge in a consistent order as models become more competent (i.e., through training steps, layers, and parameter count). Notably, we find that modal difference vectors identified within LM activations can be used to model fine-grained human categorization behavior. This potentially provides a novel view into how human participants distinguish between modal categories, which we explore by correlating projections along modal difference vectors with human participants' ratings of interpretable features. In summary, we derive new insights into LM modal categorization using techniques from mechanistic interpretability, with the potential to inform our understanding of modal categorization in humans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that language models contain linear 'modal difference vectors' in their activations that discriminate between modal categories (possible, impossible, nonsensical). These vectors purportedly yield more reliable categorization judgments than reported in prior work (Michaelov et al. 2025; Kauf et al. 2023), emerge in a consistent developmental order across training steps, layers, and model scale, and can be projected to model fine-grained human event-plausibility judgments via correlations with human ratings of interpretable features.
Significance. If the vectors are shown to encode genuine modal distinctions rather than dataset or probe artifacts, the result would strengthen mechanistic interpretability approaches to modal reasoning and offer a potential bridge to human categorization data. The consistent emergence pattern across training dynamics would be a notable contribution to understanding capability acquisition.
major comments (3)
- [§4.2] §4.2 (Vector Construction): The modal difference vectors are formed by subtracting mean activations across modal sentence sets without reported controls such as label-permutation tests, orthogonalization against lexical/syntactic covariates, or held-out probe validation. This is load-bearing for the central claim that the vectors reflect internal modal distinctions rather than spurious correlations; absent these controls, both the reliability upgrade over prior work and the human-correlation results are at risk of being artifacts.
- [§5.1] §5.1 (Human Correlation Analysis): The reported correlations between vector projections and human feature ratings provide no error bars, participant count, inter-rater reliability statistics, or multiple-comparison corrections. Because this analysis underpins the claim that the vectors model fine-grained human categorization behavior, the absence of these details prevents assessment of robustness.
- [§3.3] §3.3 (Comparison to Prior Work): The assertion of superior reliability over Michaelov et al. (2025) and Kauf et al. (2023) is presented via accuracy metrics without statistical tests or confidence intervals on the differences. This comparison is central to the paper's positioning yet lacks the quantitative grounding needed to substantiate the improvement.
minor comments (2)
- [Abstract] The abstract states that vectors 'emerge in a consistent order' but does not define the precise ordering metric or the set of models/layers examined; a brief clarification would aid readability.
- [Figures] Figure legends should explicitly label the three modal categories (possible/impossible/nonsensical) and indicate whether error bands represent standard error or bootstrap intervals.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the methodological foundations of our claims. We address each major point below and will revise the manuscript accordingly to incorporate additional controls, statistical details, and clarifications while preserving the core findings.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Vector Construction): The modal difference vectors are formed by subtracting mean activations across modal sentence sets without reported controls such as label-permutation tests, orthogonalization against lexical/syntactic covariates, or held-out probe validation. This is load-bearing for the central claim that the vectors reflect internal modal distinctions rather than spurious correlations; absent these controls, both the reliability upgrade over prior work and the human-correlation results are at risk of being artifacts.
Authors: We agree that explicit controls are important to rule out artifacts. Our sentence sets were constructed using matched templates to control for lexical and syntactic factors, but we did not report permutation tests or held-out validation in the original submission. In the revised manuscript, we will add label-permutation tests across the modal categories and report performance on held-out sentence sets to confirm that the difference vectors capture modal distinctions beyond spurious correlations. Orthogonalization against additional covariates will be explored and included if it materially affects the results. revision: yes
-
Referee: [§5.1] §5.1 (Human Correlation Analysis): The reported correlations between vector projections and human feature ratings provide no error bars, participant count, inter-rater reliability statistics, or multiple-comparison corrections. Because this analysis underpins the claim that the vectors model fine-grained human categorization behavior, the absence of these details prevents assessment of robustness.
Authors: We acknowledge that these details are essential for evaluating the human correlation results. The original manuscript focused on the correlation patterns but omitted the supporting statistics due to length. In revision, we will add bootstrapped error bars or confidence intervals to the reported correlations, include the participant count and inter-rater reliability measures, and apply multiple-comparison corrections. These additions will allow readers to assess the robustness of the link between vector projections and human feature ratings. revision: yes
-
Referee: [§3.3] §3.3 (Comparison to Prior Work): The assertion of superior reliability over Michaelov et al. (2025) and Kauf et al. (2023) is presented via accuracy metrics without statistical tests or confidence intervals on the differences. This comparison is central to the paper's positioning yet lacks the quantitative grounding needed to substantiate the improvement.
Authors: We agree that statistical grounding for the accuracy improvements would strengthen the positioning relative to prior work. The manuscript reports raw accuracy differences but does not include formal tests. In the revised version, we will compute and report confidence intervals or appropriate statistical tests (e.g., McNemar or bootstrap tests) on the differences in categorization performance between our modal difference vectors and the methods in Michaelov et al. (2025) and Kauf et al. (2023). revision: yes
Circularity Check
No significant circularity; claims rest on empirical vector extraction and external human correlations
full rationale
The paper extracts modal difference vectors via activation differences across sentence sets categorized by modality, then correlates projections with independent human feature ratings and observes emergence patterns across training/layers/parameters. No load-bearing step reduces a result to its inputs by definition or self-citation chain; vector construction follows standard difference methods without fitting the target human data into the vectors themselves. Citations to Michaelov et al. and Kauf et al. serve as external benchmarks for reliability comparisons rather than justifying the current derivations. The analysis is self-contained against held-out human judgments and observational trends, with no self-definitional, fitted-prediction, or ansatz-smuggling patterns present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear directions in activation space can isolate semantic distinctions such as modality.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify linear representations that discriminate between modal categories within a variety of LMs, or modal difference vectors... projections along modal difference vectors with human participants' ratings of interpretable features.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
modal difference vectors emerge in a consistent order as models become more competent (i.e., through training steps, layers, and parameter count)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[2]
Gordon, J. and Van Durme, B. Reporting bias and knowledge acquisition. InProceedings of the 2013 workshop on Automated knowledge base construction, pp. 25–30,
work page 2013
-
[3]
Ha, D. and Schmidhuber, J. World models.arXiv preprint arXiv:1803.10122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://www.sciencedirect.com/science/article/pii/ S0749596X25000336
1016/j.jml.2025.104640. URL https://www.sciencedirect.com/science/article/pii/ S0749596X25000336. Hume, D.A Treatise of Human Nature. Oxford University Press,
-
[5]
Ivanitskiy, M. I., Spies, A. F., Räuker, T., Corlouer, G., Mathwin, C., Quirke, L., Rager, C., Shah, R., Valentine, D., Behn, C. D., et al. Structured world representations in maze-solving transformers. arXiv preprint arXiv:2312.02566,
-
[6]
Adam: A Method for Stochastic Optimization
URL https: //arxiv.org/abs/1412.6980. Koehler, D. J. Explanation, imagination, and confidence in judgment.Psychological bulletin, 110(3): 499,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
J., Davis, E., and Morgenstern, L
Levesque, H. J., Davis, E., and Morgenstern, L. The winograd schema challenge.KR, 2012:13th,
work page 2012
-
[8]
Li, B. Z., Guo, Z. C., and Andreas, J. (how) do language models track state?arXiv preprint arXiv:2503.02854,
-
[9]
Mallozzi, A., Vaidya, A., and Wallner, M. The Epistemology of Modality. In Zalta, E. N. and Nodelman, U. (eds.),The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Summer 2024 edition,
work page 2024
-
[10]
Milliere, R. and Buckner, C. A philosophical introduction to language models - part i: Continuity with classic debates.ArXiv, abs/2401.03910,
-
[11]
Panickssery, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A. M. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Petroni, F., Rocktäschel, T., Riedel, S., Lewis, P., Bakhtin, A., Wu, Y ., and Miller, A. Language models as knowledge bases? InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 2463–2473,
work page 2019
-
[13]
doi: 10.1016/j.cogdev.2008.12.006. Shtulman, A. and Carey, S. Improbable or impossible? how children reason about the possibility of extraordinary events.Child development, 78(3):1015–1032,
- [14]
-
[15]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1472. URL https://aclanthology.org/P19-1472/. A Classification Results for Models with<2B Parameters We present classification results from models with<2B parameters in Figure
-
[16]
We find mixed results across different classification methods, with overall worse performance than with models≥2B. B Classification Results for Adversarial Stimuli We highlight the performance of all classification methods on adversarial stimuli. We include lexically adversarial stimuli from Kauf et al. (2023) and semantically adversarial stimuli from Veg...
work page 2023
-
[17]
15 Table 3: Steering Generations using Gemma-2-2B
While not perfect, these examples show many instances of steering having the desired effect, rendering generations more improbable, impossible, or inconceivable. 15 Table 3: Steering Generations using Gemma-2-2B. Model Prefix Gemma-2-2B Someone measured the furniture using a... Steering Generations None tape measure, ruler, 1, measuring tape, laser level ...
work page 2024
-
[18]
how easy is the sentence to visualize, or to form an image of the sentence’s meaning in your mind?
Imageability:Ratings on a 7 point Likert scale, answering the question “how easy is the sentence to visualize, or to form an image of the sentence’s meaning in your mind?” Physical:Ratings on a 7 point Likert scale, answering the question “how does the sentence make you think of physical objects and/or physical causal interactions?” Places:Ratings on a 7 ...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.