Learning to Extract Rational Evidence via Reinforcement Learning for Retrieval-Augmented Generation
Pith reviewed 2026-05-19 04:11 UTC · model grok-4.3
The pith
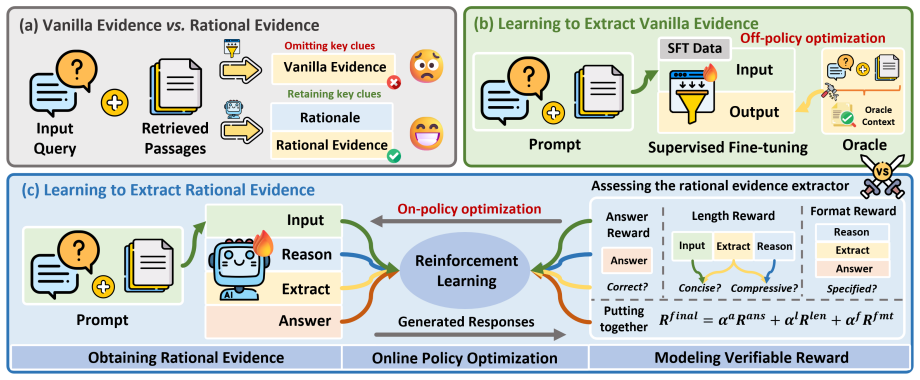
EviOmni trains models to reason about evidence before extracting it, using on-policy reinforcement learning with verifiable rewards to improve retrieval-augmented generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EviOmni integrates evidence reasoning and evidence extraction into one unified trajectory, followed by knowledge token masking to avoid information leakage, optimized via on-policy reinforcement learning with verifiable rewards in terms of answer, length, and format.
What carries the argument
Unified trajectory sequencing evidence reasoning before extraction, trained by on-policy reinforcement learning with verifiable rewards for answer, length, and format plus knowledge token masking.
If this is right
- The method produces compact and high-quality evidence suitable for RAG.
- It raises accuracy on downstream tasks across five benchmark datasets.
- It works with both traditional and agentic RAG systems.
- Knowledge token masking prevents information leakage during optimization.
Where Pith is reading between the lines
- The same reasoning-before-extraction pattern could extend to multi-step agent workflows to keep evidence quality consistent across turns.
- Varying the reward weights might let practitioners trade evidence brevity for completeness in specialized domains.
- Rational evidence selection may indirectly lower hallucination rates by limiting generation to traceable clues.
Load-bearing premise
On-policy reinforcement learning guided by rewards for answer correctness, length, and format will produce evidence that generalizes to unseen queries and retrieval distributions without reward hacking or extra tuning.
What would settle it
Running the trained model on a fresh dataset with different retrieval noise patterns and finding no gain in answer accuracy or evidence relevance compared with simple extraction baselines would falsify the central claim.
Figures






read the original abstract
Retrieval-Augmented Generation (RAG) effectively improves the accuracy of Large Language Models (LLMs). However, retrieval noises significantly undermine the quality of LLMs' generation, necessitating the development of denoising mechanisms. Previous works extract evidence straightforwardly without deep thinking, which may risk filtering out key clues and struggle with generalization. To this end, we propose EviOmni, which learns to extract rational evidence via reasoning first and then extracting. Specifically, EviOmni integrates evidence reasoning and evidence extraction into one unified trajectory, followed by knowledge token masking to avoid information leakage, optimized via on-policy reinforcement learning with verifiable rewards in terms of answer, length, and format. Extensive experiments on five benchmark datasets show the superiority of EviOmni, which provides compact and high-quality evidence, enhances the accuracy of downstream tasks, and supports both traditional and agentic RAG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EviOmni, a method for denoising retrieval in RAG systems. It integrates evidence reasoning and evidence extraction into one unified trajectory, applies knowledge token masking to prevent leakage, and optimizes the policy via on-policy reinforcement learning using composite verifiable rewards on final answer correctness, evidence length, and format compliance. Experiments across five benchmark datasets are reported to show that EviOmni produces more compact, higher-quality evidence and improves downstream accuracy in both standard and agentic RAG settings.
Significance. If the central claims hold after addressing the issues below, the work would provide a concrete demonstration that on-policy RL with terminal verifiable rewards can train LLMs to perform explicit reasoning before evidence extraction, potentially offering a more generalizable alternative to direct extraction baselines. The unified trajectory plus masking design is a clear technical contribution worth further exploration.
major comments (2)
- [§3] §3 (Method): The reward is defined solely on the terminal answer correctness, length, and format after the full trajectory. This does not include an explicit term that penalizes or rewards causal dependence between the reasoning tokens and the subsequently extracted evidence span. Consequently, the policy can satisfy the reward by emitting locally coherent reasoning that is decoupled from the evidence actually used, undermining the claim that the method learns 'rational' evidence selection.
- [§4] §4 (Experiments): No ablation is reported that isolates the contribution of the reasoning step within the unified trajectory (e.g., comparing against a version that performs extraction without the preceding reasoning tokens). In addition, the abstract and experimental section provide no details on reward-component weighting, statistical significance testing across runs, or comparison against strong RL baselines that use the same terminal rewards but lack the unified reasoning+extraction structure.
minor comments (2)
- [§3] Clarify in the method section how the knowledge-token masking is applied during the on-policy rollouts and whether it affects the gradient computation for the reasoning portion of the trajectory.
- [Abstract and §4] The abstract states superiority on five benchmarks; the experimental section should explicitly list the five datasets and report per-dataset metrics with standard deviations.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and constructive suggestions. We address each major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The reward is defined solely on the terminal answer correctness, length, and format after the full trajectory. This does not include an explicit term that penalizes or rewards causal dependence between the reasoning tokens and the subsequently extracted evidence span. Consequently, the policy can satisfy the reward by emitting locally coherent reasoning that is decoupled from the evidence actually used, undermining the claim that the method learns 'rational' evidence selection.
Authors: We thank the referee for highlighting this important aspect of the reward design. While the reward is indeed defined on the terminal outcomes, the unified trajectory structure ensures that reasoning precedes extraction, and the knowledge token masking prevents the model from bypassing the reasoning step to directly access information. This setup incentivizes the generation of reasoning that is useful for selecting the evidence, as poor reasoning would lead to suboptimal evidence and lower rewards. Nevertheless, to more rigorously demonstrate the causal dependence, we will add an ablation study and qualitative analysis in the revised manuscript showing that removing or randomizing the reasoning step degrades performance. We will also discuss this in §3. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation is reported that isolates the contribution of the reasoning step within the unified trajectory (e.g., comparing against a version that performs extraction without the preceding reasoning tokens). In addition, the abstract and experimental section provide no details on reward-component weighting, statistical significance testing across runs, or comparison against strong RL baselines that use the same terminal rewards but lack the unified reasoning+extraction structure.
Authors: We agree that these details and comparisons are valuable. In the revised version, we will: (1) report an ablation comparing the full EviOmni to a variant without the reasoning tokens (i.e., direct extraction under the same RL setup); (2) provide the exact weighting of reward components (e.g., λ_answer, λ_length, λ_format) used in our experiments; (3) include statistical significance tests (e.g., paired t-tests or bootstrap) across 3-5 runs with different random seeds; and (4) add comparisons to strong RL baselines that apply the same terminal rewards but use separate or non-unified structures for reasoning and extraction. These changes will be reflected in §4 and the appendix. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via external verifiable rewards
full rationale
The paper's central mechanism integrates reasoning and extraction into a unified trajectory optimized by on-policy RL using rewards defined directly on external verifiable signals (answer correctness against ground truth, length, and format compliance). These rewards are not fitted parameters internal to the model nor derived from prior self-citations; they reference independent evaluation criteria. No equations or steps reduce the claimed prediction or result to the inputs by construction. The method is presented as an empirical proposal validated on benchmark datasets, with no load-bearing uniqueness theorems or ansatzes imported from overlapping prior work. This qualifies as a normal non-circular finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption On-policy reinforcement learning with verifiable rewards for answer correctness, length, and format will produce generalizable evidence extraction policies.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguis- tics. Lingjie Jiang, Xun Wu, Shaohan Huang, Qingxiu Dong, Zewen Chi, Li Dong, Xingxing Zhang, Tengchao Lv, Lei Cui, and Furu Wei. 2025. Think only when you need with large hybrid- reasoning models. CoRR, abs/2505.14631. Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie ...
-
[2]
Longrag: Enhancing retrieval- augmented generation with long-context llms. CoRR, abs/2406.15319. Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search- r1: Training llms to reason and leverage search engines with reinforcement learning. CoRR, abs/2503.09516. Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoye...
-
[3]
Few-shot reranking for multi-hop QA via language model prompting. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), ACL 2023, Toronto, Canada, July 9- 14, 2023 , pages 15882–15897. Association for Computational Linguistics. Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Col...
-
[4]
Learning to filter context for retrieval- augmented generation. CoRR, abs/2311.08377. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neu- ral Information Processing Systems 35: Annual Conferenc...
-
[5]
An efficient memory-augmented trans- former for knowledge-intensive NLP tasks. In Proceedings of the 2022 Conference on Empiri- cal Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emi- rates, December 7-11, 2022 , pages 5184–5196. Association for Computational Linguistics. Fangyuan Xu, Weijia Shi, and Eunsol Choi. 2024. RECOMP: ...
-
[6]
Read the given question and use the documents provided to answer the question
-
[7]
Question: {question} Document: {document} Answer: Table 7: The prompt for retrieval-augmented QA
If the documents don’t work, please an- swer the question based on your own knowledge. Question: {question} Document: {document} Answer: Table 7: The prompt for retrieval-augmented QA. Prompt for Closed-book QA [Instruction] You are a helpful assistant. Your task is:
-
[8]
Read the given question and then an- swer the question directly
-
[9]
Question: {question} Answer: Table 8: The prompt for closed-book QA
Give a short answer to the question based on your own knowledge. Question: {question} Answer: Table 8: The prompt for closed-book QA. Prompt for CoT Generation [Instruction] You are a helpful assistant. Your task is: Read the given documents, and answer the question below. Question: {question} Document: {document} Let’s think step by step. Table 9: The pr...
-
[10]
Question Analysis: Analyze the question to understand the specific information they are seeking
In the <reason></reason> tag, perform the following steps. Question Analysis: Analyze the question to understand the specific information they are seeking. Identify the key concepts, entities, and relationships involved. Passage Analysis: For each passage, carefully read and identify sentences or phrases that are useful for answering the given question
-
[11]
Organize the information logically and concisely
In the <extract></extract> tag, synthesize useful information from the passages into a coherent narrative. Organize the information logically and concisely
-
[12]
If none of them work, please answer the question based on your knowledge
In <answer></answer> tags, give a short answer to the given question, based on the passages, reasoning information, and extracted knowledge. If none of them work, please answer the question based on your knowledge. Question: {question} Passages: {passages} Table 10: The prompt for rational evidence extraction, where generation is terminated when encounter...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.