Diffusion Models for Solving Inverse Problems via Posterior Sampling with Piecewise Guidance
Pith reviewed 2026-05-19 03:00 UTC · model grok-4.3
The pith
A piecewise guidance scheme lets diffusion models solve inverse problems faster while preserving sample quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
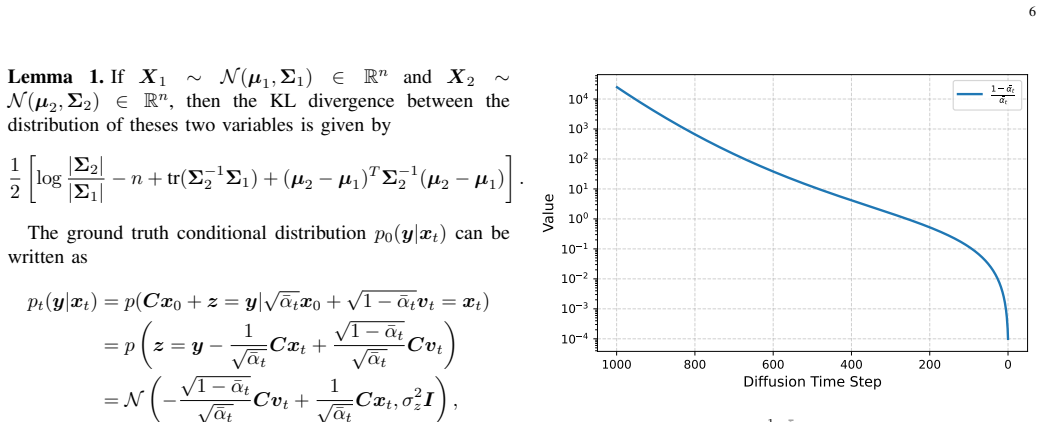
The paper establishes that defining the guidance term as a piecewise function of the diffusion timestep allows the use of different approximations during high-noise versus low-noise phases. This balances computational efficiency against the accuracy of the resulting posterior samples. The resulting method applies to a variety of inverse problems, explicitly accounts for measurement noise, and delivers measurable speedups on image restoration benchmarks while maintaining reconstruction fidelity.
What carries the argument
The piecewise guidance scheme, which switches the form of the guidance approximation according to the current diffusion timestep to trade off cost and fidelity.
If this is right
- The framework applies to multiple inverse problems without task-specific retraining.
- Measurement noise is incorporated explicitly into the posterior sampling process.
- Inference time is reduced by 25 percent on inpainting with random and center masks relative to the pseudoinverse-guided baseline.
- Inference time is reduced by 23 percent and 24 percent on 4x and 8x super-resolution, respectively, with negligible loss in PSNR and SSIM.
Where Pith is reading between the lines
- Optimizing the timestep threshold where the approximation switches could produce further speed gains on new tasks.
- The same piecewise strategy may transfer to other conditional generation settings that rely on timestep-dependent guidance.
Load-bearing premise
The piecewise function of the diffusion timestep can safely use different approximations in high-noise versus low-noise phases without materially harming the accuracy of the posterior samples.
What would settle it
Re-running the reported inpainting and super-resolution experiments with a single non-piecewise guidance approximation throughout all timesteps and finding substantially larger quality degradation than the negligible loss claimed would falsify the efficiency-accuracy balance.
Figures













read the original abstract
Diffusion models are powerful tools for sampling from high-dimensional distributions by progressively transforming pure noise into structured data through a denoising process. When equipped with a guidance mechanism, these models can also generate samples from conditional distributions. In this paper, a novel diffusion-based framework is introduced for solving inverse problems using a piecewise guidance scheme. The guidance term is defined as a piecewise function of the diffusion timestep, facilitating the use of different approximations during high-noise and low-noise phases. This design is shown to effectively balance computational efficiency with the accuracy of the guidance term. Unlike task-specific approaches that require retraining for each problem, the proposed method is problem-agnostic and readily adaptable to a variety of inverse problems. Additionally, it explicitly incorporates measurement noise into the reconstruction process. The effectiveness of the proposed framework is demonstrated through extensive experiments on image restoration tasks, specifically image inpainting and super-resolution. Using a class conditional diffusion model for recovery, compared to the \blue{pseudoinverse-guided diffusion model (\textrm{\(\Pi\)}GDM) baseline}, the proposed framework achieves a reduction in inference time of \(25\%\) for inpainting with both random and center masks, and \(23\%\) and \(24\%\) for \(4\times\) and \(8\times\) super-resolution tasks, respectively, while incurring only negligible loss in PSNR and SSIM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a diffusion-based framework for solving inverse problems via posterior sampling with a piecewise guidance scheme. The guidance term is defined as a piecewise function of the diffusion timestep to apply different approximations in high-noise versus low-noise regimes, aiming to balance efficiency and accuracy. The method is presented as problem-agnostic, incorporates measurement noise explicitly, and is evaluated on image inpainting (random and center masks) and super-resolution (4× and 8×) tasks using a class-conditional diffusion model. It reports 25% inference-time reduction for inpainting and 23–24% for super-resolution relative to the ΠGDM baseline, with only negligible drops in PSNR and SSIM.
Significance. If the piecewise approximation is shown to preserve posterior accuracy, the framework would provide a practical, general-purpose acceleration technique for conditional diffusion sampling in inverse problems, avoiding task-specific retraining while explicitly handling measurement noise. The empirical speedups on standard image-restoration benchmarks would be a useful contribution to the efficiency literature in this area.
major comments (2)
- [§3] §3 (Proposed Method): The piecewise guidance definition and the specific approximations chosen for the high-noise and low-noise phases are not accompanied by any error analysis, bias bounds, or propagation study showing that residuals from the high-noise approximation are corrected in the low-noise phase. This is load-bearing for the central claim that the scheme achieves speedups with negligible quality loss.
- [§4] §4 (Experiments): The reported speedups (25% for inpainting, 23% and 24% for 4×/8× super-resolution) and the assertion of “negligible loss” in PSNR/SSIM are given without error bars, standard deviations across runs, or ablation on the timestep switch point, so the robustness of the quality-parity claim cannot be assessed from the presented data.
minor comments (2)
- Clarify the exact functional form of the piecewise guidance (including how the switch point is selected) and provide pseudocode or a small algorithmic box for reproducibility.
- The abstract and introduction should explicitly state the datasets, diffusion backbone, and number of function evaluations used for both the proposed method and the ΠGDM baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve the theoretical grounding and experimental robustness of the work.
read point-by-point responses
-
Referee: [§3] §3 (Proposed Method): The piecewise guidance definition and the specific approximations chosen for the high-noise and low-noise phases are not accompanied by any error analysis, bias bounds, or propagation study showing that residuals from the high-noise approximation are corrected in the low-noise phase. This is load-bearing for the central claim that the scheme achieves speedups with negligible quality loss.
Authors: We acknowledge the value of a formal error analysis for supporting the central claim. In the revised manuscript we will add a dedicated paragraph in §3 that (i) characterizes the approximation error in the high-noise regime as being dominated by the large diffusion noise variance, (ii) notes that the low-noise regime reverts to the exact guidance term used by ΠGDM, and (iii) provides a short propagation argument showing that any residual bias introduced early is subsequently corrected by the accurate guidance steps. While deriving tight, non-asymptotic bias bounds for the full iterative sampler remains technically involved, we will include this qualitative analysis together with empirical intermediate-sample visualizations that illustrate the correction effect. These additions directly address the load-bearing concern. revision: partial
-
Referee: [§4] §4 (Experiments): The reported speedups (25% for inpainting, 23% and 24% for 4×/8× super-resolution) and the assertion of “negligible loss” in PSNR/SSIM are given without error bars, standard deviations across runs, or ablation on the timestep switch point, so the robustness of the quality-parity claim cannot be assessed from the presented data.
Authors: We agree that variability measures and ablation studies are necessary to substantiate the quality-parity claim. In the revised §4 we will (i) rerun all experiments over five independent random seeds and report mean ± standard deviation for PSNR and SSIM, (ii) attach error bars to the reported inference-time reductions, and (iii) add a new ablation table that varies the piecewise switch timestep (e.g., t = 400, 600, 800) while keeping all other settings fixed. These changes will allow readers to assess both statistical reliability and sensitivity to the design choice. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The paper introduces a piecewise guidance scheme for diffusion-based posterior sampling in inverse problems and validates it empirically on inpainting and super-resolution tasks, reporting speedups versus the ΠGDM baseline with negligible PSNR/SSIM degradation. No equations, parameter-fitting procedures, or self-citation chains are present that would reduce any claimed prediction or result to an input by construction. The central efficiency and accuracy claims rest on experimental outcomes rather than tautological redefinitions or fitted quantities renamed as predictions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The guidance term is defined as a piecewise function of the diffusion timestep, facilitating the use of different approximations during high-noise and low-noise phases.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1... KL divergence... 1/2σ²z (1-ᾱt)/ᾱt ∥Cvt∥²₂
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Diffusion Models Beat GANs on Image Synthesis,
P. Dhariwal and A. Nichol, “Diffusion Models Beat GANs on Image Synthesis,” in Advances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 8780–
work page 2021
-
[2]
[Online]. Available: https://proceedings.neurips.cc/paper/2021/ hash/49ad23d1ec9fa4bd8d77d02681df5cfa-Abstract.html
work page 2021
-
[3]
Label-Efficient Semantic Segmentation with Diffusion Models,
D. Baranchuk, A. V oynov, I. Rubachev, V . Khrulkov, and A. Babenko, “Label-Efficient Semantic Segmentation with Diffusion Models,” in Proc. of International Conference on Learning Representations , Oct. 2021. [Online]. Available: https://openreview.net/forum?id=SlxSY2UZQT
work page 2021
-
[4]
SegDiff: Image Segmentation with Diffusion Probabilistic Models,
T. Amit, T. Shaharbany, E. Nachmani, and L. Wolf, “SegDiff: Image Segmentation with Diffusion Probabilistic Models,” Sep. 2022, arXiv:2112.00390 [cs]. [Online]. Available: http://arxiv.org/abs/2112. 00390
-
[5]
Structured Denoising Diffusion Models in Discrete State- Spaces,
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. van den Berg, “Structured Denoising Diffusion Models in Discrete State- Spaces,” in Advances in Neural Information Processing Systems , vol. 34. Curran Associates, Inc., 2021, pp. 17 981–17 993. [Online]. Available: https://proceedings.neurips.cc/paper/2021/hash/ 958c530554f78bcd8e97125b70e6973d-Abstract.html
work page 2021
-
[6]
Argmax Flows and Multinomial Diffusion: Learning Categorical Distributions,
E. Hoogeboom, D. Nielsen, P. Jaini, P. Forr ´e, and M. Welling, “Argmax Flows and Multinomial Diffusion: Learning Categorical Distributions,” in Advances in Neural Information Processing Systems , vol. 34, 2021, pp. 12 454–12 465. [Online]. Available: https://proceedings.neurips.cc/ paper/2021/hash/67d96d458abdef21792e6d8e590244e7-Abstract.html
work page 2021
-
[7]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “DiffWave: A Versatile Diffusion Model for Audio Synthesis,” Mar. 2021. [Online]. Available: http://arxiv.org/abs/2009.09761
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
MR Image Denoising and Super- Resolution Using Regularized Reverse Diffusion,
H. Chung, E. S. Lee, and J. C. Ye, “MR Image Denoising and Super- Resolution Using Regularized Reverse Diffusion,” IEEE Transactions on Medical Imaging , vol. 42, no. 4, pp. 922–934, Apr. 2023. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9941138
-
[9]
High-Frequency Space Diffusion Model for Accelerated MRI,
C. Cao, Z.-X. Cui, Y . Wang, S. Liu, T. Chen, H. Zheng, D. Liang, and Y . Zhu, “High-Frequency Space Diffusion Model for Accelerated MRI,” IEEE Transactions on Medical Imaging , vol. 43, no. 5, pp. 1853–1865, May 2024. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/10385176 11
-
[10]
Diffusion Models: A Comprehensive Survey of Methods and Applications,
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang, “Diffusion Models: A Comprehensive Survey of Methods and Applications,” ACM Computing Surveys , vol. 56, no. 4, pp. 1–39, Nov. 2023
work page 2023
-
[11]
Denoising Diffusion Restoration Models,
B. Kawar, M. Elad, S. Ermon, and J. Song, “Denoising Diffusion Restoration Models,” Advances in Neural Information Processing Systems , vol. 35, pp. 23 593–23 606, Dec. 2022. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2022/hash/ 95504595b6169131b6ed6cd72eb05616-Abstract-Conference.html
work page 2022
-
[12]
The Perception-Distortion Tradeoff,
Y . Blau and T. Michaeli, “The Perception-Distortion Tradeoff,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2018, pp. 6228–6237. [Online]. Available: https: //ieeexplore.ieee.org/document/8578750/authors
-
[13]
Pseudoinverse-Guided Diffusion Models for Inverse Problems,
J. Song, A. Vahdat, M. Mardani, and J. Kautz, “Pseudoinverse-Guided Diffusion Models for Inverse Problems,” in Proc. of International Conference on Learning Representations , Sep. 2022. [Online]. Available: https://openreview.net/forum?id=9 gsMA8MRKQ
work page 2022
-
[14]
Y . Song, L. Shen, L. Xing, and S. Ermon, “Solving Inverse Problems in Medical Imaging with Score-Based Generative Models,” Jun. 2022, arXiv:2111.08005 [eess]. [Online]. Available: http://arxiv.org/abs/2111. 08005
-
[15]
Deep Learning Techniques for Inverse Problems in Imaging,
G. Ongie, A. Jalal, C. A. Metzler, R. G. Baraniuk, A. G. Dimakis, and R. Willett, “Deep Learning Techniques for Inverse Problems in Imaging,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 39–56, May 2020. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9084378
-
[16]
Plug-and-Play priors for model based reconstruction,
S. V . Venkatakrishnan, C. A. Bouman, and B. Wohlberg, “Plug-and-Play priors for model based reconstruction,” in IEEE Global Conference on Signal and Information Processing , pp. 945–948. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/6737048
-
[17]
The Little Engine That Could: Regularization by Denoising (RED),
Y . Romano, M. Elad, and P. Milanfar, “The Little Engine That Could: Regularization by Denoising (RED),” SIAM Journal on Imaging Sciences, vol. 10, no. 4, pp. 1804–1844, Jan. 2017. [Online]. Available: https://epubs.siam.org/doi/abs/10.1137/16M1102884
-
[18]
DeepRED: Deep Image Prior Powered by RED,
G. Mataev, M. Elad, and P. Milanfar, “DeepRED: Deep Image Prior Powered by RED,” Oct. 2019, arXiv:1903.10176 [cs]. [Online]. Available: http://arxiv.org/abs/1903.10176
-
[19]
Compressed Sensing using Generative Models,
A. Bora, A. Jalal, E. Price, and A. G. Dimakis, “Compressed Sensing using Generative Models,” in Proceedings of the 34th International Conference on Machine Learning . PMLR, Jul. 2017, pp. 537–546. [Online]. Available: https://proceedings.mlr.press/v70/bora17a.html
work page 2017
-
[20]
Intermediate Layer Optimization for Inverse Problems using Deep Generative Models,
G. Daras, J. Dean, A. Jalal, and A. G. Dimakis, “Intermediate Layer Optimization for Inverse Problems using Deep Generative Models,” Feb. 2021, arXiv:2102.07364 [cs]. [Online]. Available: http://arxiv.org/abs/2102.07364
-
[21]
PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models,
S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, “PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models,” 2020, pp. 2437–2445. [Online]. Available: https://openaccess.thecvf.com/content CVPR 2020/html/ Menon PULSE Self-Supervised Photo Upsampling via Latent Space Exploration of Generative CVPR 2020 paper.html
work page 2020
-
[22]
An Online Plug-and-Play Algorithm for Regularized Image Reconstruction,
Y . Sun, B. Wohlberg, and U. S. Kamilov, “An Online Plug-and-Play Algorithm for Regularized Image Reconstruction,” IEEE Transactions on Computational Imaging , vol. 5, no. 3, pp. 395–408, Sep
-
[23]
Available: https://ieeexplore.ieee.org/abstract/document/ 8616843
[Online]. Available: https://ieeexplore.ieee.org/abstract/document/ 8616843
-
[24]
Stochastic Solutions for Linear Inverse Problems using the Prior Implicit in a Denoiser,
Z. Kadkhodaie and E. Simoncelli, “Stochastic Solutions for Linear Inverse Problems using the Prior Implicit in a Denoiser,” in Advances in Neural Information Processing Systems , vol. 34, 2021, pp. 13 242– 13 254. [Online]. Available: https://proceedings.neurips.cc/paper/2021/ hash/6e28943943dbed3c7f82fc05f269947a-Abstract.html
work page 2021
-
[25]
Instance- Optimal Compressed Sensing via Posterior Sampling,
A. Jalal, S. Karmalkar, A. G. Dimakis, and E. Price, “Instance- Optimal Compressed Sensing via Posterior Sampling,” Jun. 2021, arXiv:2106.11438 [cs]. [Online]. Available: http://arxiv.org/abs/2106. 11438
-
[26]
SNIPS: Solving Noisy Inverse Problems Stochastically,
B. Kawar, G. Vaksman, and M. Elad, “SNIPS: Solving Noisy Inverse Problems Stochastically,” in Advances in Neural Information Processing Systems , vol. 34, 2021, pp. 21 757– 21 769. [Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2021/hash/b5c01503041b70d41d80e3dbe31bbd8c-Abstract.html
work page 2021
-
[27]
Stochastic Image Denoising by Sampling From the Posterior Distribution,
——, “Stochastic Image Denoising by Sampling From the Posterior Distribution,” 2021, pp. 1866–1875. [Online]. Available: https://openaccess.thecvf.com/content/ICCV2021W/AIM/html/Kawar Stochastic Image Denoising by Sampling From the Posterior Distribution ICCVW 2021 paper.html
work page 2021
-
[28]
H. Chung, B. Sim, and J. C. Ye, “Come-Closer-Diffuse-Faster: Accelerating Conditional Diffusion Models for Inverse Problems through Stochastic Contraction,” in Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun. 2022, pp. 12 403–12 412. [Online]. Available: https://ieeexplore.ieee.org/document/9879691/
-
[29]
Palette: Image-to-Image Diffusion Models,
C. Saharia, W. Chan, H. Chang, C. Lee, J. Ho, T. Salimans, D. Fleet, and M. Norouzi, “Palette: Image-to-Image Diffusion Models,” in ACM SIGGRAPH Conference Proceedings . Association for Computing Machinery, Jul. 2022, pp. 1–10. [Online]. Available: https://dl.acm.org/doi/10.1145/3528233.3530757
-
[30]
Image Super-Resolution via Iterative Refinement,
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, and M. Norouzi, “Image Super-Resolution via Iterative Refinement,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 45, no. 4, pp. 4713–4726, Apr. 2023. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9887996
-
[31]
M. Bertero, P. Boccacci, and C. D. Mol, Introduction to Inverse Problems in Imaging , 2nd ed. Boca Raton: CRC Press, Dec. 2021
work page 2021
-
[32]
Deep Learning and Inverse Problems,
A. Mohammad-Djafari, N. Chu, L. Wang, and L. Yu, “Deep Learning and Inverse Problems,” Sep. 2023, arXiv:2309.00802 [cs]. [Online]. Available: http://arxiv.org/abs/2309.00802
-
[33]
Inverse problems in astronomy,
I. Craig and J. Brown, “Inverse problems in astronomy,” Jan. 1986, publisher: Adam Hilger Ltd.,Accord, MA. [Online]. Available: https://www.osti.gov/biblio/5734250
-
[34]
Inverse problems: From regularization to Bayesian inference,
D. Calvetti and E. Somersalo, “Inverse problems: From regularization to Bayesian inference,” WIREs Computational Statistics , vol. 10, no. 3, p. e1427, 2018
work page 2018
-
[35]
Reverse-time diffusion equation models,
B. D. O. Anderson, “Reverse-time diffusion equation models,” Stochastic Processes and their Applications , vol. 12, no. 3, pp. 313–326, May 1982. [Online]. Available: https://www.sciencedirect. com/science/article/pii/0304414982900515
-
[36]
Approximating the Kullback Leibler Divergence Between Gaussian Mixture Models,
J. R. Hershey and P. A. Olsen, “Approximating the Kullback Leibler Divergence Between Gaussian Mixture Models,” in Proc. of IEEE International Conference on Acoustics, Speech and Signal Processing, vol. 4, Apr. 2007, pp. IV–317–IV–320. [Online]. Available: https://ieeexplore.ieee.org/document/4218101
-
[37]
ImageNet Large Scale Visual Recognition Challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision , vol. 115, no. 3, pp. 211–252, Dec. 2015. [Online]. Available: https://doi.org/10.1007/ s11263-015-0816-y
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.