Centralized Adaptive Sampling for Reliable Co-Training of Independent Multi-Agent Policies
Pith reviewed 2026-05-19 01:00 UTC · model grok-4.3
The pith
CoSER reduces joint sampling error more efficiently than independent sampling, increasing the reliability of independent policy gradient algorithms in multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Stochasticity in independent action sampling after collecting finite trajectories causes the joint data distribution to deviate from the expected joint on-policy distribution, leading to inaccurate gradient estimates and sub-optimal convergence. CoSER continually adapts a centralized behavior policy to place higher probability on joint actions that are under-sampled with respect to the current joint policy. This reduces joint sampling error and increases the reliability of independent policy gradient algorithms, defined as the probability of converging to an optimal joint policy.
What carries the argument
CoSER (Cooperative Sampling Error Reduction), which adapts a centralized behavior policy during data collection to prioritize under-sampled joint actions in the Centralized Training with Decentralized Execution setting.
Load-bearing premise
A centralized behavior policy can be trained and used to select joint actions without introducing new biases or violating the decentralized execution constraint in a way that invalidates the on-policy gradient estimates.
What would settle it
An experiment showing that CoSER does not reduce measured joint sampling error or does not increase the fraction of runs that reach optimal joint policies compared to independent sampling.
Figures













read the original abstract
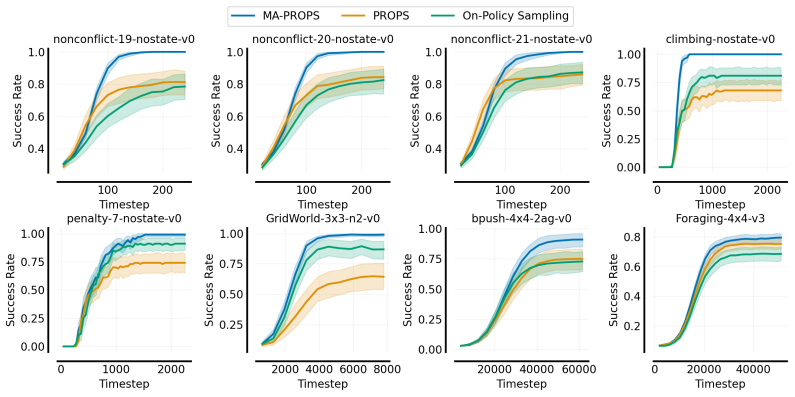
Independent on-policy policy gradient algorithms are widely used for multi-agent reinforcement learning (MARL) in cooperative and no-conflict games, but they are known to converge sub-optimally when each agent's individual policy gradient points away from an optimal joint equilibrium. Going beyond prior work, we observe that sub-optimal convergence can still arise even when the expected individual policy gradients of each agent point toward the optimal joint solution. After collecting a finite set of trajectories, stochasticity in independent action sampling can cause the joint data distribution to deviate from the expected joint on-policy distribution. This \textit{sampling error} w.r.t. the joint on-policy distribution produces inaccurate gradient estimates that can make agents converge sub-optimally. We hypothesize that joint sampling error can be reduced through coordinated action selection and that doing so will increase the reliability of policy gradient learning in MARL (i.e., the probability of converging to an optimal joint policy). To test this hypothesis, we first introduce an adaptive action sampling approach to reduce joint sampling error in the Centralized Training with Decentralized Execution setting. Our method, Cooperative Sampling Error Reduction (CoSER), continually adapts a centralized behavior policy to place higher probability on joint actions that are under-sampled w.r.t. the current joint policy. We then empirically evaluate CoSER on a diverse set of multi-agent games and demonstrate that (1) CoSER reduces joint sampling error more efficiently than independent on-policy sampling and (2) this reduction increases the reliability of independent policy gradient algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that independent on-policy policy gradient methods in multi-agent RL can converge sub-optimally due to finite-sample joint sampling error (deviation of realized joint action distribution from the expected product of individual policies), even when expected individual gradients point toward the joint optimum. It introduces CoSER, an adaptive centralized behavior policy in the CTDE setting that up-weights under-sampled joint actions relative to the current joint policy, and reports empirical results showing reduced joint sampling error and higher reliability (probability of reaching optimal joint policies) compared to independent sampling across diverse games.
Significance. If the central claim holds after addressing potential biases in the gradient estimates, the result would be significant for MARL: it isolates joint sampling error as a distinct, fixable source of unreliability in independent PG methods and demonstrates a practical centralized sampling fix that preserves decentralized execution. This could improve training stability in cooperative settings without requiring fully centralized policies or value functions.
major comments (2)
- [Abstract and §3 (CoSER description)] Abstract and CoSER method description: the paper states that joint actions are sampled from an adapted centralized behavior policy rather than from the product of the agents' independent policies, yet provides no importance-sampling correction (e.g., ratios ∏ π_i(a_i) / π_b(a)) or other unbiased estimator for the on-policy gradients. Because the data distribution differs from the joint on-policy distribution, standard REINFORCE-style updates applied directly to these trajectories are biased; this is load-bearing for the claim that observed reliability gains are attributable to reduced sampling error rather than to biased updates.
- [Empirical evaluation (results tables/figures)] Empirical evaluation sections: the manuscript reports that CoSER increases reliability but does not include error bars, statistical significance tests across random seeds, or controls for confounding factors such as the additional compute or model capacity required to train and query the centralized behavior policy. Without these, it is difficult to assess whether the reliability gains are robust or merely reflect extra resources.
minor comments (2)
- [§2 or §3] Notation for the joint policy and behavior policy should be introduced explicitly with equations early in the method section to clarify how the centralized sampler relates to the product of individual policies.
- [Abstract and introduction] The abstract and introduction would benefit from a brief statement of the precise on-policy estimator used (e.g., REINFORCE, actor-critic) and whether any off-policy correction is applied.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below and indicate the revisions we have made or plan to make in the updated version.
read point-by-point responses
-
Referee: [Abstract and §3 (CoSER description)] Abstract and CoSER method description: the paper states that joint actions are sampled from an adapted centralized behavior policy rather than from the product of the agents' independent policies, yet provides no importance-sampling correction (e.g., ratios ∏ π_i(a_i) / π_b(a)) or other unbiased estimator for the on-policy gradients. Because the data distribution differs from the joint on-policy distribution, standard REINFORCE-style updates applied directly to these trajectories are biased; this is load-bearing for the claim that observed reliability gains are attributable to reduced sampling error rather than to biased updates.
Authors: We appreciate the referee pointing out this critical aspect of the method. The CoSER behavior policy is indeed distinct from the product of individual policies to reduce joint sampling error. To maintain unbiased estimates of the on-policy gradients, we agree that an importance sampling correction is required. In the revised manuscript, we have incorporated the importance sampling ratio ∏_i π_i(a_i) / π_b(a) into the gradient estimator. This ensures that the updates remain unbiased with respect to the joint on-policy distribution while still benefiting from the adaptive sampling that reduces variance in the realized joint distribution. We have updated the method description in Section 3 and added a formal derivation in the appendix demonstrating unbiasedness of the corrected estimator. revision: yes
-
Referee: [Empirical evaluation (results tables/figures)] Empirical evaluation sections: the manuscript reports that CoSER increases reliability but does not include error bars, statistical significance tests across random seeds, or controls for confounding factors such as the additional compute or model capacity required to train and query the centralized behavior policy. Without these, it is difficult to assess whether the reliability gains are robust or merely reflect extra resources.
Authors: We acknowledge the need for more rigorous statistical analysis in the empirical sections. We have revised the evaluation to include error bars showing the standard error across 20 independent random seeds for all reported reliability metrics. Additionally, we now report results of Wilcoxon signed-rank tests to assess statistical significance of the improvements over baselines. To address potential confounding due to extra compute or capacity, we have included a new set of experiments where we allocate equivalent additional resources to the baseline methods (e.g., by increasing the size of individual policy networks). The results show that the gains from CoSER persist even under these controls. These updates are reflected in the revised Figures 3-5 and a new subsection in Section 5. revision: yes
Circularity Check
No significant circularity: empirical claims rest on external validation
full rationale
The paper defines joint sampling error as the deviation between finite-sample joint action frequencies and the product of independent policies, then constructs CoSER as an adaptive centralized behavior policy that up-weights under-sampled joints. The central claims—that CoSER reduces this error more efficiently than independent sampling and thereby increases policy-gradient reliability—are supported by empirical measurements on multiple games rather than by any equation that equates the output to the input by construction. No self-citation chains, fitted parameters renamed as predictions, or uniqueness theorems imported from prior author work appear as load-bearing steps. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost/FunctionalEquation.lean; Foundation/RealityFromDistinction.leanwashburn_uniqueness_aczel; reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MA-PROPS samples actions from a separate data collection policy and periodically updates this policy to increase the probability of under-sampled joint actions... DKL(πD(·|s)∥π(·|s)) = Op(1/m²) under MA-PROPS
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The dynamics of reinforcement learning in cooperative multiagent systems
Caroline Claus and Craig Boutilier. The dynamics of reinforcement learning in cooperative multiagent systems. AAAI/IAAI, 1998(746-752):2, 1998
work page 1998
-
[2]
Contrasting centralized and decentralized critics in multi-agent reinforcement learning
Xueguang Lyu, Yuchen Xiao, Brett Daley, and Christopher Amato. Contrasting centralized and decentralized critics in multi-agent reinforcement learning. arXiv preprint arXiv:2102.04402, 2021
-
[4]
Pareto actor-critic for equilibrium selection in multi-agent reinforcement learning
Filippos Christianos, Georgios Papoudakis, and Stefano V Albrecht. Pareto actor-critic for equilibrium selection in multi-agent reinforcement learning. arXiv preprint arXiv:2209.14344, 2022
-
[5]
Is indepen- dent learning all you need in the starcraft multi-agent challenge?
Christian Schroeder De Witt, Tarun Gupta, Denys Makoviichuk, Viktor Makoviychuk, Philip HS Torr, Mingfei Sun, and Shimon Whiteson. Is independent learning all you need in the starcraft multi-agent challenge? arXiv preprint arXiv:2011.09533, 2020
-
[6]
The surprising effectiveness of ppo in cooperative multi-agent games
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games. Advances in neural information processing systems, 35:24611–24624, 2022
work page 2022
-
[7]
Smarts: An open-source scalable multi-agent rl training school for autonomous driving
Ming Zhou, Jun Luo, Julian Villella, Yaodong Yang, David Rusu, Jiayu Miao, Weinan Zhang, Montgomery Alban, Iman Fadakar, Zheng Chen, et al. Smarts: An open-source scalable multi-agent rl training school for autonomous driving. In Conference on robot learning, pages 264–285. PMLR, 2021
work page 2021
-
[8]
Reinforcement learning: An introduction
Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[9]
Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks,
Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V Albrecht. Benchmark- ing multi-agent deep reinforcement learning algorithms in cooperative tasks. arXiv preprint arXiv:2006.07869, 2020
-
[10]
On-policy policy gradient reinforcement learning without on-policy sampling
Nicholas E Corrado and Josiah P Hanna. On-policy policy gradient reinforcement learning without on-policy sampling. arXiv preprint arXiv:2311.08290, 2023
-
[11]
Robust on-policy sampling for data-efficient policy evaluation in reinforcement learning
Rujie Zhong, Duohan Zhang, Lukas Schäfer, Stefano Albrecht, and Josiah Hanna. Robust on-policy sampling for data-efficient policy evaluation in reinforcement learning. Advances in Neural Information Processing Systems, 35:37376–37388, 2022
work page 2022
-
[12]
Revar: Strengthening policy evaluation via reduced variance sampling
Subhojyoti Mukherjee, Josiah P Hanna, and Robert D Nowak. Revar: Strengthening policy evaluation via reduced variance sampling. In Uncertainty in Artificial Intelligence , pages 1413–1422. PMLR, 2022
work page 2022
-
[13]
Variance-optimal augmentation logging for counterfactual evaluation in contextual bandits
Aaron David Tucker and Thorsten Joachims. Variance-optimal augmentation logging for counterfactual evaluation in contextual bandits. arXiv preprint arXiv:2202.01721, 2022
-
[14]
Safe exploration for efficient policy evaluation and comparison
Runzhe Wan, Branislav Kveton, and Rui Song. Safe exploration for efficient policy evaluation and comparison. In International Conference on Machine Learning , pages 22491–22511. PMLR, 2022
work page 2022
-
[15]
Active offline policy selection
Ksenia Konyushova, Yutian Chen, Thomas Paine, Caglar Gulcehre, Cosmin Paduraru, Daniel J Mankowitz, Misha Denil, and Nando de Freitas. Active offline policy selection. Advances in Neural Information Processing Systems, 34:24631–24644, 2021
work page 2021
-
[16]
Eligibility traces for off-policy policy evaluation
Doina Precup. Eligibility traces for off-policy policy evaluation. Computer Science Department Faculty Publication Series, page 80, 2000
work page 2000
-
[17]
Stochastic variance-reduced policy gradient
Matteo Papini, Damiano Binaghi, Giuseppe Canonaco, Matteo Pirotta, and Marcello Restelli. Stochastic variance-reduced policy gradient. In International conference on machine learning, pages 4026–4035. PMLR, 2018. 11
work page 2018
-
[18]
Policy opti- mization via importance sampling
Alberto Maria Metelli, Matteo Papini, Francesco Faccio, and Marcello Restelli. Policy opti- mization via importance sampling. Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[19]
Importance sampling in reinforcement learning with an estimated behavior policy
Josiah P Hanna, Scott Niekum, and Peter Stone. Importance sampling in reinforcement learning with an estimated behavior policy. Machine Learning, 110(6):1267–1317, 2021
work page 2021
-
[20]
Pavse, Ishan Durugkar, Josiah P
Brahma S. Pavse, Ishan Durugkar, Josiah P. Hanna, and Peter Stone. Reducing sampling error in batch temporal difference learning. In International Conference on Machine Learning, 2020
work page 2020
-
[21]
Toward minimax off-policy value estimation
Lihong Li, Rémi Munos, and Csaba Szepesvári. Toward minimax off-policy value estimation. In Artificial Intelligence and Statistics, pages 608–616. PMLR, 2015
work page 2015
-
[22]
Efficient counterfactual learning from bandit feedback
Yusuke Narita, Shota Yasui, and Kohei Yata. Efficient counterfactual learning from bandit feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 4634–4641, 2019
work page 2019
-
[23]
Friend-or-foe q-learning in general-sum games
Michael L Littman et al. Friend-or-foe q-learning in general-sum games. In ICML, volume 1, pages 322–328, 2001
work page 2001
-
[24]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value- decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning. Journal of Machine Learning Research, 21(178):1–51, 2020
work page 2020
-
[26]
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning
Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Earl Hostallero, and Yung Yi. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In International conference on machine learning, pages 5887–5896. PMLR, 2019
work page 2019
-
[27]
Laëtitia Matignon, Guillaume J Laurent, and Nadine Le Fort-Piat. Hysteretic q-learning: an algorithm for decentralized reinforcement learning in cooperative multi-agent teams. In 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages 64–69. IEEE, 2007
work page 2007
-
[28]
Lenient Multi-Agent Deep Reinforcement Learning
Gregory Palmer, Karl Tuyls, Daan Bloembergen, and Rahul Savani. Lenient multi-agent deep reinforcement learning. arXiv preprint arXiv:1707.04402, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Optimistic multi-agent policy gradient
Wenshuai Zhao, Yi Zhao, Zhiyuan Li, Juho Kannala, and Joni Pajarinen. Optimistic multi-agent policy gradient. arXiv preprint arXiv:2311.01953, 2023
-
[30]
Maven: Multi-agent variational exploration
Anuj Mahajan, Tabish Rashid, Mikayel Samvelyan, and Shimon Whiteson. Maven: Multi-agent variational exploration. Advances in neural information processing systems, 32, 2019
work page 2019
-
[31]
Influence-based multi-agent exploration
Tonghan Wang, Jianhao Wang, Yi Wu, and Chongjie Zhang. Influence-based multi-agent exploration. arXiv preprint arXiv:1910.05512, 2019
-
[32]
Cooperative exploration for multi-agent deep reinforcement learning
Iou-Jen Liu, Unnat Jain, Raymond A Yeh, and Alexander Schwing. Cooperative exploration for multi-agent deep reinforcement learning. In International conference on machine learning, pages 6826–6836. PMLR, 2021
work page 2021
-
[33]
Pengyi Li, Hongyao Tang, Tianpei Yang, Xiaotian Hao, Tong Sang, Yan Zheng, Jianye Hao, Matthew E Taylor, Wenyuan Tao, Zhen Wang, et al. Pmic: Improving multi-agent reinforcement learning with progressive mutual information collaboration. arXiv preprint arXiv:2203.08553, 2022
-
[34]
Uneven: Universal value exploration for multi-agent reinforcement learning
Tarun Gupta, Anuj Mahajan, Bei Peng, Wendelin Böhmer, and Shimon Whiteson. Uneven: Universal value exploration for multi-agent reinforcement learning. In International Conference on Machine Learning, pages 3930–3941. PMLR, 2021. 12
work page 2021
-
[35]
Episodic multi-agent reinforcement learning with curiosity- driven exploration
Lulu Zheng, Jiarui Chen, Jianhao Wang, Jiamin He, Yujing Hu, Yingfeng Chen, Changjie Fan, Yang Gao, and Chongjie Zhang. Episodic multi-agent reinforcement learning with curiosity- driven exploration. Advances in Neural Information Processing Systems, 34:3757–3769, 2021
work page 2021
-
[36]
Self-motivated multi- agent exploration
Shaowei Zhang, Jiahan Cao, Lei Yuan, Yang Yu, and De-Chuan Zhan. Self-motivated multi- agent exploration. arXiv preprint arXiv:2301.02083, 2023
-
[37]
High- dimensional continuous control using generalized advantage estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. In International Conference on Learning Representations (ICLR), 2016
work page 2016
-
[38]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning. Reinforcement learning, pages 5–32, 1992
work page 1992
-
[39]
Sham M Kakade. A natural policy gradient. Advances in neural information processing systems, 14, 2001
work page 2001
-
[40]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In International conference on machine learning, pages 1889–1897. PMLR, 2015
work page 2015
-
[41]
Asynchronous methods for deep reinforce- ment learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforce- ment learning. In International conference on machine learning, pages 1928–1937. PMLR, 2016
work page 1928
-
[42]
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In International conference on machine learning, pages 1407–1416. PMLR, 2018
work page 2018
-
[43]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
Policy gradient meth- ods for reinforcement learning with function approximation
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient meth- ods for reinforcement learning with function approximation. Advances in neural information processing systems, 12, 1999
work page 1999
-
[46]
Deterministic policy gradient algorithms
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. In International conference on machine learning, pages 387–395. Pmlr, 2014
work page 2014
-
[47]
arXiv preprint arXiv:2109.11251 , year=
Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang. Trust region policy optimisation in multi-agent reinforcement learning. arXiv preprint arXiv:2109.11251, 2021
-
[48]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[49]
Value-decomposition multi-agent proximal policy optimization
Yanhao Ma and Jie Luo. Value-decomposition multi-agent proximal policy optimization. In 2022 China Automation Congress (CAC), pages 3460–3464. IEEE, 2022
work page 2022
-
[50]
Heterogeneous-agent reinforcement learning
Yifan Zhong, Jakub Grudzien Kuba, Xidong Feng, Siyi Hu, Jiaming Ji, and Yaodong Yang. Heterogeneous-agent reinforcement learning. Journal of Machine Learning Research, 25(32): 1–67, 2024
work page 2024
-
[51]
Shared experience actor-critic for multi-agent reinforcement learning
Filippos Christianos, Lukas Schäfer, and Stefano Albrecht. Shared experience actor-critic for multi-agent reinforcement learning. Advances in neural information processing systems, 33: 10707–10717, 2020. 13
work page 2020
-
[52]
Multi-agent reinforcement learning: Foundations and modern approaches
Stefano V Albrecht, Filippos Christianos, and Lukas Schäfer. Multi-agent reinforcement learning: Foundations and modern approaches. MIT Press, 2024
work page 2024
-
[53]
Wendelin Böhmer, Vitaly Kurin, and Shimon Whiteson. Deep coordination graphs. In Interna- tional Conference on Machine Learning, pages 980–991. PMLR, 2020
work page 2020
-
[54]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[55]
Shengyi Huang, Rousslan Fernand Julien Dossa, Chang Ye, Jeff Braga, Dipam Chakraborty, Kinal Mehta, and João G.M. Araújo. Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms. Journal of Machine Learning Research, 23(274):1–18, 2022. URL http://jmlr.org/papers/v23/21-1342.html. 14 Appendix Table of Contents A Converg...
work page 2022
-
[56]
DKL(πD(·|s)∥π(·|s)) = Op 1 m2 under MA-PROPS while DKL(πD(·|s)∥π(·|s)) = Op 1 m under on-policy sampling
-
[57]
DKL(πD,i(·|s)∥πi(·|s)) = Op 1 m2 under MA-PROPS while DKL(πD,i(·|s)∥πi(·|s)) = Op 1 m under on-policy sampling where Op denotes stochastic boundedness. Proof. Since the behavior policy π(a|s) =Qn i=1 πi(a|si) is a single agent mapping joint states to joint actions, we can immediately apply the convergence result from Theorem 3 to obtain the conver- gence ...
-
[58]
Sampling error curves for RL training in GridWorld, Climbing game, and Penalty game (Fig. 10)
-
[59]
Training curves for all 21 distinct 2 × 2 no-conflict matrix games using MAPPO (Fig. 11) and IPPO (Fig. 12)
-
[60]
Sampling error curves for RL training in all 21 distinct 2 × 2 no-conflict matrix games (Fig. 13 and Fig. 14)
-
[61]
Training curves for BoulderPush and Level-based foraging tasks using IPPO (Fig. 15). 6Christianos et al. [4] show that on-policy policy gradient algorithms like MAPPO and MAA2C consistently converge suboptimally in the same tasks we consider. 19 Agent 2 A B Agent 1 A 4, 4 3 , 3 B 2, 2 1 , 1 Game 1 Agent 2 A B Agent 1 A 4, 4 3 , 3 B 2, 1 2 , 1 Game 2 Agent...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.