Task complexity shapes internal representations and robustness in neural networks
Pith reviewed 2026-05-18 23:45 UTC · model grok-4.3
The pith
Task complexity dictates neural network robustness, as hard tasks collapse under binarization while easy tasks do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
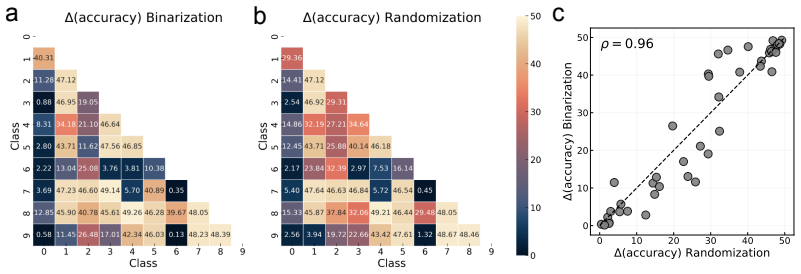
Multilayer perceptrons trained on difficult tasks lose all predictive power when their weights are binarized or when only the sign pattern is preserved through randomization, in contrast to networks on simple tasks that remain accurate under the same operations; the size of this performance drop therefore serves as a direct indicator of how complex the task is for the network.
What carries the argument
Five data-agnostic probes applied to MLPs represented as signed weighted bipartite graphs, with the performance gap after binarization or shuffling serving as the measure of task complexity.
If this is right
- Hard-task models cannot be compressed to binary weights without severe accuracy loss.
- Sign patterns alone carry sufficient information for easy tasks but not for hard ones.
- Moderate noise injection can improve performance on some tasks via a stochastic resonance mechanism.
- Pruning low-magnitude weights in binarized hard-task models triggers a sharp phase transition in accuracy.
Where Pith is reading between the lines
- This approach might help select model architectures or compression levels according to estimated task difficulty before training.
- Similar probes could be applied to convolutional or recurrent networks to test if the complexity-robustness link generalizes across architectures.
- The findings suggest that interpretability methods should focus on sign structures for simpler tasks and full weights for complex ones.
Load-bearing premise
Differences in robustness truly reflect task complexity and not particular statistics of the chosen image datasets or details of how the networks were trained.
What would settle it
Apply the same binarization and randomization probes to networks trained on other datasets with independently rated task difficulties and verify whether the performance gap consistently orders the tasks by difficulty.
Figures











read the original abstract
Neural networks excel across a wide range of tasks, yet remain black boxes. In particular, how their internal representations are shaped by the complexity of the input data and the problems they solve remains obscure. In this work, we introduce a suite of five data-agnostic probes-pruning, binarization, noise injection, sign flipping, and bipartite network randomization-to quantify how task difficulty influences the topology and robustness of representations in multilayer perceptrons (MLPs). MLPs are represented as signed, weighted bipartite graphs from a network science perspective. We contrast easy and hard classification tasks on the MNIST and Fashion-MNIST datasets. We show that binarizing weights in hard-task models collapses accuracy to chance, whereas easy-task models remain robust. We also find that pruning low-magnitude edges in binarized hard-task models reveals a sharp phase-transition in performance. Moreover, moderate noise injection can enhance accuracy, resembling a stochastic-resonance effect linked to optimal sign flips of small-magnitude weights. Finally, preserving only the sign structure-instead of precise weight magnitudes-through bipartite network randomizations suffices to maintain high accuracy. These phenomena define a model- and modality-agnostic measure of task complexity: the performance gap between full-precision and binarized or shuffled neural network performance. Our findings highlight the crucial role of signed bipartite topology in learned representations and suggest practical strategies for model compression and interpretability that align with task complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces five data-agnostic probes (pruning, binarization, noise injection, sign flipping, and bipartite network randomization) applied to multilayer perceptrons represented as signed bipartite graphs. It contrasts easy and hard classification tasks on MNIST and Fashion-MNIST, reporting that binarization collapses accuracy to chance on hard tasks while easy-task models remain robust, that pruning binarized hard-task models exhibits a sharp phase transition, that moderate noise injection can enhance accuracy via a stochastic-resonance-like mechanism, and that preserving only the sign structure through randomization suffices to maintain high accuracy. These observations are used to define a model- and modality-agnostic measure of task complexity as the performance gap between full-precision and binarized or shuffled networks.
Significance. If the central claims hold after addressing controls and quantification, the work would supply a network-science perspective on how task difficulty shapes signed weight topology and robustness, with potential utility for model compression and interpretability. The phase-transition and stochastic-resonance observations are concrete and could motivate targeted follow-up if placed on firmer statistical footing.
major comments (2)
- [Abstract] Abstract: The assertion that the five probes are data-agnostic and that the performance gap constitutes a model- and modality-agnostic measure of task complexity is load-bearing for the central claim, yet all reported contrasts are confined to MLPs on MNIST and Fashion-MNIST; no ablations or controls are described that isolate task complexity from dataset statistics (pixel covariance structure, class separability) or training choices (optimizer, initialization, epoch count).
- [Abstract] Abstract: The qualitative contrasts (accuracy collapse under binarization for hard tasks, phase transition under pruning, stochastic-resonance effect under noise) are presented without error bars, statistical tests, or explicit criteria for designating tasks as 'easy' versus 'hard,' leaving the support for the proposed complexity measure only partially quantitative.
minor comments (3)
- Provide explicit definitions or selection criteria for the easy and hard tasks, including any quantitative thresholds used.
- Include full details on network architectures, training hyperparameters, and random seeds to support reproducibility of the reported robustness differences.
- Clarify notation for the signed bipartite graph representation and how the five probes are formally implemented on the weight matrices.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the five probes are data-agnostic and that the performance gap constitutes a model- and modality-agnostic measure of task complexity is load-bearing for the central claim, yet all reported contrasts are confined to MLPs on MNIST and Fashion-MNIST; no ablations or controls are described that isolate task complexity from dataset statistics (pixel covariance structure, class separability) or training choices (optimizer, initialization, epoch count).
Authors: The probes are designed to be data-agnostic, operating exclusively on the signed weight structure of the trained network without using input data or labels. We concede that the experiments are restricted to MLPs on two image datasets. To mitigate concerns about confounding factors, we have included additional controls in the revision: retraining with different optimizers (SGD vs Adam) and random seeds, demonstrating that the binarization accuracy gap persists and correlates with task difficulty. We have also added text clarifying that while dataset-specific statistics may influence absolute performance, the relative gap serves as a proxy for complexity. Full cross-modality validation is noted as important future work. revision: partial
-
Referee: [Abstract] Abstract: The qualitative contrasts (accuracy collapse under binarization for hard tasks, phase transition under pruning, stochastic-resonance effect under noise) are presented without error bars, statistical tests, or explicit criteria for designating tasks as 'easy' versus 'hard,' leaving the support for the proposed complexity measure only partially quantitative.
Authors: We agree that enhancing the quantitative aspects strengthens the paper. In the revised manuscript, we now report results with error bars representing standard deviation over 5 independent runs for all key figures. We have applied paired t-tests to confirm significant differences between easy and hard task conditions (p < 0.01 for binarization collapse). Additionally, we define 'easy' tasks as those with binarization accuracy drop below 10% and 'hard' as above 50%, based on the clear separation observed in the data. These updates provide firmer statistical footing for the claims. revision: yes
Circularity Check
No significant circularity; measure proposed from empirical gaps without reduction to inputs
full rationale
The paper empirically contrasts robustness to binarization, shuffling, pruning and noise between MLPs trained on easy vs. hard classification tasks on MNIST/Fashion-MNIST, then proposes the observed performance gap as a model-agnostic complexity measure. This is a definitional summary of experimental results rather than a derivation that loops back to fitted parameters, self-citations or self-defined quantities. No equations, uniqueness theorems or prior-work ansatzes are invoked that would create circularity. The central claim remains independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MLPs can be faithfully represented as signed, weighted bipartite graphs whose topology encodes learned representations.
- ad hoc to paper The five listed probes are data-agnostic and sufficient to reveal task-complexity effects.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
These phenomena define a model- and modality-agnostic measure of task complexity: the performance gap between full-precision and binarized or shuffled neural network performance.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MLPs are represented as signed, weighted bipartite graphs... preserving only the sign structure... suffices to maintain high accuracy.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
L. J. Ba and R. Caruana. Do deep nets really need to be deep? In Ad- vances in Neural Information Processing Systems , volume 27. Curran Associates, Inc.,
-
[2]
URL https://proceedings.neurips.cc/paper_files/paper/2014/file/ b0c355a9dedccb50e5537e8f2e3f0810-Paper.pdf
work page 2014
-
[3]
H. Bai, W. Zhang, L. Hou, L. Shang, J. Jin, X. Jiang, Q. Liu, M. Lyu, and I. King. BinaryBERT: Pushing the limit of BERT quantization. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 4334–4348, Online, Aug
-
[4]
B inary BERT : Pushing the limit of BERT quantization
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.334. URL https://aclanthology.org/2021.acl-long.334/
- [5]
-
[6]
R. Benzi, A. Sutera, and A. Vulpiani. The mechanism of stochastic resonance.Journal of Physics A: Mathematical and General, 14(11):L453, nov 1981. doi: 10.1088/0305-4470/14/11/006. URL https://dx.doi.org/10.1088/0305-4470/14/11/006
-
[7]
R. Benzi, G. Parisi, A. Sutera, and A. Vulpiani. Stochastic resonance in climatic change. Tellus A: Dynamic Meteorology and Oceanography, 34(1):10, Jan. 1982. ISSN 1600-0870. doi: 10. 3402/tellusa.v34i1.10782. URL http://dx.doi.org/10.3402/tellusa.v34i1.10782
-
[8]
R. Benzi, G. Parisi, A. Sutera, and A. Vulpiani. A theory of stochastic resonance in climatic change. SIAM Journal on Applied Mathematics, 43(3):565–578, June 1983. ISSN 1095-712X. doi: 10.1137/0143037. URL http://dx.doi.org/10.1137/0143037
-
[9]
L. Bereska and E. Gavves. Mechanistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082, 2024
- [10]
-
[11]
C. Blöcker, M. Rosvall, I. Scholtes, and J. D. West. Insights from network science can advance deep graph learning. arXiv preprint arXiv:2502.01177, 2025
-
[12]
G. Bonifazi, F. Cauteruccio, E. Corradini, M. Marchetti, D. Ursino, and L. Virgili. A network analysis-based framework to understand the representation dynamics of graph neural networks. Neural Computing and Applications, 36(4):1875–1897, 2024
work page 2024
-
[13]
D. Castelvecchi. Can we open the black box of ai? Nature News, 538(7623):20, 2016
work page 2016
-
[14]
H. Cheng, M. Zhang, and J. Q. Shi. A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10558–10578, 2024. doi: 10.1109/TPAMI.2024.3447085
-
[15]
M. Courbariaux, Y . Bengio, and J. David. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in Neural Information Processing Systems, volume 28, pages 3123–3131, 2015
work page 2015
-
[16]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, Jun...
-
[17]
Y . Du, L. Wang, L. Guo, J. Han, T. Liu, and X. Hu. Topological similarity between artificial and biological neural networks. In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2023. 10
work page 2023
-
[18]
K. Dwivedi and G. Roig. Representation similarity analysis for efficient task taxonomy and transfer learning. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12379–12388, 2019. doi: 10.1109/CVPR.2019.01267
- [19]
-
[20]
J. Frankle and M. Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations , 2019. URL https: //openreview.net/forum?id=rJl-b3RcF7
work page 2019
-
[21]
L. Gammaitoni, P. Hänggi, P. Jung, and F. Marchesoni. Stochastic resonance. Reviews of Modern Physics, 70(1):223–287, Jan. 1998. ISSN 1539-0756. doi: 10.1103/revmodphys.70.223. URL http://dx.doi.org/10.1103/RevModPhys.70.223
-
[22]
M. Girvan and M. E. Newman. Community structure in social and biological networks. Proceedings of the national academy of sciences, 99(12):7821–7826, 2002
work page 2002
-
[23]
R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, F. Giannotti, and D. Pedreschi. A survey of methods for explaining black box models. ACM computing surveys (CSUR), 51(5):1–42, 2018
work page 2018
-
[24]
B. Hassibi, D. G. Stork, and G. J. Wolff. Optimal Brain Surgeon and General Network Pruning. In Proceedings of the IEEE International Conference on Neural Networks, 1993
work page 1993
-
[25]
Y . He, X. Zhang, and J. Sun. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 1389–1397, 2017
work page 2017
-
[26]
T. K. Ho. Complexity of representations in deep learning. In2022 26th International Conference on Pattern Recognition (ICPR), pages 2657–2663. IEEE, 2022
work page 2022
- [27]
-
[28]
M. Klabunde, T. Schumacher, M. Strohmaier, and F. Lemmerich. Similarity of neural network models: A survey of functional and representational measures. ACM Computing Surveys, 2023
work page 2023
-
[29]
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of neural network representations revisited. In Proceedings of the 36th International Conference on Machine Learning, pages 3519–3529, 2019
work page 2019
-
[30]
N. Kriegeskorte, M. Mur, and P. A. Bandettini. Representational similarity analysis—connecting the branches of systems neuroscience. Frontiers in Systems Neuroscience, 2:4, 2008
work page 2008
-
[31]
A. Krizhevsky. Learning multiple layers of features from tiny images. University of Toronto, 05 2012
work page 2012
-
[32]
E. La Malfa, G. La Malfa, G. Nicosia, and V . Latora. Characterizing learning dynamics of deep neural networks via complex networks. In 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI), pages 344–351. IEEE, 2021
work page 2021
- [33]
-
[34]
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791
-
[35]
N. Lee, T. Ajanthan, and P. H. S. Torr. SNIP: Single-Shot Network Pruning Based on Connection Sensitivity. In International Conference on Learning Representations, 2019
work page 2019
-
[36]
Y . Li, Z. Zhang, B. Liu, Z. Yang, and Y . Liu. Modeldiff: testing-based dnn similarity comparison for model reuse detection. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA ’21, page 139–151. ACM, July 2021. doi: 10.1145/ 3460319.3464816. URL http://dx.doi.org/10.1145/3460319.3464816
- [37]
-
[38]
T.-Y . Lin, A. RoyChowdhury, and S. Maji. Bilinear cnn models for fine-grained visual recogni- tion. In Proceedings of the IEEE international conference on computer vision, pages 1449–1457, 2015. 11
work page 2015
-
[39]
Y . Lu, W. Yang, Y . Zhang, Z. Chen, J. Chen, Q. Xuan, Z. Wang, and X. Yang. Understanding the dynamics of dnns using graph modularity. In European Conference on Computer Vision, pages 225–242. Springer, 2022
work page 2022
- [40]
-
[41]
O. Madani, D. Pennock, and G. Flake. Co-validation: Using model disagreement on unlabeled data to validate classification algorithms. InAdvances in Neural Information Processing Systems, volume 17. MIT Press, 2004. URL https://proceedings.neurips.cc/paper_files/ paper/2004/file/92f54963fc39a9d87c2253186808ea61-Paper.pdf
work page 2004
-
[42]
C. Marx, F. Calmon, and B. Ustun. Predictive multiplicity in classification. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 6765–6774. PMLR, 13–18 Jul 2020. URL https://proceedings. mlr.press/v119/marx20a.html
work page 2020
-
[43]
D. C. Mocanu, E. Mocanu, P. Stone, P. H. Nguyen, M. Gibescu, and A. Liotta. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nature communications, 9(1):2383, 2018
work page 2018
-
[44]
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz. Pruning convolutional neural networks for resource efficient inference. In International Conference on Learning Representations, 2017
work page 2017
-
[45]
K. Mukherjee and T. T. Rogers. How does task structure shape representations in deep neural networks? In NeurIPS 2020 Workshop SVRHM
work page 2020
- [46]
-
[47]
M. E. Newman. The structure of scientific collaboration networks. Proceedings of the national academy of sciences, 98(2):404–409, 2001
work page 2001
-
[48]
M. E. Newman. The structure and function of complex networks. SIAM review, 45(2):167–256, 2003
work page 2003
- [49]
-
[50]
M. Pósfai and A.-L. Barabási. Network science, volume 3. Citeseer, 2016
work page 2016
- [51]
- [52]
-
[53]
M. Rastegari, V . Ordonez, J. Redmon, and A. Farhadi. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In European Conference on Computer Vision, pages 525–542, 2016
work page 2016
-
[54]
V . Sanh, L. Debut, J. Chaumond, and T. Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[55]
L. Scabini, B. De Baets, and O. M. Bruno. Improving deep neural network random initialization through neuronal rewiring. Neurocomputing, 599:128130, 2024
work page 2024
-
[56]
L. F. Scabini and O. M. Bruno. Structure and performance of fully connected neural networks: Emerging complex network properties. Physica A: Statistical Mechanics and its Applications, 615:128585, 2023
work page 2023
-
[57]
Open Problems in Mechanistic Interpretability
L. Sharkey, B. Chughtai, J. Batson, J. Lindsey, J. Wu, L. Bushnaq, N. Goldowsky-Dill, S. Heimer- sheim, A. Ortega, J. Bloom, et al. Open problems in mechanistic interpretability. arXiv preprint arXiv:2501.16496, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
E. F. Tjong Kim Sang and F. De Meulder. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003 , pages 142–147, 2003. URL https: //www.aclweb.org/anthology/W03-0419. 12
work page 2003
-
[59]
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004. doi: 10.1109/TIP.2003.819861
-
[60]
A. Waqas, H. Farooq, N. C. Bouaynaya, and G. Rasool. Exploring robust architectures for deep artificial neural networks. Communications Engineering, 1(1), Dec. 2022. ISSN 2731-3395. doi: 10.1038/s44172-022-00043-2. URL http://dx.doi.org/10.1038/ s44172-022-00043-2
-
[61]
H. Xiao, K. Rasul, and R. V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
work page 2017
-
[62]
S. Xie, A. Kirillov, R. Girshick, and K. He. Exploring randomly wired neural networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1284–1293, 2019
work page 2019
-
[63]
J. You, J. Leskovec, K. He, and S. Xie. Graph structure of neural networks. In International Conference on Machine Learning, pages 10881–10891. PMLR, 2020
work page 2020
-
[64]
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018. doi: 10.1109/CVPR.2018.00068
- [65]
-
[66]
J. Zilly, L. Hetzel, A. Censi, and E. Frazzoli. Quantifying the effect of representations on task complexity, 2019. URL https://arxiv.org/abs/1912.09399. 13 A Appendix A.1 Structural Similarity Index distance between pairs of classes 0 1 2 3 4 5 6 7 8 9 Class 0123456789 Class 0.75 0.87 0.47 0.85 0.79 0.79 0.84 0.77 0.82 0.74 0.85 0.78 0.86 0.85 0.74 0.83 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.