Overhead in Quantum Circuits with Time-Multiplexed Qubit Control
Pith reviewed 2026-05-18 21:00 UTC · model grok-4.3
The pith
Time-multiplexed qubit control reduces drive lines with only logarithmic overhead for single-qubit gates and none for two-qubit couplers up to connectivity limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For standard quantum-processor layouts and typical gate times, time multiplexing allows the number of drive lines to be reduced substantially without introducing much overhead: couplers for two-qubit gates can be grouped on common lines with no overhead up to a limit fixed by qubit connectivity, and the serialization overhead for single-qubit gates scales only logarithmically with the number of qubits sharing each line.
What carries the argument
Time-multiplexed scheduling of qubit and coupler operations on shared drive lines, which converts parallel gates into sequential pulses whose total duration is bounded by connectivity for two-qubit operations and by logarithmic depth for single-qubit operations.
If this is right
- Common quantum algorithms can run with far fewer drive lines while incurring only modest extra execution time.
- Two-qubit connectivity graph determines the maximum number of couplers that can share a line at zero cost.
- Single-qubit overhead remains manageable even when dozens of qubits share one line because the cost grows logarithmically.
- Fewer drive lines reduce both cryogenic heat load and the complexity of room-temperature electronics.
Where Pith is reading between the lines
- In processors with higher connectivity, even larger groups of two-qubit couplers could share lines without overhead.
- Combining time multiplexing with frequency multiplexing might push the drive-line reduction further.
- Longer total runtimes could increase exposure to decoherence, so the overhead numbers should be compared against coherence times of specific hardware.
Load-bearing premise
The calculations assume standard processor layouts and typical gate times without extra constraints such as crosstalk or calibration overhead.
What would settle it
A direct measurement on hardware that compares the actual circuit runtime when two-qubit couplers share a drive line against the runtime when each coupler has its own line, for a circuit whose depth is set only by connectivity.
Figures








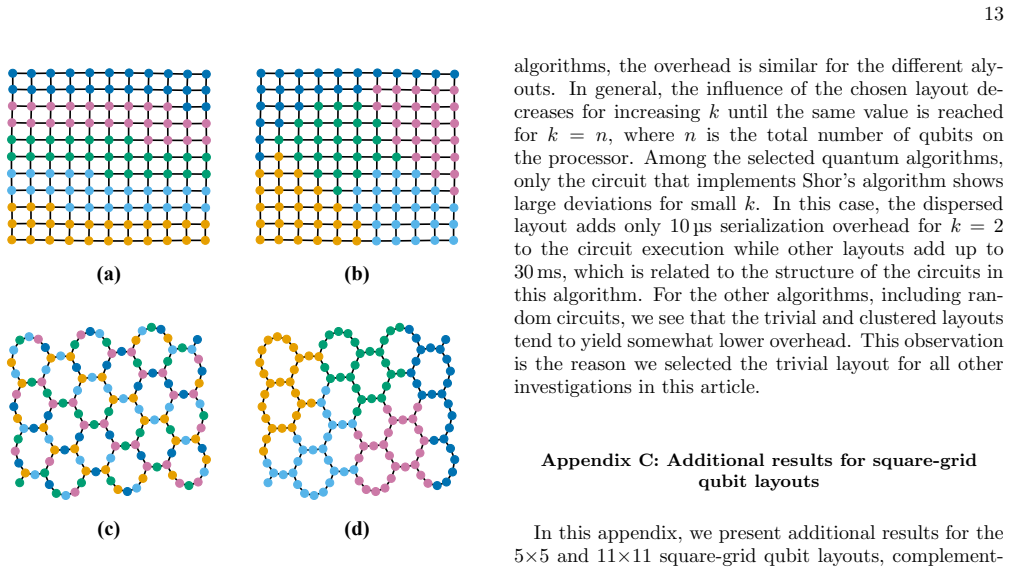









read the original abstract
When scaling up quantum processors in a cryogenic environment, it is desirable to limit the number of qubit drive lines going into the cryostat, since fewer lines makes cooling of the system more manageable and the need for complicated electronics setups is reduced. However, although time multiplexing of qubit control enables using just a few drive lines to steer many qubits, it comes with a trade-off: fewer drive lines means fewer qubits can be controlled in parallel, which leads to an overhead in the execution time for quantum algorithms. In this article, we quantify this trade-off through numerical and analytical investigations. For standard quantum processor layouts and typical gate times, we show that the trade-off is favorable for many common quantum algorithms $\unicode{x2014}$ the number of drive lines can be significantly reduced without introducing much overhead. Specifically, we show that couplers for two-qubit gates can be grouped on common drive lines without any overhead up to a limit set by the connectivity of the qubits. For single-qubit gates, we find that the serialization overhead generally scales only logarithmically in the number of qubits sharing a drive line. These results are promising for the continued progress towards large-scale quantum computers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript quantifies the execution-time overhead incurred by time-multiplexing qubit control to reduce the number of cryogenic drive lines. Using numerical scheduling simulations and analytical models, it concludes that, for standard quantum-processor layouts and typical gate times, couplers for two-qubit gates can be grouped on shared drive lines with zero overhead up to the limit imposed by qubit connectivity, while single-qubit-gate serialization overhead scales only logarithmically with the number of qubits sharing a line, rendering the trade-off favorable for many common algorithms.
Significance. If the reported scalings hold, the work supplies concrete, hardware-relevant guidance for reducing cryogenic wiring and control electronics without substantially lengthening circuit run times. The dual numerical-plus-analytical approach and the restriction to standard layouts strengthen applicability; explicit credit is due for the parameter-free analytical bounds on coupler grouping and the logarithmic scaling result for single-qubit gates.
major comments (1)
- [§3 and §4] §3 (Numerical Simulations) and §4 (Analytical Derivations): the central quantitative claims rest on the reported simulation results and closed-form expressions, yet the manuscript does not supply the full data sets, error bars, or step-by-step derivations needed to reproduce the overhead numbers; this prevents independent verification of the stated logarithmic scaling and zero-overhead coupler grouping.
minor comments (3)
- [Figure 2] Figure 2: the legend does not explicitly map line styles to the different multiplexing ratios examined, making it difficult to connect the plotted curves to the text discussion.
- [§2] The phrase 'standard quantum processor layouts' is used repeatedly but never given a precise definition (e.g., grid size, degree, or gate-time ratios); a short clarifying paragraph in §2 would remove ambiguity.
- [Eqs. (7) and (12)] A few typographical inconsistencies appear in the notation for drive-line grouping (e.g., 'N_d' vs. 'N_drive' in Eqs. (7) and (12)).
Simulated Author's Rebuttal
We thank the referee for their positive summary and for highlighting the potential hardware relevance of our results on time-multiplexed control. We address the single major comment below and will incorporate the requested improvements in a revised manuscript.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Numerical Simulations) and §4 (Analytical Derivations): the central quantitative claims rest on the reported simulation results and closed-form expressions, yet the manuscript does not supply the full data sets, error bars, or step-by-step derivations needed to reproduce the overhead numbers; this prevents independent verification of the stated logarithmic scaling and zero-overhead coupler grouping.
Authors: We agree that additional documentation is needed for independent reproduction. In the revised version we will add an appendix containing the full step-by-step derivations of the analytical bounds on coupler grouping and the logarithmic scaling for single-qubit gates. For the numerical results in §3 we will include error bars on all plotted overhead values and will make the complete simulation code together with the raw data sets available as supplementary material (or via a public repository) upon acceptance. These additions will not change the reported conclusions but will directly enable verification of the zero-overhead coupler result and the logarithmic scaling. revision: yes
Circularity Check
No significant circularity; results from direct simulation and analysis
full rationale
The paper quantifies overhead via explicit numerical scheduling simulations and analytical derivations grounded in standard processor layouts, qubit connectivity, and typical gate times. These models compute serialization times and parallelism limits directly from the input assumptions without any self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations. Claims of zero overhead for coupler grouping (bounded by connectivity) and logarithmic scaling for single-qubit gates follow as straightforward consequences of the scheduling analysis, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard quantum processor layouts and typical gate times are assumed.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a compilation algorithm to minimize the runtime overhead from time multiplexing... serialization of concurrent gates that share the same switch... logarithmic scaling in k... queueing theory
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For standard quantum processor layouts and typical gate times, the trade-off is favorable... couplers... grouped... without any overhead up to a limit set by the connectivity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Benchmarking circuits We use two different sets of circuits to estimate the overhead introduced by time multiplexing qubit control: a) random circuits and b) examples of quantum algo- rithms provided in the standard benchmarking set MQT Bench [53]. We generate the random circuits in native gates of the target hardware with single-qubit and two-qubit gate ...
work page 2000
-
[2]
Numerical modeling of overhead scaling For a dense circuit with many single-qubit gates, as illustrated in Fig. 19, not much optimization is possible and we expect a linear scaling inkfor the serialization 2000 4000 6000 8000 100000 10 20 30 40Serialization overhead (ms) (a) Qubits per switch k 127 26 8 3 2 2000 4000 6000 8000 10000 Number of gates 0 2 4 ...
work page 2000
-
[3]
21, we expand on the selection in Fig
Further supporting data In Fig. 21, we expand on the selection in Fig. 6 in the main text, showing the full data for all algorithms from the MQT Bench set, and for all three quantum processor layouts considered in this article, for scaling of serializa- tion overhead with the number of qubits per switchk. From these plots and the fits there (solid curves)...
-
[4]
Queueing-theory-inspired derivation of the logarithmic scaling LetW 1, . . . , Wm be independent and identically dis- tributed waiting times formswitches, each with an ex- ponential tail: Pr(W > x)∼e −ηx, x→ ∞.(E1) whereηis a constant called the asymptotic decay rate. Define the maximum Mm = max{W1, . . . , Wm}.(E2) The tail of the maximum is Pr(Mm > x) =...
-
[5]
X. Gu, A. F. Kockum, A. Miranowicz, Y.-X. Liu, and F. Nori, Microwave photonics with superconducting quantum circuits, Physics Reports718-719, 1 (2017)
work page 2017
- [6]
- [7]
-
[8]
A. Chatterjee, P. Stevenson, S. De Franceschi, A. Morello, N. P. de Leon, and F. Kuemmeth, Semi- conductor qubits in practice, Nature Reviews Physics 3, 157 (2021)
work page 2021
-
[9]
G. Burkard, T. D. Ladd, A. Pan, J. M. Nichol, and J. R. Petta, Semiconductor spin qubits, Reviews of Modern Physics95, 025003 (2023)
work page 2023
-
[10]
S. Krinner, S. Storz, P. Kurpiers, P. Magnard, J. Hein- soo, R. Keller, J. L¨ utolf, C. Eichler, and A. Wallraff, Engineering cryogenic setups for 100-qubit scale super- conducting circuit systems, EPJ Quantum Technology 6, 2 (2019)
work page 2019
-
[11]
How to Build a Quantum Supercomputer: Scaling from Hundreds to Millions of Qubits
M. Mohseniet al., How to build a quantum super- computer: Scaling from hundreds to millions of qubits (2025), arXiv:2411.10406
work page internal anchor Pith review arXiv 2025
- [12]
-
[13]
A. Youssefi, I. Shomroni, Y. J. Joshi, N. R. Bernier, A. Lukashchuk, P. Uhrich, L. Qiu, and T. J. Kippen- berg, A cryogenic electro-optic interconnect for super- conducting devices, Nature Electronics4, 326 (2021)
work page 2021
-
[14]
M. J. Weaver, P. Duivestein, A. C. Bernasconi, S. Scharmer, M. Lemang, T. C. v. Thiel, F. Hijazi, B. Hensen, S. Gr¨ oblacher, and R. Stockill, An integrated microwave-to-optics interface for scalable quantum com- puting, Nature Nanotechnology19, 166 (2024)
work page 2024
-
[15]
M. Shen, J. Xie, Y. Xu, S. Wang, R. Cheng, W. Fu, Y. Zhou, and H. X. Tang, Photonic link from single-flux- quantum circuits to room temperature, Nature Photon- ics18, 371 (2024)
work page 2024
-
[16]
R. McDermott, M. G. Vavilov, B. L. T. Plourde, F. K. Wilhelm, P. J. Liebermann, O. A. Mukhanov, and T. A. Ohki, Quantum–classical interface based on single flux quantum digital logic, Quantum Science and Technol- ogy3, 024004 (2018)
work page 2018
-
[17]
C. H. Liu, A. Ballard, D. Olaya, D. R. Schmidt, J. Biesecker, T. Lucas, J. Ullom, S. Patel, O. Rafferty, A. Opremcak, K. Dodge, V. Iaia, T. McBroom, J. L. DuBois, P. F. Hopkins, S. P. Benz, B. L. T. Plourde, and R. McDermott, Single Flux Quantum-Based Dig- ital Control of Superconducting Qubits in a Multichip Module, PRX Quantum4, 030310 (2023)
work page 2023
-
[18]
O. Mukhanov, A. Kirichenko, C. Howington, J. Walter, M. Hutchings, and I. Vernik, Scalable Quantum Com- puting Infrastructure Based on Superconducting Elec- tronics, in2019 IEEE International Electron Devices Meeting (IEDM)(IEEE, 2019) pp. 07–11
work page 2019
- [19]
-
[20]
J. M. Hornibrook, J. I. Colless, I. D. Conway Lamb, S. J. Pauka, H. Lu, A. C. Gossard, J. D. Watson, G. C. Gardner, S. Fallahi, M. J. Manfra, and D. J. Reilly, Cryogenic Control Architecture for Large-Scale Quan- tum Computing, Physical Review Applied3, 024010 (2015)
work page 2015
-
[21]
J. P. G. van Dijk, B. Patra, S. Pellerano, E. Char- bon, F. Sebastiano, and M. Babaie, Designing a DDS- Based SoC for High-Fidelity Multi-Qubit Control, IEEE Transactions on Circuits and Systems I: Regular Papers 67, 5380 (2020)
work page 2020
-
[22]
P. Zhao, A multiplexed control architecture for super- conducting qubits with row-column addressing (2024), arXiv:2403.03717
-
[23]
Y. Chen, D. Sank, P. O’Malley, T. White, R. Barends, B. Chiaro, J. Kelly, E. Lucero, M. Mariantoni, A. Megrant, C. Neill, A. Vainsencher, J. Wenner, Y. Yin, A. N. Cleland, and J. M. Martinis, Multiplexed dispersive readout of superconducting phase qubits, Ap- plied Physics Letters101, 182601 (2012)
work page 2012
-
[24]
J. Heinsoo, C. K. Andersen, A. Remm, S. Krin- ner, T. Walter, Y. Salath´ e, S. Gasparinetti, J.-C. Besse, A. Potoˇ cnik, A. Wallraff, and C. Eichler, Rapid High-fidelity Multiplexed Readout of Superconducting Qubits, Physical Review Applied10, 034040 (2018)
work page 2018
- [25]
-
[26]
Z. H. Yang, R. Wang, Z. T. Wang, P. Zhao, K. Huang, K. Xu, Y. Tian, H. F. Yu, and S. P. Zhao, Mitiga- tion of microwave crosstalk with parameterized single- qubit gate in superconducting quantum circuits, Ap- plied Physics Letters124, 214001 (2024)
work page 2024
- [27]
-
[28]
R. Matsuda, R. Ohira, T. Sumida, H. Shiomi, A. Machino, S. Morisaka, K. Koike, T. Miyoshi, Y. Kurimoto, Y. Sugita, Y. Ito, Y. Suzuki, P. A. Spring, S. Wang, S. Tamate, Y. Tabuchi, Y. Naka- mura, K. Ogawa, and M. Negoro, Selective Excitation of Superconducting Qubits with a Shared Control Line through Pulse Shaping (2025), arXiv:2501.10710
-
[29]
D. R. Ward, D. E. Savage, M. G. Lagally, S. N. Copper- smith, and M. A. Eriksson, Integration of on-chip field- effect transistor switches with dopantless Si/SiGe quan- tum dots for high-throughput testing, Applied Physics Letters102, 213107 (2013)
work page 2013
-
[30]
H. Al-Taie, L. W. Smith, B. Xu, P. See, J. P. Griffiths, H. E. Beere, G. A. C. Jones, D. A. Ritchie, M. J. Kelly, and C. G. Smith, Cryogenic on-chip multiplexer for the study of quantum transport in 256 split-gate devices, Applied Physics Letters102, 243102 (2013)
work page 2013
-
[31]
B. Paquelet Wuetz, P. L. Bavdaz, L. A. Yeoh, R. Schouten, H. van der Does, M. Tiggelman, D. Sab- bagh, A. Sammak, C. G. Almudever, F. Sebastiano, 22 J. S. Clarke, M. Veldhorst, and G. Scappucci, Mul- tiplexed quantum transport using commercial off-the- shelf CMOS at sub-kelvin temperatures, npj Quantum Information6, 43 (2020)
work page 2020
-
[32]
E. J. Thomas, V. N. Ciriano-Tejel, D. F. Wise, D. Prete, M. d. Kruijf, D. J. Ibberson, G. M. Noah, A. Gomez- Saiz, M. F. Gonzalez-Zalba, M. A. I. Johnson, and J. J. L. Morton, Rapid cryogenic characterization of 1,024 integrated silicon quantum dot devices, Nature Electronics8, 75 (2025)
work page 2025
-
[33]
M. F. Gonzalez-Zalba, S. de Franceschi, E. Charbon, T. Meunier, M. Vinet, and A. S. Dzurak, Scaling silicon- based quantum computing using CMOS technology, Na- ture Electronics4, 872 (2021)
work page 2021
-
[34]
H. Bohuslavskyi, A. Ronzani, J. H¨ atinen, A. Rantala, A. Shchepetov, P. Koppinen, J. S. Lehtinen, and M. Prunnila, Scalable on-chip multiplexing of sili- con single and double quantum dots, Communications Physics7, 323 (2024)
work page 2024
-
[35]
P. L. Bavdaz, H. G. J. Eenink, J. van Staveren, M. Lo- dari, C. G. Almudever, J. S. Clarke, F. Sebasatiano, M. Veldhorst, and G. Scappucci, A quantum dot cross- bar with sublinear scaling of interconnects at cryogenic temperature, npj Quantum Information8, 86 (2022)
work page 2022
-
[36]
S. K. Bartee, W. Gilbert, K. Zuo, K. Das, T. Tanttu, C. H. Yang, N. Dumoulin Stuyck, S. J. Pauka, R. Y. Su, W. H. Lim, S. Serrano, C. C. Escott, F. E. Hudson, K. M. Itoh, A. Laucht, A. S. Dzurak, and D. J. Reilly, Spin-qubit control with a milli-kelvin CMOS chip, Na- ture643, 382 (2025)
work page 2025
-
[37]
R. Acharya, S. Brebels, A. Grill, J. Verjauw, T. Ivanov, D. P. Lozano, D. Wan, J. Van Damme, A. M. Vadi- raj, M. Mongillo, B. Govoreanu, J. Craninckx, I. P. Radu, K. De Greve, G. Gielen, F. Catthoor, and A. Potoˇ cnik, Multiplexed superconducting qubit con- trol at millikelvin temperatures with a low-power cryo- CMOS multiplexer, Nature Electronics6, 900 (2023)
work page 2023
-
[38]
M. Pechal, J.-C. Besse, M. Mondal, M. Oppliger, S. Gas- parinetti, and A. Wallraff, Superconducting Switch for Fast On-Chip Routing of Quantum Microwave Fields, Physical Review Applied6, 024009 (2016)
work page 2016
-
[39]
B. J. Chapman, B. A. Moores, E. I. Rosenthal, J. Ker- ckhoff, and K. W. Lehnert, General purpose multiplex- ing device for cryogenic microwave systems, Applied Physics Letters108, 222602 (2016)
work page 2016
- [40]
-
[41]
G. De Simoni, F. Paolucci, P. Solinas, E. Strambini, and F. Giazotto, Metallic supercurrent field-effect transistor, Nature Nanotechnology13, 802 (2018)
work page 2018
- [42]
-
[43]
A. L. Graninger, J. M. Cochran, A. A. Pesetski, J. D. Strand, R. E. Zimmerman, and N. L. Mungo, Mi- crowave Switch Architecture for Superconducting Inte- grated Circuits Using Magnetic Field-Tunable Joseph- son Junctions, IEEE Transactions on Applied Supercon- ductivity33, 1501605 (2023)
work page 2023
- [44]
-
[45]
Y.-H. Huang, Q.-Y. Zhao, H. Hao, N.-T. Liu, Z. Liu, J. Deng, F. Yang, S.-Y. Ru, X.-C. Tu, L.-B. Zhang, X.- Q. Jia, J. Chen, L. Kang, and P.-H. Wu, Monolithic in- tegrated superconducting nanowire digital encoder, Ap- plied Physics Letters124, 192601 (2024)
work page 2024
- [46]
- [47]
- [48]
-
[49]
Technically, this describes demultiplexing, but we sim- ply refer to it as multiplexing for convenience
-
[50]
T. Abad, J. Fern´ andez-Pend´ as, A. F. Kockum, and G. Johansson, Universal Fidelity Reduction of Quan- tum Operations from Weak Dissipation, Physical Re- view Letters129, 150504 (2022)
work page 2022
- [51]
-
[52]
Z. Shan, Y. Zhu, and B. Zhao, A high-performance com- pilation strategy for multiplexing quantum control ar- chitecture, Scientific Reports12, 7132 (2022)
work page 2022
-
[53]
L. Lao, H. van Someren, I. Ashraf, and C. G. Almude- ver, Timing and Resource-Aware Mapping of Quantum Circuits to Superconducting Processors, IEEE Transac- tions on Computer-Aided Design of Integrated Circuits and Systems41, 359 (2021)
work page 2021
-
[54]
C.-Y. Huang and W.-K. Mak, CTQr: Control and Timing-Aware Qubit Routing, in2024 29th Asia and South Pacific Design Automation Conference (ASP- DAC)(IEEE, 2024) pp. 22–25
work page 2024
-
[55]
K. Booth, M. Do, J. Beck, E. Rieffel, D. Venturelli, and J. Frank, Comparing and Integrating Constraint Pro- gramming and Temporal Planning for Quantum Circuit Compilation, inProceedings of the International Con- ference on Automated Planning and Scheduling, Vol. 28 (2018) pp. 366–374
work page 2018
-
[56]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, B. R. Johnson, and J. M. Gambetta, Quantum computing with Qiskit (2024), arXiv:2405.08810
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
N. Quetschlich, L. Burgholzer, and R. Wille, MQT Bench: Benchmarking Software and Design Automa- tion Tools for Quantum Computing, Quantum7, 1062 (2023)
work page 2023
-
[58]
F. Aruteet al., Quantum supremacy using a pro- grammable superconducting processor, Nature574, 505 (2019)
work page 2019
-
[59]
Acharyaet al., Quantum error correction below the surface code threshold, Nature638, 920 (2025)
R. Acharyaet al., Quantum error correction below the surface code threshold, Nature638, 920 (2025). 23
work page 2025
-
[60]
J. Chow, O. Dial, and J. Gambetta, IBM Quantum breaks the 100-qubit processor barrier (2021), IBM Quantum Computing Blog. [Accessed: 23. Aug. 2025]
work page 2021
-
[61]
Y. Chen, C. Neill, P. Roushan, N. Leung, M. Fang, R. Barends, J. Kelly, B. Campbell, Z. Chen, B. Chiaro, A. Dunsworth, E. Jeffrey, A. Megrant, J. Y. Mu- tus, P. J. J. O’Malley, C. M. Quintana, D. Sank, A. Vainsencher, J. Wenner, T. C. White, M. R. Geller, A. N. Cleland, and J. M. Martinis, Qubit Architecture with High Coherence and Fast Tunable Coupling, ...
work page 2014
-
[62]
D. C. McKay, S. Filipp, A. Mezzacapo, E. Magesan, J. M. Chow, and J. M. Gambetta, Universal Gate for Fixed-Frequency Qubits via a Tunable Bus, Physical Review Applied6, 064007 (2016)
work page 2016
-
[63]
F. Yan, P. Krantz, Y. Sung, M. Kjaergaard, D. L. Campbell, T. P. Orlando, S. Gustavsson, and W. D. Oliver, Tunable Coupling Scheme for Implementing High-Fidelity Two-Qubit Gates, Physical Review Ap- plied10, 054062 (2018)
work page 2018
-
[64]
R. Acharyaet al., Suppressing quantum errors by scal- ing a surface code logical qubit, Nature614, 676 (2023)
work page 2023
- [65]
-
[66]
G. Li, Y. Ding, and Y. Xie, Tackling the Qubit Mapping Problem for NISQ-Era Quantum Devices, inProceed- ings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems(ACM, New York, NY, USA, 2019) pp. 1001–1014
work page 2019
-
[67]
A. Cowtan, S. Dilkes, R. Duncan, A. Krajenbrink, W. Simmons, and S. Sivarajah, On the qubit routing problem, in14th Conference on the Theory of Quantum Computation, Communication and Cryptography (TQC 2019), Vol. 135, edited by W. van Dam and L. Mancin- ska (Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, Dagstuhl, Germany, 2019) pp. 5:1–5:32
work page 2019
-
[68]
G. Nannicini, L. S. Bishop, O. G¨ unl¨ uk, and P. Jurce- vic, Optimal Qubit Assignment and Routing via Integer Programming, ACM Transactions on Quantum Com- puting4, 7 (2022)
work page 2022
-
[69]
T. Ito, N. Kakimura, N. Kamiyama, Y. Kobayashi, and Y. Okamoto, Algorithmic Theory of Qubit Routing, in Lecture Notes in Computer Science, Vol. 14079, edited by P. Morin and S. Suri (Springer, Cham, 2023) pp. 533–546
work page 2023
-
[70]
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Surface codes: Towards practical large-scale quantum computation, Physical Review A86, 032324 (2012)
work page 2012
-
[71]
G. S. Paraoanu, Microwave-induced coupling of su- perconducting qubits, Physical Review B74, 140504 (2006)
work page 2006
-
[72]
C. Rigetti and M. Devoret, Fully microwave-tunable universal gates in superconducting qubits with linear couplings and fixed transition frequencies, Physical Re- view B81, 134507 (2010)
work page 2010
-
[73]
J. M. Chow, A. D. C´ orcoles, J. M. Gambetta, C. Rigetti, B. R. Johnson, J. A. Smolin, J. R. Rozen, G. A. Keefe, M. B. Rothwell, M. B. Ketchen, and M. Steffen, Sim- ple All-Microwave Entangling Gate for Fixed-Frequency Superconducting Qubits, Physical Review Letters107, 080502 (2011)
work page 2011
-
[74]
S. Sheldon, E. Magesan, J. M. Chow, and J. M. Gam- betta, Procedure for systematically tuning up cross- talk in the cross-resonance gate, Physical Review A93, 060302 (2016)
work page 2016
-
[75]
K. Heya and N. Kanazawa, Cross-Cross Resonance Gate, PRX Quantum2, 040336 (2021)
work page 2021
-
[76]
Y. Kim, A. Morvan, L. B. Nguyen, R. K. Naik, C. J¨ unger, L. Chen, J. M. Kreikebaum, D. I. Santiago, and I. Siddiqi, High-fidelity three-qubit iToffoli gate for fixed-frequency superconducting qubits, Nature Physics 18, 783 (2022)
work page 2022
- [77]
-
[78]
X. Gu, J. Fern´ andez-Pend´ as, P. Vikst˚ al, T. Abad, C. Warren, A. Bengtsson, G. Tancredi, V. Shumeiko, J. Bylander, G. Johansson, and A. F. Kockum, Fast Multiqubit Gates through Simultaneous Two-Qubit Gates, PRX Quantum2, 040348 (2021)
work page 2021
-
[79]
C. W. Warren, J. Fern´ andez-Pend´ as, S. Ahmed, T. Abad, A. Bengtsson, J. Bizn´ arov´ a, K. Debnath, X. Gu, C. Kriˇ zan, A. Osman, A. Fadavi Roudsari, P. Delsing, G. Johansson, A. Frisk Kockum, G. Tan- credi, and J. Bylander, Extensive characterization and implementation of a family of three-qubit gates at the coherence limit, npj Quantum Information9, 44 (2023)
work page 2023
-
[80]
H.-T. Liu, B.-J. Chen, J.-C. Zhang, Y.-X. Xiao, T.-M. Li, K. Huang, Z. Wang, H. Li, K. Zhao, Y. Xu, C.-L. Deng, G.-H. Liang, Z.-H. Liu, S.-Y. Zhou, C.-P. Fang, X. Song, Z. Xiang, D. Zheng, Y.-H. Shi, K. Xu, and H. Fan, Direct Implementation of High-Fidelity Three- Qubit Gates for Superconducting Processor with Tun- able Couplers, Physical Review Letters13...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.