Enabling Transparent Cyber Threat Intelligence Combining Large Language Models and Domain Ontologies
Pith reviewed 2026-05-18 20:28 UTC · model grok-4.3
The pith
Integrating domain ontologies and SHACL constraints with large language models produces more accurate and explainable extractions of cyber threat information from system logs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
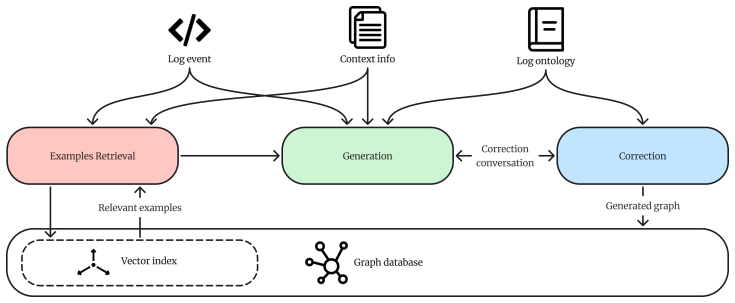
The central claim is that an AI agent built by integrating domain ontologies and SHACL-based constraints to guide LLM outputs can achieve higher accuracy in information extraction from cybersecurity logs compared to traditional prompt-only approaches, while also improving explainability and enabling semantic querying in a graph database. This is motivated by the need to handle predominantly malicious activity in honeypot log data.
What carries the argument
An AI agent that uses ontology-driven structured outputs combined with SHACL constraints to enforce semantic validity on the resulting graph from LLM processing of logs.
Load-bearing premise
Domain ontologies and SHACL-based constraints can reliably guide LLM outputs to produce semantically valid graphs without introducing systematic errors or omitting critical details from ambiguous log entries.
What would settle it
A direct comparison of the extracted graphs from the proposed method versus manual expert annotations on a dataset of ambiguous cybersecurity logs, measuring precision, recall, and semantic consistency.
Figures


read the original abstract
Effective Cyber Threat Intelligence (CTI) relies upon accurately structured and semantically enriched information extracted from cybersecurity system logs. However, current methodologies often struggle to identify and interpret malicious events reliably and transparently, particularly in cases involving unstructured or ambiguous log entries. In this work, we propose a novel methodology that combines ontology-driven structured outputs with Large Language Models (LLMs), to build an Artificial Intelligence (AI) agent that improves the accuracy and explainability of information extraction from cybersecurity logs. Central to our approach is the integration of domain ontologies and SHACL-based constraints to guide the language model's output structure and enforce semantic validity over the resulting graph. Extracted information is organized into an ontology-enriched graph database, enabling future semantic analysis and querying. The design of our methodology is motivated by the analytical requirements associated with honeypot log data, which typically comprises predominantly malicious activity. While our case study illustrates the relevance of this scenario, the experimental evaluation is conducted using publicly available datasets. Results demonstrate that our method achieves higher accuracy in information extraction compared to traditional prompt-only approaches, with a deliberate focus on extraction quality rather than processing speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a methodology that integrates Large Language Models with domain ontologies and SHACL constraints to extract structured, semantically valid information from cybersecurity logs (motivated by honeypot data) and store the results in an ontology-enriched graph database. The central claim is that this ontology-guided approach yields higher accuracy and better explainability than traditional prompt-only LLM baselines, with emphasis on extraction quality over speed.
Significance. If the empirical claims hold, the work would offer a concrete advance in transparent CTI extraction by enforcing domain semantics on LLM outputs, addressing ambiguity in logs through symbolic constraints and enabling downstream semantic querying. The combination of neural generation with SHACL validation is a timely direction for reliable graph construction in security applications.
major comments (2)
- [Abstract] Abstract: the assertion that the method 'achieves higher accuracy in information extraction compared to traditional prompt-only approaches' is unsupported by any reported metrics, dataset descriptions, baseline comparisons, error analysis, or statistical tests. This absence directly undermines the central empirical claim of the paper.
- [Methodology] Methodology description: the account of how SHACL constraints are applied to LLM-generated outputs does not specify the enforcement mechanism (e.g., parsing pipeline, iterative repair loop, or measured violation rates), leaving unclear whether constraints correct omissions or invalid relations in ambiguous logs or merely decorate outputs after the fact.
minor comments (1)
- [Abstract] Specify the exact publicly available datasets used for evaluation and the precise definition of 'accuracy' employed (e.g., entity-level F1, relation-level precision).
Simulated Author's Rebuttal
We are grateful to the referee for the constructive and detailed review. The comments identify key areas where additional clarity and evidence will strengthen the manuscript, and we address each major comment below with planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the method 'achieves higher accuracy in information extraction compared to traditional prompt-only approaches' is unsupported by any reported metrics, dataset descriptions, baseline comparisons, error analysis, or statistical tests. This absence directly undermines the central empirical claim of the paper.
Authors: We acknowledge that the abstract claim requires explicit empirical support to be fully convincing. The manuscript reports results from experiments on publicly available datasets that show improved extraction quality relative to prompt-only baselines, but we agree the current presentation lacks the granularity of specific metrics, dataset details, baseline comparisons, error analysis, and statistical tests. In the revised version we will expand the evaluation section to include precision, recall, and F1 scores, full dataset descriptions, direct comparisons against prompt-only LLM baselines, qualitative error analysis, and appropriate statistical significance tests. revision: yes
-
Referee: [Methodology] Methodology description: the account of how SHACL constraints are applied to LLM-generated outputs does not specify the enforcement mechanism (e.g., parsing pipeline, iterative repair loop, or measured violation rates), leaving unclear whether constraints correct omissions or invalid relations in ambiguous logs or merely decorate outputs after the fact.
Authors: We thank the referee for highlighting this ambiguity. The current methodology section does not provide sufficient detail on the precise enforcement process. In the revised manuscript we will clarify the pipeline by describing how LLM outputs are parsed into RDF structures, the exact procedure for applying and validating SHACL shapes (including whether an iterative repair loop is employed when violations are detected), and any observed violation rates before versus after constraint enforcement. This revision will demonstrate that the constraints actively guide and correct the outputs for semantic validity rather than serving only as post-hoc decoration. revision: yes
Circularity Check
No circularity detected in methodology or claims
full rationale
The paper presents an engineering methodology that combines external domain ontologies and SHACL constraints with LLMs to structure outputs from cybersecurity logs, followed by empirical accuracy comparisons against prompt-only baselines on public datasets. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation; the accuracy improvement is measured externally rather than constructed from internal definitions or prior author results. The approach depends on independent ontology resources and observable extraction quality, making the chain self-contained without reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Domain ontologies accurately capture cybersecurity concepts and relationships for guiding extraction.
- domain assumption SHACL constraints can be applied to enforce validity on generated graph outputs from LLMs.
invented entities (1)
-
Ontology-enriched AI agent for CTI
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Central to our approach is the integration of domain ontologies and SHACL-based constraints to guide the language model's output structure and enforce semantic validity over the resulting graph.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The correction process is coordinated through the LLM’s structured output tool, which performs automatic validation using two key criteria... ontology compliance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
E. M. Hutchins, M. J. Cloppert, R. M. Amin, et al., Intelligence-driven computer network de- fense informed by analysis of adversary campaigns and intrusion kill chains, Leading Issues in Information Warfare & Security Research 1 (2011) 80
work page 2011
-
[2]
P. McDaniel, B. Rivera, A. Swami, Towards proactive cybersecurity: Methodologies and tools, IEEE Security & Privacy 14 (2016) 12–14
work page 2016
- [3]
-
[4]
A Survey on Honeypot Software and Data Analysis
M. Nawrocki, M. Wählisch, T. C. Schmidt, C. Keil, J. Schönfelder, A survey on honeypot software and data analysis, arXiv preprint arXiv:1608.06249 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
G. Izacard, E. Grave, Leveraging passage retrieval with generative models for open domain question answering, arXiv preprint arXiv:2007.01282 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2007
- [6]
-
[7]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
A. Srivastava, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. R. Brown, A. Santoro, A. Gupta, A. Garriga-Alonso, et al., Beyond the imitation game: Quantifying and extrapolating the capabilities of language models, arXiv preprint arXiv:2206.04615 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [8]
-
[9]
Spitzner, Honeypots: Tracking Hackers, Addison-Wesley Professional, 2003
L. Spitzner, Honeypots: Tracking Hackers, Addison-Wesley Professional, 2003
work page 2003
-
[10]
D. Fraunholz, S. D. Anton, C. Lipps, F. Pohl, M. Zimmermann, H. D. Schotten, Investigation of cyber crime conducted by abusing weak or default passwords with a medium interaction honeypot, IEEE Access 6 (2018) 37163–37174
work page 2018
- [11]
-
[12]
Z. Syed, A. Padia, T. Finin, L. Mathews, A. Joshi, Uco: A unified cybersecurity ontology, in: AAAI Workshop: Artificial Intelligence for Cyber Security, 2016, pp. 14–21
work page 2016
-
[13]
S. Barnum, Standardizing cyber threat intelligence information with the structured threat infor- mation expression (stix), The MITRE Corporation (2012)
work page 2012
- [14]
-
[15]
A. Oltramari, L. F. Cranor, R. J. Walls, P. McDaniel, Building an ontology of cyber security, in: Proceedings of the Ninth Conference on Semantic Technology for Intelligence, Defense, and Security (STIDS), CEUR-WS.org, 2014, pp. 54–61
work page 2014
- [16]
-
[17]
E. Kiesling, A. Ekelhart, K. Kurniawan, F. J. Ekaputra, The SEPSES knowledge graph: An integrated resource for cybersecurity, in: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part II, volume 11779 of Lecture Notes in Computer Science, Springer, 2019, pp. 198–214. URL: h...
- [18]
-
[19]
H. Knublauch, D. Kontokostas, Shapes constraint language (shacl), W3C Recommendation 20 (2017)
work page 2017
- [20]
-
[21]
K. Rabbani, M. Lissandrini, K. Hose, SHACTOR: improving the quality of large-scale knowledge graphs with validating shapes, in: S. Das, I. Pandis, K. S. Candan, S. Amer-Yahia (Eds.), Companion of the 2023 International Conference on Management of Data, SIGMOD/PODS 2023, Seattle, WA, USA, June 18-23, 2023, ACM, 2023, pp. 151–154. URL: https://doi.org/10.11...
-
[22]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
work page 2017
-
[23]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
work page 2019
-
[24]
T. B. Brown, B. Mann, N. Ryder, et al., Language models are few-shot learners, Advances in Neural Information Processing Systems 33 (2020) 1877–1901
work page 2020
-
[25]
K. Guu, K. Lee, Z. Tung, P. Pasupat, M. Chang, Retrieval augmented language model pre-training, in: International conference on machine learning, PMLR, 2020, pp. 3929–3938
work page 2020
-
[26]
D. B. Acharya, K. Kuppan, B. Divya, Agentic ai: Autonomous intelligence for complex goals–a comprehensive survey, IEEE Access (2025)
work page 2025
-
[27]
R. Sapkota, K. I. Roumeliotis, M. Karkee, AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenges, 2025. doi:10.48550/arXiv.2505.10468. arXiv:2505.10468
-
[28]
F. Sado, C. K. Loo, W. S. Liew, M. Kerzel, S. Wermter, Explainable goal-driven agents and robots-a comprehensive review, ACM Computing Surveys 55 (2023) 1–41
work page 2023
- [29]
-
[30]
J. Carbonell, J. Goldstein, The use of mmr, diversity-based reranking for reordering documents and producing summaries, in: Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, 1998, pp. 335–336
work page 1998
-
[31]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, I. Stoica, Efficient memory management for large language model serving with pagedattention, 2023. URL: https://arxiv.org/abs/2309.06180. arXiv:2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
G. C. Publio, D. Esteves, A. Lawrynowicz, P. Panov, L. N. Soldatova, T. Soru, J. Vanschoren, H. Zafar, Ml-schema: Exposing the semantics of machine learning with schemas and ontologies, CoRR abs/1807.05351 (2018). URL: http://arxiv.org/abs/1807.05351. arXiv:1807.05351
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
M. Landauer, F. Skopik, M. Frank, W. Hotwagner, M. Wurzenberger, A. Rauber, AIT Log Data Set V2.0, 2022. doi:10.5281/zenodo.5789064
-
[34]
Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, C. Zhu, G-eval: Nlg evaluation using gpt-4 with better human alignment, 2023. URL: https://arxiv.org/abs/2303.16634. arXiv:2303.16634
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.