Amplitude Uncertainties Everywhere All at Once
Pith reviewed 2026-05-18 19:18 UTC · model grok-4.3
The pith
Neural network surrogates for particle amplitudes learn to quantify their uncertainties and flag training data problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ultra-fast amplitude surrogates need controlled uncertainties. Network ensembles reduce noise and biases while a new calibration method learns systematic uncertainties for them. Evidential regression supplies sampling-free uncertainty quantification. Learned uncertainties from Bayesian networks, ensembles, and evidential regression identify numerical noise or gaps in the training data for amplitude regression.
What carries the argument
Evidential regression as a sampling-free uncertainty method, together with Bayesian networks and network ensembles that learn to report systematic uncertainties in amplitude predictions.
If this is right
- LHC event generation can incorporate these surrogates with built-in uncertainty control for more reliable fast simulations.
- Training data collection can focus on high-uncertainty regions to fill gaps and reduce noise.
- Sampling-free methods such as evidential regression become practical for large-scale amplitude regression tasks.
Where Pith is reading between the lines
- The same uncertainty signals could drive adaptive training loops that generate extra data only where needed.
- Comparable techniques might improve machine-learning surrogates for other LHC observables beyond amplitudes.
- If the uncertainty flags prove robust, they could reduce the volume of traditional Monte Carlo samples required for validation.
Load-bearing premise
The training data for amplitudes contains numerical noise or gaps that uncertainty estimates can reliably detect without external validation.
What would settle it
An independent test set with deliberately added numerical noise or removed data points in known regions; the uncertainty maps should show elevated values exactly where the artificial problems were inserted.
Figures













read the original abstract
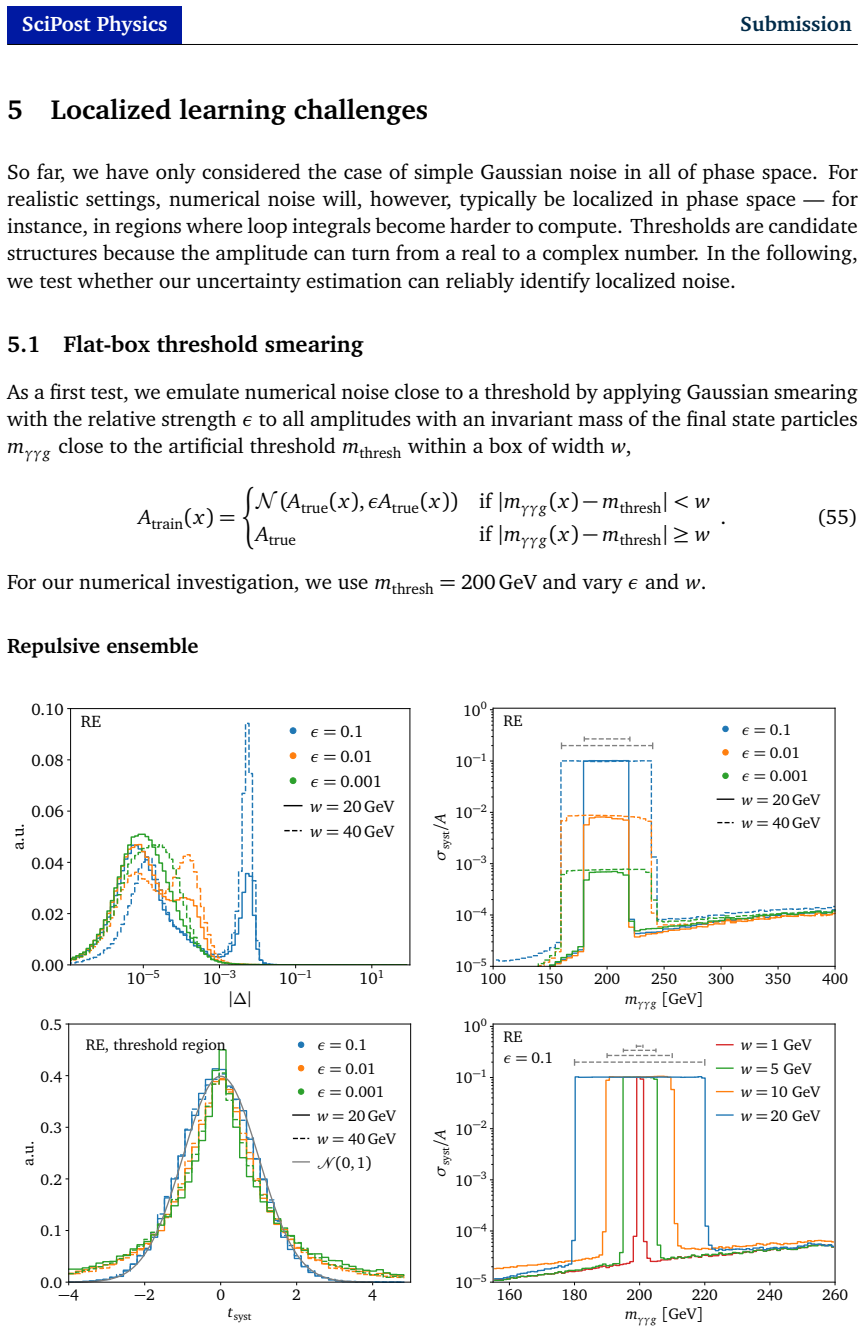
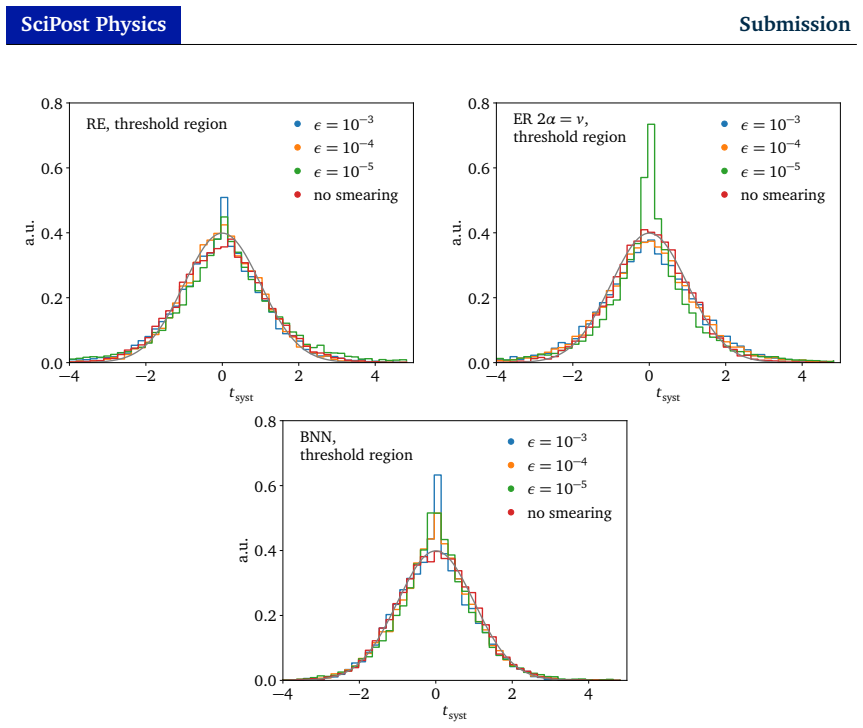
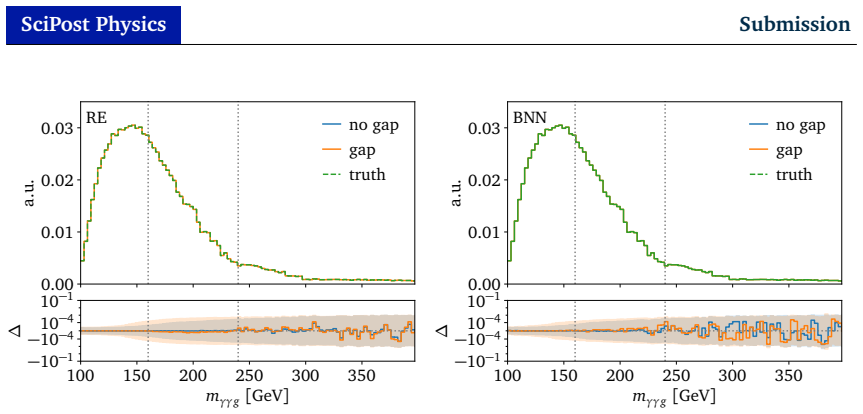
Ultra-fast, precise, and controlled amplitude surrogates are essential for future LHC event generation. First, we investigate the noise reduction and biases of network ensembles and outline a new method to learn well-calibrated systematic uncertainties for them. We also establish evidential regression as a sampling-free method for uncertainty quantification. In a second part, we tackle localized disturbances for amplitude regression and demonstrate that learned uncertainties from Bayesian networks, ensembles, and evidential regression all identify numerical noise or gaps in the training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates uncertainty quantification (UQ) for neural network surrogates of scattering amplitudes in high-energy physics. It first examines noise reduction and biases in network ensembles and outlines a method to learn well-calibrated systematic uncertainties; it then establishes evidential regression as a sampling-free UQ technique. In the second part, the work demonstrates that uncertainties learned from Bayesian networks, ensembles, and evidential regression identify numerical noise or gaps in the amplitude training data.
Significance. If the central claims are substantiated with quantitative validation, the results would provide a practical, sampling-free route to uncertainty-aware amplitude surrogates for LHC event generation, directly addressing Monte Carlo integration artifacts and interpolation gaps. The explicit comparison of multiple UQ approaches (ensembles, Bayesian networks, evidential regression) and the focus on localized disturbances constitute a useful contribution to surrogate modeling in hep-ph.
major comments (2)
- [Abstract] Abstract: the claim that 'learned uncertainties from Bayesian networks, ensembles, and evidential regression all identify numerical noise or gaps in the training data' is load-bearing for the second part of the paper yet is presented without quantitative metrics, error bars, or an independent benchmark (e.g., recomputing amplitudes at high-uncertainty points with a higher-precision integrator and reporting correlation between predicted uncertainty and observed discrepancy).
- [Abstract] Abstract: no validation metrics, cross-validation scores, or details on how noise identification was demonstrated are supplied, preventing assessment of whether the flagged regions correspond to actual numerical artifacts rather than generic high-variance kinematics or training-set sparsity.
minor comments (2)
- Clarify the precise amplitude processes and kinematic ranges used for the regression tasks.
- Add a brief description of the network architectures and training protocols employed for the ensembles and evidential regression models.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive assessment of its potential significance for uncertainty-aware amplitude surrogates. We address the two major comments on the abstract below and have revised the manuscript to incorporate quantitative validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'learned uncertainties from Bayesian networks, ensembles, and evidential regression all identify numerical noise or gaps in the training data' is load-bearing for the second part of the paper yet is presented without quantitative metrics, error bars, or an independent benchmark (e.g., recomputing amplitudes at high-uncertainty points with a higher-precision integrator and reporting correlation between predicted uncertainty and observed discrepancy).
Authors: We agree that the abstract statement would benefit from supporting quantitative evidence. In the revised manuscript we have added a dedicated validation subsection that selects the top 5% highest-uncertainty test points for each method, recomputes those amplitudes with a higher-precision integrator, and reports the Pearson correlation between predicted uncertainty and observed discrepancy together with bootstrap error bars. The correlations are positive and statistically significant for all three approaches, confirming that the learned uncertainties flag genuine numerical artifacts. revision: yes
-
Referee: [Abstract] Abstract: no validation metrics, cross-validation scores, or details on how noise identification was demonstrated are supplied, preventing assessment of whether the flagged regions correspond to actual numerical artifacts rather than generic high-variance kinematics or training-set sparsity.
Authors: We have expanded both the abstract and the main text to include the requested details. The revised version now reports 5-fold cross-validation scores for uncertainty calibration, together with a quantitative comparison of high-uncertainty regions against the training-data density. We show that the fraction of high-uncertainty points lying in sparsely sampled kinematic bins is significantly higher than expected from a uniform random sample, and we include density plots that distinguish these localized gaps from generic high-variance phase-space regions. revision: yes
Circularity Check
No significant circularity; empirical ML study with independent experimental validation
full rationale
The paper is an empirical investigation of neural network ensembles, Bayesian networks, and evidential regression applied to amplitude regression for LHC surrogates. It reports experimental results on noise reduction, bias, and uncertainty calibration, then demonstrates that learned uncertainties flag regions of numerical noise or training gaps. No derivation chain, first-principles equations, or parameter-fitting steps are claimed that reduce by construction to the inputs (e.g., no fitted parameter renamed as a prediction, no self-definitional ansatz, no uniqueness theorem imported from self-citation). Central claims rest on direct comparison of model outputs against training data properties rather than any self-referential loop. Self-citations, if present, are not load-bearing for the empirical demonstrations. This is a standard non-circular finding for applied ML work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks can serve as accurate surrogates for scattering amplitudes
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
learned uncertainties from Bayesian networks, ensembles, and evidential regression all identify numerical noise or gaps in the training data
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
heteroscedastic loss L_het and natural parametrization for systematic uncertainty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Open LHC Monte Carlo Event Generation
A review of initiatives to make LHC Monte Carlo event generations available as open data to minimize redundant simulations and resource use.
-
The Monte Carlo Ecosystem in High-Energy Physics: A Primer
A primer that surveys the architecture, methodologies, computational challenges, and future trajectory of the Monte Carlo event generator ecosystem in collider physics.
Reference graph
Works this paper leans on
-
[1]
Butteret al., SciPost Phys.14, 079 (2023), arXiv:2203.07460 [hep-ph]
S. Badger et al., Machine learning and LHC event generation, SciPost Phys. 14 (2023) 4, 079, arXiv:2203.07460 [hep-ph]
- [2]
-
[3]
E. Bothmann, T . Janßen, M. Knobbe, T . Schmale, and S. Schumann,Exploring phase space with Neural Importance Sampling, SciPost Phys. 8 (1, 2020) 069, arXiv:2001.05478 [hep-ph]
- [4]
- [5]
- [6]
-
[7]
E. Bothmann, T . Childers, W . Giele, F . Herren, S. Hoeche, J. Isaacson, M. Knobbe, and R. Wang, Efficient phase-space generation for hadron collider event simulation, SciPost Phys. 15 (2023) 4, 169, arXiv:2302.10449 [hep-ph]
-
[8]
T . Heimel, N. Huetsch, F . Maltoni, O. Mattelaer, T . Plehn, and R. Winterhalder,The MadNIS reloaded, SciPost Phys. 17 (2024) 1, 023, arXiv:2311.01548 [hep-ph]
-
[9]
N. Deutschmann and N. Götz, Accelerating HEP simulations with Neural Importance Sampling, JHEP 03 (2024) 083, arXiv:2401.09069 [hep-ph]
- [10]
- [11]
-
[12]
E. Bothmann, T . Janßen, M. Knobbe, B. Schmitzer, and F . Sinz,Efficient many-jet event generation with Flow Matching, arXiv:2506.18987 [hep-ph]
-
[13]
F . Bishara and M. Montull,(Machine) Learning Amplitudes for Faster Event Generation, arXiv:1912.11055 [hep-ph]
-
[14]
S. Badger and J. Bullock, Using neural networks for efficient evaluation of high multiplicity scattering amplitudes, JHEP 06 (2020) 114, arXiv:2002.07516 [hep-ph]
-
[15]
J. Aylett-Bullock, S. Badger, and R. Moodie, Optimising simulations for diphoton production at hadron colliders using amplitude neural networks, JHEP 08 (6, 2021) 066, arXiv:2106.09474 [hep-ph]
-
[16]
D. Maître and H. Truong, A factorisation-aware Matrix element emulator, JHEP 11 (7,
-
[17]
066, arXiv:2107.06625 [hep-ph]. 34 SciPost Physics Submission
-
[18]
R. Winterhalder, V . Magerya, E. Villa, S. P . Jones, M. Kerner, A. Butter, G. Heinrich, and T . Plehn,Targeting multi-loop integrals with neural networks, SciPost Phys. 12 (2022) 4, 129, arXiv:2112.09145 [hep-ph]
- [19]
-
[20]
D. Maître and H. Truong, One-loop matrix element emulation with factorisation awareness, arXiv:2302.04005 [hep-ph]
-
[21]
J. Spinner, V . Bresó, P . de Haan, T . Plehn, J. Thaler, and J. Brehmer,Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics, arXiv:2405.14806 [physics.data-an]
-
[22]
J. Brehmer, V . Bresó, P . de Haan, T . Plehn, H. Qu, J. Spinner, and J. Thaler,A Lorentz-Equivariant Transformer for All of the LHC, arXiv:2411.00446 [hep-ph]
- [23]
- [24]
-
[25]
LHC analysis-specific datasets with Generative Adversarial Networks
B. Hashemi, N. Amin, K. Datta, D. Olivito, and M. Pierini, LHC analysis-specific datasets with Generative Adversarial Networks, arXiv:1901.05282 [hep-ex]
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[26]
R. Di Sipio, M. Faucci Giannelli, S. Ketabchi Haghighat, and S. Palazzo,DijetGAN: A Generative-Adversarial Network Approach for the Simulation of QCD Dijet Events at the LHC, JHEP 08 (2019) 110, arXiv:1903.02433 [hep-ex]
- [27]
-
[28]
Y. Alanazi, N. Sato, T . Liu, W . Melnitchouk, M. P . Kuchera, E. Pritchard, M. Robertson, R. Strauss, L. Velasco, and Y. Li,Simulation of electron-proton scattering events by a Feature-Augmented and Transformed Generative Adversarial Network (FAT-GAN), arXiv:2001.11103 [hep-ph]
- [29]
-
[30]
M. Paganini, L. de Oliveira, and B. Nachman, Accelerating Science with Generative Adversarial Networks: An Application to 3D Particle Showers in Multilayer Calorimeters, Phys. Rev. Lett.120 (2018) 4, 042003, arXiv:1705.02355 [hep-ex]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
M. Paganini, L. de Oliveira, and B. Nachman, CaloGAN : Simulating 3D high energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks, Phys. Rev. D97 (2018) 1, 014021, arXiv:1712.10321 [hep-ex]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
M. Erdmann, J. Glombitza, and T . Quast,Precise simulation of electromagnetic calorimeter showers using a Wasserstein Generative Adversarial Network, Comput. Softw. Big Sci. 3 (2019) 1, 4, arXiv:1807.01954 [physics.ins-det]
-
[33]
D. Belayneh et al., Calorimetry with Deep Learning: Particle Simulation and Reconstruction for Collider Physics, Eur. Phys. J. C 80 (12, 2020) 688, arXiv:1912.06794 [physics.ins-det]. 35 SciPost Physics Submission
-
[34]
E. Buhmann, S. Diefenbacher, E. Eren, F . Gaede, G. Kasieczka, A. Korol, and K. Krüger, Getting High: High Fidelity Simulation of High Granularity Calorimeters with High Speed, Comput. Softw. Big Sci. 5 (2021) 1, 13, arXiv:2005.05334 [physics.ins-det]
-
[35]
C. Krause and D. Shih, CaloFlow: Fast and Accurate Generation of Calorimeter Showers with Normalizing Flows, arXiv:2106.05285 [physics.ins-det]
- [36]
-
[37]
C. Krause and D. Shih, CaloFlow II: Even Faster and Still Accurate Generation of Calorimeter Showers with Normalizing Flows, arXiv:2110.11377 [physics.ins-det]
-
[38]
E. Buhmann, S. Diefenbacher, D. Hundhausen, G. Kasieczka, W . Korcari, E. Eren, F . Gaede, K. Krüger, P . McKeown, and L. Rustige,Hadrons, better, faster, stronger, Mach. Learn. Sci. Tech. 3 (2022) 2, 025014, arXiv:2112.09709 [physics.ins-det]
-
[39]
C. Chen, O. Cerri, T . Q. Nguyen, J. R. Vlimant, and M. Pierini,Analysis-Specific Fast Simulation at the LHC with Deep Learning, Comput. Softw. Big Sci. 5 (2021) 1, 15
work page 2021
-
[40]
V . Mikuni and B. Nachman,Score-based generative models for calorimeter shower simulation, Phys. Rev. D106 (2022) 9, 092009, arXiv:2206.11898 [hep-ph]
-
[41]
J. C. Cresswell, B. L. Ross, G. Loaiza-Ganem, H. Reyes-Gonzalez, M. Letizia, and A. L. Caterini, CaloMan: Fast generation of calorimeter showers with density estimation on learned manifolds, in 36th Conference on Neural Information Processing Systems. 11,
- [42]
-
[43]
S. Diefenbacher, E. Eren, F . Gaede, G. Kasieczka, C. Krause, I. Shekhzadeh, and D. Shih, L2LFlows: Generating High-Fidelity 3D Calorimeter Images, arXiv:2302.11594 [physics.ins-det]
- [44]
-
[45]
E. Buhmann, S. Diefenbacher, E. Eren, F . Gaede, G. Kasieczka, A. Korol, W . Korcari, K. Krüger, and P . McKeown,CaloClouds: Fast Geometry-Independent Highly-Granular Calorimeter Simulation, arXiv:2305.04847 [physics.ins-det]
- [46]
-
[47]
S. Diefenbacher, V . Mikuni, and B. Nachman,Refining Fast Calorimeter Simulations with a Schrödinger Bridge, arXiv:2308.12339 [physics.ins-det]
- [48]
- [49]
- [50]
-
[51]
G. Quétant, J. A. Raine, M. Leigh, D. Sengupta, and T . Golling,Generating variable length full events from partons, Phys. Rev. D110 (2024) 7, 076023, arXiv:2406.13074 [hep-ph]
-
[52]
O. Amram et al., CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation, arXiv:2410.21611 [cs.LG]
- [53]
-
[54]
S. Bieringer, A. Butter, S. Diefenbacher, E. Eren, F . Gaede, D. Hundhausen, G. Kasieczka, B. Nachman, T . Plehn, and M. Trabs,Calomplification — the power of generative calorimeter models, JINST 17 (2022) 09, P09028, arXiv:2202.07352 [hep-ph]
-
[55]
S. Bieringer, S. Diefenbacher, G. Kasieczka, and M. Trabs,Calibrating Bayesian generative machine learning for Bayesiamplification, Mach. Learn. Sci. Tech. 5 (2024) 4, 045044, arXiv:2408.00838 [cs.LG]
-
[56]
K. Danziger, T . Janßen, S. Schumann, and F . Siegert,Accelerating Monte Carlo event generation – rejection sampling using neural network event-weight estimates, SciPost Phys. 12 (9, 2022) 164, arXiv:2109.11964 [hep-ph]
- [57]
-
[58]
Accelerating multijet-merged event generation with neural network matrix element surrogates
T . Herrmann, T . Janßen, M. Schenker, S. Schumann, and F . Siegert,Accelerating multijet-merged event generation with neural network matrix element surrogates, arXiv:2506.06203 [hep-ph]
-
[59]
Gal, Uncertainty in Deep Learning
Y. Gal, Uncertainty in Deep Learning. PhD thesis, Cambridge, 2016
work page 2016
-
[60]
S. Bollweg, M. Haußmann, G. Kasieczka, M. Luchmann, T . Plehn, and J. Thompson, Deep-Learning Jets with Uncertainties and More, SciPost Phys. 8 (2020) 1, 006, arXiv:1904.10004 [hep-ph]
-
[61]
G. Kasieczka, M. Luchmann, F . Otterpohl, and T . Plehn,Per-Object Systematics using Deep-Learned Calibration, SciPost Phys. 9 (2020) 089, arXiv:2003.11099 [hep-ph]
-
[62]
F . D’Angelo and V . Fortuin,Repulsive deep ensembles are bayesian, arXiv:2106.11642 [cs.LG]
- [63]
- [64]
- [65]
-
[66]
N. Meinert and A. Lavin, Multivariate Deep Evidential Regression, arXiv:2104.06135 [cs.LG]
- [67]
-
[68]
M. Seitzer, A. Tavakoli, D. Antic, and G. Martius,On the pitfalls of heteroscedastic uncertainty estimation with probabilistic neural networks, arXiv:2203.09168 [cs.LG]
-
[69]
A. Stirn, H.-H. Wessels, M. Schertzer, L. Pereira, N. E. Sanjana, and D. A. Knowles, Faithful heteroscedastic regression with neural networks, arXiv:2212.09184 [cs.LG]
- [70]
-
[71]
Sherpa Collaboration, Event Generation with Sherpa 2.2, SciPost Phys. 7 (2019) 3, 034, arXiv:1905.09127 [hep-ph]
-
[72]
Numerical evaluation of virtual corrections to multi-jet production in massless QCD
S. Badger, B. Biedermann, P . Uwer, and V . Yundin,Numerical evaluation of virtual corrections to multi-jet production in massless QCD, Comput. Phys. Commun. 184 (2013) 1981, arXiv:1209.0100 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [73]
- [74]
-
[75]
Jordan, The exponential family: Conjugate priors
M. Jordan, The exponential family: Conjugate priors. 2009
work page 2009
- [76]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.