Preconditioned Regularized Wasserstein Proximal Sampling
Pith reviewed 2026-05-21 23:31 UTC · model grok-4.3
The pith
Preconditioning the regularized Wasserstein proximal operator enables efficient particle sampling from Gibbs distributions with step-size independent bias for quadratic potentials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that by preconditioning the regularized Wasserstein proximal sampling and using the score from the proximal operator derived via Cole-Hopf transformation, one obtains a practical particle-based sampling algorithm with explicit bias characterization for quadratic cases that is independent of step-size.
What carries the argument
The preconditioned regularized Wasserstein proximal operator, derived by Cole-Hopf transformation on coupled anisotropic heat equations, which provides the score approximation and kernel formulation for the sampling dynamics.
If this is right
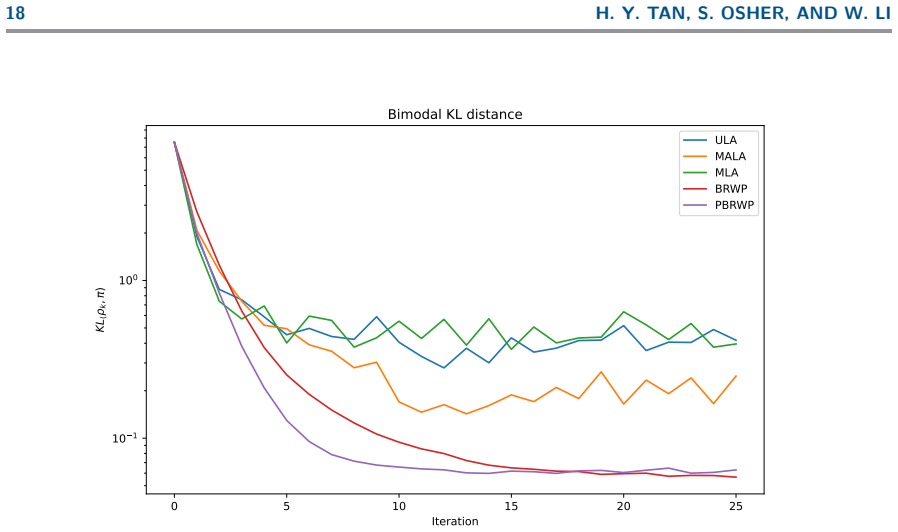
- Convergence analysis shows non-asymptotic rates for quadratic potentials with bias controlled solely by regularization.
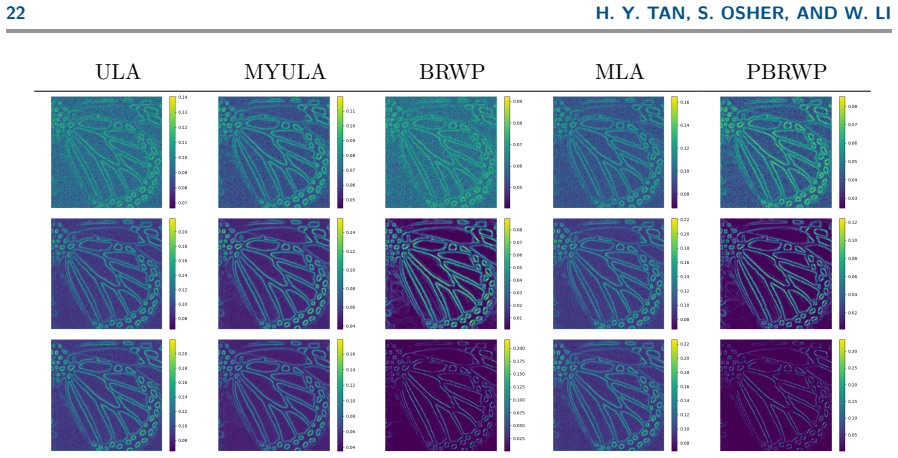
- The method achieves acceleration and particle stability on toy examples and real applications like Bayesian image deconvolution.
- Variable preconditioning matrices improve performance in non-convex settings such as Bayesian neural network training.
- The diffusion component interprets as a modified self-attention block, potentially linking to transformer models.
Where Pith is reading between the lines
- This framework might generalize the convergence results to non-quadratic potentials if similar bias independence can be shown.
- Connecting the proximal operator to self-attention could inspire new hybrid models combining sampling and attention mechanisms.
- Independent bias from step-size suggests robustness in choosing discretization parameters for practical implementations.
Load-bearing premise
The score function of the target distribution can be well approximated by the numerically tractable score of the regularized Wasserstein proximal operator obtained from the Cole-Hopf transformation.
What would settle it
Running the sampling algorithm on a quadratic potential with varying step sizes but fixed regularization and checking if the stationary distribution bias remains constant while changing regularization alters it.
Figures









read the original abstract
We consider sampling from a Gibbs distribution by evolving finitely many particles. We propose a preconditioned version of a recently proposed noise-free sampling method, governed by approximating the score function with the numerically tractable score of a regularized Wasserstein proximal operator. This is derived by a Cole--Hopf transformation on coupled anisotropic heat equations, yielding a kernel formulation for the preconditioned regularized Wasserstein proximal. The diffusion component of the proposed method is also interpreted as a modified self-attention block, as in transformer architectures. For quadratic potentials, we provide a discrete-time non-asymptotic convergence analysis and explicitly characterize the bias, which is dependent on regularization and independent of step-size. Experiments demonstrate acceleration and particle-level stability on various log-concave and non-log-concave toy examples to Bayesian total-variation regularized image deconvolution, and competitive/better performance on non-convex Bayesian neural network training when utilizing variable preconditioning matrices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a preconditioned regularized Wasserstein proximal sampling method for drawing particles from a Gibbs distribution. The score is approximated via the numerically tractable score of a regularized Wasserstein proximal operator, obtained through a Cole-Hopf transformation applied to coupled anisotropic heat equations that yields an explicit kernel formulation. The diffusion step is interpreted as a modified self-attention mechanism. For quadratic potentials the authors supply a discrete-time non-asymptotic convergence analysis together with an explicit bias characterization that depends on the regularization parameter but is claimed to be independent of step-size. Experiments on log-concave and non-log-concave toy problems, Bayesian total-variation image deconvolution, and non-convex Bayesian neural-network training are reported to demonstrate acceleration and particle stability.
Significance. If the non-asymptotic analysis and the step-size-independent bias result for quadratic potentials are rigorously established, the work would provide a concrete advance in noise-free particle-based sampling with explicit error controls and a novel link to attention mechanisms. The explicit bias formula tied only to regularization is a clear strength that could guide practical tuning; the reported experiments on both synthetic and applied tasks add empirical support.
major comments (1)
- [Quadratic potentials analysis] Quadratic-potential analysis (discrete-time non-asymptotic convergence section): the central claim that the bias is independent of step-size h rests on an unverified cancellation inside the one-step proximal map. Standard Euler or proximal discretizations of score-based dynamics produce O(h) or O(h^2) bias; the paper must supply an explicit expansion of the update for a quadratic V (or an equivalent algebraic verification) to confirm that the kernel obtained from the Cole-Hopf transformation exactly cancels the leading h-dependent term. Without this verification the independence statement is not yet load-bearing.
minor comments (2)
- [Abstract] The abstract states that the bias 'is dependent on regularization and independent of step-size' but provides no quantitative error bounds or statement of the precise norm in which convergence is measured; adding one sentence with the leading-order bias expression would improve clarity.
- [Method and analysis sections] Notation for the preconditioning matrix and the regularization parameter should be introduced once in a dedicated 'Notation' paragraph rather than scattered across the method and analysis sections.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive feedback on our work. The single major comment raises a valid point about the need for explicit verification in the quadratic-potential analysis. We address it directly below and will revise the manuscript to incorporate the requested algebraic details.
read point-by-point responses
-
Referee: [Quadratic potentials analysis] Quadratic-potential analysis (discrete-time non-asymptotic convergence section): the central claim that the bias is independent of step-size h rests on an unverified cancellation inside the one-step proximal map. Standard Euler or proximal discretizations of score-based dynamics produce O(h) or O(h^2) bias; the paper must supply an explicit expansion of the update for a quadratic V (or an equivalent algebraic verification) to confirm that the kernel obtained from the Cole-Hopf transformation exactly cancels the leading h-dependent term. Without this verification the independence statement is not yet load-bearing.
Authors: We agree that an explicit algebraic verification is required to make the step-size independence rigorous. The current manuscript derives the kernel via the Cole-Hopf transformation on the coupled anisotropic heat equations and states that the resulting bias depends only on the regularization parameter, but it does not include a term-by-term expansion of the one-step update for quadratic V. In the revision we will add this expansion in the discrete-time non-asymptotic convergence section. Specifically, we will substitute the quadratic potential into the proximal map, apply the explicit kernel formula, and show that all O(h) and O(h^2) bias contributions cancel identically, leaving a remainder that depends solely on the regularization strength. This verification will be presented as a self-contained lemma with the algebraic steps spelled out. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives the preconditioned regularized Wasserstein proximal operator via Cole-Hopf transformation applied to coupled anisotropic heat equations, yielding an explicit kernel formulation. This PDE step is a standard external technique with independent mathematical grounding and does not reduce to a self-definition or fitted input. The discrete-time non-asymptotic convergence analysis for quadratic potentials explicitly characterizes bias as a function of the regularization parameter (independent of step-size h), without evidence that the bias term is obtained by construction from the discretization or from a self-citation chain. No load-bearing uniqueness theorem, ansatz smuggling, or renaming of known results is present; the central claims remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization parameter
axioms (1)
- domain assumption The score function can be approximated by the score of a regularized Wasserstein proximal operator.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For quadratic potentials, we provide a discrete-time non-asymptotic convergence analysis and explicitly characterize the bias, which is dependent on regularization and independent of step-size.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
derived by a Cole–Hopf transformation on coupled anisotropic heat equations, yielding a kernel formulation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. V. Afonso, J. M. Bioucas-Dias, and M. A. Figueiredo, Fast image recovery using variable splitting and constrained optimization, IEEE transactions on image processing, 19 (2010), pp. 2345–2356
work page 2010
-
[2]
J.-D. Benamou and Y. Brenier , A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem, Numerische Mathematik, 84 (2000), pp. 375–393
work page 2000
-
[3]
N. Bleistein and R. A. Handelsman , Asymptotic expansions of integrals , Ardent Media, 1975
work page 1975
-
[4]
S. Bond-Taylor, A. Leach, Y. Long, and C. G. Willcocks, Deep generative modelling: A comparative review of VAEs, GANs, normalizing flows, energy-based and autoregressive models , IEEE transactions on pattern analysis and machine intelligence, (2021)
work page 2021
-
[5]
Z. I. Botev, J. F. Grotowski, and D. P. Kroese , Kernel density estimation via diffusion , Annals of Statistics, 38 (2010), pp. 2916–2957
work page 2010
-
[6]
J. A. Carrillo, K. Craig, and F. S. Patacchini , A blob method for diffusion , Calculus of Variations and Partial Differential Equations, 58 (2019), pp. 1–53
work page 2019
-
[7]
A unified perspective on the dynamics of deep transformers.arXiv preprint arXiv:2501.18322,
V. Castin, P. Ablin, J. A. Carrillo, and G. Peyr ´e, A unified perspective on the dynamics of deep 26 H. Y. TAN, S. OSHER, AND W. LI transformers, arXiv preprint arXiv:2501.18322, (2025)
-
[8]
R. T. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud , Neural ordinary differential equations, Advances in neural information processing systems, 31 (2018)
work page 2018
-
[9]
L. Condat, A primal–dual splitting method for convex optimization involving Lipschitzian, proximable and linear composite terms , Journal of optimization theory and applications, 158 (2013), pp. 460–479
work page 2013
-
[10]
A. Durmus and ´E. Moulines, High-dimensional Bayesian inference via the unadjusted Langevin algorithm, Bernoulli, 25 (2019), pp. 2854–2882
work page 2019
- [11]
- [12]
-
[13]
B. Geshkovski, C. Letrouit, Y. Polyanskiy, and P. Rigollet , A mathematical perspective on transformers, Bulletin of the American Mathematical Society, 62 (2025), pp. 427–479
work page 2025
-
[14]
Gramacki, Nonparametric kernel density estimation and its computational aspects , vol
A. Gramacki, Nonparametric kernel density estimation and its computational aspects , vol. 37, Springer, 2018
work page 2018
-
[15]
A. Habring, A. Falk, and T. Pock , Diffusion at absolute zero: Langevin sampling using successive Moreau envelopes, in 2025 IEEE Statistical Signal Processing Workshop (SSP), IEEE, 2025, pp. 61–65
work page 2025
-
[16]
A. Habring, M. Holler, and T. Pock , Subgradient langevin methods for sampling from nonsmooth potentials, SIAM Journal on Mathematics of Data Science, 6 (2024), pp. 897–925
work page 2024
- [17]
- [18]
-
[19]
F. Han, S. Osher, and W. Li , Tensor train based sampling algorithms for approximating regularized Wasserstein proximal operators, SIAM/ASA Journal on Uncertainty Quantification, 13 (2025), pp. 775– 804
work page 2025
-
[20]
J. R. Hershey and P. A. Olsen, Approximating the Kullback Leibler divergence between Gaussian mixture models, in 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, vol. 4, IEEE, 2007, pp. IV–317
work page 2007
- [21]
-
[22]
D. Hwang, Fadam: Adam is a natural gradient optimizer using diagonal empirical Fisher information , arXiv preprint arXiv:2405.12807, (2024)
-
[23]
Q. Jiang, Mirror Langevin Monte Carlo: the case under isoperimetry , Advances in Neural Information Processing Systems, 34 (2021), pp. 715–725
work page 2021
-
[24]
D. P. Kingma and J. Ba , Adam: A method for stochastic optimization , arXiv preprint arXiv:1412.6980, (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[25]
Krauth, Statistical mechanics: algorithms and computations , vol
W. Krauth, Statistical mechanics: algorithms and computations , vol. 13, OUP Oxford, 2006
work page 2006
-
[26]
Kubo, Stochastic Liouville equations , Journal of Mathematical Physics, 4 (1963), pp
R. Kubo, Stochastic Liouville equations , Journal of Mathematical Physics, 4 (1963), pp. 174–183
work page 1963
-
[27]
F. Kunstner, P. Hennig, and L. Balles , Limitations of the empirical fisher approximation for natural gradient descent, Advances in neural information processing systems, 32 (2019)
work page 2019
-
[28]
R. Laumont, V. D. Bortoli, A. Almansa, J. Delon, A. Durmus, and M. Pereyra , Bayesian imaging using plug & play priors: when Langevin meets Tweedie , SIAM Journal on Imaging Sciences, 15 (2022), pp. 701–737
work page 2022
-
[29]
W. Li, S. Liu, and S. Osher , A kernel formula for regularized Wasserstein proximal operators , Research in the Mathematical Sciences, 10 (2023), p. 43
work page 2023
-
[30]
W. Li, W. Liu, J. Chen, L. Wu, P. D. Flynn, W. Ding, and P. Chen , Reducing mode collapse with Monge–Kantorovich optimal transport for generative adversarial networks , IEEE Transactions on Cybernetics, (2023)
work page 2023
-
[31]
D. J. MacKay, Bayesian neural networks and density networks , Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 354 (1995), pp. 73–80
work page 1995
-
[32]
E. Nijkamp, R. Gao, P. Sountsov, S. Vasudevan, B. Pang, S.-C. Zhu, and Y. N. Wu , MCMC PRECONDITIONED REGULARIZED WASSERSTEIN PROXIMAL SAMPLING METHODS 27 should mix: learning energy-based model with neural transport latent space MCMC. , in International Conference on Learning Representations (ICLR 2022)., 2022
work page 2022
-
[33]
K. B. Petersen, M. S. Pedersen, et al. , The matrix cookbook, Technical University of Denmark, 7 (2008), p. 510
work page 2008
-
[34]
H. Risken, Fokker-Planck equation, in The Fokker-Planck equation: methods of solution and applications, Springer, 1989, pp. 63–95
work page 1989
-
[35]
G. O. Roberts and R. L. Tweedie, Exponential convergence of Langevin distributions and their discrete approximations, Bernoulli, (1996), pp. 341–363
work page 1996
-
[36]
P. J. Rossky, J. D. Doll, and H. L. Friedman , Brownian dynamics as smart Monte Carlo simulation , The Journal of Chemical Physics, 69 (1978), pp. 4628–4633
work page 1978
-
[37]
L. I. Rudin, S. Osher, and E. Fatemi, Nonlinear total variation based noise removal algorithms , Physica D: nonlinear phenomena, 60 (1992), pp. 259–268
work page 1992
-
[38]
M. E. Sander, P. Ablin, M. Blondel, and G. Peyr ´e, Sinkformers: Transformers with doubly stochastic attention, in International Conference on Artificial Intelligence and Statistics, PMLR, 2022, pp. 3515–3530
work page 2022
-
[39]
Santambrogio, Optimal transport for applied mathematicians , vol
F. Santambrogio, Optimal transport for applied mathematicians , vol. 87, Springer, 2015
work page 2015
-
[40]
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole , Score-based generative modeling through stochastic differential equations , in International Conference on Learning Representations, 2021
work page 2021
-
[41]
A. Srivastava, L. Valkov, C. Russell, M. U. Gutmann, and C. Sutton, Veegan: Reducing mode collapse in GANs using implicit variational learning , Advances in neural information processing systems, 30 (2017)
work page 2017
-
[42]
A. M. Stuart, Inverse problems: a Bayesian perspective , Acta numerica, 19 (2010), pp. 451–559
work page 2010
-
[43]
J. Tachella, M. Terris, S. Hurault, A. Wang, D. Chen, M.-H. Nguyen, M. Song, T. Davies, L. Davy, J. Dong, et al. , Deepinverse: A python package for solving imaging inverse problems with deep learning, arXiv preprint arXiv:2505.20160, (2025)
-
[44]
H. Y. Tan, Z. Cai, M. Pereyra, S. Mukherjee, J. Tang, and C.-B. Sch ¨onlieb, Unsupervised training of convex regularizers using maximum likelihood estimation , Transactions on Machine Learning Research, (2024)
work page 2024
-
[45]
H. Y. Tan, S. Osher, and W. Li , Noise-free sampling algorithms via regularized Wasserstein proximals , Research in the Mathematical Sciences, 11 (2024), p. 65
work page 2024
-
[46]
R. J. Tibshirani, S. W. Fung, H. Heaton, and S. Osher, Laplace meets Moreau: Smooth approximation to infimal convolutions using Laplace’s method , Journal of Machine Learning Research, 26 (2025), pp. 1–36
work page 2025
-
[47]
Van Kerm, Adaptive kernel density estimation , The Stata Journal, 3 (2003), pp
P. Van Kerm, Adaptive kernel density estimation , The Stata Journal, 3 (2003), pp. 148–156
work page 2003
-
[48]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Attention is all you need , Advances in neural information processing systems, 30 (2017)
work page 2017
-
[49]
M. P. Wand and M. C. Jones , Kernel smoothing, CRC press, 1994
work page 1994
-
[50]
log |˜Σk| |˜Σk+1| + Tr ˜Σ−1 ∞ (˜Σk+1 − ˜Σk) # = 1 2
Y. Wang and W. Li, Accelerated information gradient flow, Journal of Scientific Computing, 90 (2022), pp. 1–47. 28 H. Y. TAN, S. OSHER, AND W. LI Appendix A. Proofs. A.1. Anisotropic Green’s function. Recall (3.1): (A.1) Gt,M(x, y) := 1 (4πβ −1t)d/2|M |1/2 e−β (x−y)⊤M −1(x−y) 4t . Proposition A.1. The anisotropic kernel Gt,M(x, y) is a Green’s function fo...
work page 2022
-
[51]
// bias correction 6 M (k) = diag(1/(√ˆvk + ϵ)) ; // construct preconditioning matrix 7 end 8 return (M (k))K k=1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.