AR-KAN: Autoregressive-Weight-Enhanced Kolmogorov-Arnold Network for Time Series Forecasting
Pith reviewed 2026-05-18 19:19 UTC · model grok-4.3
The pith
AR-KAN integrates a pre-trained autoregressive module with KAN to preserve temporal features and tighten the probabilistic approximation error bound for almost-periodic time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AR-KAN integrates a pre-trained autoregressive module with a Kolmogorov-Arnold Network on the basis of the Universal Myopic Mapping Theorem. The AR module preserves essential temporal features while reducing redundancy, and the upper bound of the approximation error for AR-KAN is smaller than that for KAN in a probabilistic sense. Experiments on synthetic almost-periodic functions and real-world datasets show that AR-KAN outperforms existing models in time series forecasting.
What carries the argument
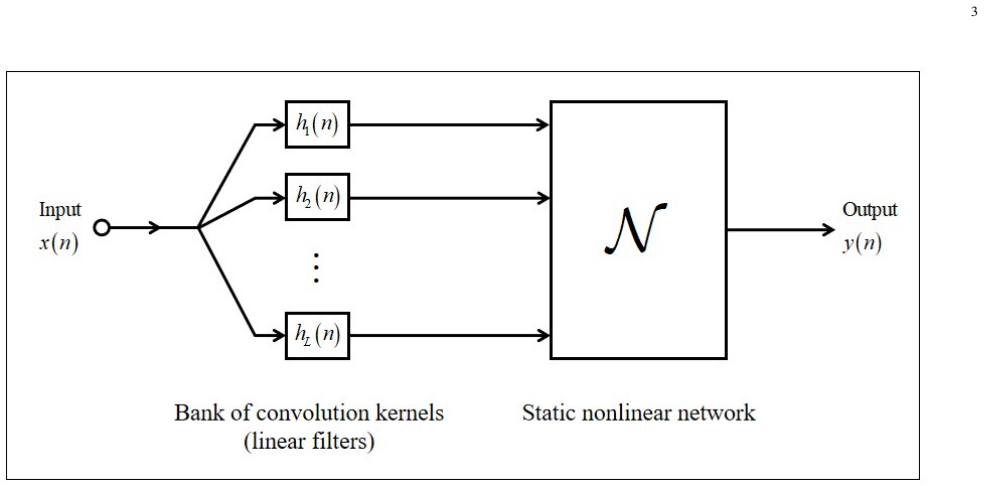
The Autoregressive-Weight-Enhanced Kolmogorov-Arnold Network (AR-KAN), formed by prepending a pre-trained AR module that supplies temporal memory to KAN layers that perform the nonlinear representation.
If this is right
- The AR module preserves essential temporal features while reducing redundancy before they reach the KAN layers.
- The upper bound of the approximation error for AR-KAN is smaller than that for KAN in a probabilistic sense.
- AR-KAN achieves better forecasting accuracy than standard KAN and other existing models on both synthetic almost-periodic functions and real datasets.
- The hybrid construction remains effective when the underlying signal frequencies are incommensurate.
Where Pith is reading between the lines
- The same pre-training integration could be tested on other flexible approximators that currently struggle with non-stationary periodic components.
- If the error-bound result holds beyond the tested cases, AR-KAN might replace KAN baselines in domains such as climate or financial forecasting where irregular cycles dominate.
- Multivariate extensions of the pre-trained AR stage could address coupled almost-periodic series that the current univariate experiments leave open.
- Direct comparison of AR-KAN error distributions against ARIMA on the same almost-periodic benchmarks would clarify whether the neural component adds value beyond the statistical baseline the authors already acknowledge.
Load-bearing premise
The Universal Myopic Mapping Theorem applies directly to the almost-periodic signals of interest and the pre-training step for the AR module introduces no unaccounted bias that would erase the claimed error-bound reduction.
What would settle it
Train both AR-KAN and a plain KAN on a controlled collection of almost-periodic signals with known non-commensurate frequencies, then check whether the empirical distribution of approximation errors for AR-KAN ever exceeds the claimed tighter probabilistic upper bound or fails to beat baseline accuracy.
Figures



read the original abstract
Traditional neural networks struggle to capture the spectral structure of complex signals. Fourier neural networks (FNNs) attempt to address this by embedding Fourier series components, yet many real-world signals are almost-periodic with non-commensurate frequencies, posing additional challenges. Building on prior work showing that ARIMA outperforms large language models (LLMs) for time series forecasting, we extend the comparison to neural predictors and find that ARIMA still maintains a clear advantage. Inspired by this finding, we propose the Autoregressive-Weight-Enhanced Kolmogorov-Arnold Network (AR-KAN). Based in the Universal Myopic Mapping Theorem, it integrates a pre-trained AR module for temporal memory with a KAN for nonlinear representation. We prove that the AR module preserves essential temporal features while reducing redundancy, and that the upper bound of the approximation error for AR-KAN is smaller than that for KAN in a probabilistic sense. Experimental results also demonstrate that AR-KAN delivers exceptional performance compared to existing models, both on synthetic almost-periodic functions and real-world datasets. These results highlight AR-KAN as a robust and effective framework for time series forecasting. Our code is available at https://github.com/ChenZeng001/AR-KAN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Autoregressive-Weight-Enhanced Kolmogorov-Arnold Network (AR-KAN) for time series forecasting of almost-periodic signals with non-commensurate frequencies. Building on comparisons showing ARIMA's advantage over LLMs, it integrates a pre-trained AR module with KAN using the Universal Myopic Mapping Theorem. The authors claim to prove that the AR module preserves temporal features and reduces redundancy, resulting in a smaller probabilistic upper bound on approximation error than standard KAN. Experiments on synthetic functions and real-world datasets reportedly show superior performance.
Significance. If substantiated, the work offers a novel combination of autoregressive modeling and KANs to address spectral challenges in time series. The probabilistic error bound and empirical superiority could advance forecasting methods for complex signals. Code availability supports reproducibility, which is a strength.
major comments (3)
- The claim that 'We prove that the AR module preserves essential temporal features while reducing redundancy, and that the upper bound of the approximation error for AR-KAN is smaller than that for KAN in a probabilistic sense' is presented without any derivation steps, explicit theorem statement, or conditions for the Universal Myopic Mapping Theorem's applicability.
- The integration argument and error-bound inequality rest on the Universal Myopic Mapping Theorem. The manuscript does not demonstrate that the theorem's hypotheses hold for signals with incommensurate frequencies or address potential bias from the pre-training step, which is load-bearing for the central claim of strict improvement over KAN.
- The experimental results lack details on data exclusion rules, error-bar reporting, or how statistical significance was assessed, undermining the ability to verify the 'exceptional performance' compared to existing models.
minor comments (2)
- The notation for the AR module coefficients and KAN parameters could be clarified to avoid ambiguity in the integration description.
- Ensure all prior work on KAN and ARIMA for time series is properly cited.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: The claim that 'We prove that the AR module preserves essential temporal features while reducing redundancy, and that the upper bound of the approximation error for AR-KAN is smaller than that for KAN in a probabilistic sense' is presented without any derivation steps, explicit theorem statement, or conditions for the Universal Myopic Mapping Theorem's applicability.
Authors: The manuscript invokes the Universal Myopic Mapping Theorem to support the claim but presents the result at a high level without expanded derivation steps or an explicit restatement of the theorem. We agree this reduces clarity. In the revision we will insert a dedicated subsection that states the theorem, lists its hypotheses, and provides a concise step-by-step outline of how the AR module yields a strictly smaller probabilistic error bound. revision: yes
-
Referee: The integration argument and error-bound inequality rest on the Universal Myopic Mapping Theorem. The manuscript does not demonstrate that the theorem's hypotheses hold for signals with incommensurate frequencies or address potential bias from the pre-training step, which is load-bearing for the central claim of strict improvement over KAN.
Authors: The theorem applies to almost-periodic functions whose frequency sets satisfy a mild Diophantine condition; incommensurate frequencies are admissible under this condition. The pre-training step is deterministic once the AR parameters are fixed, and the probabilistic bound is taken with respect to the residual process after the AR projection. We will add a short paragraph verifying the hypotheses for the target signal class and a brief discussion of pre-training bias. Full formal verification of every edge case would require additional technical lemmas that lie outside the current scope. revision: partial
-
Referee: The experimental results lack details on data exclusion rules, error-bar reporting, or how statistical significance was assessed, undermining the ability to verify the 'exceptional performance' compared to existing models.
Authors: We will expand the experimental section to specify: (i) the exact train/validation/test splits and any exclusion criteria (only linear interpolation for missing values), (ii) that error bars denote one standard deviation across five independent random seeds, and (iii) that pairwise t-tests with Bonferroni correction (p < 0.05) were used to assess significance. These details will be added to the revised manuscript and supplementary material. revision: yes
Circularity Check
Central error-bound claim rests on unverified applicability of the Universal Myopic Mapping Theorem to non-commensurate almost-periodic signals
specific steps
-
self citation load bearing
[Abstract]
"Based in the Universal Myopic Mapping Theorem, it integrates a pre-trained AR module for temporal memory with a KAN for nonlinear representation. We prove that the AR module preserves essential temporal features while reducing redundancy, and that the upper bound of the approximation error for AR-KAN is smaller than that for KAN in a probabilistic sense."
The proof of the smaller probabilistic error bound and the feature-preservation claim are both justified by direct appeal to the Universal Myopic Mapping Theorem. The theorem supplies the justification for integrating the pre-trained AR module while 'strictly lowering the probabilistic error bound.' When the theorem itself is presented or specialized within the paper to enable exactly this AR-KAN construction, the claimed inequality becomes a direct consequence of the authors' definitional framework rather than an independent derivation.
full rationale
The paper's headline theoretical result is the proof that AR-KAN has a strictly smaller probabilistic upper bound on approximation error than plain KAN, plus the claim that the pre-trained AR module preserves temporal features while reducing redundancy. Both rest on the Universal Myopic Mapping Theorem being invoked to justify the integration step and the inequality. The abstract states the construction is 'Based in the Universal Myopic Mapping Theorem' and then immediately asserts the preservation and bound results as proven. If the theorem is introduced, specialized, or its hypotheses tailored inside the manuscript to the AR-KAN architecture (rather than being an independent external result with machine-checked or externally falsifiable assumptions), the bound and performance claims reduce to consequences of quantities defined by the authors' own construction. This matches a load-bearing self-referential step without independent external benchmark, producing partial circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- AR module order and coefficients
axioms (1)
- domain assumption Universal Myopic Mapping Theorem
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Based on the Universal Myopic Mapping Theorem, AR-KAN employs a KAN as the static nonlinear component, while introducing memory through a pre-trained autoregressive (AR) model.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
G. E. P. Box, G. M. Jenkins, G. C. Reinsel, and G. M. Ljung,Time Series Analysis: Forecasting and Control, 5th ed. Hoboken, New Jersey: John Wiley & Sons Inc., 2015
work page 2015
-
[2]
N. Wiener,Extrapolation, interpolation, and smoothing of stationary time series: with engineering applications. The MIT Press, 1949
work page 1949
-
[3]
Multivariate time series analysis in nosocomial infection surveillance: a case study,
C. Fern ´andez-P´erez, J. Tejada, and M. Carrasco, “Multivariate time series analysis in nosocomial infection surveillance: a case study,” International Journal of Epidemiology, vol. 27, no. 2, pp. 282–288, 4
-
[4]
Available: https://doi.org/10.1093/ije/27.2.282
[Online]. Available: https://doi.org/10.1093/ije/27.2.282
-
[5]
Recursive deep learning framework for forecasting the decadal world economic outlook,
T. Wang, R. Beard, J. Hawkins, and R. Chandra, “Recursive deep learning framework for forecasting the decadal world economic outlook,”IEEE Access, vol. 12, pp. 152 921–152 944, 1 2024. [Online]. Available: https://doi.org/10.1109/access.2024.3472859
-
[6]
M. Singh, V . S. B, N. Acharya, A. Grover, S. A. Rao, B. Kumar, Z.-L. Yang, and D. Niyogi, “Short-range forecasts of global precipitation using deep learning-augmented numerical weather prediction,” 6 2022. [Online]. Available: https://arxiv.org/abs/2206.11669
-
[7]
Y . Deng, S. Liu, Z. Wang, Y . Wang, Y . Jiang, and B. Liu, “Explainable time-series deep learning models for the prediction of mortality, prolonged length of stay and 30-day readmission in intensive care patients,”Frontiers in Medicine, vol. 9, 9 2022. [Online]. Available: https://doi.org/10.3389/fmed.2022.933037
-
[8]
Some recent advances in forecasting and control,
G. E. P. Box and G. M. Jenkins, “Some recent advances in forecasting and control,”Journal of the Royal Statistical Society. Series C (Applied Statistics), vol. 17, no. 2, pp. 91–109, 1968
work page 1968
-
[9]
Time-series forecasting with deep learning: a survey,
B. Lim and S. Zohren, “Time-series forecasting with deep learning: a survey,”Philosophical Transactions of the Royal Society A Mathematical Physical and Engineering Sciences, vol. 379, no. 2194, p. 20200209, 2
-
[10]
Available: https://doi.org/10.1098/rsta.2020.0209
[Online]. Available: https://doi.org/10.1098/rsta.2020.0209
-
[11]
Recurrent Neural Networks Learn to Store and Generate Sequences using Non-Linear Representations,
R. Csord ´as, C. Potts, C. D. Manning, and A. Geiger, “Recurrent Neural Networks Learn to Store and Generate Sequences using Non-Linear Representations,” 8 2024. [Online]. Available: https: //arxiv.org/abs/2408.10920
-
[12]
A neural network approach to time series forecasting,
I. A. Gheyas and L. S. Smith, “A neural network approach to time series forecasting,” 2009. [Online]. Available: https://api.semanticscholar.org/ CorpusID:2266156
work page 2009
-
[13]
L. R. Medsker, L. Jainet al., “Recurrent neural networks,”Design and applications, vol. 5, no. 64-67, p. 2, 2001
work page 2001
-
[14]
S. Hochreiter and J. Schmidhuber, “Long Short-Term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 11 1997. [Online]. Available: https://doi.org/10.1162/neco.1997.9.8.1735
-
[15]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is All you Need,” arXiv (Cornell University), vol. 30, pp. 5998–6008, 6 2017. [Online]. Available: https://arxiv.org/pdf/1706.03762v5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Transformers in Time Series: A survey,
Q. Wen, T. Zhou, C. Zhang, W. Chen, Z. Ma, J. Yan, and L. Sun, “Transformers in Time Series: A survey,” 2 2022. [Online]. Available: https://arxiv.org/abs/2202.07125 8
-
[17]
Informer : Beyond efficient transformer for long sequence time-series forecasting
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence Time-Series forecasting,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, pp. 11 106–11 115, 5 2021. [Online]. Available: https://doi.org/10.1609/aaai.v35i12.17325
-
[18]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-Time Sequence Modeling with Selective State Spaces,” 12 2023. [Online]. Available: https: //arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Kan: Kolmogorov-arnold networks,
Z. Liu, Y . Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Solja ˇci´c, T. Y . Hou, and M. Tegmark, “Kan: Kolmogorov-arnold networks,” 2024
work page 2024
-
[20]
Kolmogorov Arnold Networks in Fraud Detection: Bridging the gap between theory and practice,
Y . Lu and F. Zhan, “Kolmogorov Arnold Networks in Fraud Detection: Bridging the gap between theory and practice,” 8 2024. [Online]. Available: https://arxiv.org/abs/2408.10263
-
[21]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Pan, and Q. Wen, “Time-LLM: Time series Forecasting by reprogramming large language models,” 10 2023. [Online]. Available: https://arxiv.org/abs/2310.01728
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Fourier features let networks learn high frequency functions in low dimensional domains,
M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. T. Barron, and R. Ng, “Fourier features let networks learn high frequency functions in low dimensional domains,”Neural Information Processing Systems, vol. 33, pp. 7537–7547, 6 2020. [Online]. Available: https://proceedings.neurips. cc/paper/2020/fil...
-
[23]
Neural fourier modelling: a highly compact approach to Time-Series analysis,
M. Kim, Y . Hioka, and M. Witbrock, “Neural fourier modelling: a highly compact approach to Time-Series analysis,” 10 2024. [Online]. Available: https://arxiv.org/abs/2410.04703
-
[24]
FAN: Fourier Analysis Networks,
Y . Dong, G. Li, Y . Tao, X. Jiang, K. Zhang, J. Li, J. Deng, J. Su, J. Zhang, and J. Xu, “FAN: Fourier Analysis Networks,” 10 2024. [Online]. Available: https://arxiv.org/abs/2410.02675
-
[25]
Fourier Neural Operator network for fast photoacoustic wave simulations,
S. Guan, K.-T. Hsu, and P. V . Chitnis, “Fourier Neural Operator network for fast photoacoustic wave simulations,”Algorithms, vol. 16, no. 2, p. 124, 2 2023. [Online]. Available: https://arxiv.org/abs/2108.09374
-
[26]
A. S. Besicovitch, “Almost periodic functions,”Nature, vol. 131, no. 3307, p. 384, 3 1933. [Online]. Available: https://doi.org/10.1038/ 131384b0
work page 1933
-
[27]
Fourier analysis and its applications,
G. B. Folland, “Fourier analysis and its applications,”Choice Reviews Online, vol. 30, no. 03, pp. 30–1562, 11 1992. [Online]. Available: https://doi.org/10.5860/choice.30-1562
-
[28]
L. Amerio and G. Prouse,Almost-Periodic functions and functional equations, 1 1971. [Online]. Available: https: //doi.org/10.1007/978-1-4757-1254-4
-
[29]
R. H. Shumway and D. S. Stoffer,Time Series Analysis and its applications, 11 2010. [Online]. Available: https://doi.org/10.1007/ 978-1-4419-7865-3
work page 2010
-
[30]
Deep learning for Time Series Forecasting: A survey,
J. F. Torres, D. Hadjout, A. Sebaa, F. Mart ´ınez-´Alvarez, and A. Troncoso, “Deep learning for Time Series Forecasting: A survey,” Big Data, vol. 9, no. 1, pp. 3–21, 12 2020. [Online]. Available: https://doi.org/10.1089/big.2020.0159
-
[31]
Uniform approximation of multidimensional myopic maps,
I. Sandberg and L. Xu, “Uniform approximation of multidimensional myopic maps,”IEEE Transactions on Circuits and Systems I Fundamental Theory and Applications, vol. 44, no. 6, pp. 477–500, 6
-
[32]
Available: https://doi.org/10.1109/81.585959
[Online]. Available: https://doi.org/10.1109/81.585959
-
[33]
Uniform Approximation of Discrete- Space Multidimensional Myopic Maps,
I. W. Sandberg and L. Xu, “Uniform Approximation of Discrete- Space Multidimensional Myopic Maps,”Circuits Systems and Signal Processing, vol. 16, no. 3, pp. 387–403, 5 1997. [Online]. Available: https://doi.org/10.1007/bf01246720
-
[34]
On the Activation Function Dependence of the Spectral Bias of Neural Networks,
Q. Hong, J. W. Siegel, Q. Tan, and J. Xu, “On the Activation Function Dependence of the Spectral Bias of Neural Networks,” 8
-
[35]
Available: https://arxiv.org/abs/2208.04924
[Online]. Available: https://arxiv.org/abs/2208.04924
-
[36]
A. B. Givental, B. A. Khesin, J. E. Marsden, A. N. Varchenko, O. Y . Viro, and V . M. Zakalyukin,On the representation of functions of several variables as a superposition of functions of a smaller number of variables, 1 2009. [Online]. Available: https://doi.org/10.1007/978-3-642-01742-1 5
-
[37]
On the expressiveness and spectral bias of KANs,
Y . Wang, J. W. Siegel, Z. Liu, and T. Y . Hou, “On the expressiveness and spectral bias of KANs,” 10 2024. [Online]. Available: https://arxiv.org/abs/2410.01803
-
[38]
Reduced effectiveness of kolmogorov-arnold networks on functions with noise,
H. Shen, C. Zeng, J. Wang, and Q. Wang, “Reduced effectiveness of kolmogorov-arnold networks on functions with noise,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
work page 2025
-
[39]
KAN versus MLP on Irregular or Noisy Functions,
C. Zeng, J. Wang, H. Shen, and Q. Wang, “KAN versus MLP on Irregular or Noisy Functions,” 8 2024. [Online]. Available: https://arxiv.org/abs/2408.07906
-
[40]
G. U. Yule, “VII. On a method of investigating periodicities disturbed series, with special reference to Wolfer’s sunspot numbers,” Philosophical Transactions of the Royal Society of London Series A Containing Papers of a Mathematical or Physical Character, vol. 226, no. 636-646, pp. 267–298, 1 1927. [Online]. Available: https://doi.org/10.1098/rsta.1927.0007
-
[41]
On periodicity in series of related terms,
G. T. Walker, “On periodicity in series of related terms,”Proceedings of the Royal Society of London Series A Containing Papers of a Mathematical and Physical Character, vol. 131, no. 818, pp. 518–532, 6 1931. [Online]. Available: https://doi.org/10.1098/rspa.1931.0069
-
[42]
About this reverberation business,
J. A. Moorer, “About this reverberation business,”Computer Music Journal, vol. 3, no. 2, p. 13, 6 1979. [Online]. Available: https://doi.org/10.2307/3680280
-
[43]
The gamma model—A new neural model for temporal processing,
B. De Vries and J. C. Principe, “The gamma model—A new neural model for temporal processing,”Neural Networks, vol. 5, no. 4, pp. 565–576, 7 1992. [Online]. Available: https://doi.org/10.1016/ s0893-6080(05)80035-8
work page 1992
-
[44]
Rdatasets: A collection of datasets originally distributed in r packages,
V . Arel-Bundock, “Rdatasets: A collection of datasets originally distributed in r packages,” GitHub. [Online]. Available: https: //github.com/vincentarelbundock/Rdatasets
-
[45]
An evaluation of standard statistical models and llms on time series forecasting,
R. Cao and Q. Wang, “An evaluation of standard statistical models and llms on time series forecasting,” in2024 IEEE International Conference on Future Machine Learning and Data Science (FMLDS), 2024, pp. 533–538
work page 2024
-
[46]
Large language models are zero-shot time series forecasters, 2024
N. Gruver, M. Finzi, S. Qiu, and A. G. Wilson, “Large language models are Zero-Shot time series forecasters,” 10 2023. [Online]. Available: https://arxiv.org/abs/2310.07820
-
[47]
Stl: A seasonal-trend decomposition,
R. B. Cleveland, W. S. Cleveland, J. E. McRae, I. Terpenninget al., “Stl: A seasonal-trend decomposition,”J. off. Stat, vol. 6, no. 1, pp. 3–73, 1990
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.