LITcoder: A General-Purpose Library for Building and Comparing Encoding Models
Pith reviewed 2026-05-18 18:25 UTC · model grok-4.3
The pith
LITcoder supplies modular tools to align continuous stimuli like stories with fMRI scans and to build and test encoding models that predict brain activity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
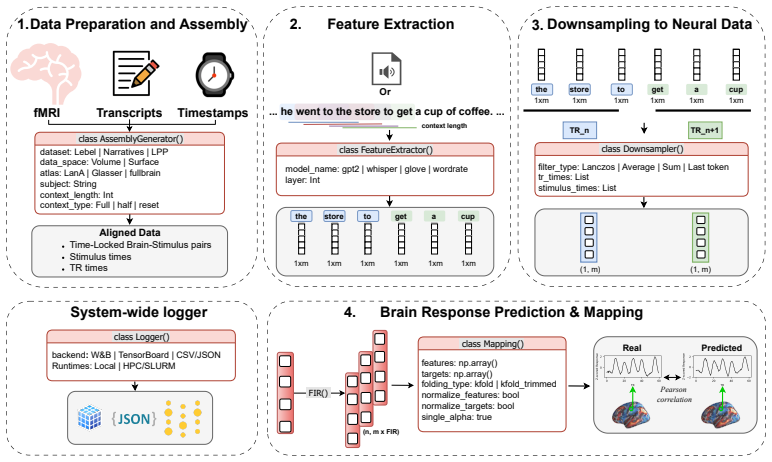
LITcoder implements a flexible backend pipeline that lets users select brain datasets and regions, choose stimulus features including neural-net representations and controls such as word rate, apply different downsampling methods, and incorporate logging plus experiment tracking. When applied to the LeBel et al. (2023), Narratives, and Little Prince datasets, the pipeline shows that accounting for every token within a TR scan rather than only the last token, modeling hemodynamic response lag, using train-test splits that avoid information leakage, and correcting for head motion each raise the predictive accuracy of the resulting encoding models.
What carries the argument
The modular pipeline that composes alignment of continuous stimuli to brain time series, feature transformation, feature-to-voxel mapping, and held-out evaluation while allowing easy swapping of datasets, regions, and design choices.
If this is right
- Users can swap stimulus features or brain regions and immediately compare predictive performance without rewriting alignment or evaluation code.
- Incorporating hemodynamic lag and motion correction as defaults raises the upper bound on how accurately language stimuli can be mapped to fMRI responses.
- Leakage-minimizing splits become standard practice, reducing over-optimistic performance estimates in future studies.
- Built-in logging and W&B integration make it straightforward to reproduce and share exact model configurations across research groups.
Where Pith is reading between the lines
- The library could serve as a shared reference point that reduces hidden methodological differences when multiple labs report encoding results on the same public datasets.
- Extending the same modular structure to new stimulus modalities or non-fMRI modalities would test whether the same design choices remain critical outside story listening.
- If the pipeline is adopted widely, aggregate meta-analyses of encoding performance across papers could become feasible for the first time.
Load-bearing premise
The particular design decisions coded into the library, such as full token accounting and hemodynamic lag modeling, are the main factors that control how well an encoding model predicts brain data.
What would settle it
A head-to-head test on the same three datasets that finds encoding models built without full token accounting or lag modeling reach equal or higher prediction accuracy than those built with the library's recommended choices.
Figures





read the original abstract
We introduce LITcoder, an open-source library for building and benchmarking neural encoding models. Designed as a flexible backend, LITcoder provides standardized tools for aligning continuous stimuli (e.g., text and speech) with brain data, transforming stimuli into representational features, mapping those features onto brain data, and evaluating the predictive performance of the resulting model on held-out data. The library implements a modular pipeline covering a wide array of methodological design choices, so researchers can easily compose, compare, and extend encoding models without reinventing core infrastructure. Such choices include brain datasets, brain regions, stimulus feature (both neural-net-based and control, such as word rate), downsampling approaches, and many others. In addition, the library provides built-in logging, plotting, and seamless integration with experiment tracking platforms such as Weights & Biases (W&B). We demonstrate the scalability and versatility of our framework by fitting a range of encoding models to three story listening datasets: LeBel et al. (2023), Narratives, and Little Prince. We also explore the methodological choices critical for building encoding models for continuous fMRI data, illustrating the importance of accounting for all tokens in a TR scan (as opposed to just taking the last one, even when contextualized), incorporating hemodynamic lag effects, using train-test splits that minimize information leakage, and accounting for head motion effects on encoding model predictivity. Overall, LITcoder lowers technical barriers to encoding model implementation, facilitates systematic comparisons across models and datasets, fosters methodological rigor, and accelerates the development of high-quality high-performance predictive models of brain activity. Project page: https://litcoder-brain.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LITcoder, an open-source library for building and benchmarking neural encoding models. It provides standardized modular tools for aligning continuous stimuli (text and speech) with brain data, transforming stimuli into representational features (neural-net-based and controls such as word rate), mapping features onto brain activity, and evaluating predictive performance on held-out data. The library supports choices including brain datasets, regions, downsampling approaches, and others, with built-in logging, plotting, and Weights & Biases integration. The authors demonstrate scalability by fitting models to three story-listening fMRI datasets (LeBel et al. 2023, Narratives, Little Prince) and explore methodological choices, claiming to illustrate the importance of full token accounting per TR, hemodynamic lag modeling, leakage-minimizing splits, and motion correction.
Significance. If the library performs as described and the methodological claims are quantitatively supported, LITcoder could meaningfully lower implementation barriers and promote standardized, reproducible practices in computational neuroscience for stimulus-brain alignment. The modular design and experiment-tracking integration are practical strengths that could facilitate systematic model comparisons across datasets. Open-source release with a project page further supports potential community adoption and extension.
major comments (1)
- [Abstract and demonstrations on three datasets] Abstract and demonstrations section: The manuscript states that it illustrates the importance of accounting for all tokens in a TR scan (as opposed to just the last one), incorporating hemodynamic lag effects, using train-test splits that minimize information leakage, and accounting for head motion effects on encoding model predictivity. However, no quantitative performance tables, ablation studies, effect sizes, statistical tests, or cross-variant comparisons are reported to support these illustrations. This leaves the central assertion that these specific choices are critical determinants of model quality unverified and weakens the recommendation of the library as a high-quality standardized backend.
minor comments (2)
- The manuscript could include a table or structured list summarizing all available pipeline components, default settings, and configurable options to improve clarity for potential users.
- Ensure explicit statements on data and code availability, including direct links to the GitHub repository, installation instructions, and any required dependencies beyond the project page URL.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for recognizing the potential of LITcoder to promote standardized practices in the field. We agree with the assessment that the demonstrations would be strengthened by additional quantitative evidence and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and demonstrations on three datasets] Abstract and demonstrations section: The manuscript states that it illustrates the importance of accounting for all tokens in a TR scan (as opposed to just the last one), incorporating hemodynamic lag effects, using train-test splits that minimize information leakage, and accounting for head motion effects on encoding model predictivity. However, no quantitative performance tables, ablation studies, effect sizes, statistical tests, or cross-variant comparisons are reported to support these illustrations. This leaves the central assertion that these specific choices are critical determinants of model quality unverified and weakens the recommendation of the library as a high-quality standardized backend.
Authors: We thank the referee for this important point. The current version of the manuscript uses the three-dataset demonstrations to showcase how LITcoder enables researchers to easily implement and compare these methodological choices, rather than serving as a full empirical study validating each choice's necessity. While the importance of these practices is supported by existing literature in the field, we recognize that the manuscript would benefit from direct quantitative support. In the revised manuscript, we will expand the demonstrations section to include quantitative performance comparisons, such as tables showing encoding model predictivity (e.g., Pearson correlation or R^2) for variants with and without full token accounting per TR, hemodynamic lag modeling, different split strategies, and motion correction. We will also report effect sizes and conduct statistical tests to assess the significance of differences where feasible. This revision will better substantiate the claims and strengthen the paper's recommendation of the library. revision: yes
Circularity Check
Tool-release paper with empirical demonstrations but no mathematical derivation or fitted prediction exhibits no circularity.
full rationale
The manuscript introduces LITcoder as a modular software library for encoding models and illustrates its use on three story-listening fMRI datasets. It describes pipeline components (token accounting per TR, hemodynamic lag, leakage-minimizing splits, motion correction) and reports that these choices affect predictivity, but presents no equations, first-principles derivations, or statistical predictions whose outputs are forced by their own inputs. No self-citation chain is invoked to justify a uniqueness theorem or ansatz; the value of the library rests on its implementation and the reproducibility of its demonstrations rather than on any tautological reduction. The central claims are therefore self-contained and independent of the circularity patterns enumerated in the analysis criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Daniel L. K. Yamins, Ha Hong, Charles F. Cadieu, Ethan A. Solomon, Darren Seibert, and James J. DiCarlo. Performance-optimized hierarchical models predict neural responses in higher visual cortex.Proceedings of the National Academy of Sciences, 111(23):8619–8624, June
-
[2]
URL https://www.pnas.org/doi/10.1073/pnas
doi: 10.1073/pnas.1403112111. URL https://www.pnas.org/doi/10.1073/pnas. 1403112111. Publisher: Proceedings of the National Academy of Sciences
-
[3]
U. Guclu and M. A. J. Van Gerven. Deep Neural Networks Reveal a Gradient in the Complexity of Neural Representations across the Ventral Stream.Journal of Neuroscience, 35(27):10005– 10014, July 2015. ISSN 0270-6474, 1529-2401. doi: 10.1523/JNEUROSCI.5023-14.2015. URL https://www.jneurosci.org/lookup/doi/10.1523/JNEUROSCI.5023-14.2015
-
[4]
Apurva Ratan Murty, Pouya Bashivan, Alex Abate, James J
N. Apurva Ratan Murty, Pouya Bashivan, Alex Abate, James J. DiCarlo, and Nancy Kanwisher. Computational models of category-selective brain regions enable high-throughput tests of selec- tivity.Nature Communications, 12(1):5540, September 2021. ISSN 2041-1723. doi: 10.1038/ s41467-021-25409-6. URL https://www.nature.com/articles/s41467-021-25409-6 . Publis...
work page 2021
-
[5]
Kendrick N. Kay, Thomas Naselaris, Ryan J. Prenger, and Jack L. Gallant. Identifying natural images from human brain activity.Nature, 452(7185):352–355, March 2008. ISSN 1476-4687. doi: 10.1038/nature06713. URL https://www.nature.com/articles/nature06713. Pub- lisher: Nature Publishing Group
-
[6]
Seyed-Mahdi Khaligh-Razavi and Nikolaus Kriegeskorte. Deep Supervised, but Not Un- supervised, Models May Explain IT Cortical Representation.PLOS Computational Bi- ology, 10(11):e1003915, November 2014. ISSN 1553-7358. doi: 10.1371/journal.pcbi. 1003915. URL https://journals.plos.org/ploscompbiol/article?id=10.1371/ journal.pcbi.1003915. Publisher: Public...
-
[7]
Hosseini, Nancy Kanwisher, Joshua B
Martin Schrimpf, Idan Asher Blank, Greta Tuckute, Carina Kauf, Eghbal A. Hosseini, Nancy Kanwisher, Joshua B. Tenenbaum, and Evelina Fedorenko. The neural architecture of lan- guage: Integrative modeling converges on predictive processing.Proceedings of the Na- tional Academy of Sciences, 118(45):e2105646118, November 2021. ISSN 0027-8424, 1091-
work page 2021
-
[8]
and Kanwisher, Nancy and Tenenbaum, Joshua B
doi: 10.1073/pnas.2105646118. URL https://pnas.org/doi/full/10.1073/pnas. 2105646118
-
[9]
Alexander G. Huth, Wendy A. de Heer, Thomas L. Griffiths, Frédéric E. Theunissen, and Jack L. Gallant. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600):453–458, April 2016. ISSN 0028-0836. doi: 10.1038/nature17637. URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4852309/. 9
- [10]
-
[11]
Charlotte Caucheteux and Jean-Rémi King. Brains and algorithms partially converge in nat- ural language processing.Communications Biology, 5(1):1–10, February 2022. ISSN 2399-
work page 2022
-
[12]
doi: 10.1038/s42003-022-03036-1
doi: 10.1038/s42003-022-03036-1. URL https://www.nature.com/articles/ s42003-022-03036-1. Publisher: Nature Publishing Group
-
[13]
Mariya Toneva and Leila Wehbe. Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain), November 2019. URL http: //arxiv.org/abs/1905.11833. arXiv:1905.11833 [cs]
-
[14]
Refael Tikochinski, Ariel Goldstein, Yoav Meiri, Uri Hasson, and Roi Reichart. Incremental accumulation of linguistic context in artificial and biological neural networks.Nature Commu- nications, 16(1):803, January 2025. ISSN 2041-1723. doi: 10.1038/s41467-025-56162-9. URL https://www.nature.com/articles/s41467-025-56162-9 . Publisher: Nature Publish- ing Group
-
[15]
From Language to Cognition: How LLMs Outgrow the Human Language Network, March 2025
Badr AlKhamissi, Greta Tuckute, Yingtian Tang, Taha Binhuraib, Antoine Bosselut, and Martin Schrimpf. From Language to Cognition: How LLMs Outgrow the Human Language Network, March 2025. URLhttp://arxiv.org/abs/2503.01830. arXiv:2503.01830 [cs]
-
[16]
Executable science: Research software engineering practices for replicating neuroscience findings
Gabriel Kressin Palacios, Zhuoyang Li, and Kristijan Armeni. Executable science: Research software engineering practices for replicating neuroscience findings. InProceedings of the ACM Conference on Reproducibility and Replicability (ACM REP ’25), pages 1–14, Vancouver, BC, Canada, 2025. Association for Computing Machinery. doi: 10.1145/3736731.3746147. U...
-
[17]
Nima Hadidi, Ebrahim Feghhi, Bryan H. Song, Idan A. Blank, and Jonathan C. Kao. Illusions of Alignment Between Large Language Models and Brains Emerge From Fragile Methods and Overlooked Confounds, March 2025. URL https://www.biorxiv.org/content/10. 1101/2025.03.09.642245v1. Pages: 2025.03.09.642245 Section: Contradictory Results
work page 2025
-
[18]
Majaj, Rishi Rajalingham, Elias B
Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Franziska Geiger, Kailyn Schmidt, Daniel L. K. Yamins, and James J. DiCarlo. Brain-Score: Which Artificial Neural Network for Object Recognition is most Brain-Like?, September 2018. URL http://biorxiv.org/lookup/ ...
-
[19]
Joint processing of linguistic properties in brains and language models, November 2023
Subba Reddy Oota, Manish Gupta, and Mariya Toneva. Joint processing of linguistic properties in brains and language models, November 2023. URLhttp://arxiv.org/abs/2212.08094. arXiv:2212.08094 [cs]
-
[20]
Idan Blank, Nancy Kanwisher, and Evelina Fedorenko. A functional dissociation between language and multiple-demand systems revealed in patterns of BOLD signal fluctuations. Journal of Neurophysiology, 112(5):1105–1118, September 2014. ISSN 0022-3077, 1522-
work page 2014
-
[21]
URL https://www.physiology.org/doi/10.1152/ jn.00884.2013
doi: 10.1152/jn.00884.2013. URL https://www.physiology.org/doi/10.1152/ jn.00884.2013
-
[22]
Gershman, Nancy Kanwisher, Matthew Botvinick, and Evelina Fedorenko
Francisco Pereira, Bin Lou, Brianna Pritchett, Samuel Ritter, Samuel J. Gershman, Nancy Kanwisher, Matthew Botvinick, and Evelina Fedorenko. Toward a universal decoder of linguistic meaning from brain activation.Nature Communications, 9(1):963, March 2018. ISSN 2041-
work page 2018
-
[23]
URL https://www.nature.com/articles/ s41467-018-03068-4
doi: 10.1038/s41467-018-03068-4. URL https://www.nature.com/articles/ s41467-018-03068-4. Publisher: Nature Publishing Group
-
[24]
Charlotte Caucheteux, Alexandre Gramfort, and Jean-Rémi King. Evidence of a predictive coding hierarchy in the human brain listening to speech.Nature Human Behaviour, 7(3): 430–441, March 2023. ISSN 2397-3374. doi: 10.1038/s41562-022-01516-2. URL https:// www.nature.com/articles/s41562-022-01516-2. Publisher: Nature Publishing Group. 10
-
[25]
Matthew F Glasser, Timothy S Coalson, Emma C Robinson, Carl D Hacker, John Harwell, Essa Yacoub, Kamil Ugurbil, Jesper Andersson, Christian F Beckmann, Mark Jenkinson, Stephen M Smith, and David C Van Essen. A multi-modal parcellation of human cerebral cortex.Nature, 536(7615):171–178, August 2016. ISSN 0028-0836. doi: 10.1038/nature18933. URLhttps://www....
-
[26]
Incorporating Context into Language Encoding Models for fMRI
Shailee Jain and Alexander Huth. Incorporating Context into Language Encoding Models for fMRI. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper_files/paper/2018/hash/ f471223d1a1614b58a7dc45c9d01df19-Abstract.html
work page 2018
-
[27]
Alexander G. Huth, Shinji Nishimoto, An T. Vu, and Jack L. Gallant. A Continuous Semantic Space Describes the Representation of Thousands of Object and Action Categories across the Human Brain.Neuron, 76(6):1210–1224, December 2012. ISSN 0896-6273. doi: 10.1016/j. neuron.2012.10.014. URL https://www.cell.com/neuron/abstract/S0896-6273(12) 00934-8. Publish...
work page doi:10.1016/j 2012
-
[28]
Machine learning for neuroimaging with scikit-learn.Frontiers in Neuroinformatics, 8, February 2014
Alexandre Abraham, Fabian Pedregosa, Michael Eickenberg, Philippe Gervais, Andreas Mueller, Jean Kossaifi, Alexandre Gramfort, Bertrand Thirion, and Gael Varoquaux. Machine learning for neuroimaging with scikit-learn.Frontiers in Neuroinformatics, 8, February 2014. ISSN 1662-
work page 2014
-
[29]
URL https://www.frontiersin.org/journals/ neuroinformatics/articles/10.3389/fninf.2014.00014/full
doi: 10.3389/fninf.2014.00014. URL https://www.frontiersin.org/journals/ neuroinformatics/articles/10.3389/fninf.2014.00014/full. Publisher: Frontiers
-
[30]
Ahmad Samara, Zaid Zada, Tamara Vanderwal, Uri Hasson, and Samuel A. Nastase. Cortical language areas are coupled via a soft hierarchy of model-based linguistic features.bioRxiv: The Preprint Server for Biology, page 2025.06.02.657491, June 2025. ISSN 2692-8205. doi: 10.1101/2025.06.02.657491
-
[31]
Benjamin Lipkin, Greta Tuckute, Josef Affourtit, Hannah Small, Zachary Mineroff, Hope Kean, Olessia Jouravlev, Lara Rakocevic, Brianna Pritchett, Matthew Siegelman, Caitlyn Hoeflin, Alvincé Pongos, Idan A. Blank, Melissa Kline Struhl, Anna Ivanova, Steven Shannon, Aalok Sathe, Malte Hoffmann, Alfonso Nieto-Castañón, and Evelina Fedorenko. Probabilistic at...
-
[32]
Samuel A. Nastase, Yun-Fei Liu, Hanna Hillman, Asieh Zadbood, Liat Hasenfratz, Neggin Keshavarzian, Janice Chen, Christopher J. Honey, Yaara Yeshurun, Mor Regev, Mai Nguyen, Claire H. C. Chang, Christopher Baldassano, Olga Lositsky, Erez Simony, Michael A. Chow, Yuan Chang Leong, Paula P. Brooks, Emily Micciche, Gina Choe, Ariel Goldstein, Tamara Vanderwa...
-
[33]
Jixing Li, Shohini Bhattasali, Shulin Zhang, Berta Franzluebbers, Wen-Ming Luh, R. Nathan Spreng, Jonathan R. Brennan, Yiming Yang, Christophe Pallier, and John Hale. Le Petit Prince multilingual naturalistic fMRI corpus.Scientific Data, 9(1):530, August 2022. ISSN 2052-
work page 2022
-
[34]
URL https://www.nature.com/articles/ s41597-022-01625-7
doi: 10.1038/s41597-022-01625-7. URL https://www.nature.com/articles/ s41597-022-01625-7. Publisher: Nature Publishing Group
-
[35]
Amanda LeBel, Lauren Wagner, Shailee Jain, Aneesh Adhikari-Desai, Bhavin Gupta, Allyson Morgenthal, Jerry Tang, Lixiang Xu, and Alexander G. Huth. A natural language fMRI dataset for voxelwise encoding models.Scientific Data, 10(1):555, August 2023. ISSN 2052-
work page 2023
-
[36]
doi: 10.1038/s41597-023-02437-z
doi: 10.1038/s41597-023-02437-z. URL https://www.nature.com/articles/ s41597-023-02437-z. Publisher: Nature Publishing Group
-
[37]
Oscar Esteban, Christopher J. Markiewicz, Ross W. Blair, Craig A. Moodie, A. Ilkay Isik, Asier Erramuzpe, James D. Kent, Mathias Goncalves, Elizabeth DuPre, Madeleine Snyder, Hiroyuki Oya, Satrajit S. Ghosh, Jessey Wright, Joke Durnez, Russell A. Poldrack, and Krzysztof J. Gorgolewski. fMRIPrep: a robust preprocessing pipeline for functional MRI.Nature Me...
-
[38]
Jonathan D Power, Kelly A Barnes, Abraham Z Snyder, Bradley L Schlaggar, and Steven E Petersen. Spurious but systematic correlations in functional connectivity MRI networks arise from subject motion.Neuroimage, 59(3):2142–2154, February 2012. ISSN 1053-8119. doi: 10. 1016/j.neuroimage.2011.10.018. URL https://www.ncbi.nlm.nih.gov/pmc/articles/ PMC3254728/...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.