DualTrack: Sensorless 3D Ultrasound needs Local and Global Context
Pith reviewed 2026-05-18 17:43 UTC · model grok-4.3
The pith
DualTrack uses separate encoders for local motion and global anatomy to improve sensorless 3D ultrasound reconstruction accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
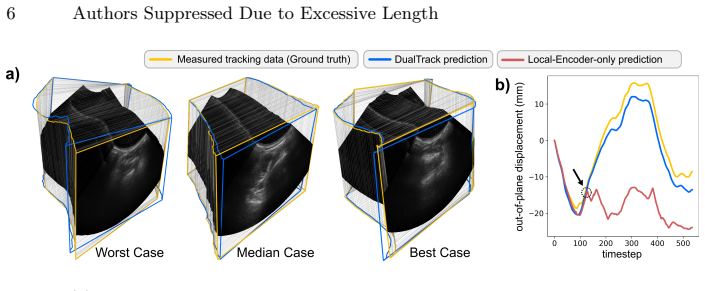
The authors establish that a decoupled dual-encoder architecture, with specialized local spatiotemporal processing and global backbone plus temporal attention, followed by lightweight fusion, enables better capture of complementary scales of information, resulting in state-of-the-art trajectory estimation and globally consistent 3D reconstructions from 2D ultrasound sequences.
What carries the argument
The DualTrack dual-encoder architecture that processes local fine-grained features via dense spatiotemporal convolutions and global high-level anatomical features via an image backbone with temporal attention layers, integrated by a lightweight fusion module for trajectory prediction.
If this is right
- Reconstruction error averages below 5 mm on large public benchmarks.
- Produces globally consistent volumes without significant drift over extended scans.
- Outperforms previous sensorless methods that used single or coupled feature streams.
- The approach supports plugging in different backbones, including foundation models, for the global encoder.
Where Pith is reading between the lines
- This design choice may help in other sequential imaging problems where both short-range details and long-range structure are important.
- Testing the method on data from different ultrasound machines or body regions could reveal if the decoupling generalizes beyond the training distribution.
- If the fusion step proves insufficient for very complex motions, adding more sophisticated integration could further reduce inconsistencies.
Load-bearing premise
The benefits of keeping local and global feature streams separate and fusing them lightly will outweigh the potential advantages of fully joint optimization across both scales.
What would settle it
Run DualTrack and a comparable single-encoder model on a held-out set of long clinical ultrasound sequences and check if the dual version maintains lower cumulative trajectory error and better volume consistency; absence of such improvement would falsify the core benefit of decoupling.
Figures


read the original abstract
Three-dimensional ultrasound (US) offers many clinical advantages over conventional 2D imaging, yet its widespread adoption is limited by the cost and complexity of traditional 3D systems. Sensorless 3D US, which uses deep learning to estimate a 3D probe trajectory from a sequence of 2D US images, is a promising alternative. Local features, such as speckle patterns, can help predict frame-to-frame motion, while global features, such as coarse shapes and anatomical structures, can situate the scan relative to anatomy and help predict its general shape. In prior approaches, global features are either ignored or tightly coupled with local feature extraction, restricting the ability to robustly model these two complementary aspects. We propose DualTrack, a novel dual-encoder architecture that leverages decoupled local and global encoders specialized for their respective scales of feature extraction. The local encoder uses dense spatiotemporal convolutions to capture fine-grained features, while the global encoder utilizes an image backbone (e.g., a 2D CNN or foundation model) and temporal attention layers to embed high-level anatomical features and long-range dependencies. A lightweight fusion module then combines these features to estimate the trajectory. Experimental results on a large public benchmark show that DualTrack achieves state-of-the-art accuracy and globally consistent 3D reconstructions, outperforming previous methods and yielding an average reconstruction error below 5 mm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DualTrack, a dual-encoder architecture for sensorless 3D ultrasound reconstruction from 2D image sequences. It decouples a local encoder (dense spatiotemporal convolutions for speckle-based frame-to-frame motion) from a global encoder (2D CNN or foundation model backbone plus temporal attention for anatomical context and long-range dependencies), then combines them with a lightweight fusion module to regress the 6-DoF probe trajectory. Experiments on a large public benchmark are reported to yield state-of-the-art accuracy with average reconstruction error below 5 mm and globally consistent 3D volumes, outperforming prior methods.
Significance. If the empirical results hold, the explicit separation of local and global feature streams addresses a clear limitation in earlier tightly coupled designs and could improve robustness for clinical sensorless 3D US. The timely use of foundation models in the global branch is a positive design choice that aligns with broader trends in computer vision.
major comments (3)
- [Experiments] Experiments section: the central SOTA claim with sub-5 mm average error is presented without quantitative ablation results isolating the contribution of the decoupled local encoder, global encoder, or the lightweight fusion module. This makes it impossible to verify that the architectural decoupling (rather than other implementation details) drives the reported gains over prior coupled methods.
- [Section 4] Section 4 (results): no error bars, standard deviations across sequences, or statistical significance tests are supplied for the reconstruction errors on the public benchmark. This weakens the claim of consistent outperformance and global consistency, particularly given the known variability of clinical ultrasound data.
- [Method] Method (fusion module description): the paper provides no explicit analysis or out-of-distribution experiments showing that the lightweight fusion reliably reconciles the two decoupled streams without introducing drift when anatomical context changes. This is load-bearing for the global-consistency claim, as prior coupled architectures avoided this risk by construction.
minor comments (2)
- [Abstract] Abstract: the phrase 'a large public benchmark' is used without naming the dataset or supplying basic statistics (number of sequences, patients, or acquisition parameters), which would help readers assess the scope of the evaluation.
- [Method] Notation: the parameterization of the 6-DoF trajectory (e.g., whether rotation is represented as quaternions, Euler angles, or axis-angle) is not introduced until late in the method section; an early definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify key areas where additional analysis and statistical reporting can strengthen the presentation of DualTrack's contributions. We address each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central SOTA claim with sub-5 mm average error is presented without quantitative ablation results isolating the contribution of the decoupled local encoder, global encoder, or the lightweight fusion module. This makes it impossible to verify that the architectural decoupling (rather than other implementation details) drives the reported gains over prior coupled methods.
Authors: We agree that quantitative ablations are necessary to isolate the role of the decoupled encoders and fusion module. We have conducted these experiments on the public benchmark and will add the results to the revised Experiments section, including tables that report performance when each component is removed or replaced with a coupled baseline. revision: yes
-
Referee: [Section 4] Section 4 (results): no error bars, standard deviations across sequences, or statistical significance tests are supplied for the reconstruction errors on the public benchmark. This weakens the claim of consistent outperformance and global consistency, particularly given the known variability of clinical ultrasound data.
Authors: We acknowledge that the current results lack these statistical details. In the revision we will report per-sequence standard deviations, add error bars to all relevant plots and tables in Section 4, and include paired statistical significance tests against prior methods to support the claims of consistent outperformance. revision: yes
-
Referee: [Method] Method (fusion module description): the paper provides no explicit analysis or out-of-distribution experiments showing that the lightweight fusion reliably reconciles the two decoupled streams without introducing drift when anatomical context changes. This is load-bearing for the global-consistency claim, as prior coupled architectures avoided this risk by construction.
Authors: We recognize the value of explicit validation for the fusion module. While the benchmark results already demonstrate low drift through globally consistent volumes, we will expand the method description with a dedicated analysis subsection on fusion behavior and add experiments on anatomical-context subsets of the benchmark to further illustrate robustness without introducing new data collection. revision: yes
Circularity Check
No circularity: empirical architecture validated on benchmark
full rationale
The paper presents DualTrack as a dual-encoder neural architecture for sensorless 3D ultrasound trajectory estimation. Claims of SOTA accuracy and sub-5mm average error rest on experimental results from a large public benchmark, not on any closed-form derivation, fitted parameter renamed as prediction, or self-citation chain. The abstract describes decoupled local (dense spatiotemporal convolutions) and global (CNN + temporal attention) encoders plus a lightweight fusion module, but performance is reported as measured outcome rather than forced by construction. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the inputs. This is a standard empirical CV contribution with independent external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decoupled local and global feature extraction improves modeling of complementary aspects in ultrasound sequences over tightly coupled or single-stream approaches.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose DualTrack, a novel dual-encoder architecture that leverages decoupled local and global encoders specialized for their respective scales of feature extraction. The local encoder uses dense spatiotemporal convolutions... while the global encoder utilizes an image backbone... and temporal attention layers... A lightweight fusion module then combines these features
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DualTrack achieves state-of-the-art accuracy and globally consistent 3D reconstructions... average reconstruction error below 5 mm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: International conference on medical image computing and computer-assisted intervention
Farshad, A., Yeganeh, Y., Gehlbach, P., Navab, N.: Y-net: A spatiospectral dual- encoder network for medical image segmentation. In: International conference on medical image computing and computer-assisted intervention. pp. 582–592. Springer (2022)
work page 2022
-
[2]
Computers in Biology and Medicine150, 106197 (2022)
Fu, Z., Li, J., Hua, Z.: Deau-net: Attention networks based on dual encoder for medical image segmentation. Computers in Biology and Medicine150, 106197 (2022)
work page 2022
-
[3]
IEEE Transactions on Biomed- ical Engineering70(3), 970–979 (2023).https://doi.org/10.1109/TBME.2022
Guo, H., Chao, H., Xu, S., Wood, B.J., Wang, J., Yan, P.: Ultrasound volume re- construction from freehand scans without tracking. IEEE Transactions on Biomed- ical Engineering70(3), 970–979 (2023).https://doi.org/10.1109/TBME.2022. 3206596
-
[4]
Guo, H., Xu, S., Wood, B., Yan, P.: Sensorless freehand 3d ultrasound reconstruc- tion via deep contextual learning. In: Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part III 23. pp. 463–472. Springer (2020)
work page 2020
-
[5]
Medical & biological engineering & computing61(3), 661–671 (2023)
Hong, Z., Chen, M., Hu, W., Yan, S., Qu, A., Chen, L., Chen, J.: Dual encoder network with transformer-cnn for multi-organ segmentation. Medical & biological engineering & computing61(3), 661–671 (2023)
work page 2023
-
[6]
Medical Image Analysis 96, 103202 (2024)
Jiao,J.,Zhou,J.,Li,X.,Xia,M.,Huang,Y.,Huang,L.,Wang,N.,Zhang,X.,Zhou, S., Wang, Y., et al.: Usfm: A universal ultrasound foundation model generalized to tasks and organs towards label efficient image analysis. Medical Image Analysis 96, 103202 (2024)
work page 2024
-
[7]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
work page 2023
-
[8]
Li, Q., Saeed, S.U., Barratt, D.C., Clarkson, M.J., Vercauteren, T., Hu, Y.: Track- erless 3d freehand ultrasound reconstruction challenge. In: 27th International Con- ference on Medical Image Computing and Computer Assisted Intervention (MIC- CAI 2024). Zenodo (2024).https://doi.org/10.5281/zenodo.10991501,https: //doi.org/10.5281/zenodo.10991501
-
[9]
In: 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI)
Li, Q., Shen, Z., Li, Q., Barratt, D.C., Dowrick, T., Clarkson, M.J., Vercauteren, T., Hu, Y.: Trackerless freehand ultrasound with sequence modelling and auxiliary transformation over past and future frames. In: 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI). pp. 1–5. IEEE (2023) 10 Authors Suppressed Due to Excessive Length
work page 2023
-
[10]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Li, Q., Shen, Z., Yang, Q., Barratt, D.C., Clarkson, M.J., Vercauteren, T., Hu, Y.: Nonrigid reconstruction of freehand ultrasound without a tracker. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 689–699. Springer (2024)
work page 2024
-
[11]
Advances in neural information processing systems32(2019)
Lu,J.,Batra,D.,Parikh,D.,Lee,S.:Vilbert:Pretrainingtask-agnosticvisiolinguis- tic representations for vision-and-language tasks. Advances in neural information processing systems32(2019)
work page 2019
-
[12]
Luo, M., Yang, X., Huang, X., Huang, Y., Zou, Y., Hu, X., Ravikumar, N., Frangi, A.F., Ni, D.: Self context and shape prior for sensorless freehand 3d ultrasound reconstruction. In: Medical Image Computing and Computer Assisted Interven- tion – MICCAI 2021: 24th International Conference, Strasbourg, France, Septem- ber 27–October 1, 2021, Proceedings, Par...
-
[13]
In: International Conference on Medical Image Com- puting and Computer-Assisted Intervention
Luo, M., Yang, X., Wang, H., Du, L., Ni, D.: Deep motion network for freehand 3d ultrasound reconstruction. In: International Conference on Medical Image Com- puting and Computer-Assisted Intervention. pp. 290–299. Springer (2022)
work page 2022
-
[14]
Nature Communications15(1), 654 (2024)
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment anything in medical images. Nature Communications15(1), 654 (2024)
work page 2024
-
[15]
In: 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI)
Ning, G., Liang, H., Zhou, L., Zhang, X., Liao, H.: Spatial position estimation method for 3d ultrasound reconstruction based on hybrid transfomers. In: 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI). pp. 1–5. IEEE (2022)
work page 2022
-
[16]
Medical image analysis48, 187–202 (2018)
Prevost, R., Salehi, M., Jagoda, S., Kumar, N., Sprung, J., Ladikos, A., Bauer, R., Zettinig, O., Wein, W.: 3d freehand ultrasound without external tracking using deep learning. Medical image analysis48, 187–202 (2018)
work page 2018
-
[17]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
work page 2017
-
[18]
Zhang, Y., Liu, H., Hu, Q.: Transfuse: Fusing transformers and cnns for med- ical image segmentation. In: Medical image computing and computer assisted intervention–MICCAI 2021: 24th international conference, Strasbourg, France, September 27–October 1, 2021, proceedings, Part I 24. pp. 14–24. Springer (2021)
work page 2021
-
[19]
iBOT: Image BERT Pre-Training with Online Tokenizer
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.