PolyTruth: Multilingual Disinformation Detection using Transformer-Based Language Models
Pith reviewed 2026-05-18 16:59 UTC · model grok-4.3
The pith
RemBERT outperforms other multilingual transformers in detecting disinformation across languages, especially low-resource ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
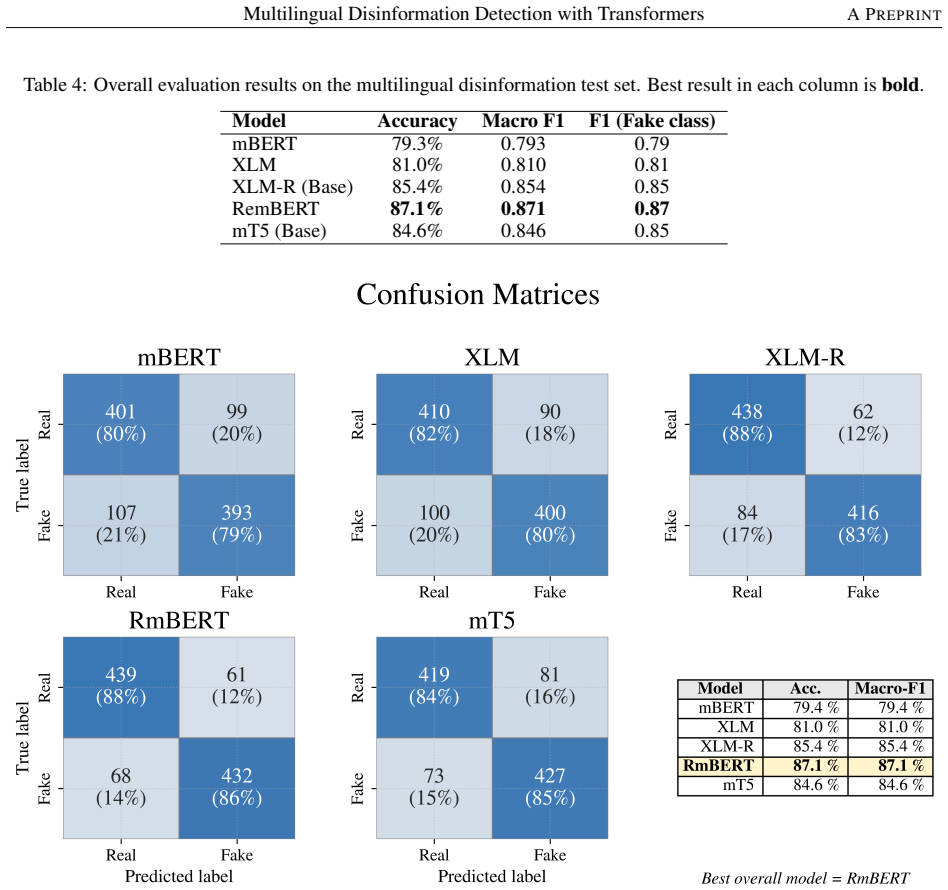
The paper establishes through direct comparison that RemBERT achieves better overall accuracy than mBERT, XLM, XLM-RoBERTa, and mT5 when classifying false claims versus factual corrections in the PolyTruth Disinfo Corpus, with particular strength on low-resource languages, while mBERT and XLM exhibit considerable limitations when training data is scarce.
What carries the argument
The PolyTruth Disinfo Corpus of 60,486 statement pairs across 25 languages, used as a common benchmark for fake-versus-true classification by five multilingual transformer models.
If this is right
- RemBERT's stronger results on low-resource languages indicate it may be the better choice for real-world systems monitoring disinformation in linguistically diverse settings.
- The observed limitations of mBERT and XLM imply that additional data or architectural changes are required to make those models reliable for languages with scarce examples.
- Public release of the PolyTruth Disinfo Corpus enables other researchers to test new models and training strategies on the same multilingual task.
- Performance differences across models underscore the need to account for language family coverage and topical balance when deploying disinformation detectors globally.
Where Pith is reading between the lines
- If RemBERT's advantage holds under broader testing, it could support faster identification of coordinated false claims that appear in multiple languages at once.
- The findings suggest testing whether fine-tuning RemBERT on additional low-resource language pairs further widens its lead over the other models.
- This line of work connects to the problem of detecting disinformation that originates in one language and spreads through translations into others.
Load-bearing premise
The PolyTruth Disinfo Corpus provides accurately labeled, representative examples of disinformation across languages and topics with minimal cultural or annotation bias.
What would settle it
A replication experiment on an independently collected multilingual disinformation dataset in which RemBERT no longer shows higher accuracy than mBERT or XLM on low-resource languages would disprove the performance ranking.
Figures




read the original abstract
Disinformation spreads rapidly across linguistic boundaries, yet most AI models are still benchmarked only on English. We address this gap with a systematic comparison of five multilingual transformer models: mBERT, XLM, XLM-RoBERTa, RemBERT, and mT5 on a common fake-vs-true machine learning classification task. While transformer-based language models have demonstrated notable success in detecting disinformation in English, their effectiveness in multilingual contexts still remains up for debate. To facilitate evaluation, we introduce PolyTruth Disinfo Corpus, a novel corpus of 60,486 statement pairs (false claim vs. factual correction) spanning over twenty five languages that collectively cover five language families and a broad topical range from politics, health, climate, finance, and conspiracy, half of which are fact-checked disinformation claims verified by an augmented MindBugs Discovery dataset. Our experiments revealed performance variations. Models such as RemBERT achieved better overall accuracy, particularly excelling in low-resource languages, whereas models like mBERT and XLM exhibit considerable limitations when training data is scarce. We provide a discussion of these performance patterns and implications for real-world deployment. The dataset is publicly available on our GitHub repository to encourage further experimentation and advancement. Our findings illuminate both the potential and the current limitations of AI systems for multilingual disinformation detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PolyTruth Disinfo Corpus (60,486 statement pairs spanning >25 languages and five language families, half drawn from an augmented MindBugs dataset) and reports a comparative evaluation of five multilingual transformers (mBERT, XLM, XLM-RoBERTa, RemBERT, mT5) on a binary fake-vs-true disinformation classification task. It claims that RemBERT attains higher overall accuracy and performs particularly well on low-resource languages, while mBERT and XLM show limitations under data scarcity; the dataset is released publicly.
Significance. A well-validated multilingual disinformation corpus with broad topical coverage could serve as a useful benchmark for low-resource settings, where English-centric models often fail. Public release of the data supports reproducibility. However, the absence of statistical rigor and corpus-quality diagnostics in the reported experiments substantially weakens the evidential basis for the claimed model rankings.
major comments (3)
- [§3] §3 (Dataset construction): No inter-annotator agreement figures, no description of the multilingual fact-checking or augmentation protocol, and no audit for annotation or cultural bias are supplied for the PolyTruth corpus. Because the central claim attributes accuracy gaps to model architecture rather than label noise or topic skew in low-resource languages, this omission is load-bearing.
- [§4] §4 (Experiments): The abstract and results summary report raw accuracy differences without error bars, statistical significance tests, training hyper-parameters, data-split details, or ablation studies. This prevents verification that the reported superiority of RemBERT is robust rather than an artifact of post-hoc choices or unbalanced splits.
- [Results] Results tables/figures: No confidence intervals or per-language breakdown with sample sizes is referenced, so the specific claim that RemBERT “excels in low-resource languages” cannot be assessed for statistical reliability or confounding by data volume.
minor comments (3)
- [Abstract] Abstract: The phrase “up for debate” is vague; replace with a concise statement of the open empirical question.
- [Abstract] The GitHub repository URL should be given explicitly rather than described generically.
- [§3] Notation: “statement pairs (false claim vs. factual correction)” should clarify whether each pair is treated as a single training instance or as separate positive/negative examples.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the transparency and statistical rigor of our work. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [§3] §3 (Dataset construction): No inter-annotator agreement figures, no description of the multilingual fact-checking or augmentation protocol, and no audit for annotation or cultural bias are supplied for the PolyTruth corpus. Because the central claim attributes accuracy gaps to model architecture rather than label noise or topic skew in low-resource languages, this omission is load-bearing.
Authors: We agree that additional details on the dataset construction are necessary to support our claims. In the revised manuscript, we will expand §3 to include a full description of the augmentation protocol based on the MindBugs dataset, the multilingual fact-checking sources used, and any steps taken to address potential cultural biases. Regarding inter-annotator agreement, since the labels originate from verified fact-checking sources rather than crowd-sourced annotations, IAA was not applicable in the traditional sense; however, we will add a discussion of label verification processes and acknowledge this as a potential source of noise in the limitations section. revision: partial
-
Referee: [§4] §4 (Experiments): The abstract and results summary report raw accuracy differences without error bars, statistical significance tests, training hyper-parameters, data-split details, or ablation studies. This prevents verification that the reported superiority of RemBERT is robust rather than an artifact of post-hoc choices or unbalanced splits.
Authors: We acknowledge the need for greater experimental detail to ensure reproducibility and robustness. We will revise §4 to include training hyperparameters, data split ratios and methodology, and results from multiple runs with different random seeds to provide error bars. We will also perform and report statistical significance tests (e.g., paired t-tests or McNemar's test) comparing model performances. Ablation studies on key components will be added where feasible. revision: yes
-
Referee: [Results] Results tables/figures: No confidence intervals or per-language breakdown with sample sizes is referenced, so the specific claim that RemBERT “excels in low-resource languages” cannot be assessed for statistical reliability or confounding by data volume.
Authors: We will update the results section and associated tables/figures to include per-language performance metrics along with sample sizes for each language. Confidence intervals will be added to the accuracy figures. This will enable a clearer assessment of RemBERT's performance on low-resource languages and help identify any confounding effects from varying data volumes. revision: yes
Circularity Check
No significant circularity in empirical model comparison on new corpus
full rationale
The paper conducts a direct empirical evaluation of five standard multilingual transformers (mBERT, XLM, XLM-RoBERTa, RemBERT, mT5) on the introduced PolyTruth Disinfo Corpus for a binary classification task. No equations, derivations, or first-principles claims appear in the provided text; reported accuracies are straightforward experimental outputs rather than quantities reduced by construction to fitted parameters or self-citations. The central results follow from training and testing the models on the dataset without any load-bearing step that renames or re-derives the inputs as predictions. This is a standard empirical comparison whose validity rests on data quality and experimental design, not on internal definitional circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard supervised classification assumptions hold, including that the training and test splits are representative and that human fact-check labels are reliable ground truth.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We fine-tuned five multilingual transformers under identical settings (binary true vs. false objective)... RemBERT achieves the highest overall accuracy at 87.1%
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We base our experiments on a multilingual disinformation dataset... 60,486 statement pairs spanning over twenty five languages
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The spread of true and false news online
Soroush Vosoughi, Deb Roy, and Sinan Aral. The spread of true and false news online. Science, 359 0 (6380): 0 1146--1151, 2018
work page 2018
-
[2]
Fake news detection on social media: A data mining perspective
Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu. Fake news detection on social media: A data mining perspective. SIGKDD Explorations, 19 0 (1): 0 22--36, 2017
work page 2017
-
[3]
Supriyono, A. P. Wibawa, Suyono, and F. Kurniawan. Advancements in natural language processing: Implications, challenges, and future directions. Telematics and Informatics Reports, 16: 0 100173, 2024
work page 2024
-
[4]
A survey on stance detection for mis- and disinformation identification
Momchil Hardalov, Arun Arora, Preslav Nakov, and Isabelle Augenstein. A survey on stance detection for mis- and disinformation identification. arXiv preprint arXiv:2103.00242, 2021
-
[5]
Multilingual fake news detection: A study on various models and training scenarios
Reza Chalehchaleh, Reza Farahbakhsh, and Noel Crespi. Multilingual fake news detection: A study on various models and training scenarios. In Intelligent Systems Conference, pages 73--89. Springer, 2024
work page 2024
-
[6]
Myanmar: Facebook’s systems promoted violence against rohingya; meta owes reparations
Amnesty International . Myanmar: Facebook’s systems promoted violence against rohingya; meta owes reparations. Amnesty International, 2022. 29 September
work page 2022
-
[7]
Daniel Zaleznik. Facebook and genocide: How facebook contributed to genocide in myanmar and why it will not be held accountable. Harvard Law School, 2021
work page 2021
-
[8]
Evidence-aware multilingual fake news detection
Hicham Hammouchi and Mustapha Ghogho. Evidence-aware multilingual fake news detection. IEEE Access, 10: 0 116808--116818, 2022
work page 2022
-
[9]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL, pages 4171--4186, 2019
work page 2019
-
[10]
Unsupervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, et al. Unsupervised cross-lingual representation learning at scale. In Proceedings of ACL, pages 8440--8451, 2020
work page 2020
-
[11]
Mindbugs disinformation/fake news dataset (2009--2024), 2024
Ioana Cheres. Mindbugs disinformation/fake news dataset (2009--2024), 2024. Accessed 01 Jan 2025
work page 2009
-
[12]
Cross-lingual language model pretraining
Guillaume Lample and Alexis Conneau. Cross-lingual language model pretraining. In Advances in Neural Information Processing Systems (NeurIPS), pages 7059--7069, 2019
work page 2019
-
[13]
Rethinking embedding coupling in pre-trained language models
Hyung Won Chung, Thibault F \'e vry, Henry Tsai, Melvin Johnson, et al. Rethinking embedding coupling in pre-trained language models. In Proceedings of ICLR, 2021
work page 2021
-
[14]
mt5: A massively multilingual pre-trained text-to-text transformer
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Sharan Barua, and Colin Raffel. mt5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of NAACL, pages 483--498, 2021
work page 2021
-
[15]
Markus Sch \"u tz, Julian B \"o ck, Michael Andresel, et al. Ait\_fhstp at checkthat! 2022: Cross-lingual fake news detection with a large pre-trained transformer. In Working Notes of CLEF 2022 - CheckThat! Lab, 2022
work page 2022
-
[16]
Parth Patwa, Mohit Bhardwaj, Vinay Gupta, et al. Overview of constraint 2021 shared tasks: Detecting english covid-19 fake news and hindi hostile posts. In Workshop on Combating Online Hostile Posts in Regional Languages (CONSTRAINT), pages 42--53. Springer, 2021
work page 2021
-
[17]
Enhancing multilingual fake news detection through llm-based data augmentation
Reza Chalehchaleh, Reza Farahbakhsh, and Noel Crespi. Enhancing multilingual fake news detection through llm-based data augmentation. In Complex Networks and Their Applications XIII, volume 2065 of Lecture Notes in Computer Science, pages 258--270. Springer, 2025
work page 2065
-
[18]
Cross-lingual knowledge transfer for low-resource fake news detection
Xin Zhou, Yichao Wang, Zhen Liu, et al. Cross-lingual knowledge transfer for low-resource fake news detection. In Proceedings of ACL, pages 215--223, 2023
work page 2023
-
[19]
Multimodal multilingual fake news detection: Integrating text and image signals
Rohan Gupta, Aman Singh, and Vikram Kumar. Multimodal multilingual fake news detection: Integrating text and image signals. Information Fusion, 95: 0 315--328, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.