User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums
Pith reviewed 2026-05-18 17:13 UTC · model grok-4.3
The pith
The UXPID dataset supplies 7130 synthesized user feedback branches from industrial forums, each annotated by LLM for UX insights, expectations, severity, sentiment and topics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
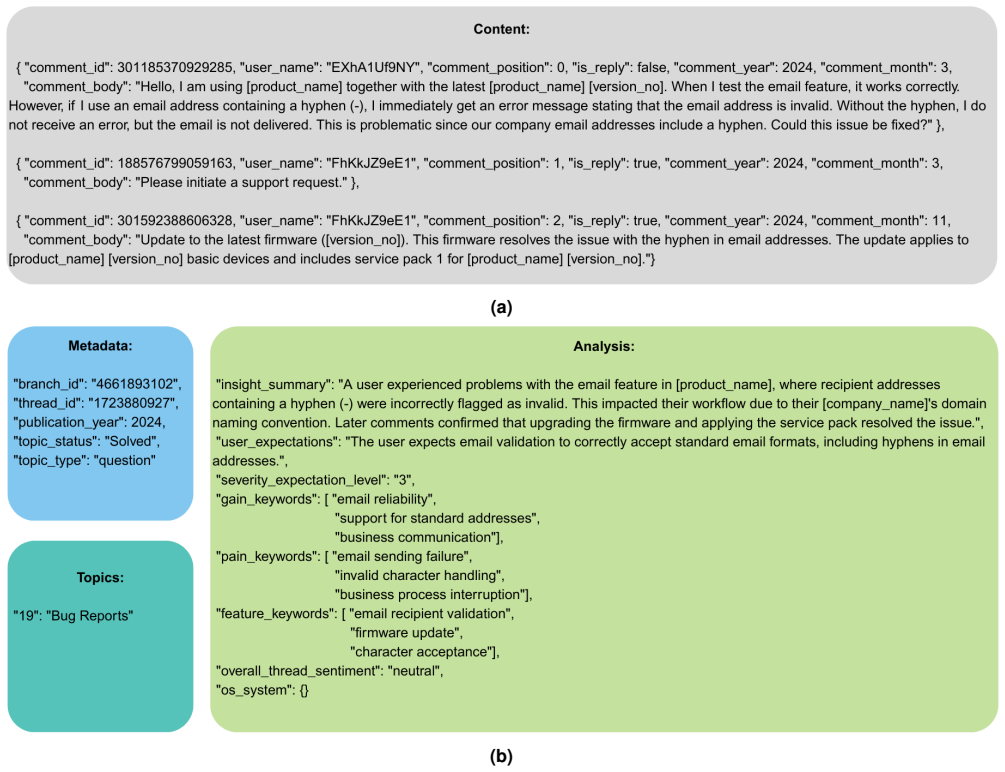
The paper presents UXPID as a collection of 7130 synthesized and anonymized user feedback branches extracted from a public industrial automation forum, each stored as a JSON record containing multi-post comments together with metadata and LLM annotations for UX insights, user expectations, severity ratings, sentiment, and topic classifications, thereby enabling research in user requirements, UX analysis, and AI-driven feedback processing where privacy and licensing restrictions limit access to real-world data.
What carries the argument
The UXPID dataset itself: a set of structured JSON records of multi-post forum comments enriched with LLM annotations across UX-related attributes.
If this is right
- The dataset can be used directly to train and evaluate transformer models on issue detection and requirements extraction in technical forums.
- It supplies labeled examples for sentiment analysis tasks specific to industrial product support discussions.
- Researchers gain a public benchmark for studying how users articulate expectations and problems in automation contexts.
- The resource lowers the barrier to developing AI tools that process forum feedback while respecting privacy constraints.
Where Pith is reading between the lines
- If the annotations hold up under scrutiny, similar LLM-assisted synthesis pipelines could be reused on forums from other technical fields.
- The dataset could serve as seed data for training smaller models that then label much larger volumes of unlabeled forum posts.
- Aggregated patterns from the severity and topic labels might inform product teams about recurring user pain points without reading every thread.
Load-bearing premise
The LLM-generated annotations for UX insights, severity, sentiment, and topics are accurate and unbiased enough to function as reliable training labels without systematic errors from the model or the synthesis process.
What would settle it
Independent human experts rating a random sample of the records and finding low agreement with the LLM labels on severity ratings or topic classifications would show that the annotations cannot be trusted as ground truth.
Figures



read the original abstract
Customer feedback in industrial forums offers rich but underexplored insights into real-world product experience. Yet systematic analysis remains challenging due to unstructured, domain-specific content and the scarcity of high-quality labeled datasets. This paper presents the User eXperience Perception Insights Dataset (UXPID), a collection of 7130 synthesized and anonymized user feedback branches extracted from a public industrial automation forum. Each JSON record contains multi-post comments enriched with metadata and annotated by a large language model (LLM) for UX insights, user expectations, severity ratings, sentiment, and topic classifications. UXPID is designed to facilitate research in user requirements, user experience (UX) analysis, and AI-driven feedback processing, particularly where privacy and licensing restrictions limit access to real-world data. It supports the training and evaluation of transformer-based models for tasks such as issue detection, sentiment analysis, and requirements extraction in technical forums, providing a valuable resource for advancing NLP methods within industrial product support and software engineering domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the User eXperience Perception Insights Dataset (UXPID), a collection of 7130 synthesized and anonymized user feedback branches extracted from a public industrial automation forum. Each JSON record contains multi-post comments enriched with metadata and annotated by a large language model (LLM) for UX insights, user expectations, severity ratings, sentiment, and topic classifications. The dataset is positioned as a resource to support research in user requirements, UX analysis, and AI-driven feedback processing in technical forums where privacy and licensing restrictions limit real data access.
Significance. If the LLM annotations prove reliable, UXPID could help address the scarcity of labeled domain-specific data for training models on issue detection, sentiment analysis, and requirements extraction in industrial product support and software engineering. The use of public forum data combined with synthesis and anonymization to navigate privacy constraints is a constructive approach that may enable similar dataset efforts in other restricted domains.
major comments (1)
- [Abstract] Abstract: The manuscript claims that UXPID supplies a valuable resource for advancing NLP methods and supports training of transformer-based models, yet provides no description of prompt engineering details, few-shot examples, temperature settings, model version, or—most critically—any human evaluation, inter-annotator agreement metrics, or error analysis of the LLM labels for severity ratings, sentiment, and topic classifications. In a specialized industrial-automation domain, this leaves the central usefulness claim dependent on an untested assumption that the annotations are sufficiently accurate and free of systematic domain-specific errors.
minor comments (1)
- [Abstract] Abstract: The description of record structure would benefit from an explicit statement of the JSON schema or key fields to improve immediate usability for potential adopters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript describing the UXPID dataset. We address the major comment point by point below and outline the revisions we will make to improve transparency regarding the LLM annotation process.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript claims that UXPID supplies a valuable resource for advancing NLP methods and supports training of transformer-based models, yet provides no description of prompt engineering details, few-shot examples, temperature settings, model version, or—most critically—any human evaluation, inter-annotator agreement metrics, or error analysis of the LLM labels for severity ratings, sentiment, and topic classifications. In a specialized industrial-automation domain, this leaves the central usefulness claim dependent on an untested assumption that the annotations are sufficiently accurate and free of systematic domain-specific errors.
Authors: We agree that the current manuscript would be strengthened by greater transparency on the annotation methodology. In the revised version, we will add a new subsection in the Methods section detailing the LLM model and version used, the full prompt templates, few-shot examples, and temperature settings applied during annotation. We will also include results from a human validation study conducted on a random sample of 300 records, reporting inter-annotator agreement (Cohen's kappa) for severity, sentiment, and topic labels along with a qualitative error analysis that examines potential domain-specific issues in industrial automation feedback. These additions will directly support the usefulness claims for NLP and transformer model training. revision: yes
Circularity Check
No significant circularity; dataset paper with no derivations or self-referential predictions
full rationale
The paper presents UXPID as a new data resource: 7130 synthesized forum threads annotated by an external LLM for UX insights, severity, sentiment, and topics. No equations, predictive models, fitted parameters, or derivation chains are claimed or present. The abstract and description frame the work as data collection and enrichment rather than any result derived from the paper's own inputs. No self-citations function as load-bearing justifications for uniqueness or ansatzes, and the annotations are generated outside the paper rather than reduced to its own definitions. This is a standard honest data-release contribution whose value depends on external use and validation, not internal circular logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can produce accurate and unbiased annotations for UX insights, severity, sentiment, and topics on technical forum text.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each JSON record contains multi-post comments enriched with metadata and annotated by a large language model (LLM) for UX insights, user expectations, severity ratings, sentiment, and topic classifications.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tasnim, M., Rayhan, M., Zhang, Z. & Poranen, T. A systematic literature review on requirements engineering practices and challenges in open-source projects. In2023 49th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), 278–285, 10.1109/SEAA60479.2023.00050 (2023). 3.Sommerville, I. & Sawyer, P.Requirements engineering: a good ...
-
[2]
Factors4, e8, 10.2196/humanfactors.5443, (2017)
Harte, R.et al.A human-centered design methodology to enhance the usability, human factors, and user experience of connected health systems: A three-phase methodology.JMIR Hum. Factors4, e8, 10.2196/humanfactors.5443, (2017)
-
[3]
Sauer, J., Sonderegger, A. & Schmutz, S. Usability, user experience and accessibility: towards an integrative model.Er- gonomics63, 1207–1220, 10.1080/00140139.2020.1774080, (2020). PMID: 32450782, https://doi.org/10.1080/00140139. 2020.1774080
-
[4]
Maalej, W., Biryuk, V ., Wei, J. & Panse, F. On the automated processing of user feedback. InHandbook on Natural Language Processing for Requirements Engineering, 279–308 (Springer, 2025)
work page 2025
-
[5]
Soares, M. D. S., Vrancken, J. & Verbraeck, A. User requirements modeling and analysis of software-intensive systems84, 328–339, 10.1016/j.jss.2010.10.020, (2011)
- [6]
-
[7]
Just, J. Natural language processing for innovation search–reviewing an emerging non-human innovation intermediary. Technovation129, 102883, (2024)
work page 2024
-
[8]
Laurer, M., Van Atteveldt, W., Casas, A. & Welbers, K. Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and bert-nli.Polit. Analysis32, 84–100, (2024)
work page 2024
-
[9]
Zhang, J.et al.Less is more: On the importance of data quality for unit test generation.Proc. ACM on Softw. Eng.2, 1293–1316, (2025)
work page 2025
-
[10]
Osman, A., Salim, N. & Saeed, F. Quality dimensions features for identifying high-quality user replies in text forum threads using classification methods14, e0215516, 10.1371/journal.pone.0215516. 14.Castelli, V .et al.The techqa dataset.arXiv preprint arXiv:1911.02984(2019). 15.Sonali, S. FR_nfr_dataset, 10.17632/4YSX9FYZV4.1, (2024)
-
[11]
Ferrari, A., Spagnolo, G. O. & Gnesi, S. Pure: A dataset of public requirements documents. In2017 IEEE 25th international requirements engineering conference (RE), 502–505 (IEEE, 2017). 8/9 17.Bozyigit, F.et al.Dataset for: Text requirements to models, 10.21227/r9j6-nd62, (2023)
-
[12]
Mekala, R. R., Irfan, A., Groen, E. C., Porter, A. & Lindvall, M. Classifying user requirements from online feedback in small dataset environments using deep learning. In2021 IEEE 29th International requirements engineering conference (RE), 139–149 (IEEE, 2021)
work page 2021
-
[13]
Kadebu, P., Sikka, S., Tyagi, R. K. & Chiurunge, P. A classification approach for software requirements towards maintainable security.Sci. Afr.19, e01496, (2023)
work page 2023
-
[14]
Neo, G., Moura, J., Almeida, H., Neo, A. & Freitas Júnior, O. User story tutor (UST) to support agile software developers:. InProceedings of the 16th International Conference on Computer Supported Education, 51–62, 10.5220/ 0012619200003693 (SCITEPRESS - Science and Technology Publications, 2024). 21.Kulyabin, M.et al.User experience perception insights d...
-
[15]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Sanh, V ., Debut, L., Chaumond, J. & Wolf, T. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, (2020). 1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[16]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding, (2018). 1810.04805. Author contributions statement Data collection, M.K. and J.J.; conceptualization, J.J., M.K. and N.N.M.P; software, M.K. and J.J.; writing-original draft preparation, M.K., J.J., and N.N.M.P.; writing—revi...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.