FluentAvatar: Flicker-Free Talking-Head Animation via Phoneme-Guided Autoregressive Modeling
Pith reviewed 2026-05-18 16:38 UTC · model grok-4.3
The pith
FluentAvatar uses phoneme-guided autoregressive modeling to generate flicker-free talking-head videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FluentAvatar is a two-stage autoregressive framework built on phoneme representations. First, Facial Keyframe Generation produces phoneme-aligned keyframes under a Phoneme-Frame Causal Attention Mask. Then, Inter-frame Interpolation synthesizes transition frames via a timestamp-aware adaptive strategy built upon selective state space modeling. Experiments show it attains the best FVD on both CMLR and HDTF datasets with BG-Flicker results close to ground truth while maintaining strong visual fidelity, lip synchronization, and temporal stability.
What carries the argument
Phoneme-guided autoregressive modeling with a Phoneme-Frame Causal Attention Mask for keyframe generation and selective state space modeling for inter-frame interpolation.
If this is right
- Attains the best Fréchet Video Distance on CMLR and HDTF datasets.
- Produces BG-Flicker scores close to those of real ground-truth videos.
- Delivers strong visual fidelity, accurate lip synchronization, and improved temporal stability.
- Introduces BG-Flicker as a more reliable metric for evaluating inter-frame flicker in talking-head videos.
Where Pith is reading between the lines
- This sequential approach might allow for incremental generation suitable for live streaming applications.
- The phoneme guidance could be adapted to other conditional video tasks like gesture or expression control.
- Adopting similar autoregressive priors might reduce artifacts in broader diffusion-based video synthesis beyond talking heads.
Load-bearing premise
That the primary cause of inter-frame flicker is the variation in denoising trajectories from stochastic initialization in diffusion models.
What would settle it
Generating multiple samples with the autoregressive model on the same fixed input sequence and finding markedly different flicker patterns across runs with low Pearson correlation, as observed in the diffusion baseline.
Figures









read the original abstract
Current talking-head generation has gradually shifted from GAN-based methods to diffusion-based paradigms, achieving remarkable progress in visual fidelity and temporal consistency. However, inter-frame flicker remains prevalent in existing diffusion-based methods. An important reason is that denoising trajectory variation induced by stochastic initialization leaves residual inter-frame inconsistencies, which manifest as short-term, abrupt visual fluctuations between adjacent frames. To further verify this, we conduct a controlled study by fixing the input while varying only the random seed. The results show markedly different flicker patterns across samplings, with a mean inter-seed Pearson correlation of only r = 0.15. This motivates us to explore autoregressive generation, which models frames sequentially and provides a more direct prior for temporal continuity. Based on this, we propose FluentAvatar, a two-stage autoregressive framework built on phoneme representations. First, Facial Keyframe Generation produces phoneme-aligned keyframes under a Phoneme-Frame Causal Attention Mask, and Inter-frame Interpolation synthesizes transition frames via a timestamp-aware adaptive strategy built upon selective state space modeling. Moreover, we introduce BG-Flicker, a background-isolated metric for talking-head videos that enables more reliable evaluation of inter-frame flicker. Experiments on CMLR and HDTF demonstrate that FluentAvatar achieves strong performance in visual fidelity, lip synchronization, and temporal stability, attaining the best FVD on both datasets and BG-Flicker results close to ground truth. The code, the model, and the interface will be released to facilitate further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that inter-frame flicker in diffusion-based talking-head generation arises primarily from denoising trajectory variations due to stochastic initialization, supported by a controlled study showing low mean inter-seed Pearson correlation (r=0.15). It proposes FluentAvatar, a two-stage phoneme-guided autoregressive framework: (1) Facial Keyframe Generation using a Phoneme-Frame Causal Attention Mask to produce aligned keyframes, and (2) Inter-frame Interpolation via timestamp-aware selective state space modeling. On CMLR and HDTF datasets, it reports the best FVD scores, BG-Flicker values close to ground truth, and strong results in visual fidelity, lip synchronization, and temporal stability, with code and model to be released.
Significance. If the results hold, this represents a useful contribution by providing empirical evidence that autoregressive modeling with phoneme guidance can improve temporal stability over diffusion baselines in talking-head animation. The BG-Flicker metric is a practical addition for isolating background flicker evaluation. Explicit credit is due for the planned release of code, model, and interface, which supports reproducibility, and for grounding comparisons against diffusion baselines.
major comments (1)
- [Motivation and controlled study] Controlled study (motivation section): The seed-variation experiment with r=0.15 demonstrates flicker inconsistency but does not isolate stochastic initialization from other diffusion factors such as noise schedule or U-Net biases; without such controls, the direct link to preferring autoregressive modeling over diffusion remains partially unproven, though the final quantitative results provide some external grounding.
minor comments (3)
- [Method] The exact formulation of the Phoneme-Frame Causal Attention Mask and the timestamp-aware adaptive strategy in the selective state space module should include explicit equations or pseudocode for clarity and to allow verification of the claimed temporal continuity prior.
- [Experiments] Hyperparameter choices, exact data splits for CMLR and HDTF, and training details are referenced but would benefit from a dedicated table or appendix subsection to facilitate reproduction of the reported FVD and BG-Flicker numbers.
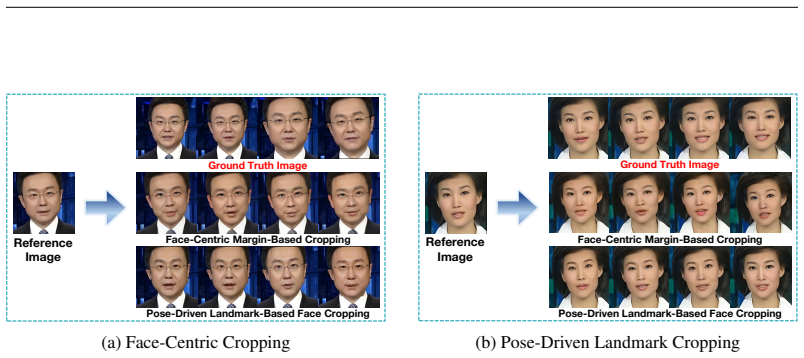
- [Figures] Figure captions for qualitative results should explicitly note the datasets and baselines shown to avoid ambiguity when comparing flicker patterns.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: Controlled study (motivation section): The seed-variation experiment with r=0.15 demonstrates flicker inconsistency but does not isolate stochastic initialization from other diffusion factors such as noise schedule or U-Net biases; without such controls, the direct link to preferring autoregressive modeling over diffusion remains partially unproven, though the final quantitative results provide some external grounding.
Authors: We thank the referee for this observation. In the controlled study, we fix the input condition and vary only the random seed while keeping the noise schedule, U-Net weights, and all other diffusion hyperparameters constant. This isolates the contribution of stochastic initialization to the observed inter-seed variation in flicker patterns (mean Pearson r = 0.15). We agree that a broader set of ablations could further strengthen the motivation; accordingly, we will add a clarifying paragraph in the revised motivation section that explicitly states the controlled variables and notes that the empirical superiority of FluentAvatar over diffusion baselines on FVD and BG-Flicker provides complementary support for the autoregressive design choice. revision: yes
Circularity Check
No circularity: empirical motivation and new architecture are externally validated
full rationale
The paper's chain begins with an empirical observation (low inter-seed correlation r=0.15 in a controlled diffusion study) used to motivate a modeling shift to autoregressive generation with phoneme guidance. It then defines a two-stage architecture (Phoneme-Frame Causal Attention Mask for keyframes + selective state-space interpolation) and evaluates it via standard metrics (FVD) plus a new BG-Flicker metric on CMLR/HDTF datasets against diffusion baselines. No step reduces a claimed prediction or first-principles result to a fitted parameter, self-definition, or self-citation chain; the central claims rest on experimental comparisons that are independent of the model's internal construction. This is the common case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Autoregressive models generate video frames as a single and unified token sequence... P(x(t)j | x(1)1, ..., x(t-1)K, x(t)1, ..., x(t)j-1, c)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Phoneme-Frame Causal Attention Mask... timestamp-aware adaptive strategy built upon selective state space modeling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
AsymTalker: Identity-Consistent Long-Term Talking Head Generation via Asymmetric Distillation
AsymTalker maintains identity consistency in long-term diffusion talking-head videos by encoding temporal references from a static image and training a student model under inference-like conditions via asymmetric dist...
-
AsymTalker: Identity-Consistent Long-Term Talking Head Generation via Asymmetric Distillation
AsymK-Talker introduces kernel-conditioned loop generation, temporal reference encoding, and asymmetric kernel distillation to achieve real-time, drift-resistant talking head synthesis from audio using diffusion models.
-
AsymTalker: Identity-Consistent Long-Term Talking Head Generation via Asymmetric Distillation
AsymTalker uses temporal reference encoding and asymmetric knowledge distillation to produce identity-consistent talking head videos up to 600 seconds long at 66 FPS.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Videoretalking: Audio-based lip synchronization for talking head video editing in the wild
Kun Cheng, Xiaodong Cun, Yong Zhang, Menghan Xia, Fei Yin, Mingrui Zhu, Xuan Wang, Jue Wang, and Nannan Wang. Videoretalking: Audio-based lip synchronization for talking head video editing in the wild. InSIGGRAPH Asia 2022 Conference Papers, pp. 1–9,
work page 2022
-
[3]
Artalk: Speech- driven 3d head animation via autoregressive model.arXiv preprint arXiv:2502.20323,
Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, and Tatsuya Harada. Artalk: Speech- driven 3d head animation via autoregressive model.arXiv preprint arXiv:2502.20323,
-
[4]
Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu, and Jingdong Wang. Hallo2: Long-duration and high-resolution audio-driven portrait image anima- tion.arXiv preprint arXiv:2410.07718,
-
[5]
Speech-driven facial animation using cascaded gans for learning of motion and texture
Dipanjan Das, Sandika Biswas, Sanjana Sinha, and Brojeshwar Bhowmick. Speech-driven facial animation using cascaded gans for learning of motion and texture. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16, pp. 408–424. Springer,
work page 2020
-
[6]
Vimi: Grounding video generation through multi-modal instruction.arXiv preprint arXiv:2407.06304,
Yuwei Fang, Willi Menapace, Aliaksandr Siarohin, Tsai-Shien Chen, Kuan-Chien Wang, Ivan Sko- rokhodov, Graham Neubig, and Sergey Tulyakov. Vimi: Grounding video generation through multi-modal instruction.arXiv preprint arXiv:2407.06304,
-
[7]
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm infer- ence using lookahead decoding.arXiv preprint arXiv:2402.02057,
-
[8]
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, and Di Zhang. Liveportrait: Efficient portrait animation with stitching and retargeting control.arXiv preprint arXiv:2407.03168,
-
[9]
Yefei He, Feng Chen, Yuanyu He, Shaoxuan He, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Zipar: Accelerating autoregressive image generation through spatial locality.arXiv preprint arXiv:2412.04062,
-
[10]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pre- training for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Xiaozhong Ji, Xiaobin Hu, Zhihong Xu, Junwei Zhu, Chuming Lin, Qingdong He, Jiangning Zhang, Donghao Luo, Yi Chen, Qin Lin, et al. Sonic: Shifting focus to global audio perception in portrait animation.arXiv preprint arXiv:2411.16331,
-
[12]
Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, and Yanbo Zheng. Loopy: Taming audio-driven portrait avatar with long-term motion dependency.arXiv preprint arXiv:2409.02634,
-
[13]
Simran Khanuja, Sathyanarayanan Ramamoorthy, Yueqi Song, and Graham Neubig. An image speaks a thousand words, but can everyone listen? on image transcreation for cultural relevance. arXiv preprint arXiv:2404.01247,
-
[14]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jos ´e Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation.arXiv preprint arXiv:2312.14125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Latentsync: Audio conditioned latent diffusion models for lip sync.arXiv preprint arXiv:2412.09262,
Chunyu Li, Chao Zhang, Weikai Xu, Jinghui Xie, Weiguo Feng, Bingyue Peng, and Weiwei Xing. Latentsync: Audio conditioned latent diffusion models for lip sync.arXiv preprint arXiv:2412.09262,
-
[16]
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, and Chao Liang. Omnihuman-1: Re- thinking the scaling-up of one-stage conditioned human animation models.arXiv preprint arXiv:2502.01061,
-
[17]
Zhuoyan Luo, Fengyuan Shi, Yixiao Ge, Yujiu Yang, Limin Wang, and Ying Shan. Open-magvit2: An open-source project toward democratizing auto-regressive visual generation.arXiv preprint arXiv:2409.04410,
-
[18]
Rang Meng, Xingyu Zhang, Yuming Li, and Chenguang Ma. Echomimicv2: Towards striking, simplified, and semi-body human animation.arXiv preprint arXiv:2411.10061,
-
[19]
Vipe: Visualise pretty-much every- thing.arXiv preprint arXiv:2310.10543,
Hassan Shahmohammadi, Adhiraj Ghosh, and Hendrik Lensch. Vipe: Visualise pretty-much every- thing.arXiv preprint arXiv:2310.10543,
-
[20]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[21]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
LLaMA: Open and Efficient Foundation Language Models
K Tian, Y Jiang, Z Yuan, et al. Visual autoregressive modeling: Scalable image generation via next- scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024a. Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive generating ex- pressive portrait videos with audio2video diffusion model under weak condit...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Cong Wang, Kuan Tian, Jun Zhang, Yonghang Guan, Feng Luo, Fei Shen, Zhiwei Jiang, Qing Gu, Xiao Han, and Wei Yang. V-express: Conditional dropout for progressive training of portrait video generation.arXiv preprint arXiv:2406.02511, 2024a. Jiadong Wang, Xinyuan Qian, Malu Zhang, Robby T Tan, and Haizhou Li. Seeing what you said: Talking face generation gu...
-
[24]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024b. Yuchi Wang, Junliang Guo, Jianhong Bai, Runyi Yu, Tianyu He, Xu Tan, Xu Sun, and Jiang Bian. Instructavatar: Text-guided emotion and motion...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation.arXiv preprint arXiv:2403.17694,
-
[26]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Hallo: Hierarchical audio-driven visual synthesis for portrait image animation
Mingwang Xu, Hui Li, Qingkun Su, Hanlin Shang, Liwei Zhang, Ce Liu, Jingdong Wang, Yao Yao, and Siyu Zhu. Hallo: Hierarchical audio-driven visual synthesis for portrait image animation. arXiv preprint arXiv:2406.08801, 2024a. Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, and Baining Guo. Vasa-1: Lifel...
-
[28]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, Jos´e Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vighnesh Birodkar, Agrim Gupta, Xiuye Gu, et al. Language model beats diffusion– tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8652–8661, 2023a. Yue Zhang, Minhao Liu, Zhaokang Chen, Bi...
-
[30]
Figure 7: Original Video Frames from the Dataset
Furthermore, to foster future research and benefit the community, we will open-source this enhanced, high-resolution version of the CMLR dataset. Figure 7: Original Video Frames from the Dataset. Figure 8: Enhanced Video Frames after Super-Resolution. A.2 TRAININGDETAILS We trained the model on a mixed dataset that combines the super-resolved CMLR dataset...
-
[31]
In this study, we establish a baseline model trained exclusively with a token-level cross-entropy (CE) loss. We then incre- mentally incorporate our other proposed loss terms: the pixel-level LPIPS perceptual loss, identity consistency loss, and facial similarity loss. The experimental results clearly demonstrate that while each loss component individuall...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.