ScaleDoc: Scaling LLM-based Predicates over Large Document Collections
Pith reviewed 2026-05-22 12:35 UTC · model grok-4.3
The pith
ScaleDoc speeds up semantic predicates on large document collections by using an offline LLM representation phase and an online proxy model that filters most documents before invoking the full LLM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
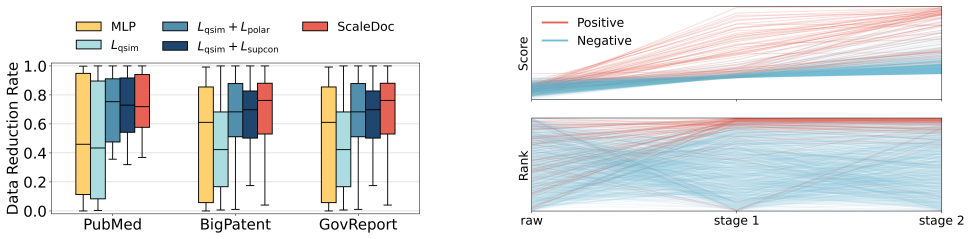
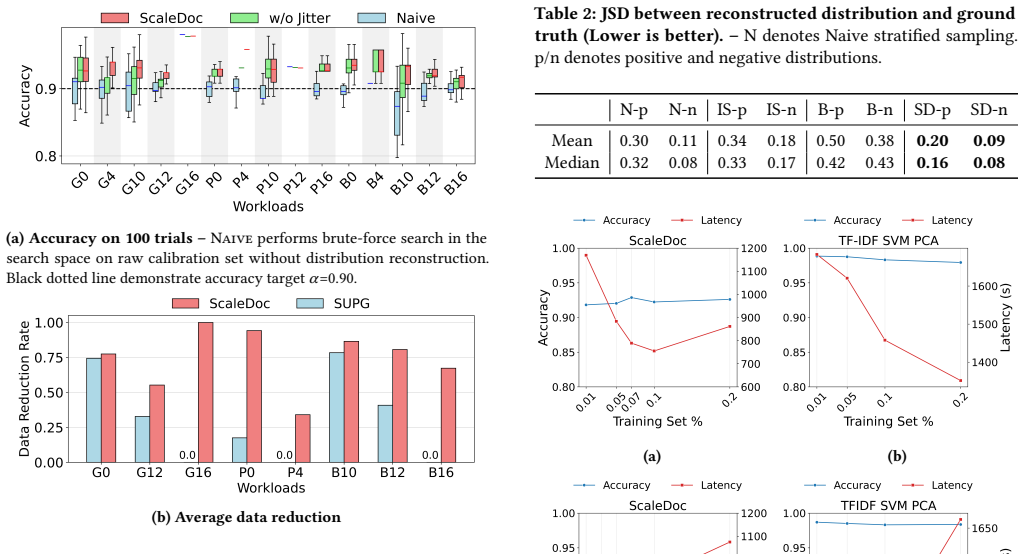
ScaleDoc decouples predicate execution into an offline phase that uses an LLM to generate semantic representations for each document and an online phase that trains a lightweight contrastive-learning proxy model on those representations; the proxy produces decision scores that, together with an adaptive cascade, filter the bulk of documents while meeting accuracy targets and forwarding only ambiguous cases to the LLM.
What carries the argument
Contrastive-learning-based proxy model trained on offline semantic representations, combined with an adaptive cascade that selects the filtering policy to satisfy accuracy constraints.
If this is right
- Semantic predicates over document collections become feasible at scales where full LLM invocation per document would be prohibitive.
- Query latency drops by more than half while preserving the accuracy level users specify.
- LLM invocations are limited to a small, query-dependent fraction of the collection rather than the entire set.
- The same offline representations can be reused across many ad-hoc queries without re-running the LLM.
Where Pith is reading between the lines
- The offline representation step could be applied to other expensive models besides LLMs, such as large vision or multimodal models.
- The approach might combine with traditional database indexes to handle mixed structured and semantic predicates in a single system.
- Further gains could come from sharing proxy training across similar queries or from distilling the proxy into an even smaller model.
Load-bearing premise
The contrastive-learning proxy model produces decision scores accurate enough to filter the majority of documents without violating the target accuracy.
What would settle it
Run the proxy on a held-out dataset and measure that either fewer than half the documents are filtered or that end-to-end accuracy falls below the chosen target even after the cascade adjusts its threshold.
Figures








read the original abstract
Predicates are foundational components in data analysis systems. However, modern workloads increasingly involve unstructured documents, which demands semantic understanding, beyond traditional value-based predicates. Given enormous documents and ad-hoc queries, while Large Language Models (LLMs) demonstrate powerful zero-shot capabilities, their high inference cost leads to unacceptable overhead. Therefore, we introduce \textsc{ScaleDoc}, a novel system that addresses this by decoupling predicate execution into an offline representation phase and an optimized online filtering phase. In the offline phase, \textsc{ScaleDoc} leverages a LLM to generate semantic representations for each document. Online, for each query, it trains a lightweight proxy model on these representations to filter the majority of documents, forwarding only the ambiguous cases to the LLM for final decision. Furthermore, \textsc{ScaleDoc} proposes two core innovations to achieve significant efficiency: (1) a contrastive-learning-based framework that trains the proxy model to generate reliable predicating decision scores; (2) an adaptive cascade mechanism that determines the effective filtering policy while meeting specific accuracy targets. Our evaluations across three datasets demonstrate that \textsc{ScaleDoc} achieves over a 2$\times$ end-to-end speedup and reduces expensive LLM invocations by up to 85\%, making large-scale semantic analysis practical and efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScaleDoc, a system for executing LLM-based predicates over large document collections. It decouples the process into an offline phase that uses an LLM to generate semantic representations for all documents and an online phase that, for each ad-hoc query, trains a lightweight proxy model via contrastive learning on those fixed representations; the proxy produces decision scores that feed an adaptive cascade, which filters the majority of documents while forwarding only ambiguous cases to the LLM to meet a user-specified accuracy target. The central claims are a >2× end-to-end speedup and up to 85% reduction in LLM invocations, demonstrated on three datasets.
Significance. If the proxy reliably separates clear from ambiguous documents at scale while preserving accuracy, ScaleDoc would make semantic predicates practical for large-scale document workloads in database systems, substantially lowering inference costs. The offline/online decoupling and per-query proxy training are technically interesting directions for scaling LLM-augmented data processing.
major comments (2)
- [Evaluation section] Evaluation section: the abstract and evaluation report concrete numbers (2× speedup, ≤85% LLM reduction) but supply no experimental setup details—dataset sizes and characteristics, query workload, baseline systems, number of runs, statistical significance, or error analysis—making it impossible to assess whether the claimed gains are achieved at the stated accuracy targets.
- [§4] §4 (contrastive proxy and adaptive cascade): the manuscript provides no quantitative evidence on proxy calibration, decision-score distributions, threshold selection, or accuracy-vs-filtering trade-off curves. These measurements are load-bearing for the central claim that the cascade meets accuracy targets while correctly filtering the majority of documents.
minor comments (2)
- [Abstract] The abstract refers to 'three datasets' without naming them or giving high-level statistics (size, domain, predicate types).
- [§4.1] Notation for 'predicating decision scores' and the exact form of the contrastive loss could be stated more precisely to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current manuscript would benefit from expanded experimental details and additional quantitative analyses to better support the central claims. We will revise the paper accordingly and respond to each major comment below.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the abstract and evaluation report concrete numbers (2× speedup, ≤85% LLM reduction) but supply no experimental setup details—dataset sizes and characteristics, query workload, baseline systems, number of runs, statistical significance, or error analysis—making it impossible to assess whether the claimed gains are achieved at the stated accuracy targets.
Authors: We acknowledge that the Evaluation section requires more comprehensive details to enable proper assessment of the results. In the revised manuscript, we will expand this section to describe dataset sizes and characteristics, the query workload, baseline systems, number of runs, statistical significance testing, and error analysis. These additions will allow readers to evaluate the reported >2× speedup and up to 85% LLM reduction at the target accuracy levels. revision: yes
-
Referee: [§4] §4 (contrastive proxy and adaptive cascade): the manuscript provides no quantitative evidence on proxy calibration, decision-score distributions, threshold selection, or accuracy-vs-filtering trade-off curves. These measurements are load-bearing for the central claim that the cascade meets accuracy targets while correctly filtering the majority of documents.
Authors: We agree that quantitative evidence on these aspects is important for validating the proxy and cascade. In the revision, we will augment §4 with analyses including proxy calibration metrics, decision-score distributions, threshold selection methodology, and accuracy-vs-filtering trade-off curves. This will provide direct support for how the adaptive cascade meets accuracy targets while filtering the majority of documents. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical system for scaling LLM predicates via offline embeddings and a per-query contrastive proxy plus adaptive cascade. Performance numbers (2× speedup, ≤85% LLM reduction) are reported from evaluations on three datasets rather than derived as predictions from fitted parameters. The proxy is trained on fixed representations for each new predicate, supplying independent grounding instead of reducing to self-definition or prior fits by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the abstract or described method. The contrastive framework and accuracy targets are design choices whose effectiveness is measured externally, not tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- accuracy target
axioms (1)
- domain assumption LLM-generated semantic representations capture predicate-relevant information sufficiently for proxy model training
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a contrastive-learning-based framework that trains the proxy model to generate reliable predicating decision scores; an adaptive cascade mechanism that determines the effective filtering policy while meeting specific accuracy targets
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose ScaleDoc, a novel system that decouples execution into a one-time offline representation phase and an optimized online query phase.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
PLOP: Cost-Based Placement of Semantic Operators in Hybrid Query Plans
PLOP is a cost-based optimizer that finds optimal placements for semantic LLM operators in hybrid query plans via dynamic programming, delivering up to 1.5x speedup and 4.29x cost reduction on 44 benchmark queries whi...
-
Distributed Generative Inference of LLM at Internet Scales with Multi-Dimensional Communication Optimization
BloomBee is a distributed LLM inference system that achieves up to 1.76x higher throughput and 43.2% lower latency than prior decentralized systems by optimizing communication across multiple dimensions in low-bandwid...
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 117–134
work page 2024
-
[2]
Simran Arora, Brandon Yang, Sabri Eyuboglu, Avanika Narayan, Andrew Ho- jel, Immanuel Trummer, and Christopher Ré. 2023. Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes. Proceedings of the VLDB Endowment17, 2 (2023), 92–105
work page 2023
-
[3]
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. 2024. LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders. InFirst Conference on Language Modeling. https://openreview.net/forum?id=IW1PR7vEBf
work page 2024
-
[4]
Lingjiao Chen, Matei Zaharia, and James Zou. 2023. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv:2305.05176 [cs.LG] https://arxiv.org/abs/2305.05176
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. InInter- national conference on machine learning. PmLR, 1597–1607
work page 2020
-
[6]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashat- tention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
work page 2022
-
[7]
Franck Dernoncourt and Ji Young Lee. 2017. PubMed 200k RCT: a Dataset for Se- quential Sentence Classification in Medical Abstracts. InProceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Greg Kondrak and Taro Watanabe (Eds.). Asian Federation of Natural Lan- guage Processing, Taipei, Taiwan, 30...
work page 2017
-
[8]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple Contrastive Learning of Sentence Embeddings. InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association for Compu- tational Linguistics, Online and Punta Cana, Domini...
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. 2020. Mo- mentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9729–9738
work page 2020
- [11]
-
[12]
Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. 2021. Efficient Attentions for Long Document Summarization. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies. Association for Computational 13 Linguistics, Online, 1419–1436. https://doi.org/...
-
[13]
Yulong Hui, Yao Lu, and Huanchen Zhang. [n.d.]. UDA: A Benchmark Suite for Retrieval Augmented Generation in Real-World Document Analysis. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Daniel Kang, John Emmons, Firas Abuzaid, Peter Bailis, and Matei Zaharia. 2017. NoScope: Optimizing Neural Network Queries over Video at Scale.Proceedings of the VLDB Endowment10, 11 (2017)
work page 2017
-
[16]
Daniel Kang, Edward Gan, Peter Bailis, Tatsunori Hashimoto, and Matei Zaharia
- [17]
-
[18]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. [n.d.]. Dense Passage Retrieval for Open-Domain Ques- tion Answering
-
[19]
Moe Kayali, Anton Lykov, Ilias Fountalis, Nikolaos Vasiloglou, Dan Olteanu, and Dan Suciu. 2024. Chorus: Foundation Models for Unified Data Discovery and Exploration.Proceedings of the VLDB Endowment17, 8 (2024), 2104–2114
work page 2024
-
[20]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. 2020. Supervised contrastive learning.Advances in neural information processing systems33 (2020), 18661–18673
work page 2020
-
[21]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles. 611–626
work page 2023
-
[22]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2024. Nv-embed: Improved techniques for train- ing llms as generalist embedding models.arXiv preprint arXiv:2405.17428(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrap- ping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
work page 2023
- [24]
-
[25]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baille Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, and Gerardo Vitagliano
- [27]
-
[28]
Shicheng Liu, Jialiang Xu, Wesley Tjangnaka, Sina Semnani, Chen Yu, and Monica Lam. 2024. SUQL: Conversational Search over Structured and Unstructured Data with Large Language Models. InFindings of the Association for Computational Linguistics: NAACL 2024, Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Linguistics, Mexic...
-
[29]
Yao Lu, Aakanksha Chowdhery, Srikanth Kandula, and Surajit Chaudhuri. 2018. Accelerating machine learning inference with probabilistic predicates. InPro- ceedings of the 2018 International Conference on Management of Data. 1493–1508
work page 2018
-
[30]
Kyle Luoma and Arun Kumar. 2025. SNAILS: Schema Naming Assessments for Improved LLM-Based SQL Inference.Proceedings of the ACM on Management of Data3, 1 (2025), 1–26
work page 2025
-
[31]
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, et al . 2022. Large Dual Encoders Are Generalizable Retrievers. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 9844–9855
work page 2022
-
[32]
OpenAI, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Car- ney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alexi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [33]
-
[34]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[35]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[36]
Abhinav Ramesh Kashyap, Thanh-Tung Nguyen, Viktor Schlegel, Stefan Winkler, See-Kiong Ng, and Soujanya Poria. 2024. A Comprehensive Survey of Sentence Representations: From the BERT Epoch to the CHATGPT Era and Beyond. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Yv...
work page 2024
-
[37]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992
work page 2019
-
[38]
Ricardo Salazar-Díaz, Boris Glavic, and Tilmann Rabl. 2024. Inferdb: In-database machine learning inference using indexes.Proceedings of the VLDB Endowment 17, 8 (2024), 1830–1842
work page 2024
- [39]
-
[40]
Eva Sharma, Chen Li, and Lu Wang. 2019. BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 2204–2213. https://doi.org/10.18653...
-
[41]
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A Smith, Luke Zettlemoyer, and Tao Yu. 2023. One Embed- der, Any Task: Instruction-Finetuned Text Embeddings. InAnnual Meeting of the Association for Computational Linguistics-ACL 2023 (09/07/2023-14/07/2023„, Toronto, Canada)
work page 2023
-
[42]
Zhihui Yang, Zuozhi Wang, Yicong Huang, Yao Lu, Chen Li, and X Sean Wang
-
[43]
Optimizing machine learning inference queries with correlative proxy models.Proceedings of the VLDB Endowment15, 10 (2022), 2032–2044
work page 2022
-
[44]
Enhao Zhang, Nicole Sullivan, Brandon Haynes, Ranjay Krishna, and Magdalena Balazinska. 2025. Self-Enhancing Video Data Management System for Composi- tional Events with Large Language Models.Proc. ACM Manag. Data3, 3, Article 215 (June 2025), 29 pages. https://doi.org/10.1145/3725352
- [45]
-
[46]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serving. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Article...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.