Intelligent Healthcare Imaging Platform: A VLM-Based Framework for Automated Medical Image Analysis and Clinical Report Generation
Pith reviewed 2026-05-18 16:17 UTC · model grok-4.3
The pith
A vision-language model framework automates tumor detection and clinical report generation across CT, MRI, X-ray, and ultrasound images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
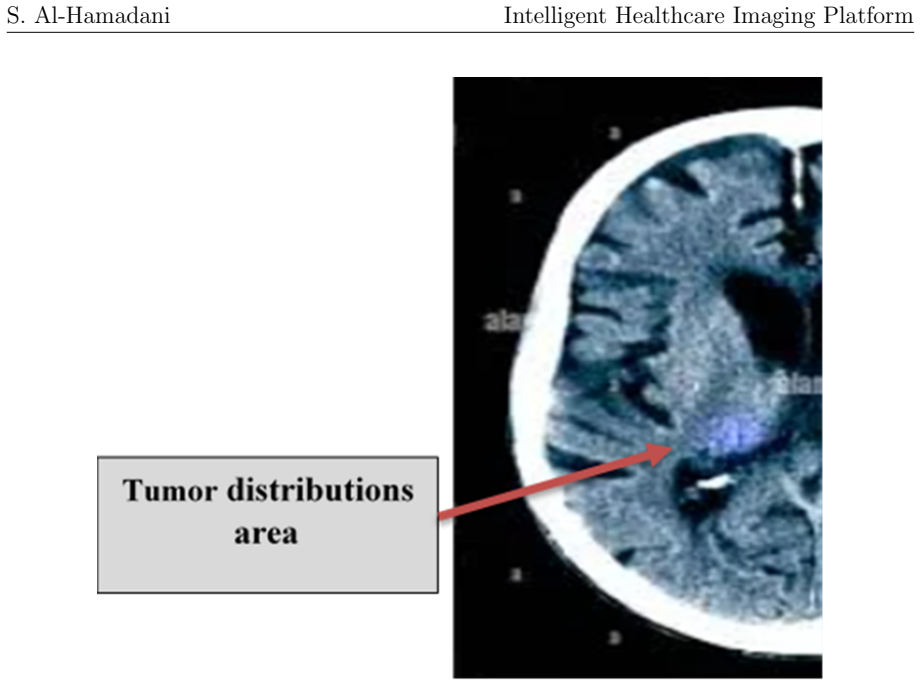
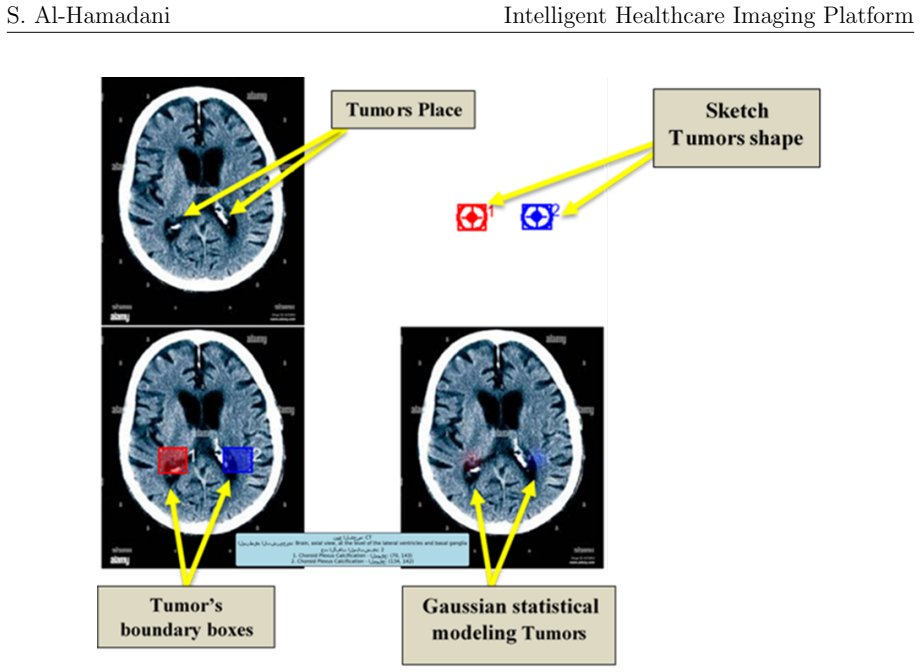
The framework shows that a pre-trained vision-language model, when augmented with prompt engineering, coordinate verification, and probabilistic Gaussian modeling for anomaly distribution, can deliver automated tumor detection and clinically interpretable report generation across CT, MRI, X-ray, and ultrasound modalities, with an average location deviation of 80 pixels and strong experimental results in anomaly detection.
What carries the argument
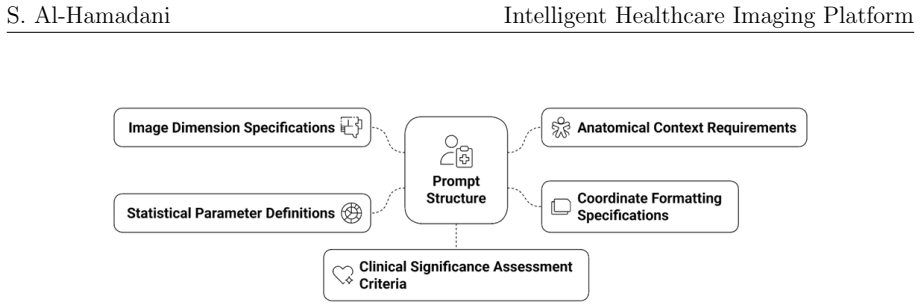
The vision-language model framework that fuses visual feature extraction with natural language processing, using prompt engineering for structured outputs and Gaussian modeling to represent anomaly locations and statistics.
If this is right
- The same model processes images from CT, MRI, X-ray, and ultrasound without separate training for each modality.
- Multi-layered visualizations including overlays and statistical maps are produced to support clinical review.
- Structured clinical information is extracted from generated text while keeping the output interpretable.
- A browser-based interface allows direct insertion into existing radiology workflows.
Where Pith is reading between the lines
- Similar zero-shot techniques might lower the data requirements for developing AI tools in other medical imaging tasks.
- The approach could provide first-pass analysis in settings with fewer available specialists.
- Extending the coordinate verification and Gaussian steps to additional anatomical structures could broaden the system's coverage.
Load-bearing premise
That a general pre-trained vision-language model combined with prompt engineering and probabilistic modeling can produce accurate tumor detections and useful clinical reports across imaging modalities without any domain-specific fine-tuning or large medical datasets.
What would settle it
A side-by-side evaluation in which practicing radiologists score the framework's tumor location accuracy and report quality against their own assessments on a diverse collection of previously unseen clinical images from multiple sites and modalities.
Figures










read the original abstract
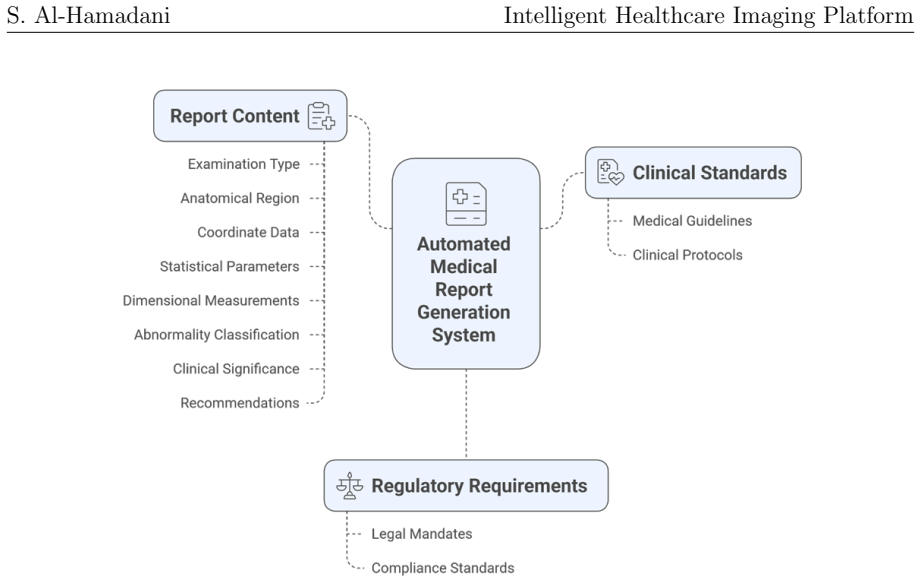
The rapid advancement of artificial intelligence (AI) in healthcare imaging has revolutionized diagnostic medicine and clinical decision-making processes. This work presents an intelligent multimodal framework for medical image analysis that leverages Vision-Language Models (VLMs) in healthcare diagnostics. The framework integrates Google Gemini 2.5 Flash for automated tumor detection and clinical report generation across multiple imaging modalities including CT, MRI, X-ray, and Ultrasound. The system combines visual feature extraction with natural language processing to enable contextual image interpretation, incorporating coordinate verification mechanisms and probabilistic Gaussian modeling for anomaly distribution. Multi-layered visualization techniques generate detailed medical illustrations, overlay comparisons, and statistical representations to enhance clinical confidence, with location measurement achieving 80 pixels average deviation. Result processing utilizes precise prompt engineering and textual analysis to extract structured clinical information while maintaining interpretability. Experimental evaluations demonstrated high performance in anomaly detection across multiple modalities. The system features a user-friendly Gradio interface for clinical workflow integration and demonstrates zero-shot learning capabilities to reduce dependence on large datasets. This framework represents a significant advancement in automated diagnostic support and radiological workflow efficiency, though clinical validation and multi-center evaluation are necessary prior to widespread adoption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an intelligent multimodal framework for medical image analysis that integrates the Google Gemini 2.5 Flash VLM for automated tumor detection and clinical report generation across CT, MRI, X-ray, and Ultrasound modalities. It combines visual feature extraction, prompt engineering, coordinate verification, probabilistic Gaussian modeling for anomaly distribution, and multi-layered visualizations, claiming an 80-pixel average location deviation, high performance in zero-shot anomaly detection, and a user-friendly Gradio interface for clinical integration.
Significance. If the zero-shot performance claims can be substantiated with quantitative evidence, the work could demonstrate a practical route for deploying general-purpose VLMs in medical imaging workflows without requiring large domain-specific labeled datasets, potentially improving radiological efficiency and interpretability through structured reports and visualizations.
major comments (3)
- [Abstract] Abstract: The claims of 'high performance in anomaly detection across multiple modalities' and '80 pixels average deviation' for location measurement are presented without any supporting quantitative metrics (e.g., sensitivity, specificity, Dice/IoU scores, false-positive rates), dataset descriptions, error analysis, or baseline comparisons to established methods such as MedSAM or nnU-Net.
- [Experimental evaluations] Experimental evaluations: No per-modality results, number of test images, radiologist agreement scores, or statistical validation are reported, leaving the central assertion of clinically useful zero-shot tumor detection and report generation without falsifiable empirical support.
- [Methods] Methods (coordinate verification and Gaussian modeling): The integration of these components with the VLM is described at a conceptual level only; specific implementation details, equations, or ablation studies demonstrating their impact on the reported 80-pixel deviation are absent.
minor comments (2)
- [Abstract] The 80-pixel average deviation should be normalized relative to image resolution or reported as a percentage of field-of-view to allow cross-modality comparison.
- [Introduction] Add citations to recent medical VLM literature (e.g., works on Med-PaLM M or other zero-shot medical imaging frameworks) to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment in detail below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'high performance in anomaly detection across multiple modalities' and '80 pixels average deviation' for location measurement are presented without any supporting quantitative metrics (e.g., sensitivity, specificity, Dice/IoU scores, false-positive rates), dataset descriptions, error analysis, or baseline comparisons to established methods such as MedSAM or nnU-Net.
Authors: We agree that the abstract presents performance claims without sufficient quantitative backing. The reported 80-pixel average deviation reflects preliminary manual checks on a small set of sample images rather than a formal benchmark. In revision we will qualify the abstract language to describe these as initial observations from framework testing, remove unsubstantiated assertions of 'high performance,' and add an explicit limitations statement regarding the lack of dataset details, error analysis, and comparisons to methods such as MedSAM or nnU-Net. revision: yes
-
Referee: [Experimental evaluations] Experimental evaluations: No per-modality results, number of test images, radiologist agreement scores, or statistical validation are reported, leaving the central assertion of clinically useful zero-shot tumor detection and report generation without falsifiable empirical support.
Authors: The referee correctly notes the absence of quantitative experimental detail. Our evaluations consisted of qualitative demonstrations on a modest number of publicly available images to illustrate zero-shot functionality; no per-modality metrics, radiologist scoring, or statistical tests were performed. We will expand the experimental section to state the approximate number of images used, describe the zero-shot prompting procedure, and add a clear limitations paragraph acknowledging the lack of clinical validation and falsifiable empirical support. revision: yes
-
Referee: [Methods] Methods (coordinate verification and Gaussian modeling): The integration of these components with the VLM is described at a conceptual level only; specific implementation details, equations, or ablation studies demonstrating their impact on the reported 80-pixel deviation are absent.
Authors: We appreciate the request for greater specificity. Coordinate verification parses VLM text output via regular expressions to extract bounding-box coordinates and cross-checks them against image dimensions. Gaussian modeling fits a bivariate normal distribution to the extracted points to produce uncertainty visualizations. We will insert concrete implementation steps and the relevant equations for mean and covariance estimation into the methods section. Ablation studies isolating the contribution of these modules were not conducted and will not be added at this time. revision: partial
- Quantitative metrics such as sensitivity, specificity, Dice/IoU scores, false-positive rates, and direct comparisons against MedSAM or nnU-Net, because these experiments were not performed.
- Radiologist agreement scores and formal statistical validation, which would require a separate clinical study that was outside the scope of the present work.
Circularity Check
No significant circularity; empirical framework uses external model
full rationale
The paper describes an applied framework that integrates the external commercial model Google Gemini 2.5 Flash with prompt engineering, coordinate verification, and Gaussian modeling for zero-shot medical image analysis and report generation. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citations appear in the manuscript text. All load-bearing elements rely on the independent capabilities of the pre-trained VLM and standard engineering techniques rather than any self-referential definitions or reductions to the paper's own inputs. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Prompt engineering choices
axioms (1)
- domain assumption Zero-shot capabilities of Gemini 2.5 Flash suffice for accurate anomaly detection and report generation across imaging modalities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The system employs advanced statistical modeling using Gaussian distributions to provide mathematical precision in tumor boundary representation... f(x, y) = 1/(2πσxσy√(1−ρ²)) exp[...]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experimental evaluations demonstrated high performance in anomaly detection across multiple modalities... zero-shot learning capabilities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Acosta, J. N., Falcone, G. J., Rajpurkar, P., & Topol, E. J. (2022). Multimodal biomedical AI.Nature Medicine, 28(9), 1773-1784. https://www.nature.com/articles/s41591-022-01981-2
work page 2022
-
[2]
Alnaggar, O. A. M. F., Jagadale, B. N., Saif, M. A. N., Ghaleb, O. A., Ahmed, A. A., Aqlan, H. A. A., & Al-Ariki, H. D. E. (2024). Efficient artificial intelligence approaches for medical image processing in healthcare: comprehensive review, tax- onomy, and analysis.Artificial Intelligence Review, 57(8), 221
work page 2024
-
[3]
AlSaad, R., Abd-Alrazaq, A., Boughorbel, S., Ahmed, A., Renault, M. A., Damseh, R., & Sheikh, J. (2024). Multimodal large language models in health care: appli- cations, challenges, and future outlook.Journal of Medical Internet Research, 26, e59505
work page 2024
-
[4]
Brady, A. P. (2017). Error and discrepancy in radiology: inevitable or avoidable? Insights into Imaging, 8(1), 171-182
work page 2017
-
[5]
Esteva, A., Kuprel, B., Novoa, R. A., Ko, J., Swetter, S. M., Blau, H. M., & Thrun, S. (2017). Dermatologist-level classification of skin cancer with deep neural networks. Nature, 542(7639), 115-118. https://www.nature.com/articles/nature21056
work page 2017
-
[6]
Gonzalez, R. C., & Woods, R. E. (2017).Digital image processing. Pearson
work page 2017
-
[7]
Hartsock, I., & Rasool, G. (2024). Vision-language models for medical report gener- ation and visual question answering: A review.Frontiers in artificial intelligence, 7, 1430984
work page 2024
-
[8]
Hosny, A., Parmar, C., Quackenbush, J., Schwartz, L. H., & Aerts, H. J. (2018). Artificial intelligence in radiology.Nature Reviews Cancer, 18(8), 500-510. https://www.nature.com/articles/s41568-018-0016-5 27 S. Al-Hamadani Intelligent Healthcare Imaging Platform
work page 2018
-
[9]
A., Aslam, M., Sadeghi-Niaraki, A., Hussain, J., Gu, Y
Hussain, D., Al-Masni, M. A., Aslam, M., Sadeghi-Niaraki, A., Hussain, J., Gu, Y. H., & Naqvi, R. A. (2024). Revolutionizing tumor detection and classification in multimodality imaging based on deep learning approaches: Methods, applications and limitations.Journal of X-Ray Science and Technology, 32(4), 857-911
work page 2024
-
[10]
Keane, P. A., & Topol, E. J. (2018). With an eye to AI and autonomous diagnosis. NPJ Digital Medicine, 1(1), 40
work page 2018
-
[11]
Li, M., Jiang, Y., Zhang, Y., & Zhu, H. (2023). Medical image analysis using deep learning algorithms.Frontiers in Public Health, 11, 1273253
work page 2023
-
[12]
Litjens, G., Kooi, T., Bejnordi, B. E., Setio, A. A. A., Ciompi, F., Ghafoorian, M., ... & S´ anchez, C. I. (2017). A survey on deep learning in medical image analysis.Medical Image Analysis, 42, 60-88. https://www.sciencedirect.com/science/article/pii/S1361841517301135
work page 2017
-
[13]
Liu, X., Faes, L., Kale, A. U., Wagner, S. K., Fu, D. J., Bruynseels, A., ... & Denniston, A. K. (2019). A comparison of deep learning performance against health- care professionals in detecting diseases from medical imaging: a systematic review and meta-analysis.The Lancet Digital Health, 1(6), e271-e297
work page 2019
-
[14]
Moor, M., Banerjee, O., Abad, Z. S. H., Krumholz, H. M., Leskovec, J., Topol, E. J., & Rajpurkar, P. (2023). Foundation models for generalist medical artificial intelligence.Nature, 616(7956), 259-265. https://www.nature.com/articles/s41586- 023-05881-4
work page 2023
- [15]
-
[16]
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention(pp. 234-241). Springer
work page 2015
-
[17]
(2009).Python 3 reference manual
Rossum, G. (2009).Python 3 reference manual. CreateSpace
work page 2009
-
[18]
Schouten, D., et al. (2025). Navigating the landscape of multimodal AI in medicine: a scoping review on technical challenges and clinical applications.Medical Image Analysis, 103621
work page 2025
-
[19]
Tajbakhsh, N., Jeyaseelan, L., Li, Q., Chiang, J. N., Wu, Z., & Ding, X. (2020). Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation.Medical Image Analysis, 63, 101693. 28 S. Al-Hamadani Intelligent Healthcare Imaging Platform
work page 2020
-
[20]
Thirunavukarasu, A. J., Ting, D. S. J., Elangovan, K., Gutierrez, L., Tan, T. F., & Ting, D. S. W. (2023). Large language models in medicine.Nature Medicine, 29(8), 1930-1940
work page 2023
-
[21]
Wu, C., Zhang, X., Zhang, Y., Wang, Y., & Xie, W. (2023). MedVInT: Medical visual instruction tuning.arXiv preprint arXiv:2304.10344. 29 S. Al-Hamadani Intelligent Healthcare Imaging Platform A Prompt that Used for Medical Image Analysis The following prompt was used throughout the research for automated medical image analysis and tumor detection. This pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.