V-SEAM: Visual Semantic Editing and Attention Modulating for Causal Interpretability of Vision-Language Models
Pith reviewed 2026-05-18 16:16 UTC · model grok-4.3
The pith
V-SEAM uses concept-level visual edits to identify attention heads that causally shape vision-language model predictions and modulates them to raise VQA accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
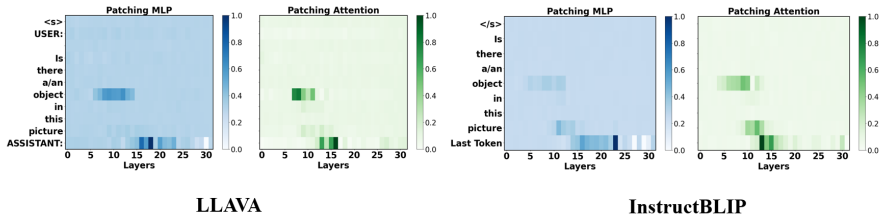
V-SEAM combines visual semantic editing with attention-head modulation to reveal that specific heads contribute positively or negatively to VLM predictions at three distinct semantic levels, with positive heads largely shared inside each level and negative heads generalizing across levels; automatic embedding modulation of the identified heads then improves performance on three VQA benchmarks for LLaVA and InstructBLIP.
What carries the argument
V-SEAM framework that performs concept-level visual semantic edits to intervene on inputs and then selects and modulates attention-head embeddings according to their measured positive or negative causal effect.
If this is right
- Positive attention heads are shared within each semantic level but differ across object, attribute, and relationship levels.
- Negative attention heads generalize across semantic levels rather than staying level-specific.
- Automatic modulation of the selected head embeddings raises accuracy on three separate VQA benchmarks for both LLaVA and InstructBLIP.
- The approach supplies a causal account of how multimodal integration occurs inside the attention layers.
Where Pith is reading between the lines
- The same editing-plus-modulation pipeline could be tested on additional VLMs beyond the two reported here to check consistency of head roles.
- If semantic levels are handled by partly distinct head groups, future architectures might explicitly route or regularize those groups to reduce cross-level interference.
- Causal head identification of this kind offers a route to targeted model editing that avoids retraining entire networks.
Load-bearing premise
The attention heads located by the semantic editing interventions are causally responsible for the observed predictions rather than merely correlated with them.
What would settle it
Modulating the identified heads produces no performance gain or introduces new errors on the three VQA benchmarks while leaving the original predictions unchanged under the same visual edits.
Figures













read the original abstract
Recent advances in causal interpretability have extended from language models to vision-language models (VLMs), seeking to reveal their internal mechanisms through input interventions. While textual interventions often target semantics, visual interventions typically rely on coarse pixel-level perturbations, limiting semantic insights on multimodal integration. In this study, we introduce V-SEAM, a novel framework that combines Visual Semantic Editing and Attention Modulating for causal interpretation of VLMs. V-SEAM enables concept-level visual manipulations and identifies attention heads with positive or negative contributions to predictions across three semantic levels: objects, attributes, and relationships. We observe that positive heads are often shared within the same semantic level but vary across levels, while negative heads tend to generalize broadly. Finally, we introduce an automatic method to modulate key head embeddings, demonstrating enhanced performance for both LLaVA and InstructBLIP across three diverse VQA benchmarks. Our data and code are released at: https://github.com/petergit1/V-SEAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces V-SEAM, a framework combining visual semantic editing at object, attribute, and relationship levels with attention-head modulation to probe causal mechanisms in vision-language models. It identifies heads with positive or negative contributions to predictions, reports patterns of head sharing within and across semantic levels, and claims that automatic modulation of selected heads improves VQA performance for LLaVA and InstructBLIP on three benchmarks.
Significance. If the causal claims are substantiated, the work would advance multimodal interpretability by moving beyond pixel-level perturbations to concept-level visual interventions and by linking identified heads to measurable performance gains. The public release of data and code is a clear strength that supports reproducibility and follow-up studies.
major comments (3)
- [§4] §4 (Head Identification via Semantic Edits): The claim that identified heads are causally responsible for predictions at each semantic level rests on the assumption that the visual edits isolate the targeted concept without introducing correlated pixel-level or cross-level changes. No ablation or control experiments (e.g., non-semantic visual perturbations or cross-level edit controls) are reported to rule out these confounds; this directly affects the validity of the positive/negative head attributions.
- [§5.2] §5.2 (Automatic Modulation and Benchmark Results): The modulation procedure re-uses heads selected from the same editing interventions that are later used to demonstrate performance gains. Without a held-out validation split or explicit non-causal control conditions (random heads, shuffled attributions), the reported improvements on the three VQA benchmarks may partly reflect selection bias rather than causal modulation, weakening the link between interpretability findings and performance claims.
- [§4.3] §4.3 (Head-Sharing Patterns): The observation that positive heads are shared within semantic levels but vary across levels lacks statistical controls for multiple comparisons or baseline comparisons against randomly selected heads; without these, the reported patterns could arise from noise or model idiosyncrasies rather than genuine semantic specialization.
minor comments (2)
- [Abstract] The abstract states results on 'three diverse VQA benchmarks' but does not name them; listing the specific datasets (e.g., VQAv2, GQA, OK-VQA) would improve immediate clarity.
- [§3] Notation for contribution scores (positive/negative head metrics) is introduced without an explicit equation; adding a short formal definition would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects for strengthening the causal claims in V-SEAM, and we address each point below with plans for revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Head Identification via Semantic Edits): The claim that identified heads are causally responsible for predictions at each semantic level rests on the assumption that the visual edits isolate the targeted concept without introducing correlated pixel-level or cross-level changes. No ablation or control experiments (e.g., non-semantic visual perturbations or cross-level edit controls) are reported to rule out these confounds; this directly affects the validity of the positive/negative head attributions.
Authors: We agree that explicit controls are needed to rule out potential confounds and fully support the causal attributions. Our semantic editing method targets specific concepts (objects, attributes, relationships) through precise, localized visual changes intended to isolate the relevant semantics while preserving other elements. However, to directly address this concern, we will add ablation experiments in the revised manuscript, including non-semantic perturbations (such as random pixel noise or unrelated edits) and cross-level edit controls. These will quantify whether the positive/negative head identifications are specific to the targeted semantic interventions. revision: yes
-
Referee: [§5.2] §5.2 (Automatic Modulation and Benchmark Results): The modulation procedure re-uses heads selected from the same editing interventions that are later used to demonstrate performance gains. Without a held-out validation split or explicit non-causal control conditions (random heads, shuffled attributions), the reported improvements on the three VQA benchmarks may partly reflect selection bias rather than causal modulation, weakening the link between interpretability findings and performance claims.
Authors: We acknowledge the potential selection bias arising from reusing the same interventions for both head selection and performance evaluation. In the revision, we will introduce a held-out validation split to separate head identification from the final modulation experiments. We will also add explicit control conditions using randomly selected heads and shuffled attributions. These additions will strengthen the evidence that the observed VQA improvements for LLaVA and InstructBLIP on the three benchmarks result from causal modulation of the identified heads rather than bias. revision: yes
-
Referee: [§4.3] §4.3 (Head-Sharing Patterns): The observation that positive heads are shared within semantic levels but vary across levels lacks statistical controls for multiple comparisons or baseline comparisons against randomly selected heads; without these, the reported patterns could arise from noise or model idiosyncrasies rather than genuine semantic specialization.
Authors: We will revise §4.3 to include rigorous statistical controls. This will involve applying corrections for multiple comparisons across the tested heads and semantic levels, as well as baseline comparisons against randomly sampled head sets of equivalent size. These analyses will help establish whether the observed within-level sharing and cross-level variation reflect genuine semantic specialization beyond what would be expected from noise or model-specific artifacts. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents V-SEAM as a sequential framework: visual semantic edits at object/attribute/relationship levels are used to measure changes in predictions and thereby identify positive/negative attention heads, followed by a separate automatic modulation step applied to those heads to report benchmark gains on VQA tasks. No equations or self-citations are shown that reduce the identification or modulation steps to a direct fit or re-use of the same quantities by construction. The performance claims rest on empirical application across models and benchmarks rather than a closed definitional loop, and the released code allows external verification independent of any internal fitting procedure described in the manuscript.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic edits at the concept level produce valid causal interventions that isolate contributions at object, attribute, and relationship levels.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
identifies attention heads with positive or negative contributions to predictions across three semantic levels: objects, attributes, and relationships... automatic method to modulate key head embeddings
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
activation patching... ∆ℓl_τ(x,˜z, y) = ˆℓl_τ(x,˜z, y) − ℓ(x,˜z, y)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Guillaume Alain and Yoshua Bengio. 2016. Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, and Iain Barr. 2022. Flamingo: a visual language model for few-shot learning. In Advances in Neural Information Processing Systems
work page 2022
-
[3]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S \"u nderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3674--3683
work page 2018
- [4]
-
[5]
Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, and Daniela Massiceti. 2024. https://openreview.net/forum?id=s63dtq0mwA Understanding information storage and transfer in multi-modal large language models . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
work page 2024
-
[6]
Yonatan Belinkov. 2022. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48(1):207--219
work page 2022
-
[7]
Gabriela Ben Melech Stan, Estelle Aflalo, Raanan Yehezkel Rohekar, Anahita Bhiwandiwalla, Shao-Yen Tseng, Matthew Lyle Olson, Yaniv Gurwicz, Chenfei Wu, Nan Duan, and Vasudev Lal. 2024. Lvlm-interpret: An interpretability tool for large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8182--8187
work page 2024
-
[8]
Blair Bilodeau, Natasha Jaques, Pang Wei Koh, and Been Kim. 2024. Impossibility theorems for feature attribution. Proceedings of the National Academy of Sciences, 121(2):e2304406120
work page 2024
- [9]
- [10]
-
[11]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2023. Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning. In Advances in Neural Information Processing Systems (NeurIPS) 36
work page 2023
- [13]
- [14]
-
[15]
Michal Golovanevsky, William Rudman, Vedant Palit, Carsten Eickhoff, and Ritambhara Singh. 2025. https://aclanthology.org/2025.naacl-long.571/ What do vlms notice? a mechanistic interpretability pipeline for gaussian-noise-free text-image corruption and evaluation . In Proceedings of the 2025 Conference of the North American Chapter of the Association for...
work page 2025
- [16]
- [17]
-
[18]
Drew A Hudson and Christopher D Manning. 2019. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700--6709
work page 2019
- [19]
-
[20]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, and 1 others. 2023. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015--4026
work page 2023
-
[21]
Philipp Koehn. 2004. Statistical significance tests for machine translation evaluation. In Proceedings of the 2004 conference on empirical methods in natural language processing, pages 388--395
work page 2004
-
[22]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and 1 others. 2024. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Junnan Li, Dongxu Li, Yixuan Xie, Yixuan Guo, Xiyang Dai, Jianfeng Gao, Jianwei Sang, and Lijuan Wang. 2023 a . Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning (ICML)
work page 2023
-
[24]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023 b . Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Zihao Lin, Samyadeep Basu, Mohammad Beigi, Varun Manjunatha, Ryan A Rossi, Zichao Wang, Yufan Zhou, Sriram Balasubramanian, Arman Zarei, Keivan Rezaei, and 1 others. 2025. A survey on mechanistic interpretability for multi-modal foundation models. arXiv preprint arXiv:2502.17516
-
[26]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296--26306
work page 2024
-
[27]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. Advances in neural information processing systems, 36:34892--34916
work page 2023
-
[28]
Y Liu, Y Zhang, and S Yeung-Levy. 2025. Mechanistic interpretability meets vision language models: Insights and limitations. In The Fourth Blogpost Track at ICLR 2025
work page 2025
-
[29]
Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. 2016. Hierarchical question-image co-attention for visual question answering. Advances in neural information processing systems, 29
work page 2016
-
[30]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359--17372
work page 2022
- [31]
-
[32]
Vedant Palit, Rohan Pandey, Aryaman Arora, and Paul Pu Liang. 2023. https://arxiv.org/abs/2308.14179 Towards vision-language mechanistic interpretability: A causal tracing tool for blip . In Proceedings of the ICCV Workshop on Computational Linguistics for Vision and Language (CLVL)
-
[33]
Ekta Sood, Fabian K \"o gel, Philipp M \"u ller, Dominike Thomas, Mihai B \^a ce, and Andreas Bulling. 2023. Multimodal integration of human-like attention in visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2648--2658
work page 2023
-
[34]
Student. 1908. The probable error of a mean. Biometrika, pages 1--25
work page 1908
-
[35]
Shimon Ullman. 1987. Visual routines. In Readings in computer vision, pages 298--328. Elsevier
work page 1987
-
[36]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. Investigating gender bias in language models using causal mediation analysis. Advances in neural information processing systems, 33:12388--12401
work page 2020
-
[37]
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Song XiXuan, and 1 others. 2024. Cogvlm: Visual expert for pretrained language models. Advances in Neural Information Processing Systems, 37:121475--121499
work page 2024
- [38]
-
[39]
Fred Zhang and Neel Nanda. 2023. Towards best practices of activation patching in language models: Metrics and methods. arXiv preprint arXiv:2309.16042
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. 2021. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5579--5588
work page 2021
-
[41]
Xiaofeng Zhang, Chen Shen, Xiaosong Yuan, Shaotian Yan, Liang Xie, Wenxiao Wang, Chaochen Gu, Hao Tang, and Jieping Ye. 2024. From redundancy to relevance: Enhancing explainability in multimodal large language models. arXiv e-prints, pages arXiv--2406
work page 2024
-
[42]
Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, and Mengnan Du. 2024. Explainability for large language models: A survey. ACM Transactions on Intelligent Systems and Technology, 15(2):1--38
work page 2024
-
[43]
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, and Qi Wu. 2024. Navgpt-2: Unleashing navigational reasoning capability for large vision-language models. In European Conference on Computer Vision, pages 260--278. Springer
work page 2024
-
[44]
Deyao Zhu, Xiangxin Zhou, Xiang Wang, Xiubo Geng, Fan Liu, and Jiashen Zhu. 2024. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen. 2024. A task is worth one word: Learning with task prompts for high-quality versatile image inpainting. In European Conference on Computer Vision, pages 195--211. Springer
work page 2024
-
[46]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[47]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.