SMARTER: A Data-efficient Framework to Improve Toxicity Detection with Explanation via Self-augmenting Large Language Models
Pith reviewed 2026-05-18 15:48 UTC · model grok-4.3
The pith
LLMs boost toxicity detection accuracy up to 13 percent by aligning on their own synthetic explanations for correct and incorrect labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
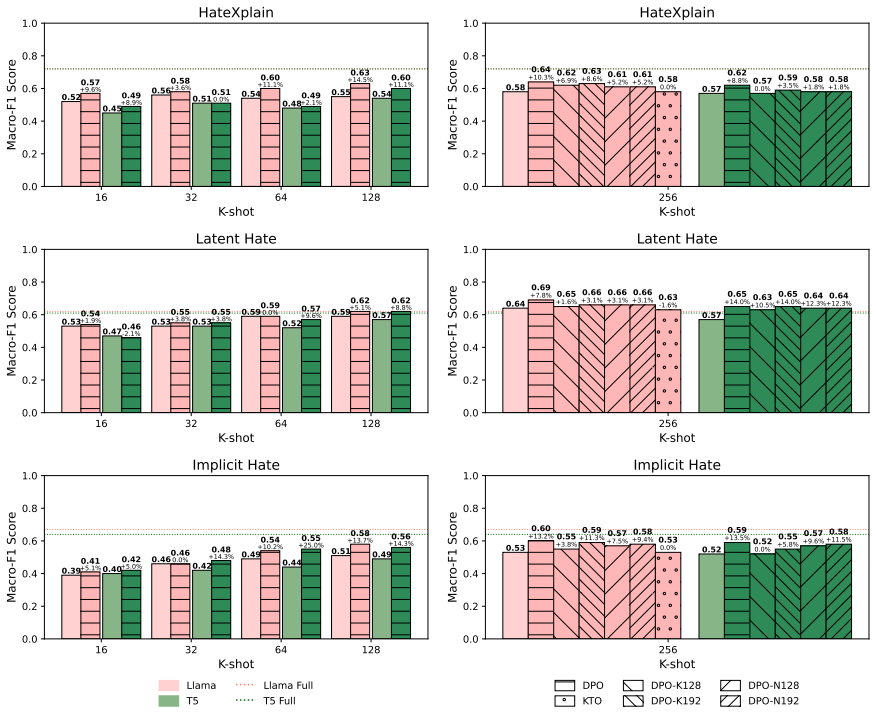
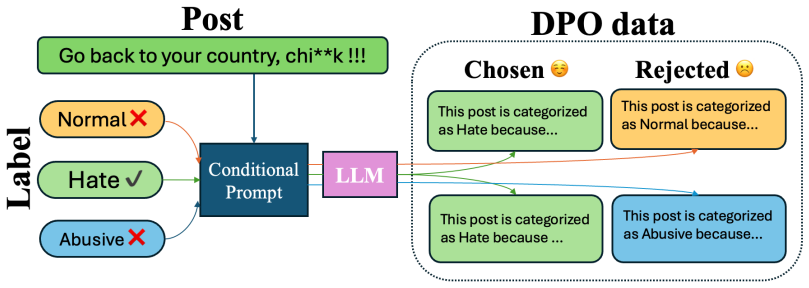
SMARTER is a data-efficient two-stage framework for explainable content moderation. In Stage 1, LLMs produce synthetic explanations for both correct and incorrect labels so that preference optimization can align the model toward higher-quality rationales with minimal human supervision. In Stage 2, cross-model training lets weaker models adopt the stylistic and semantic patterns of stronger models, simultaneously raising classification performance and explanation quality. Experiments on HateXplain, Latent Hate, and Implicit Hate show macro-F1 gains of up to 13 percent over standard few-shot baselines while using far less labeled data than full supervised training.
What carries the argument
Two-stage self-augmentation via preference optimization over LLM-generated explanations for both correct and incorrect predictions, followed by cross-model stylistic alignment.
If this is right
- Classification and explanation quality improve together rather than trading off.
- The method works with only a small fraction of the labeled data normally required.
- Weaker models can be upgraded by aligning to stronger models' explanation style.
- The same pipeline scales to other low-resource moderation settings without new human annotation.
- Both classification accuracy and human-interpretable rationales are produced by the same trained model.
Where Pith is reading between the lines
- The framework could be tested on non-English toxicity datasets to check whether self-augmentation reduces the need for native-speaker annotators.
- Preference optimization over self-generated labels might be combined with existing RLHF pipelines to improve safety guardrails more broadly.
- If explanation quality is measured by human raters after Stage 2, the cross-model alignment step may serve as a cheap proxy for human feedback.
- The approach suggests a general recipe for any classification task where both the label and a short justification are desired but labeled data are scarce.
Load-bearing premise
The synthetic explanations the LLM produces for both right and wrong labels are high enough quality and free enough of new bias that they can serve as reliable training signals.
What would settle it
Run the full SMARTER pipeline on one of the three benchmarks and measure whether adding the preference-optimization stage produces no gain or a loss in macro-F1 compared with the same base LLM trained only on the few-shot examples without any synthetic explanations.
Figures











read the original abstract
WARNING: This paper contains examples of offensive materials. To address the proliferation of toxic content on social media, we introduce SMARTER, we introduce SMARTER, a data-efficient two-stage framework for explainable content moderation using Large Language Models (LLMs). In Stage 1, we leverage LLMs' own outputs to generate synthetic explanations for both correct and incorrect labels, enabling alignment via preference optimization with minimal human supervision. In Stage 2, we refine explanation quality through cross-model training, allowing weaker models to align stylistically and semantically with stronger ones. Experiments on three benchmark tasks -- HateXplain, Latent Hate, and Implicit Hate -- demonstrate that SMARTER enables LLMs to achieve up to a 13% macro-F1 improvement over standard few-shot baselines while using only a fraction of the full training data. Our framework offers a scalable strategy for low-resource settings by harnessing LLMs' self-improving capabilities for both classification and explanation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SMARTER, a two-stage framework for data-efficient, explainable toxicity detection using LLMs. Stage 1 generates synthetic explanations for both correct and incorrect labels to enable preference optimization with minimal human supervision; Stage 2 refines explanation quality via cross-model training. Experiments on HateXplain, Latent Hate, and Implicit Hate benchmarks claim up to 13% macro-F1 gains over few-shot baselines while using only a fraction of the full training data.
Significance. If the empirical claims hold after proper validation, the work could offer a scalable approach to low-resource content moderation by leveraging LLM self-augmentation for both classification accuracy and explanation quality, addressing a practical need in subjective toxicity tasks.
major comments (3)
- [Abstract] Abstract: the reported 13% macro-F1 improvement is stated without any description of experimental setup, baseline definitions (e.g., exact few-shot prompting details), number of runs, statistical significance tests, or controls for bias introduced by synthetic data generation.
- [Stage 1] Stage 1 description: the framework relies on LLM-generated explanations for incorrect labels to form preference pairs, yet provides no explicit mechanism for fidelity checking, quality filtering, or human validation of these synthetic rationales; this is load-bearing for the central claim of net-positive self-improvement.
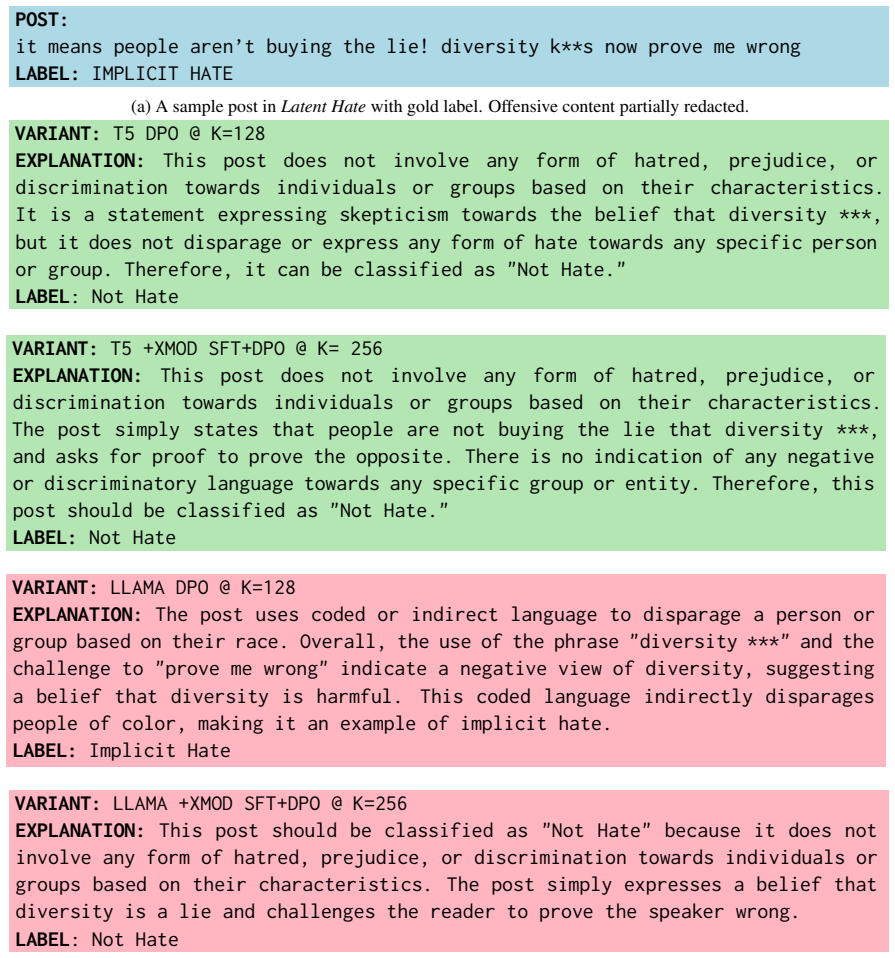
- [Experiments] Experiments section: in subjective tasks such as Implicit Hate and Latent Hate, the absence of analysis on whether synthetic explanations for incorrect labels amplify initial model biases or hallucinations undermines the interpretation of the reported gains as genuine self-improvement rather than optimization artifacts.
minor comments (1)
- [Abstract] Abstract contains a clear duplication: 'we introduce SMARTER, we introduce SMARTER'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating where we agree and the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 13% macro-F1 improvement is stated without any description of experimental setup, baseline definitions (e.g., exact few-shot prompting details), number of runs, statistical significance tests, or controls for bias introduced by synthetic data generation.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we have updated the abstract to briefly note that the reported gains are the maximum observed across the three benchmarks relative to standard few-shot prompting with the identical base LLM, that results are averaged over five independent runs, and that statistical significance was assessed via paired bootstrap tests. Detailed baseline prompting templates, run counts, and synthetic-data ablation controls are now explicitly referenced in the abstract and expanded in Section 4. revision: partial
-
Referee: [Stage 1] Stage 1 description: the framework relies on LLM-generated explanations for incorrect labels to form preference pairs, yet provides no explicit mechanism for fidelity checking, quality filtering, or human validation of these synthetic rationales; this is load-bearing for the central claim of net-positive self-improvement.
Authors: The referee rightly highlights that explicit safeguards are important for the self-improvement claim. While the original preference-optimization step implicitly down-weights low-quality rationales by contrasting them with correct-label explanations, we have added an automated fidelity filter in Stage 1 that uses a separate NLI model to discard explanations whose entailment score with the assigned label falls below a threshold. We report the filtering rate and include a small-scale human validation study in the appendix to substantiate that the retained synthetic data supports net-positive gains. revision: yes
-
Referee: [Experiments] Experiments section: in subjective tasks such as Implicit Hate and Latent Hate, the absence of analysis on whether synthetic explanations for incorrect labels amplify initial model biases or hallucinations undermines the interpretation of the reported gains as genuine self-improvement rather than optimization artifacts.
Authors: We concur that bias amplification is a legitimate concern in these subjective domains. In the revised experiments section we have added a targeted analysis that compares hallucination and bias indicators (measured by an independent verifier model) on synthetic explanations before and after SMARTER training. The results indicate that inconsistency rates do not increase and, in several cases, decrease, supporting that the observed macro-F1 gains reflect genuine improvement rather than artifacts. We discuss these findings and provide illustrative examples in the appendix. revision: yes
Circularity Check
No significant circularity: empirical framework evaluated on external benchmarks
full rationale
The paper presents SMARTER as a two-stage empirical method: LLM-generated synthetic explanations for preference optimization (Stage 1) followed by cross-model refinement (Stage 2). All performance claims (up to 13% macro-F1 gain) are direct measurements on public benchmarks (HateXplain, Latent Hate, Implicit Hate) against few-shot baselines using a fraction of training data. No equations, self-definitional quantities, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation. The central results remain externally falsifiable on standard datasets and do not reduce to the method's own outputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate synthetic explanations for both correct and incorrect toxicity labels that are useful for preference optimization.
Reference graph
Works this paper leans on
-
[1]
InThe 7th Workshop on Online Abuse and Harms (WOAH), pages 231–242
Robust hate speech detection in social me- dia: A cross-dataset empirical evaluation. InThe 7th Workshop on Online Abuse and Harms (WOAH), pages 231–242. Stephanie Alice Baker, Matthew Wade, and Michael James Walsh. 2020. <? covid19?> the challenges of responding to misinformation during a pandemic: content moderation and the limi- tations of the concept ...
work page 2020
-
[2]
A review of the f-measure: its history, prop- erties, criticism, and alternatives.ACM Computing Surveys, 56(3):1–24. Matteo Cinelli, Gianmarco De Francisci Morales, Alessandro Galeazzi, Walter Quattrociocchi, and Michele Starnini. 2021. The echo chamber effect on social media.Proceedings of the National Academy of Sciences, 118(9):e2023301118. Jacob Devli...
work page 2021
-
[3]
Bert and fasttext embeddings for automatic de- tection of toxic speech. In2020 International Multi- Conference on:“Organization of Knowledge and Ad- vanced Technologies”(OCTA), pages 1–5. IEEE. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. Th...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
How well do hate speech, toxicity, abusive and offensive language classification models gener- alize across datasets?Information Processing & Management, 58(3):102524. Katharine Gelber. 2021. Differentiating hate speech: a systemic discrimination approach.Critical Review of International Social and Political Philosophy. Feng Gu, Zongxia Li, Carlos Rafael ...
work page 2021
-
[5]
Large Language Models Are Effective Human Annotation Assistants, But Not Good Independent Annotators
Large language models are effective human annotation assistants, but not good independent an- notators.arXiv preprint arXiv:2503.06778. Shibo Hao, Yi Gu, Haotian Luo, Tianyang Liu, Xiyan Shao, Xinyuan Wang, Shuhua Xie, Haodi Ma, Adithya Samavedhi, Qiyue Gao, et al. Llm reasoners: New evaluation, library, and analysis of step-by-step reasoning with large l...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Synthetic data generation with large language models for text classification: Potential and limita- tions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10443–10461. Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. 2023. The flan c...
work page 2023
-
[7]
A decade of tweets: Visualizing racial senti- ments towards minoritized groups in the united states between 2011 and 2021.Epidemiology, 35(1):51–59. Tin Nguyen, Jiannan Xu, Aayushi Roy, Hal Daumé III, and Marine Carpuat. 2023. Towards conceptualiza- tion of “fair explanation”: Disparate impacts of anti- asian hate speech explanations on content moderators...
work page 2011
-
[8]
Melissa Kazemi Rad, Huy Nghiem, Andy Luo, Sahil Wadhwa, Mohammad Sorower, and Stephen Rawls
Training language models to follow instruc- tions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744. Melissa Kazemi Rad, Huy Nghiem, Andy Luo, Sahil Wadhwa, Mohammad Sorower, and Stephen Rawls
-
[9]
Refining input guardrails: Enhancing llm-as-a- judge efficiency through chain-of-thought fine-tuning and alignment.arXiv preprint arXiv:2501.13080. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn
-
[10]
Sarthak Roy, Ashish Harshvardhan, Animesh Mukher- jee, and Punyajoy Saha
Direct preference optimization: Your language model is secretly a reward model.Advances in Neu- ral Information Processing Systems, 36. Sarthak Roy, Ashish Harshvardhan, Animesh Mukher- jee, and Punyajoy Saha. 2023. Probing llms for hate speech detection: strengths and vulnerabilities. In Findings of the Association for Computational Lin- guistics: EMNLP ...
-
[11]
Large-scale hate speech detection with cross- domain transfer.arXiv preprint arXiv:2203.01111. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Al- isa Liu, Noah A Smith, Daniel Khashabi, and Han- naneh Hajishirzi. 2022. Self-instruct: Aligning lan- guage models with self-generated instructions.arXiv preprint arXiv:2212.10560. Benjamin Warner, Antoine Chaffin...
-
[12]
Tree of thoughts: Deliberate problem solving with large language models.Advances in Neural Information Processing Systems, 36. Zhixue Zhao, Ziqi Zhang, and Frank Hopfgartner. 2021. A comparative study of using pre-trained language models for toxic comment classification. InCompan- ion Proceedings of the Web Conference 2021, pages 500–507. Adam Zweiger, Jy...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.