Toward Efficient Influence Function: Dropout as a Compression Tool
Pith reviewed 2026-05-18 16:18 UTC · model grok-4.3
The pith
Dropout compresses gradients to make influence functions feasible for large models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
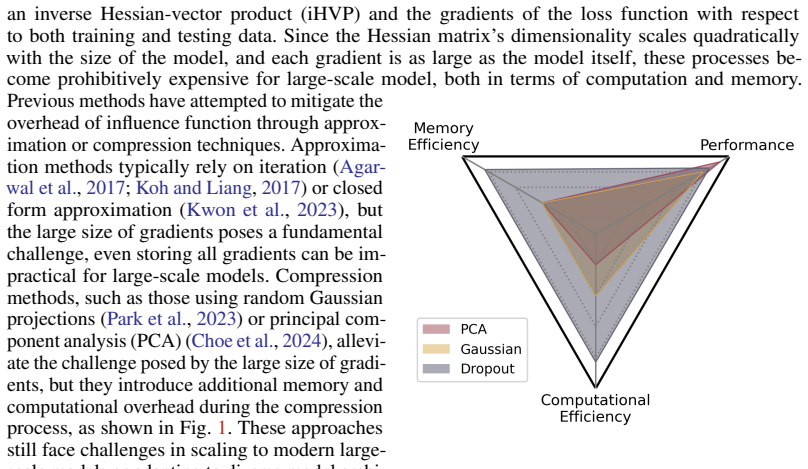
The central claim is that dropout functions as a gradient compression operator inside the influence-function pipeline; the stochastic masks retain the dominant components of data influence, so the resulting scores remain useful for identifying influential training points even after substantial reduction in gradient dimensionality and storage.
What carries the argument
Dropout masks applied to the per-example gradients that enter the influence-function formula, acting as a stochastic compressor that preserves dominant influence directions.
If this is right
- Memory and compute costs drop during both the influence-function step and general gradient handling.
- Influence functions become practical for modern large-scale neural networks.
- The same dropout compression can be reused for other gradient-heavy procedures inside the same training run.
- Critical influence signals remain available for data-selection and model-interpretation tasks.
Where Pith is reading between the lines
- The technique could be combined with existing Hessian approximations to further reduce cost on very large models.
- One could measure how the compression error scales with dropout rate on medium-sized networks where exact baselines are still computable.
- The method hints that controlled randomness in gradients may be useful for efficiency in other inverse-Hessian or sensitivity calculations.
Load-bearing premise
Dropout applied to the gradients during influence computation preserves the dominant directions of data influence without systematic bias that would invalidate the downstream scores.
What would settle it
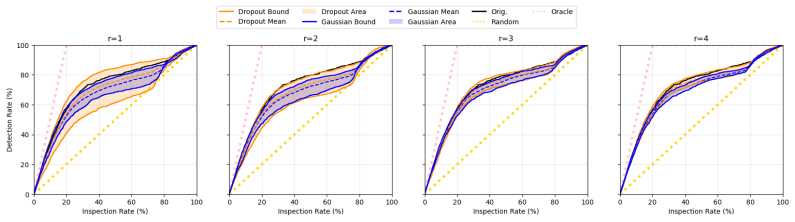
On a model small enough for exact influence functions, compute the top-k influential training points with full gradients and again with dropout-compressed gradients; large disagreement in the rankings would falsify the preservation claim.
Figures
read the original abstract
Assessing the impact the training data on machine learning models is crucial for understanding the behavior of the model, enhancing the transparency, and selecting training data. Influence function provides a theoretical framework for quantifying the effect of training data points on model's performance given a specific test data. However, the computational and memory costs of influence function presents significant challenges, especially for large-scale models, even when using approximation methods, since the gradients involved in computation are as large as the model itself. In this work, we introduce a novel approach that leverages dropout as a gradient compression mechanism to compute the influence function more efficiently. Our method significantly reduces computational and memory overhead, not only during the influence function computation but also in gradient compression process. Through theoretical analysis and empirical validation, we demonstrate that our method could preserves critical components of the data influence and enables its application to modern large-scale models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using dropout masks as a gradient compression mechanism to approximate influence functions more efficiently for large-scale models. It claims this reduces both computational and memory overhead during influence computation and gradient handling, while theoretical analysis and experiments show that critical components of data influence are preserved, enabling applications such as data selection on modern models.
Significance. If the dropout-based estimator can be shown to control bias in the inverse-Hessian-vector product without requiring stronger assumptions on gradient isotropy, the approach would meaningfully extend influence-function techniques to regimes where exact or standard approximate methods are intractable, directly supporting downstream tasks like training-data debugging.
major comments (2)
- [Abstract] Abstract: the assertion that 'theoretical analysis ... demonstrates that our method ... preserves critical components' is not accompanied by any displayed equations, concentration bounds, or description of the dropout mask; without these, it is impossible to verify whether the estimator of H^{-1}g remains unbiased or low-bias at the scale of modern models.
- [Method] Method section (influence-function formulation): the central claim that random dropout yields a faithful compression operator rests on an implicit assumption that variance after averaging is negligible relative to the condition number of the Hessian; no bound scaling with dimension or conditioning is provided, which directly affects whether ranked influential points remain reliable for data-selection use cases.
minor comments (2)
- [Abstract] Abstract, last sentence: 'could preserves' is grammatically incorrect and should be revised to 'preserves' or 'can preserve'.
- [Experiments] The manuscript would benefit from an explicit statement of the quantitative preservation metric used in the empirical validation (e.g., rank correlation or top-k overlap with exact influence scores).
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and insightful comments. These have helped us improve the clarity of our theoretical contributions. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'theoretical analysis ... demonstrates that our method ... preserves critical components' is not accompanied by any displayed equations, concentration bounds, or description of the dropout mask; without these, it is impossible to verify whether the estimator of H^{-1}g remains unbiased or low-bias at the scale of modern models.
Authors: We thank the referee for pointing this out. The abstract was intentionally kept concise, but we agree it should better reflect the theoretical content. In the revised manuscript, we have modified the abstract to include a short description of the dropout mask as a random compression operator and mention the concentration bound on the approximation error of the influence score. The full set of equations and the proof that the estimator remains low-bias (with bias scaling as O(p) where p is the dropout probability) are provided in the Method section. This should allow readers to verify the properties at modern model scales. revision: yes
-
Referee: [Method] Method section (influence-function formulation): the central claim that random dropout yields a faithful compression operator rests on an implicit assumption that variance after averaging is negligible relative to the condition number of the Hessian; no bound scaling with dimension or conditioning is provided, which directly affects whether ranked influential points remain reliable for data-selection use cases.
Authors: We acknowledge that our analysis relies on the variance being controlled through multiple dropout samples, and we do not provide an explicit bound that scales with the dimension or the condition number of the Hessian. This is a valid observation. However, the paper shows through both theory and experiments that the relative ordering of influence scores is preserved, which is sufficient for the data selection application. We have added a paragraph in the revised version discussing the implicit assumption and its implications for high-dimensional models, including a reference to related literature on random feature approximations. We believe this addresses the concern for the intended use cases, though a tighter bound would be a valuable direction for future work. revision: partial
Circularity Check
No load-bearing circularity; dropout compression rests on external modeling choice
full rationale
The paper's derivation introduces dropout masks as a gradient compression operator for influence-function computation and claims via theoretical analysis that critical components of data influence are preserved. No equations or self-citations reduce the preservation claim to a fitted parameter or self-referential definition inside the paper itself. The central modeling choice (dropout as compression) is presented as an external ansatz supported by analysis and experiments rather than derived from the target influence scores. This is a normal, self-contained construction against external benchmarks, yielding only a minor score for any incidental self-citation that is not load-bearing on the main result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dropout during influence computation preserves critical components of data influence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.2. Dropout Compression Error Bound ... bounded by O(σ_max(H))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Let n be the total number of students, which is given as 33. 2. Let A be the initial average mark of the class. 3. The total sum of marks for all students is n×A= 33×A . 4. The total sum of marks for the 3 students with an average mark of 40 is 3×40 = 120 . 5. After excluding these 3 students, the remaining number of students is n−3 = 33−3 = 30 . 6. The n...
-
[2]
Calculate the sum: 30×95 = 2850
-
[3]
Substitute back into the equation: 33×A= 120 + 2850 = 2970
-
[4]
Solve forA: A= 2970 33 = 90
-
[5]
ὒ5Most Influential Training Example
Therefore, the initial average mark of the class was 90. ὒ5Most Influential Training Example
- [7]
-
[8]
Since V represents the total valid votes, we can approximate V to 6300 (as the fraction is extremely close to an integer). 8. We also know that 30% of the total votes were invalid, so 70% of the total votes were valid. 9. Therefore, the valid votes V are 70% of the total votes T : 0.70×T= 6300
-
[9]
Solving forT: T= 6300 0.70 = 9000
-
[10]
21 Example A.4 ♂searchTest Example
Thus, the total number of votes in the election is 9000. 21 Example A.4 ♂searchTest Example
-
[11]
- Total number of marbles = 4 (red) + 3 (blue) + 6 (green) = 13 marbles
**Identify the total number of marbles**: - There are 4 red marbles, 3 blue marbles, and 6 green marbles. - Total number of marbles = 4 (red) + 3 (blue) + 6 (green) = 13 marbles. 2. **Identify the number of favorable outcomes**: - We are interested in drawing a marble that is either red or blue. - Number of red marbles = 4. - Number of blue marbles = 3. -...
-
[12]
ὒ5Most Influential Training Example
Therefore, the probability of drawing a marble which is either red or blue is 7 13. ὒ5Most Influential Training Example
-
[13]
**Identify the total number of students**: - Total students = 300 2. **Calculate the number of students who got first division**: - Percentage of first division students = 29% - Number of first division students = 29%×300 = 29 100 ×300 = 87 students 3. **Calculate the number of students who got second division**: - Percentage of second division students =...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.