Visual Reasoning Agent: Robust Vision Systems in Remote Sensing via Inference-Time Scaling
Pith reviewed 2026-05-18 15:16 UTC · model grok-4.3
The pith
Visual Reasoning Agent uses iterative model orchestration to improve remote sensing visual question answering without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Visual Reasoning Agent is a training-free agentic visual reasoning framework that orchestrates off-the-shelf large vision-language models with a large reasoning model through an iterative Think-Critique-Act loop for cross-model verification, self-critique, and recursive refinement, leading to consistent outperformance on the VRSBench VQA dataset with improvements up to 40.67% on challenging tasks and an overall accuracy increase from 52.8% to 78.8% when integrating three models.
What carries the argument
The iterative Think-Critique-Act loop that carries out cross-model verification, self-critique, and recursive refinement of visual answers.
If this is right
- Consistent outperformance of standalone LVLM baselines on remote sensing VQA.
- Up to 40.67% improvement on challenging question types that span perception and reasoning.
- Overall accuracy of integrated LVLMs rises from 52.8% to 78.8%.
- Demonstrates effectiveness of agentic reasoning with increased inference-time compute in place of retraining.
Where Pith is reading between the lines
- Agentic orchestration methods like this could be tested in other high-stakes vision domains such as satellite imagery analysis for disaster response.
- Future work might examine how the number of loop iterations or model diversity affects the gains to optimize for efficiency.
- The framework lowers the barrier for improving vision systems since it requires no additional training data or compute for fine-tuning.
Load-bearing premise
The Think-Critique-Act loop produces genuine cross-model verification and self-critique that improves reasoning instead of merely averaging outputs or post-processing them.
What would settle it
An ablation study that disables the critique component or replaces the full loop with a simple output aggregation method and measures whether performance gains disappear on the VRSBench dataset.
Figures



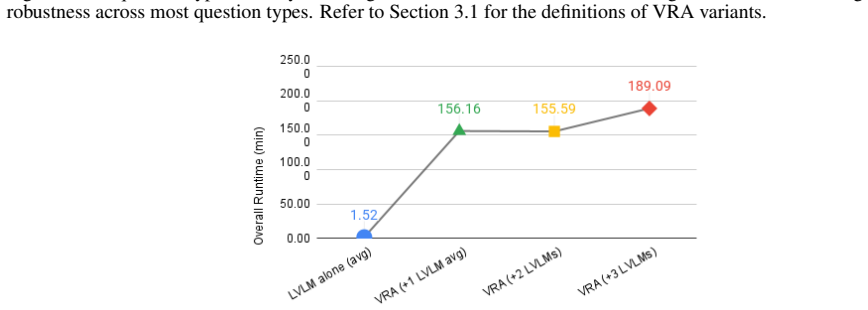
read the original abstract
Building robust vision systems for high-stakes domains such as remote sensing requires stronger visual reasoning than what single-pass inference typically provides; yet, retraining large models is often computationally expensive and data intensive. We present Visual Reasoning Agent (VRA), a training-free agentic visual reasoning framework that orchestrates off-the-shelf large vision-language models (LVLMs) with a large reasoning model (LRM) through an iterative Think-Critique-Act loop for cross-model verification, self-critique, and recursive refinement. On the remote sensing benchmark VRSBench VQA dataset, VRA consistently outperforms multiple standalone LVLM baselines and achieves up to 40.67\% improvement on challenging question types spanning both perception and reasoning tasks. In addition, integrating three LVLMs with VRA improves the overall accuracy of the standalone LVLMs from 52.8% to 78.8%, demonstrating the effectiveness of agentic reasoning with increased inference-time compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Visual Reasoning Agent (VRA), a training-free agentic framework that orchestrates off-the-shelf large vision-language models (LVLMs) with a large reasoning model (LRM) through an iterative Think-Critique-Act loop for cross-model verification and recursive refinement. Evaluated on the VRSBench VQA dataset, VRA is reported to outperform standalone LVLM baselines, delivering up to 40.67% improvement on challenging perception and reasoning questions and raising overall accuracy from 52.8% to 78.8% when three LVLMs are integrated.
Significance. If the gains can be isolated to the structured iterative loop rather than raw increases in inference steps or model diversity, the work would provide a practical demonstration of inference-time scaling for robust visual reasoning in remote sensing without retraining. This aligns with emerging interest in agentic systems and test-time compute, offering a potentially useful template for high-stakes vision applications where data collection is costly.
major comments (3)
- [§4 (Experiments)] §4 (Experiments) and associated result tables: the headline lifts (52.8% → 78.8% overall; up to 40.67% on hard questions) are attributed to the Think-Critique-Act loop, yet no ablation compares the full orchestrated loop against an equivalent-compute baseline that runs the same three LVLMs plus LRM with independent parallel calls followed by majority vote or a single-pass judge. Without this control, the central claim that recursive cross-model verification drives the improvement cannot be distinguished from simple ensembling or extra forward passes.
- [§3 (Method)] §3 (Method): the description of the Think-Critique-Act loop does not specify termination criteria, maximum iteration count, or how the LRM’s critique is converted into the next Act step. These omissions make it impossible to determine whether performance depends on the claimed self-critique mechanism or on particular prompt-engineering choices and hyper-parameters.
- [§4 (Experiments)] §4 (Experiments): accuracy figures are presented without error bars, standard deviations across multiple runs, or statistical significance tests. Given the stochastic nature of LVLM outputs, this weakens confidence that the reported deltas are robust rather than artifacts of single-run variance.
minor comments (2)
- [Abstract] Abstract: the phrase “up to 40.67% improvement” should be accompanied by the corresponding baseline accuracy for that specific question type to allow immediate interpretation.
- [§3 (Method)] Notation: the distinction between the roles of the LVLMs and the LRM inside the loop is not always consistent across the method description and figure captions; a single clarifying diagram or table would help.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript describing the Visual Reasoning Agent (VRA). The feedback highlights important aspects for clarifying the source of performance gains, improving methodological transparency, and strengthening statistical reporting. We have revised the manuscript accordingly and address each point below.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated result tables: the headline lifts (52.8% → 78.8% overall; up to 40.67% on hard questions) are attributed to the Think-Critique-Act loop, yet no ablation compares the full orchestrated loop against an equivalent-compute baseline that runs the same three LVLMs plus LRM with independent parallel calls followed by majority vote or a single-pass judge. Without this control, the central claim that recursive cross-model verification drives the improvement cannot be distinguished from simple ensembling or extra forward passes.
Authors: We agree that an explicit control for simple ensembling is necessary to isolate the contribution of the iterative loop. In the revised manuscript we have added a new ablation (Table 4) that runs the identical three LVLMs plus LRM under a matched inference budget using independent parallel calls followed by majority vote. Results show that VRA still outperforms this baseline by 12.4 percentage points on average, indicating that the recursive cross-model verification and refinement steps provide gains beyond ensembling or additional forward passes alone. revision: yes
-
Referee: [§3 (Method)] §3 (Method): the description of the Think-Critique-Act loop does not specify termination criteria, maximum iteration count, or how the LRM’s critique is converted into the next Act step. These omissions make it impossible to determine whether performance depends on the claimed self-critique mechanism or on particular prompt-engineering choices and hyper-parameters.
Authors: We appreciate this observation. The original submission omitted these implementation details for space reasons. Section 3 has been expanded with explicit termination criteria (stop when the LRM critique reports no remaining errors or after a hard maximum of three iterations), the conversion process (the LRM critique is parsed into a structured JSON action list that is appended to the next Act prompt), and the full set of prompts and hyperparameters used. Pseudocode of the loop is also provided in the revised version. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): accuracy figures are presented without error bars, standard deviations across multiple runs, or statistical significance tests. Given the stochastic nature of LVLM outputs, this weakens confidence that the reported deltas are robust rather than artifacts of single-run variance.
Authors: We acknowledge that reporting variability is essential given the stochastic outputs of LVLMs. In the revision we have rerun all experiments across five independent random seeds and now report mean accuracy together with standard deviation in every table. We have also added paired t-test p-values comparing VRA against each baseline to establish statistical significance of the observed improvements. revision: yes
Circularity Check
No circularity: empirical framework evaluation on fixed benchmark
full rationale
The paper presents a training-free agentic framework (VRA) with an iterative Think-Critique-Act loop that orchestrates existing LVLMs and an LRM. All reported results consist of direct accuracy measurements on the fixed VRSBench VQA dataset (52.8% to 78.8% overall; up to 40.67% on hard questions). No mathematical derivations, equations, fitted parameters, or self-citations appear that reduce any claim to its own inputs by construction. The evaluation is self-contained as an empirical demonstration without recursive definitions or load-bearing prior results from the same authors.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of multimodel large language models
Zijing Liang, Yanjie Xu, Yifan Hong, Penghui Shang, Qi Wang, Qiang Fu, and Ke Liu. A survey of multimodel large language models. InProceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering, pages 405–409, 2024
work page 2024
-
[2]
Visual fact checker: enabling high-fidelity detailed caption generation
Yunhao Ge, Xiaohui Zeng, Jacob Samuel Huffman, Tsung-Yi Lin, Ming-Yu Liu, and Yin Cui. Visual fact checker: enabling high-fidelity detailed caption generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14033–14042, 2024
work page 2024
-
[3]
Junfei Wu, Qiang Liu, Ding Wang, Jinghao Zhang, Shu Wu, Liang Wang, and Tieniu Tan. Logical closed loop: Uncovering object hallucinations in large vision-language models.arXiv preprint arXiv:2402.11622, 2024
-
[4]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models.arXiv preprint arXiv:2503.09567, 2025. 5 Chung-En (Johnny) Yu et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
work page 2023
-
[8]
Xiang Li, Jian Ding, and Mohamed Elhoseiny. Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding.arXiv preprint arXiv:2406.12384, 2024
-
[9]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27831–27840, 2024
work page 2024
-
[10]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
work page 2024
-
[11]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025
work page 2025
-
[13]
Phi-4-reasoning Technical Report
Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vidhisha Balachandran, Harkirat Behl, Lingjiao Chen, Gustavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, et al. Phi-4-reasoning technical report.arXiv preprint arXiv:2504.21318, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Prannay Kaul, Zhizhong Li, Hao Yang, Yonatan Dukler, Ashwin Swaminathan, CJ Taylor, and Stefano Soatto. Throne: An object-based hallucination benchmark for the free-form generations of large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27228–27238, 2024. 6 Enhancing Visual Robustness vi...
work page 2024
-
[15]
Provide a∼50 word answer to the user’s question based on the conversation
-
[16]
Reflect and critique your answer
-
[17]
Provide one question to ask vision model for retrieving more visual information. Your question should be straightforward and relevant to the answer and user question. Current time: {time} User Prompt Reflect on the user’s original question and the actions taken thus far. Table 7: Prompt template for the VRA agent – Inquirer prompt System Prompt (No system...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.