Multi-View Attention Multiple-Instance Learning Enhanced by LLM Reasoning for Cognitive Distortion Detection
Pith reviewed 2026-05-18 15:30 UTC · model grok-4.3
The pith
Decomposing utterances into emotion, logic, and behavior lets LLMs propose distortion instances with salience scores that a multi-view attention MIL model then classifies more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
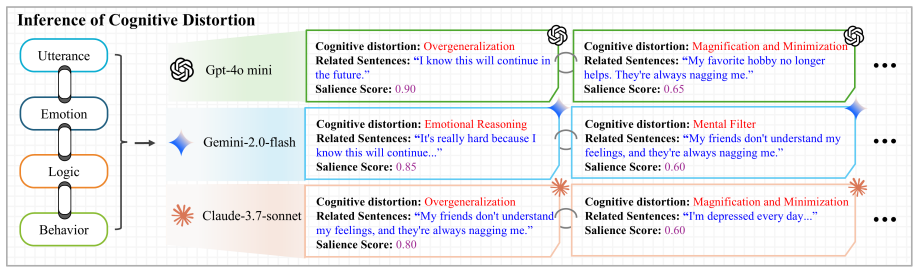
The central claim is that LLM reasoning over ELB-decomposed utterances produces multiple distortion instances carrying salience scores, and that feeding these instances into a Multi-View Gated Attention MIL architecture yields higher classification accuracy than baselines, especially on high-ambiguity distortions, as measured on the KoACD Korean and Therapist QA English datasets.
What carries the argument
The Multi-View Gated Attention mechanism that pools LLM-generated distortion instances, each carrying a salience score derived from Emotion-Logic-Behavior decomposition of the original utterance.
If this is right
- Classification performance rises when ELB decomposition and LLM-inferred salience scores are included in the MIL pipeline.
- Gains are largest for cognitive distortions that carry high interpretive ambiguity.
- The framework supplies expression-level reasoning that improves interpretability of the final classification.
- The same pipeline generalizes from Korean to English therapy dialogues without language-specific retraining.
Where Pith is reading between the lines
- The approach could be extended to live chat-based mental-health screening tools where quick, instance-level explanations matter.
- If the salience scores prove stable across different LLMs, the method might reduce dependence on large human-annotated corpora for similar mental-health NLP tasks.
- A natural next test would measure whether the model-assigned salience scores correlate with independent clinician ratings of distortion severity.
Load-bearing premise
The LLM-generated distortion instances and salience scores are accurate and psychologically valid enough to be used directly as inputs to the MIL classifier.
What would settle it
A side-by-side comparison in which human psychologists rate the same set of utterances and show low agreement with the LLM-proposed distortion types or salience rankings on a substantial fraction of cases would undermine the reliability of the generated inputs.
Figures


read the original abstract
Cognitive distortions have been closely linked to mental health disorders, yet their automatic detection remains challenging due to contextual ambiguity, co-occurrence, and semantic overlap. We propose a novel framework that combines Large Language Models (LLMs) with a Multiple-Instance Learning (MIL) architecture to enhance interpretability and expression-level reasoning. Each utterance is decomposed into Emotion, Logic, and Behavior (ELB) components, which are processed by LLMs to infer multiple distortion instances, each with a predicted type, expression, and model-assigned salience score. These instances are integrated via a Multi-View Gated Attention mechanism for final classification. Experiments on Korean (KoACD) and English (Therapist QA) datasets demonstrate that incorporating ELB and LLM-inferred salience scores improves classification performance, especially for distortions with high interpretive ambiguity. Our results suggest a psychologically grounded and generalizable approach for fine-grained reasoning in mental health NLP. The dataset and implementation details are publicly accessible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework combining Large Language Models (LLMs) with Multiple-Instance Learning (MIL) for cognitive distortion detection. Utterances are decomposed into Emotion, Logic, and Behavior (ELB) components; LLMs then infer multiple distortion instances each with a type, expression, and salience score. These are integrated via a Multi-View Gated Attention mechanism for final classification. Experiments on the Korean KoACD and English Therapist QA datasets claim performance improvements, especially for high-ambiguity distortions, with the dataset and code released publicly.
Significance. If the results hold after addressing validation gaps, the work could advance interpretable mental health NLP by grounding detection in psychologically motivated ELB decomposition and expression-level LLM reasoning. The public release of the dataset and implementation details is a clear strength supporting reproducibility.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and abstract: Performance gains are reported from ELB decomposition plus LLM-inferred salience scores, yet no statistical significance tests, detailed baseline descriptions, or error analysis are provided. This is load-bearing for the central claim that improvements are robust and especially pronounced for high-ambiguity distortions.
- [§3 (Method)] §3 (Method): The pipeline trains the MIL attention directly on LLM-generated distortion instances and salience scores without any reported human validation, inter-annotator agreement, or error rates on either KoACD or Therapist QA. This is load-bearing because the claim that these inputs improve classification for interpretive ambiguity rests on the unverified assumption that the LLM outputs are accurate psychological proxies rather than artifacts.
minor comments (1)
- [Abstract] Abstract: The phrase 'psychologically grounded' would benefit from a brief explicit link to established cognitive-behavioral frameworks to clarify the ELB alignment.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We appreciate the recognition of the framework's potential contribution to interpretable mental health NLP and the value of releasing the dataset and code. We address the two major comments below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: §4 (Experiments) and abstract: Performance gains are reported from ELB decomposition plus LLM-inferred salience scores, yet no statistical significance tests, detailed baseline descriptions, or error analysis are provided. This is load-bearing for the central claim that improvements are robust and especially pronounced for high-ambiguity distortions.
Authors: We agree that statistical significance testing, expanded baseline details, and error analysis are necessary to robustly support the central claims. In the revised manuscript we will add McNemar's tests (or bootstrap confidence intervals) comparing our full model against ablations and baselines on both KoACD and Therapist QA. We will expand the baseline descriptions to include exact architectures, training procedures, and hyperparameter choices. We will also insert a dedicated error analysis subsection that stratifies results by interpretive ambiguity level, highlighting cases where the multi-view attention and salience scores yield gains and where they do not. revision: yes
-
Referee: §3 (Method): The pipeline trains the MIL attention directly on LLM-generated distortion instances and salience scores without any reported human validation, inter-annotator agreement, or error rates on either KoACD or Therapist QA. This is load-bearing because the claim that these inputs improve classification for interpretive ambiguity rests on the unverified assumption that the LLM outputs are accurate psychological proxies rather than artifacts.
Authors: We acknowledge that the current manuscript does not report human validation of the LLM-generated ELB instances or salience scores. While the observed performance lift on held-out test sets provides indirect evidence of utility, we agree that direct verification would better ground the assumption that these outputs serve as reliable psychological proxies. In the revision we will add a human evaluation on a stratified sample of generated instances from both datasets, reporting inter-annotator agreement (Cohen's kappa) and error rates for distortion type, expression, and salience. We will also discuss potential LLM artifacts and how the gated attention mechanism is intended to down-weight unreliable instances. revision: yes
Circularity Check
No circularity in derivation chain; empirical results are independent of inputs
full rationale
The paper proposes an empirical pipeline that decomposes utterances into ELB components, uses LLMs to generate distortion instances and salience scores, and feeds them into a Multi-View Gated Attention MIL classifier. Central claims rest on reported classification improvements on the KoACD and Therapist QA datasets rather than any closed-form derivation, fitted parameter renamed as prediction, or self-citation that reduces the outcome to the input by construction. No equations or uniqueness theorems are invoked that would create self-definitional or load-bearing circularity. The framework is self-contained against external benchmarks via standard train/test evaluation, making this the normal non-circular finding for an applied ML paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM inferences on ELB components produce valid distortion instances and salience scores
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each utterance is decomposed into Emotion, Logic, and Behavior (ELB) components... integrated via a Multi-View Gated Attention mechanism
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MIL framework... bag of LLM-generated instances... salience score
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stuart Andrews, Ioannis Tsochantaridis, and Thomas Hofmann. 2002. Support vector machines for multiple-instance learning. In Advances in Neural Information Processing Systems, volume 15
work page 2002
-
[2]
Anthropic. 2025. https://www.anthropic.com/claude/sonnet Claude 3.7 sonnet
work page 2025
-
[3]
Aaron T. Beck. 1979. Cognitive therapy and the emotional disorders. Penguin
work page 1979
-
[4]
Zhiyu Chen, Yujie Lu, and William Yang Wang. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.284 Empowering psychotherapy with large language models: Cognitive distortion detection through diagnosis of thought prompting . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4295--4304, Singapore. Association for Computatio...
-
[5]
Thomas G. Dietterich, Richard H. Lathrop, and Tom \'a s Lozano-P \'e rez. 1997. https://doi.org/10.1016/S0004-3702(96)00034-3 Solving the multiple instance problem with axis-parallel rectangles . Artificial Intelligence, 89(1-2):31--71
-
[6]
Xiruo Ding, Kevin Lybarger, Justin Tauscher, and Trevor Cohen. 2022. https://doi.org/10.18653/v1/2022.naacl-srw.9 Improving classification of infrequent cognitive distortions: Domain-specific model vs. data augmentation . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Te...
-
[7]
Nada Elsharawi and Alia El Bolock. 2024. https://aclanthology.org/2024.lrec-main.286/ C-journal: A journaling application for detecting and classifying cognitive distortions using deep-learning based on a crowd-sourced dataset . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-...
work page 2024
-
[8]
Google DeepMind . 2024. https://deepmind.google/technologies/gemini/flash/ Gemini 2.0 flash
work page 2024
-
[9]
Maximilian Ilse, Jakub Tomczak, and Max Welling. 2018. Attention-based deep multiple instance learning. In Proceedings of the 35th International Conference on Machine Learning (ICML 2018), pages 2127--2136. PMLR
work page 2018
-
[10]
Zach Jorgensen, Yan Zhou, and Meador Inge. 2008. A multiple instance learning strategy for combating good word attacks on spam filters. Journal of Machine Learning Research, 9(6)
work page 2008
-
[11]
S.C. Kaplan, A.S. Morrison, P.R. Goldin, R.T. Olino, and J. Gross. 2017. https://doi.org/10.1007/s10608-017-9838-9 The cognitive distortions questionnaire (cd-quest): Validation in a sample of adults with social anxiety disorder . Cognitive Therapy and Research, 41:576--587
-
[12]
K \"u rsat Mustafa Karao g lan. 2024. https://doi.org/10.1016/j.neucom.2024.128263 Novel approaches for fake news detection based on attention-based deep multiple-instance learning using contextualized neural language models . Neurocomputing, 602:128263
- [13]
-
[14]
Dimitrios Kotzias, Misha Denil, Phil Blunsom, and Nando de Freitas. 2014. https://arxiv.org/abs/1411.3128 Deep multi-instance transfer learning . Preprint, arXiv:1411.3128
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Jiexi Liu, Dehan Kong, Longtao Huang, Dinghui Mao, and Hui Xue. 2022. https://doi.org/10.18653/v1/2022.findings-emnlp.546 Multiple instance learning for offensive language detection . In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 7387--7396, Abu Dhabi, UAE. Association for Computational Linguistics
-
[16]
Kevin Lybarger, Justin Tauscher, Xiruo Ding, Dror Ben-Zeev, and Trevor Cohen. 2022. https://doi.org/10.18653/v1/2022.clpsych-1.11 Identifying distorted thinking in patient-therapist text message exchanges by leveraging dynamic multi-turn context . In Proceedings of the Eighth Workshop on Computational Linguistics and Clinical Psychology, pages 126--136, S...
-
[17]
Oded Maron and Aparna Lakshmi Ratan. 1998. Multiple-instance learning for natural scene classification. In Proceedings of the 15th International Conference on Machine Learning (ICML 1998), pages 341--349
work page 1998
-
[18]
McGrath, Ali Al-Hamzawi, Jordi Alonso, Yasmin Altwaijri, Laura H
John J. McGrath, Ali Al-Hamzawi, Jordi Alonso, Yasmin Altwaijri, Laura H. Andrade, Evelyn J. Bromet, Ronny Bruffaerts, Jos \'e Miguel Caldas-de Almeida, Stephanie Chardoul, Wai Tat Chiu, Louisa Degenhardt, Olga V. Demler, Finola Ferry, Oye Gureje, Josep Maria Haro, Elie G. Karam, Georges Karam, Salma M. Khaled, Viviane Kovess-Masfety, and 40 others. 2023....
-
[19]
Nihan Mercan, Merve Bulut, and C i g dem Y \"u ksel. 2023. https://doi.org/10.1007/s12144-021-02251-z Investigation of the relatedness of cognitive distortions with emotional expression, anxiety, and depression . Current Psychology, 42:2176--2185
-
[20]
Amanda S. Morrison, Carrie M. Potter, Matthew M. Carper, Dina G. Kinner, Dane Jensen, Laura Bruce, Judy Wong, Irismar Reis de Oliveira, Donna M. Sudak, and Richard G. Heimberg. 2015. https://doi.org/10.1521/ijct.2015.8.4.287 The cognitive distortions questionnaire (cd-quest): Psychometric properties and exploratory factor analysis . International Journal ...
-
[21]
OpenAI . 2023. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Nikolaos Pappas and Andrei Popescu-Belis. 2014. https://doi.org/10.3115/v1/D14-1052 Explaining the stars: Weighted multiple-instance learning for aspect-based sentiment analysis . In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 455--466, Doha, Qatar. Association for Computational Linguistics
-
[23]
Hongzhi Qi, Qing Zhao, Jianqiang Li, Changwei Song, Wei Zhai, Dan Luo, Shuo Liu, Yi Jing Yu, Fan Wang, Huijing Zou, Bing Xiang Yang, and Guanghui Fu. 2023. https://doi.org/10.21203/rs.3.rs-3523508/v1 Supervised learning and large language model benchmarks on mental health datasets: Cognitive distortions and suicidal risks in chinese social media . Preprin...
-
[24]
Benjamin Shickel, Scott Siegel, Martin Heesacker, Sherry Benton, and Parisa Rashidi. 2020. https://doi.org/10.1109/BIBE50027.2020.00052 Automatic detection and classification of cognitive distortions in mental health text . In Proceedings of the 2020 IEEE 20th International Conference on Bioinformatics and Bioengineering (BIBE), pages 275--280. IEEE
-
[25]
Sagarika Shreevastava and Peter W. Foltz. 2021. https://doi.org/10.18653/v1/2021.clpsych-1.17 Detecting cognitive distortions from patient-therapist interactions . In Proceedings of the Seventh Workshop on Computational Linguistics and Clinical Psychology: Improving Access, pages 151--158. Association for Computational Linguistics
-
[26]
Taetem Simms, Christopher Ramstedt, Marc Rich, Matthew Richards, Thomas Martinez, and Christophe Giraud-Carrier. 2017. https://doi.org/10.1109/ICHI.2017.39 Detecting cognitive distortions through machine learning text analytics . In Proceedings of the 2017 IEEE International Conference on Healthcare Informatics (ICHI), pages 508--512. IEEE
-
[27]
Strohmeier, Brad Rosenfield, Robert A
Craig W. Strohmeier, Brad Rosenfield, Robert A. DiTomasso, and J. Russell Ramsay. 2016. https://doi.org/10.1016/j.psychres.2016.02.034 Assessment of the relationship between self-reported cognitive distortions and adult adhd, anxiety, depression, and hopelessness . Psychiatry Research, 238:153--158
-
[28]
I. Putu Gede Harsa Suputra, Linawati, Ni Putu Sastra, Gede Sukadarmika, Ni Kadek Anindya Saraswati, Diah Purwitasari Er, and I Made Agus Setiawan. 2023. https://doi.org/10.1109/ICSGTEIS60500.2023.10424225 Detection and classification of cognitive distortions: A literature review . In Proceedings of the 2023 International Conference on Smart-Green Technolo...
-
[29]
Tauscher, Kevin Lybarger, Xiruo Ding, Ayesha Chander, William J
Justin S. Tauscher, Kevin Lybarger, Xiruo Ding, Ayesha Chander, William J. Hudenko, Trevor Cohen, and Dror Ben-Zeev. 2023. https://doi.org/10.1176/appi.ps.202100692 Automated detection of cognitive distortions in text exchanges between clinicians and people with serious mental illness . Psychiatric Services, 74(4):407--410
-
[30]
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. 2021. https://doi.org/10.18653/v1/2021.findings-acl.188 Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2140--2151. Association for Computational Linguistics
-
[31]
World Health Organization . 2022. World mental health report: Transforming mental health for all
work page 2022
-
[32]
Qi Zhang, Sally A. Goldman, Wei Yu, and Jason E. Fritts. 2008. https://doi.org/10.1109/ICPR.2008.4761441 Em-dd: An improved multiple-instance learning algorithm . In Proceedings of the 19th IEEE International Conference on Pattern Recognition, pages 1--4. IEEE
-
[33]
Zhi Zhao, Yang Zhang, and Xindong Wu. 2017. Multiple instance learning via deep kernel embedding. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI 2017), pages 3442--3448. AAAI Press
work page 2017
-
[34]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[35]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.