Future Policy Approximation for Offline Reinforcement Learning Improves Mathematical Reasoning
Pith reviewed 2026-05-18 14:37 UTC · model grok-4.3
The pith
Future Policy Approximation improves offline RL for LLM mathematical reasoning by estimating future policies to reweight gradients proactively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
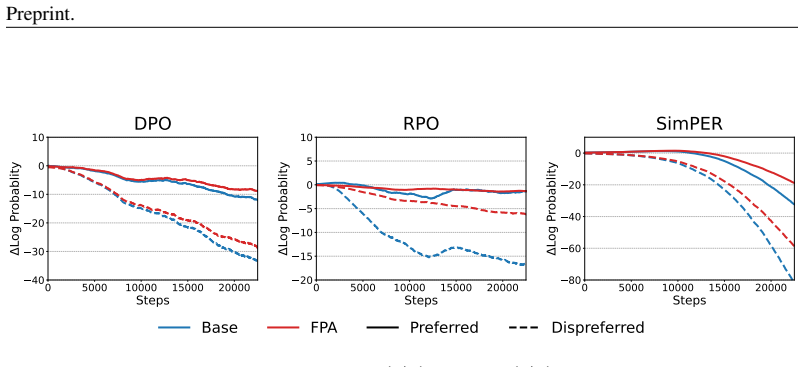
Future Policy Approximation estimates the future policy in logit space with negligible overhead and applies this estimate to reweight gradients in offline RL objectives. This change mitigates the suppression of correct tokens caused by substantial overlap with incorrect reasoning trajectories. Motivated by Optimistic Mirror Descent and linked to DPO, the method produces consistent gains over DPO, RPO, KTO, and vanilla offline RL while stabilizing long-horizon training and delivering accuracy comparable to online RLVR at a fraction of the GPU cost.
What carries the argument
Future Policy Approximation, which replaces current-policy gradient weighting with an estimate of the future policy obtained via logit-space extrapolation to enable proactive reweighting.
If this is right
- Accuracy improves consistently over DPO, RPO, KTO, and vanilla offline RL across three models and seven mathematical benchmarks.
- Training remains stable on long-horizon reasoning trajectories where standard offline objectives degrade.
- Accuracy reaches levels comparable to online RLVR while consuming only a small fraction of the GPU hours.
- The same method applies without modification to different model sizes and families.
Where Pith is reading between the lines
- The logit-extrapolation trick could be tested on other long-horizon tasks such as code generation or multi-step planning where token overlap is also high.
- Because the method connects to Optimistic Mirror Descent, similar future-policy estimates might improve other optimistic offline algorithms beyond the ones tested.
- A direct comparison of gradient statistics before and after FPA on held-out reasoning problems would show whether the reweighting actually reduces suppression of correct tokens.
Load-bearing premise
Logit-space extrapolation from the current policy produces an estimate accurate enough to reweight gradients usefully without introducing new biases that cancel the intended benefit.
What would settle it
A controlled training run on the same math benchmarks where applying the future-policy weighting produces the same sharp accuracy drop after many steps as vanilla offline RL, or where the extrapolated estimate leads to lower final performance than current-policy weighting.
Figures












read the original abstract
Reinforcement Learning (RL) has emerged as the key driver for post-training complex reasoning in Large Language Models (LLMs), yet online RL introduces significant instability and computational overhead. Offline RL offers a compelling alternative by decoupling inference from training; however, offline algorithms for reasoning remain under-optimized compared to their online counterparts. A central challenge is gradient entanglement: in long-horizon reasoning trajectories, correct and incorrect solutions share substantial token overlap, causing gradient updates from incorrect trajectories to suppress tokens critical for correct ones. We propose Future Policy Approximation (FPA), a simple method that weights gradients against an estimate of the future policy rather than the current one, enabling proactive gradient reweighting. This future policy is estimated via logit-space extrapolation with negligible overhead. We provide theoretical intuition for FPA through the lens of Optimistic Mirror Descent and further ground it through its connection to DPO. Evaluating FPA across three models and seven mathematical benchmarks, we demonstrate consistent improvements over strong offline baselines including DPO, RPO, KTO, and vanilla offline RL. FPA stabilizes long-horizon training where vanilla objectives degrade and achieves comparable accuracy to online RLVR at a fraction of its GPU hours.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Future Policy Approximation (FPA) as an offline RL method for improving mathematical reasoning in LLMs. It identifies gradient entanglement in long-horizon trajectories as a key issue where correct and incorrect solutions overlap in tokens, and addresses it by reweighting gradients using an estimate of the future policy obtained via simple logit-space extrapolation from the current policy. The approach is motivated by Optimistic Mirror Descent and linked to DPO, with empirical evaluation showing consistent gains over DPO, RPO, KTO, and vanilla offline RL across three models and seven benchmarks, plus stabilization of training and performance comparable to online RLVR at lower compute cost.
Significance. If the extrapolation step holds without introducing substantial bias, FPA provides a low-overhead mechanism to stabilize offline RL for complex, multi-step reasoning tasks where standard objectives degrade. The explicit grounding in Optimistic Mirror Descent and DPO connection supplies theoretical intuition, while the reported gains across multiple models and benchmarks indicate potential practical utility for reducing reliance on unstable online RL methods.
major comments (2)
- The central claim depends on the logit-space extrapolation yielding a sufficiently accurate proxy for the future policy to enable effective proactive reweighting without new errors. No direct validation is provided, such as measuring divergence (KL or total variation) between the extrapolated policy and the policy obtained after one or more actual gradient steps on the same batch. This is load-bearing for mathematical reasoning, where small policy changes can reroute entire solution trajectories.
- Experiments section: results report consistent improvements but omit error bars across runs, detailed ablations isolating the extrapolation component from other design choices, and step-by-step derivation of how the Optimistic Mirror Descent intuition translates into the specific logit extrapolation formula.
minor comments (2)
- Clarify the precise form of the logit extrapolation (e.g., linear coefficient, any clipping or normalization) and whether it introduces free parameters beyond those already present in the base offline objective.
- Add a short discussion of potential failure modes when the current policy is far from convergence, as linear extrapolation may diverge more severely in that regime.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional validation and experimental details will strengthen the paper and outline our planned revisions below.
read point-by-point responses
-
Referee: The central claim depends on the logit-space extrapolation yielding a sufficiently accurate proxy for the future policy to enable effective proactive reweighting without new errors. No direct validation is provided, such as measuring divergence (KL or total variation) between the extrapolated policy and the policy obtained after one or more actual gradient steps on the same batch. This is load-bearing for mathematical reasoning, where small policy changes can reroute entire solution trajectories.
Authors: We agree that direct validation of the extrapolation accuracy is important for supporting the central claim. In the revised manuscript we will add a new analysis that measures KL divergence and total variation distance between the logit-extrapolated policy and the policy obtained after one or more actual gradient steps on held-out batches from the same training distribution. We will report these metrics across the three models and multiple benchmarks to quantify how closely the simple extrapolation approximates the updated policy. revision: yes
-
Referee: Experiments section: results report consistent improvements but omit error bars across runs, detailed ablations isolating the extrapolation component from other design choices, and step-by-step derivation of how the Optimistic Mirror Descent intuition translates into the specific logit extrapolation formula.
Authors: We accept these suggestions for improving experimental rigor and theoretical clarity. The revised version will include error bars (mean and standard deviation) computed over at least three independent random seeds for all main results. We will add targeted ablations that isolate the extrapolation step by comparing FPA against an otherwise identical objective that uses the current policy for reweighting. We will also expand the theoretical section with a step-by-step derivation that starts from the Optimistic Mirror Descent update and arrives at the specific logit-space extrapolation formula employed by FPA. revision: yes
Circularity Check
No significant circularity; extrapolation step is independent of DPO fit
full rationale
The paper grounds FPA via Optimistic Mirror Descent intuition and an explicit connection to DPO, but the central logit-space extrapolation for the future policy is introduced as a distinct mechanism with its own formula. No equations reduce the claimed future-policy target to a quantity already fitted inside the DPO loss or to any self-citation chain. The method is evaluated against DPO and other baselines as an improvement, confirming the derivation remains self-contained against external benchmarks. No self-definitional, fitted-input-renamed-as-prediction, or load-bearing self-citation patterns appear in the provided derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Logit-space extrapolation from the current policy provides a usable estimate of the future policy for gradient reweighting.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Future policy estimated via lightweight logit-space extrapolation: ˆπθ = softmax((1+λ)hθ − λhref) (Eq. 5); applied inside coefficients Cw(ˆπθ), Cl(ˆπθ) with stop-gradient (Eq. 6)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Training dynamics driven by ∇θ log πθ(y|x) and algorithm-specific coefficients C(πθ) (Eq. 1); regularization reactive until probability drops
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.20. URL https://aclanthology.org/2024.emnlp-main.20/. Dongyoung Kim, Kimin Lee, Jinwoo Shin, and Jaehyung Kim. Spread preference annotation: Di- rect preference judgment for efficient LLM alignment. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main.20 2024
-
[2]
URLhttps://arxiv.org/abs/2406.18629. Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brah- man, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024. URL https://arxiv.org/abs/2411.15124. Aitor Lewkowycz,...
-
[3]
URLhttps://aclanthology.org/ P11-1015/
Association for Computational Linguistics. URLhttps://aclanthology.org/ P11-1015/. Xin Mao, Huimin Xu, Feng-Lin Li, Ziqi Jin, W ANG CHEN, Wei Zhang, and Anh Tuan Luu. As simple as fine-tuning: LLM alignment via bidirectional negative feedback loss. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview. net/foru...
work page 2025
-
[4]
URLhttps://proceedings.neurips.cc/paper_files/paper/2024/ file/e099c1c9699814af0be873a175361713-Paper-Conference.pdf. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kel- ton, Luke Miller, Maddie Simens, Amanda Askell, Peter W...
work page 2024
-
[5]
Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/ file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf. Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with dpo-positive.arXiv preprint arXiv:2402.13228, 2024. URLhttps://arxiv.org/abs/2402.13228....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
URLhttps://proceedings.neurips.cc/paper_files/paper/2024/ file/d37c9ad425fe5b65304d500c6edcba00-Paper-Conference.pdf. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Da...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/ file/a85b405ed65c6477a4fe8302b5e06ce7-Paper-Conference.pdf. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.033...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Teng Xiao, Yige Yuan, Huaisheng Zhu, Mingxiao Li, and Vasant G Honavar
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/ file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf. Teng Xiao, Yige Yuan, Huaisheng Zhu, Mingxiao Li, and Vasant G Honavar. Cal-dpo: Calibrated direct preference optimization for language model alignment. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (...
work page 2022
-
[9]
Teng Xiao, Yige Yuan, Zhengyu Chen, Mingxiao Li, Shangsong Liang, Zhaochun Ren, and Vasant G Honavar
URLhttps://proceedings.neurips.cc/paper_files/paper/2024/ file/cf8b2205e39f81726a8d828ecbe00ad0-Paper-Conference.pdf. Teng Xiao, Yige Yuan, Zhengyu Chen, Mingxiao Li, Shangsong Liang, Zhaochun Ren, and Vasant G Honavar. SimPER: A minimalist approach to preference alignment without hyperparameters. In The Thirteenth International Conference on Learning Rep...
work page 2024
-
[10]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
URLhttps://proceedings.mlr.press/v235/xu24h.html. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2.5-math technical report: Toward math- ematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024. URL https://arxiv.org/abs/2409.12122. Hui Yuan, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Group Sequence Policy Optimization
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/ file/639a9a172c044fbb64175b5fad42e9a5-Paper-Conference.pdf. Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. URLhttps://arxiv.org/pdf/2507.18071. 13 Pr...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
As Gheshlaghi Azar et al. (2024) and Fisch et al. (2025) show, deterministic preferences require r∗(yw)−r ∗(yl)→ ∞in the Bradley-Terry model, forcingπ θ∗(yl |x) = 0regardless of the KL regularization strengthβ. Since mathematical reasoning trajectories often share a large num- ber of common tokens between preferred and dispreferred sequences, this over-pe...
work page 2024
-
[13]
I hope it is correct. Problem:{Problem} Solution: Figure 12: 4-shot Prompt used for MATH in DeepSeekMath-7B(Lewkowycz et al., 2022) 22 Preprint. Problem: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now? Solution: Shawn started with 5 toys. He received 2 toys from his mom and 2 toys from his dad...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.