Knowing When to Defer: Selective Prediction for Responsible Knowledge Tracing
Pith reviewed 2026-05-18 13:48 UTC · model grok-4.3
The pith
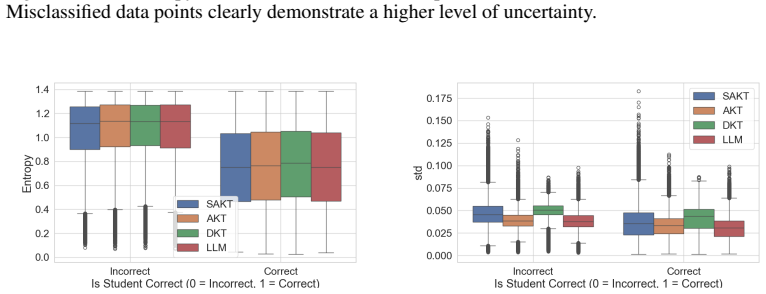
Knowledge tracing models improve accuracy by abstaining on their most uncertain predictions using Monte Carlo Dropout.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adding an intrinsic selective-prediction layer via Monte Carlo Dropout to standard KT architectures allows abstention on the 20 percent most uncertain predictions, which lifts accuracy 2.3–3.0 points and AUC 1.9–2.4 points while the deferred set shows 1.45–1.60 times the error rate of the kept set. This performance gain holds inside every question-difficulty quartile and across student-ability strata. A BALD variance decomposition demonstrates that the entire classical psychometric stack (question difficulty, student ability, IRT outcome ambiguity, curriculum coverage) accounts for less than 4 percent linearly and at most 23 percent non-linearly of the uncertainty, leaving 77–90 percent as a
What carries the argument
Monte Carlo Dropout variance used as a model-native epistemic-uncertainty signal to drive selective abstention in knowledge tracing models.
If this is right
- Abstaining on the 20 percent most uncertain predictions improves accuracy, AUC, and F1 without retraining across DKT, SAKT, and AKT.
- The deferred predictions exhibit 1.45–1.60 times the error rate of kept predictions inside every question-difficulty quartile.
- MC-Dropout variance supplies roughly five times the AUC lift of a calibrated 2PL IRT baseline as a selective signal.
- Classical psychometric factors explain at most 23 percent of the epistemic-uncertainty signal even under non-linear regression.
- Selective prediction with model-native uncertainty complements subgroup-fairness audits and classroom evaluation for responsible KT deployment.
Where Pith is reading between the lines
- The same uncertainty layer could be added to other deep KT variants to test whether architecture-specific epistemic content is a general feature.
- Real-time uncertainty estimates might be paired with teacher feedback to adapt models faster than batch retraining alone.
- The unexplained portion of uncertainty could be examined for correlation with specific misconceptions or curriculum gaps not captured by IRT.
- Production systems would need to weigh the added compute cost of MC-Dropout against the observed accuracy gains in live classroom use.
Load-bearing premise
That Monte Carlo Dropout variance reliably isolates epistemic uncertainty in these KT architectures and that the 20 percent abstention threshold produces gains that generalize beyond the Eedi dataset and the three tested models.
What would settle it
Repeating the selective-prediction experiment on a new KT dataset or additional model architectures and observing no accuracy lift or that an IRT baseline explains most of the uncertainty signal would falsify the central claim.
Figures




read the original abstract
Research on Knowledge Tracing (KT) models traditionally focuses on improving predictive accuracy. However, responsible real-world deployment requires models to know when to defer uncertain predictions to a human teacher. We introduce an intrinsic selective prediction layer for existing KT models using Monte Carlo Dropout (MC-Dropout) to quantify uncertainty. We evaluate this approach across three architectures (DKT, SAKT, and AKT) using the Eedi mathematics dataset. Abstaining on the 20\% most uncertain predictions lifts accuracy by 2.3 to 3.0 percentage points, AUC by 1.9 to 2.4 percentage points and F1 by 1.4 to 4.3 percentage points without any retraining. This abstention strategy is highly targeted: the deferred set exhibits 1.45 to 1.60 times the error rate of the kept set. Furthermore, this targeting holds within every question-difficulty quartile and remains fair across student-ability levels. Importantly, MC-Dropout variance gives roughly five times the AUC lift of a calibrated two-parameter logistic (2PL) Item Response Theory (IRT) baseline as a selective-prediction signal. A variance decomposition of the model's epistemic uncertainty (BALD) reveals that the entire classical psychometric stack, comprising question difficulty, student ability, IRT-style outcome ambiguity, and historical curriculum coverage, explains less than 4\% of the signal under linear modeling and at most 23\% even with a non-linear regressor. This leaves 77\% to 90\% as architecture-specific epistemic content that MC-Dropout surfaces and simpler proxies cannot recover. Selective prediction with model-native epistemic uncertainty is therefore a necessary component of responsible KT deployment, complementary to subgroup-fairness audits and downstream classroom evaluation rather than a substitute for them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an intrinsic selective-prediction mechanism for Knowledge Tracing (KT) models by applying Monte Carlo Dropout to estimate epistemic uncertainty in DKT, SAKT, and AKT architectures. On the Eedi mathematics dataset, abstaining on the top 20% most uncertain predictions yields accuracy gains of 2.3–3.0 pp, AUC gains of 1.9–2.4 pp, and F1 gains of 1.4–4.3 pp. The deferred predictions exhibit 1.45–1.60× higher error rates than retained ones, with the pattern holding across difficulty quartiles and student-ability levels. A BALD variance decomposition shows that a psychometric feature stack (question difficulty, student ability, IRT ambiguity, curriculum coverage) explains at most 23% of the uncertainty signal, leaving 77–90% as architecture-specific content; MC-Dropout uncertainty also delivers roughly 5× the AUC lift of a calibrated 2PL IRT baseline for selective prediction.
Significance. If the MC-Dropout procedure reliably isolates epistemic uncertainty, the work demonstrates that standard KT architectures contain substantial model-native uncertainty not recoverable from classical psychometric proxies. The targeted abstention results, cross-architecture consistency, and within-subgroup fairness checks provide concrete evidence that selective prediction can improve deployment safety without retraining. The explicit comparison to 2PL IRT and the low explanatory power of the psychometric regressors are strengths that make the necessity argument falsifiable and reproducible in principle.
major comments (3)
- [§3] §3 (Method), MC-Dropout implementation: the description does not state the number of Monte Carlo samples, the dropout probability, or the precise layers at which dropout is inserted (particularly the recurrent connections in DKT). Because the central claim that 77–90% of the uncertainty is architecture-specific epistemic content rests on BALD variance being a faithful epistemic signal, these missing parameters are load-bearing for both the decomposition and the reported selective-prediction lifts.
- [Results] Results section (performance tables and IRT comparison): the accuracy, AUC, and F1 improvements and the claimed 5× AUC advantage over 2PL IRT are reported without error bars, bootstrap intervals, or statistical significance tests. Given that the necessity argument for model-native uncertainty depends on these gains being reliable and larger than the IRT baseline, the absence of uncertainty quantification weakens the strength of the empirical support.
- [Results] Variance decomposition paragraph: the linear and non-linear regressors are said to use “question difficulty, student ability, IRT-style outcome ambiguity, and historical curriculum coverage,” yet the exact feature definitions, how IRT parameters are estimated on the same data, and the non-linear model architecture are not specified. If the feature set is incomplete or collinear with the KT inputs, the reported 77–90% unexplained variance could be inflated, directly affecting the claim that simpler proxies cannot recover the signal.
minor comments (2)
- [Abstract] Abstract and §4: the 20% abstention threshold is presented as fixed; a brief sensitivity analysis or justification for this operating point would clarify robustness.
- [§4] The manuscript states that the approach requires “no retraining,” which is a practical strength; confirming that no auxiliary fine-tuning or calibration was performed on the uncertainty head would remove any ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity, reproducibility, and empirical rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method), MC-Dropout implementation: the description does not state the number of Monte Carlo samples, the dropout probability, or the precise layers at which dropout is inserted (particularly the recurrent connections in DKT). Because the central claim that 77–90% of the uncertainty is architecture-specific epistemic content rests on BALD variance being a faithful epistemic signal, these missing parameters are load-bearing for both the decomposition and the reported selective-prediction lifts.
Authors: We agree that these implementation details are necessary for full reproducibility and to substantiate the epistemic interpretation of the BALD signal. In the revised manuscript we will add the missing specifications: 10 Monte Carlo forward passes, a dropout probability of 0.1, and explicit layer placement (including dropout on the recurrent connections of DKT as well as the corresponding layers in SAKT and AKT). revision: yes
-
Referee: [Results] Results section (performance tables and IRT comparison): the accuracy, AUC, and F1 improvements and the claimed 5× AUC advantage over 2PL IRT are reported without error bars, bootstrap intervals, or statistical significance tests. Given that the necessity argument for model-native uncertainty depends on these gains being reliable and larger than the IRT baseline, the absence of uncertainty quantification weakens the strength of the empirical support.
Authors: We acknowledge the absence of uncertainty quantification in the current results. We will recompute all reported metrics using bootstrap resampling (1,000 iterations) to include 95% confidence intervals and will add paired significance tests comparing the selective-prediction gains against the 2PL IRT baseline. These additions will appear in the revised tables and accompanying text. revision: yes
-
Referee: [Results] Variance decomposition paragraph: the linear and non-linear regressors are said to use “question difficulty, student ability, IRT-style outcome ambiguity, and historical curriculum coverage,” yet the exact feature definitions, how IRT parameters are estimated on the same data, and the non-linear model architecture are not specified. If the feature set is incomplete or collinear with the KT inputs, the reported 77–90% unexplained variance could be inflated, directly affecting the claim that simpler proxies cannot recover the signal.
Authors: We agree that precise feature definitions and model specifications are required to support the variance-decomposition claims. In the revision we will (i) give exact operational definitions for each feature, (ii) describe the 2PL IRT parameter estimation procedure performed on the identical training split, (iii) specify the non-linear regressor as a random forest with 100 trees, and (iv) report variance-inflation factors to address potential collinearity concerns. revision: yes
Circularity Check
No significant circularity; derivation uses external benchmarks and direct empirical measurement
full rationale
The paper's chain proceeds from standard MC-Dropout application to KT models, direct measurement of accuracy/AUC/F1 lifts on abstention, and a regression of BALD epistemic scores onto independently defined psychometric regressors (difficulty, ability, IRT ambiguity, curriculum coverage). The reported low explanatory power (under 4% linear, 23% non-linear) and 5x lift versus 2PL IRT are computed outcomes on the Eedi dataset rather than quantities defined by the authors' own fitted parameters or prior self-citations. No uniqueness theorem, ansatz smuggling, or renaming of known results occurs; the necessity claim follows from the residual signal's observed targeting of errors, which remains falsifiable against the held-out performance metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- abstention fraction
axioms (1)
- domain assumption MC-Dropout variance approximates epistemic uncertainty in neural KT models
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We estimate predictive uncertainty using Monte Carlo Dropout... quantify total uncertainty by the entropy of the aggregated predictive distribution... variance decomposition of the model's epistemic uncertainty (BALD) reveals that the entire classical psychometric stack... explains less than 4% of the signal
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat_equivNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Abstaining on the 20% most uncertain predictions lifts accuracy... MC-Dropout variance gives roughly five times the AUC lift of a calibrated two-parameter logistic (2PL) Item Response Theory (IRT) baseline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Z. A. Pardos and N. T. Heffernan, ``Modeling individualization in a bayesian networks implementation of knowledge tracing,'' in International conference on user modeling, adaptation, and personalization. 1em plus 0.5em minus 0.4em Springer, 2010, pp. 255--266
work page 2010
-
[2]
M. V. Yudelson, K. R. Koedinger, and G. J. Gordon, ``Individualized bayesian knowledge tracing models,'' in International conference on artificial intelligence in education. 1em plus 0.5em minus 0.4em Springer, 2013, pp. 171--180
work page 2013
-
[3]
C. Piech, J. Bassen, J. Huang, S. Ganguli, M. Sahami, L. Guibas, and J. Sohl-Dickstein, ``Deep knowledge tracing,'' in Proceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1, ser. NIPS'15. 1em plus 0.5em minus 0.4em Cambridge, MA, USA: MIT Press, 2015, p. 505–513
work page 2015
-
[4]
S. Pandey and G. Karypis, ``A self-attentive model for knowledge tracing,'' in EDM 2019 - Proceedings of the 12th International Conference on Educational Data Mining. 1em plus 0.5em minus 0.4em International Educational Data Mining Society, 2019, pp. 384--389
work page 2019
-
[5]
A. Ghosh, N. Heffernan, and A. S. Lan, ``Context-aware attentive knowledge tracing,'' in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD '20. 1em plus 0.5em minus 0.4em New York, NY, USA: Association for Computing Machinery, 2020, p. 2330–2339. [Online]. Available: https://doi.org/10.1145/3394486.3403282
-
[6]
Y. Yang, J. Shen, Y. Qu, Y. Liu, K. Wang, Y. Zhu, W. Zhang, and Y. Yu, ``Gikt: a graph-based interaction model for knowledge tracing,'' in Joint European conference on machine learning and knowledge discovery in databases. 1em plus 0.5em minus 0.4em Springer, 2020, pp. 299--315
work page 2020
- [7]
- [8]
-
[9]
B. Yamkovenko, C. Hogg, M. Miller-Vedam, P. Grimaldi, and W. Wells, ``Practical evaluation of deep knowledge tracing models for use in learning platforms,'' in Proceedings of the 18th International Conference on Educational Data Mining, 2025, pp. 673--679
work page 2025
-
[10]
Y. Gal and Z. Ghahramani, ``Dropout as a bayesian approximation: Representing model uncertainty in deep learning,'' in Proceedings of The 33rd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. F. Balcan and K. Q. Weinberger, Eds., vol. 48. 1em plus 0.5em minus 0.4em New York, New York, USA: PMLR, 20--22 Jun 20...
work page 2016
-
[11]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y. Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin, F. Huang, and J. Zhou, ``Qwen3 embedding: Advancing text embedding and reranking through foundation models,'' arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
T. M. Cover and J. A. Thomas, Elements of Information Theory 2nd Edition (Wiley Series in Telecommunications and Signal Processing). 1em plus 0.5em minus 0.4em Wiley-Interscience, July 2006
work page 2006
-
[13]
A. T. Corbett and J. R. Anderson, ``Knowledge tracing: Modeling the acquisition of procedural knowledge,'' User Modeling and User-Adapted Interaction, vol. 4, pp. 253--278, 2005. [Online]. Available: https://api.semanticscholar.org/CorpusID:19228797
work page 2005
-
[14]
J. Lee and D.-Y. Yeung, ``Knowledge query network for knowledge tracing: How knowledge interacts with skills,'' in Proceedings of the 9th International Conference on Learning Analytics & Knowledge, ser. LAK19. 1em plus 0.5em minus 0.4em New York, NY, USA: Association for Computing Machinery, 2019, p. 491–500. [Online]. Available: https://doi.org/10.1145/3...
-
[15]
J. Zhang, X. Shi, I. King, and D.-Y. Yeung, ``Dkvmn,'' in Proceedings of the 26th International Conference on World Wide Web, ser. WWW '17. 1em plus 0.5em minus 0.4em Republic and Canton of Geneva, CHE: International World Wide Web Conferences Steering Committee, 2017, p. 765–774. [Online]. Available: https://doi.org/10.1145/3038912.3052580
-
[16]
Y. Liu, Y. Yang, X. Chen, J. Shen, H. Zhang, and Y. Yu, ``Improving knowledge tracing via pre-training question embeddings,'' in Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20 , C. Bessiere, Ed. 1em plus 0.5em minus 0.4em International Joint Conferences on Artificial Intelligence Organization, 7 2020, p...
-
[17]
Y. Yang, J. Shen, Y. Qu, Y. Liu, K. Wang, Y. Zhu, W. Zhang, and Y. Yu, ``Gikt: A graph-based interaction model for knowledge tracing,'' in Machine Learning and Knowledge Discovery in Databases, F. Hutter, K. Kersting, J. Lijffijt, and I. Valera, Eds. 1em plus 0.5em minus 0.4em Cham: Springer International Publishing, 2021, pp. 299--315
work page 2021
-
[18]
W. Cheng, H. Du, C. Li, E. Ni, L. Tan, T. Xu, and Y. Ni, ``Uncertainty-aware knowledge tracing,'' in Proceedings of the AAAI Conference on Artificial Intelligence, ser. AAAI'25/IAAI'25/EAAI'25. 1em plus 0.5em minus 0.4em AAAI Press, 2025. [Online]. Available: https://doi.org/10.1609/aaai.v39i27.35007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.