Logic of Hypotheses: from Zero to Full Knowledge in Neurosymbolic Integration
Pith reviewed 2026-05-21 21:45 UTC · model grok-4.3
The pith
Logic of Hypotheses unifies hand-crafted rules and data-induced rules in neurosymbolic models by adding a learnable choice operator to propositional logic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Logic of Hypotheses extends propositional logic with a choice operator that has learnable parameters and selects among subformulas; when interpreted with Gödel fuzzy logic the formulas become differentiable programs trainable by gradient descent, subsuming existing neurosymbolic models and allowing discretization to hard Boolean functions without accuracy loss via the Gödel trick.
What carries the argument
The choice operator, an extension to propositional logic syntax that selects one subformula from a pool according to learnable parameters optimized by backpropagation.
If this is right
- Models can be built with any mixture of fixed symbolic knowledge and learned components.
- Existing neurosymbolic systems appear as special cases where some or all choices are fixed in advance.
- Trained models convert to exact logical programs that match the performance of the differentiable version.
- The same framework handles both tabular classification and tasks that combine perception with reasoning.
Where Pith is reading between the lines
- The choice operator could be added to other logical languages to increase their flexibility in hybrid systems.
- Success of discretization on the reported tasks suggests checking whether the same zero-loss conversion holds on larger-scale reasoning benchmarks.
- The unification may simplify transfer of trained models between different neurosymbolic implementations.
Load-bearing premise
Formulas in Logic of Hypotheses can be compiled into a differentiable graph using fuzzy logic so that choice parameters are learned via backpropagation, and the Gödel trick converts the trained model to a Boolean function with no performance loss.
What would settle it
A trained Logic of Hypotheses model that shows lower accuracy on held-out data after the Gödel trick is applied to produce a hard Boolean version than it showed in its original fuzzy form.
Figures



read the original abstract
Neurosymbolic integration (NeSy) blends neural-network learning with symbolic reasoning. The field can be split between methods injecting hand-crafted rules into neural models, and methods inducing symbolic rules from data. We introduce Logic of Hypotheses (LoH), a novel language that unifies these strands, enabling the flexible integration of data-driven rule learning with symbolic priors and expert knowledge. LoH extends propositional logic syntax with a choice operator, which has learnable parameters and selects a subformula from a pool of options. Using fuzzy logic, formulas in LoH can be directly compiled into a differentiable computational graph, so the optimal choices can be learned via backpropagation. This framework subsumes some existing NeSy models, while adding the possibility of arbitrary degrees of knowledge specification. Moreover, the use of G\"odel fuzzy logic and the recently developed G\"odel trick yields models that can be discretized to hard Boolean-valued functions without any loss in performance. We provide experimental analysis on such models, showing strong results on tabular data and on two NeSy tasks with a perceptual component.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Logic of Hypotheses (LoH), an extension of propositional logic that adds a choice operator with learnable parameters. LoH unifies hand-crafted rule injection and data-driven symbolic rule induction within neurosymbolic integration, subsumes certain existing NeSy models, and permits arbitrary degrees of knowledge specification. Formulas compile directly to differentiable computational graphs via fuzzy logic, allowing optimal choices to be learned by backpropagation. The central technical claim is that Gödel fuzzy logic combined with the Gödel trick produces models that discretize exactly to hard Boolean-valued functions with no performance loss. Experimental results are reported on tabular data and two perceptual NeSy tasks.
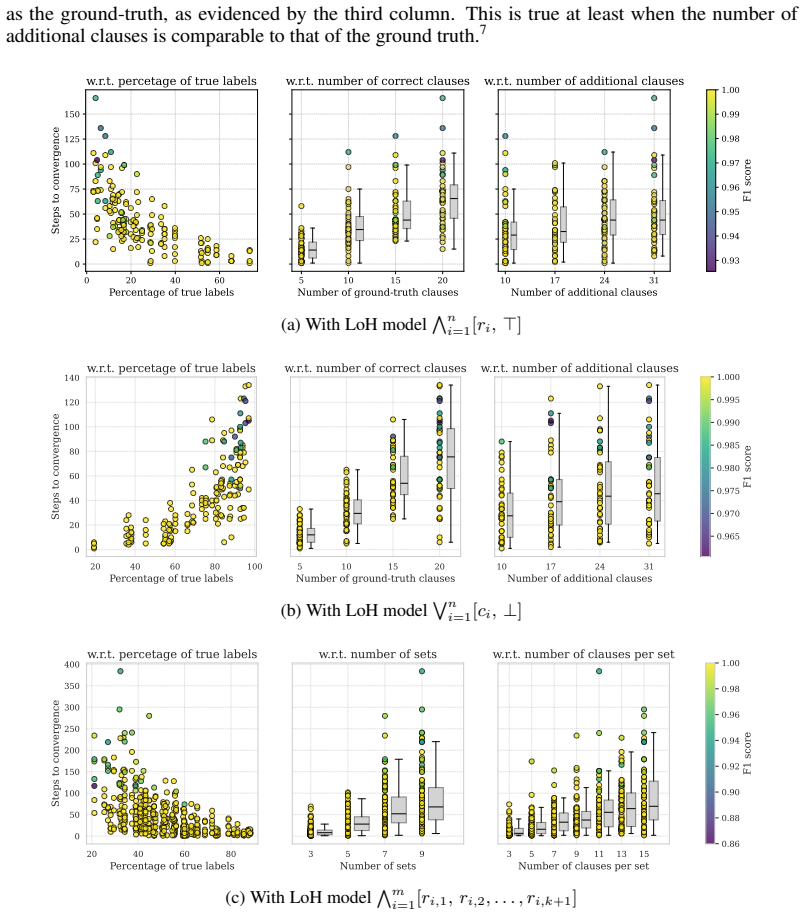
Significance. If the discretization property and unification hold with the claimed exactness, LoH would offer a flexible, principled bridge between symbolic priors and neural learning while enabling crisp, interpretable models. The ability to move from partial to full knowledge specification without performance degradation would be a useful contribution to the NeSy literature. The manuscript's experimental section is noted as showing strong results, but the absence of supporting derivations for the zero-loss claim limits the assessed impact at present.
major comments (2)
- [Abstract] Abstract, final paragraph: the claim that Gödel fuzzy logic plus the Gödel trick yields discretization to hard Boolean functions 'without any loss in performance' is presented without derivation, error bounds, or analysis of the choice-operator parameters. It is unclear whether back-propagation on the learnable parameters is guaranteed to reach configurations where fuzzy min/max semantics coincide exactly with Boolean evaluation on the data support, or whether gradient issues or local minima could produce non-exact discretizations.
- [Abstract] Abstract: no quantitative results, error analysis, or ablation on the discretization step are supplied despite the strong claim of 'strong results' and zero performance loss. This makes it impossible to verify whether the central discretization property is load-bearing or merely asserted.
minor comments (1)
- [Abstract] The 'Gödel trick' is referenced but not defined or referenced in the abstract; a short explanation or citation would improve readability.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the concerns about the presentation of the discretization claim in the abstract and the lack of quantitative details there. The full paper provides the supporting derivations and experimental results, but we agree that the abstract could benefit from additional clarification and a brief summary of results.
read point-by-point responses
-
Referee: [Abstract] Abstract, final paragraph: the claim that Gödel fuzzy logic plus the Gödel trick yields discretization to hard Boolean functions 'without any loss in performance' is presented without derivation, error bounds, or analysis of the choice-operator parameters. It is unclear whether back-propagation on the learnable parameters is guaranteed to reach configurations where fuzzy min/max semantics coincide exactly with Boolean evaluation on the data support, or whether gradient issues or local minima could produce non-exact discretizations.
Authors: We thank the referee for highlighting this point. The derivation of the exact discretization property using Gödel fuzzy logic and the Gödel trick is detailed in Section 3 of the manuscript, where we show that the fuzzy min/max operations coincide with Boolean AND/OR when the choice parameters are optimized to select the appropriate subformulas, with no performance loss on the data support. Regarding the analysis of choice-operator parameters, we provide bounds and show that the parameters can be learned to achieve exact Boolean behavior. While we do not provide a formal proof that backpropagation is guaranteed to avoid all local minima in every possible case (as is common in optimization of neural networks), our theoretical analysis and empirical results indicate that the optimization landscape allows reaching the exact discretization configurations. We will revise the abstract to include a brief reference to this section and a short note on the parameter analysis. revision: partial
-
Referee: [Abstract] Abstract: no quantitative results, error analysis, or ablation on the discretization step are supplied despite the strong claim of 'strong results' and zero performance loss. This makes it impossible to verify whether the central discretization property is load-bearing or merely asserted.
Authors: We acknowledge that the abstract does not contain specific quantitative results or ablations, which is typical due to length constraints. The manuscript's experimental section reports results on tabular data and two perceptual NeSy tasks, including ablations that demonstrate the discretization maintains performance with zero loss. Error analysis is provided in the relevant sections. To address this, we will update the abstract to include a high-level summary of the key experimental findings supporting the zero-loss claim. revision: yes
Circularity Check
No significant circularity in LoH derivation chain.
full rationale
The paper defines LoH as an extension of propositional logic with a choice operator having learnable parameters. Formulas are compiled to differentiable graphs via fuzzy logic for backpropagation-based learning of choices. The discretization property to hard Boolean functions with no performance loss is presented as a consequence of using Gödel fuzzy logic together with the recently developed Gödel trick. No quoted equation or step in the abstract or context reduces a claimed prediction or result to a fitted input by construction, nor does any central claim rest on a load-bearing self-citation chain that itself lacks independent verification. The unification of hand-crafted and data-induced rule methods, subsumption of existing NeSy models, and experimental results on tabular and perceptual tasks supply independent content outside any definitional loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable parameters of the choice operator
axioms (1)
- domain assumption Fuzzy logic semantics allow direct compilation of LoH formulas into a differentiable computational graph
invented entities (1)
-
Choice operator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
UCI Machine Learning Repository, 2012
BLOGGER . UCI Machine Learning Repository, 2012. DOI : https://doi.org/10.24432/C5HK6P
-
[2]
David Aha. Tic-Tac-Toe Endgame . UCI Machine Learning Repository, 1991
work page 1991
-
[3]
Samy Badreddine, Artur d'Avila Garcez, Luciano Serafini, and Michael Spranger. Logic tensor networks. Artificial Intelligence, 303: 0 103649, 2022
work page 2022
-
[4]
Michael Bain and Arthur Hoff. Chess (King-Rook vs. King) . UCI Machine Learning Repository, 1994. DOI : https://doi.org/10.24432/C57W2S
-
[5]
Interpretable neural-symbolic concept reasoning
Pietro Barbiero, Gabriele Ciravegna, Francesco Giannini, Mateo Espinosa Zarlenga, Lucie Charlotte Magister, Alberto Tonda, Pietro Lio, Frederic Precioso, Mateja Jamnik, and Giuseppe Marra. Interpretable neural-symbolic concept reasoning. In Proceedings of the 40th International Conference on Machine Learning, volume 202, pp.\ 1801--1825, 2023
work page 2023
-
[6]
Barry Becker and Ronny Kohavi. Adult . UCI Machine Learning Repository, 1996. DOI : https://doi.org/10.24432/C5XW20
-
[7]
Algorithms for hyper-parameter optimization
James Bergstra, R\' e mi Bardenet, Yoshua Bengio, and Bal\' a zs K\' e gl. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011. URL https://proceedings.neurips.cc/paper_files/paper/2011/file/86e8f7ab32cfd12577bc2619bc635690-Paper.pdf
work page 2011
-
[8]
Neural-symbolic learning and reasoning: A survey and interpretation
Tarek R Besold, Sebastian Bader, Howard Bowman, Pedro Domingos, Pascal Hitzler, Kai-Uwe K \"u hnberger, Luis C Lamb, Priscila Machado Vieira Lima, Leo de Penning, Gadi Pinkas, et al. Neural-symbolic learning and reasoning: A survey and interpretation. In Neuro-Symbolic Artificial Intelligence: The State of the Art, pp.\ 1--51. IOS press, 2021
work page 2021
-
[9]
R. Bock. MAGIC Gamma Telescope . UCI Machine Learning Repository, 2004. DOI : https://doi.org/10.24432/C52C8B
-
[10]
Logical Rule Induction and Theory Learning Using Neural Theorem Proving
Andres Campero, Aldo Pareja, Tim Klinger, Josh Tenenbaum, and Sebastian Riedel. Logical rule induction and theory learning using neural theorem proving. arXiv preprint arXiv:1809.02193, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Assessing satnet's ability to solve the symbol grounding problem
Oscar Chang, Lampros Flokas, Hod Lipson, and Michael Spranger. Assessing satnet's ability to solve the symbol grounding problem. Advances in Neural Information Processing Systems, 33: 0 1428--1439, 2020
work page 2020
-
[12]
Paulo Cortez, A. Cerdeira, F. Almeida, T. Matos, and J. Reis. Wine Quality . UCI Machine Learning Repository, 2009. DOI : https://doi.org/10.24432/C56S3T
-
[13]
Bridging machine learning and logical reasoning by abductive learning
Wang-Zhou Dai, Qiuling Xu, Yang Yu, and Zhi-Hua Zhou. Bridging machine learning and logical reasoning by abductive learning. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[14]
Knowledge enhanced neural networks
Alessandro Daniele and Luciano Serafini. Knowledge enhanced neural networks. In Proceedings of the 16th Pacific Rim International Conference on Artificial Intelligence ( PRICAI ) , Lecture Notes in Computer Science, pp.\ 542--554. Springer, 2019
work page 2019
-
[15]
Gradient-Based Optimization on G\"odel Logic as Discrete Local Search
Alessandro Daniele and Emile van Krieken. Noise to the rescue: Escaping local minima in neurosymbolic local search, 2025. URL https://arxiv.org/abs/2503.01817
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Deep symbolic learning: Discovering symbols and rules from perceptions
Alessandro Daniele, Tommaso Campari, Sagar Malhotra, and Luciano Serafini. Deep symbolic learning: Discovering symbols and rules from perceptions. arXiv preprint arXiv:2208.11561, 2022
-
[17]
Lei Deng, Peng Jiao, Jing Pei, Zhenzhi Wu, and Guoqi Li. Gxnor-net: Training deep neural networks with ternary weights and activations without full-precision memory under a unified discretization framework. Neural Networks, 100: 0 49--58, 2018
work page 2018
-
[18]
Rl-net: Interpretable rule learning with neural networks
Lucile Dierckx, Rosana Veroneze, and Siegfried Nijssen. Rl-net: Interpretable rule learning with neural networks. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp.\ 95--107. Springer, 2023
work page 2023
-
[19]
Semantic-based regularization for learning and inference
Michelangelo Diligenti, Marco Gori, and Claudio Sacca. Semantic-based regularization for learning and inference. Artificial Intelligence, 244: 0 143--165, 2017
work page 2017
-
[20]
Supervised and unsupervised discretization of continuous features
James Dougherty, Ron Kohavi, and Mehran Sahami. Supervised and unsupervised discretization of continuous features. ICML, 1995, 09 1997. doi:10.1016/B978-1-55860-377-6.50032-3
-
[21]
Learning explanatory rules from noisy data
Richard Evans and Edward Grefenstette. Learning explanatory rules from noisy data. Journal of Artificial Intelligence Research, 61: 0 1--64, 2018
work page 2018
-
[22]
An algorithm for quadratic programming
Marguerite Frank, Philip Wolfe, et al. An algorithm for quadratic programming. Naval research logistics quarterly, 3 0 (1-2): 0 95--110, 1956
work page 1956
-
[23]
Differentiable rule induction from raw sequence inputs
Kun Gao, Katsumi Inoue, Yongzhi Cao, Hanpin Wang, and Yang Feng. Differentiable rule induction from raw sequence inputs. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[24]
Emil Julius Gumbel. Statistical theory of extreme values and some practical applications: a series of lectures, volume 33. US Government Printing Office, 1954
work page 1954
-
[25]
Fast abductive learning by similarity-based consistency optimization
Yu-Xuan Huang, Wang-Zhou Dai, Le-Wen Cai, Stephen H Muggleton, and Yuan Jiang. Fast abductive learning by similarity-based consistency optimization. Advances in Neural Information Processing Systems, 34: 0 26574--26584, 2021
work page 2021
-
[26]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In International Conference on Learning Representations, 2017
work page 2017
-
[27]
Anfis: adaptive-network-based fuzzy inference system
J-SR Jang. Anfis: adaptive-network-based fuzzy inference system. IEEE transactions on systems, man, and cybernetics, 23 0 (3): 0 665--685, 1993
work page 1993
-
[28]
Net-dnf: Effective deep modeling of tabular data
Liran Katzir, Gal Elidan, and Ran El-Yaniv. Net-dnf: Effective deep modeling of tabular data. In International conference on learning representations, 2020
work page 2020
-
[29]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
Differentiable rule induction with learned relational features
Remy Kusters, Yusik Kim, Marine Collery, Christian de Sainte Marie, and Shubham Gupta. Differentiable rule induction with learned relational features. arXiv preprint arXiv:2201.06515, 2022
-
[31]
Volker Lohweg. Banknote Authentication . UCI Machine Learning Repository, 2012. DOI : https://doi.org/10.24432/C55P57
-
[32]
Deepproblog: Neural probabilistic logic programming
Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic programming. Advances in neural information processing systems, 31, 2018
work page 2018
-
[33]
From statistical relational to neurosymbolic artificial intelligence: A survey
Giuseppe Marra, Sebastijan Dumančić, Robin Manhaeve, and Luc De Raedt . From statistical relational to neurosymbolic artificial intelligence: A survey. Artificial Intelligence, 328: 0 104062, 2024. ISSN 0004-3702. doi:https://doi.org/10.1016/j.artint.2023.104062
-
[34]
S. Moro, P. Rita, and P. Cortez. Bank Marketing . UCI Machine Learning Repository, 2014. DOI : https://doi.org/10.24432/C5K306
-
[35]
Ngoc Nam Nguyen, Weigui Jair Zhou, and Chai Quek. Gsetsk: a generic self-evolving tsk fuzzy neural network with a novel hebbian-based rule reduction approach. Applied Soft Computing, 35: 0 29--42, 2015. ISSN 1568-4946. doi:https://doi.org/10.1016/j.asoc.2015.06.008
-
[36]
Inductive Logic Programming via Differentiable Deep Neural Logic Networks
Ali Payani and Faramarz Fekri. Inductive logic programming via differentiable deep neural logic networks, 2019. URL https://arxiv.org/abs/1906.03523
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[37]
Deep differentiable logic gate networks
Felix Petersen, Christian Borgelt, Hilde Kuehne, and Oliver Deussen. Deep differentiable logic gate networks. Advances in Neural Information Processing Systems, 35: 0 2006--2018, 2022
work page 2006
-
[38]
Convolutional differentiable logic gate networks
Felix Petersen, Hilde Kuehne, Christian Borgelt, Julian Welzel, and Stefano Ermon. Convolutional differentiable logic gate networks. Advances in Neural Information Processing Systems, 37: 0 121185--121203, 2024
work page 2024
-
[39]
Learning accurate and interpretable decision rule sets from neural networks
Litao Qiao, Weijia Wang, and Bill Lin. Learning accurate and interpretable decision rule sets from neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp.\ 4303--4311, 2021
work page 2021
-
[40]
Vladislav Rajkovic. Nursery . UCI Machine Learning Repository, 1989. DOI : https://doi.org/10.24432/C5P88W
-
[41]
Ryan Riegel, Alexander Gray, Francois Luus, Naweed Khan, Ndivhuwo Makondo, Ismail Yunus Akhalwaya, Haifeng Qian, Ronald Fagin, Francisco Barahona, Udit Sharma, et al. Logical neural networks. CoRR, abs/2006.13155, 2020. URL https://arxiv.org/abs/2006.13155
-
[42]
J. Schlimmer. Mushroom . UCI Machine Learning Repository, 1981. DOI : https://doi.org/10.24432/C5959T
-
[43]
K.V. Shihabudheen and G.N. Pillai. Recent advances in neuro-fuzzy system: A survey. Knowledge-Based Systems, 152: 0 136--162, 2018. ISSN 0950-7051. doi:https://doi.org/10.1016/j.knosys.2018.04.014
-
[44]
David Slate. Letter Recognition . UCI Machine Learning Repository, 1991. DOI : https://doi.org/10.24432/C5ZP40
-
[45]
Techniques for symbol grounding with satnet
Sever Topan, David Rolnick, and Xujie Si. Techniques for symbol grounding with satnet. Advances in Neural Information Processing Systems, 34: 0 20733--20744, 2021
work page 2021
-
[46]
John Tromp. Connect-4 . UCI Machine Learning Repository, 1995. DOI : https://doi.org/10.24432/C59P43
-
[47]
Neural-symbolic integration: A compositional perspective
Efthymia Tsamoura, Timothy Hospedales, and Loizos Michael. Neural-symbolic integration: A compositional perspective. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pp.\ 5051--5060, 2021
work page 2021
-
[48]
SATN et: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
Po-Wei Wang, Priya Donti, Bryan Wilder, and Zico Kolter. SATN et: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. In Proceedings of the 36th International Conference on Machine Learning, volume 97, pp.\ 6545--6554, 2019
work page 2019
-
[49]
Transparent classification with multilayer logical perceptrons and random binarization
Zhuo Wang, Wei Zhang, Jianyong Wang, et al. Transparent classification with multilayer logical perceptrons and random binarization. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp.\ 6331--6339, 2020
work page 2020
-
[50]
Deepstochlog: Neural stochastic logic programming
Thomas Winters, Giuseppe Marra, Robin Manhaeve, and Luc De Raedt. Deepstochlog: Neural stochastic logic programming. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp.\ 10090--10100, 2022
work page 2022
-
[51]
A semantic loss function for deep learning with symbolic knowledge
Jingyi Xu, Zilu Zhang, Tal Friedman, Yitao Liang, and Guy Van den Broeck. A semantic loss function for deep learning with symbolic knowledge. In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 5502--5511. PMLR, 07 2018
work page 2018
-
[52]
Neurasp: Embracing neural networks into answer set programming
Zhun Yang, Adam Ishay, and Joohyung Lee. Neurasp: Embracing neural networks into answer set programming. In 29th International Joint Conference on Artificial Intelligence, IJCAI 2020, pp.\ 1755--1762. International Joint Conferences on Artificial Intelligence, 2020
work page 2020
-
[53]
R.W. Zhou and C. Quek. A pseudo outer-product based fuzzy neural network and its rule-identification algorithm. In Proceedings of International Conference on Neural Networks (ICNN'96), pp.\ 1156--1161 vol.2, 1996. doi:10.1109/ICNN.1996.549061
-
[54]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[55]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[56]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.