Learning Aligned Stability in Neural ODEs Reconciling Accuracy with Robustness
Pith reviewed 2026-05-18 13:07 UTC · model grok-4.3
The pith
Reformulating Zubov's equation as a differentiable loss aligns prescribed and true regions of attraction in Neural ODEs to reconcile accuracy with robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Minimizing the tripartite loss guarantees consistency alignment of PRoAs-RoAs, non-overlapping PRoAs, trajectory stability, and a certified robustness margin. Stochastic convex separability with tighter probability bounds and lower dimensionality requirements justifies the convex design in Lyapunov functions.
What carries the argument
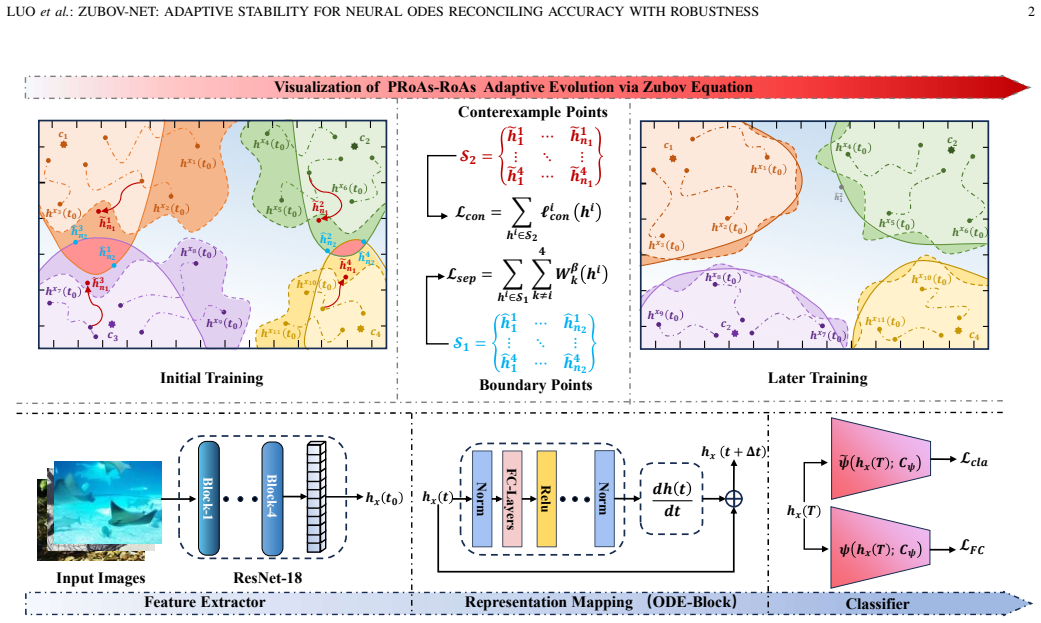
The Zubov-driven stability region matching mechanism, which reformulates Zubov's equation into a differentiable consistency loss to align prescribed regions of attraction (PRoAs) with true regions of attraction (RoAs).
Load-bearing premise
Reformulating Zubov's equation into a differentiable consistency loss produces non-overlapping, accurately aligned prescribed regions of attraction without introducing new fitting artifacts or requiring post-hoc adjustments.
What would settle it
A concrete falsifier would be a trained model in which the prescribed regions of attraction overlap or a trajectory escapes its prescribed region even though the tripartite loss has been driven to its minimum.
Figures



read the original abstract
Despite Neural Ordinary Differential Equations (Neural ODEs) exhibiting intrinsic robustness, existing methods often impose Lyapunov stability for formal guarantees. However, these methods still face a fundamental accuracy-robustness trade-off, which stems from a core limitation: their applied stability conditions are rigid and inappropriate, creating a mismatch between the model's regions of attraction (RoAs) and its decision boundaries. To resolve this, we propose Zubov-Net, a novel framework that unifies dynamics and decision-making. We first employ learnable Lyapunov functions directly as the multi-class classifier, ensuring the prescribed RoAs (PRoAs, defined by the Lyapunov functions) inherently align with a classification objective. Then, for aligning prescribed and true regions of attraction (PRoAs-RoAs), we establish a Zubov-driven stability region matching mechanism by reformulating Zubov's equation into a differentiable consistency loss. Building on this alignment, we introduce a new paradigm for actively controlling the geometry of RoAs by directly optimizing PRoAs to reconcile accuracy and robustness. Theoretically, we prove that minimizing the tripartite loss guarantees consistency alignment of PRoAs-RoAs, non-overlapping PRoAs, trajectory stability, and a certified robustness margin. Moreover, we establish stochastic convex separability with tighter probability bounds and lower dimensionality requirements to justify the convex design in Lyapunov functions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Zubov-Net, a framework for Neural ODEs that employs learnable Lyapunov functions directly as multi-class classifiers to define Prescribed Regions of Attraction (PRoAs). It reformulates Zubov's equation into a differentiable consistency loss to align PRoAs with true Regions of Attraction (RoAs), and minimizes a tripartite loss combining classification, consistency, and stability terms. The central claims are that this minimization guarantees PRoA-RoA consistency alignment, non-overlapping PRoAs, trajectory stability, and a certified robustness margin, with additional justification via stochastic convex separability arguments supporting the convex design of the Lyapunov functions.
Significance. If the theoretical guarantees can be rigorously established with explicit derivations and the empirical results confirm practical alignment without post-hoc fixes, this work could meaningfully advance robust learning in dynamical systems by providing a mechanism to actively control RoA geometry and reconcile the accuracy-robustness trade-off beyond rigid stability constraints. The integration of Zubov's PDE reformulation with neural parameterization offers a novel angle, though its impact depends on resolving the verifiability of the claimed independence of the guarantees.
major comments (3)
- [Abstract] Abstract (paragraph on Zubov-driven stability region matching mechanism): The central claim that reformulating Zubov's equation into a differentiable consistency loss produces non-overlapping and accurately aligned PRoAs without new fitting artifacts or post-hoc adjustments is load-bearing, yet the abstract supplies no explicit loss formulation, derivation steps, or convergence analysis. This leaves open whether residual mismatches from finite-capacity networks and numerical ODE integration (e.g., adaptive step-size tolerances) violate the non-overlap or certified-margin proofs.
- [Abstract] Abstract: The claim that minimizing the tripartite loss guarantees consistency alignment of PRoAs-RoAs, non-overlapping PRoAs, trajectory stability, and a certified robustness margin risks circularity because the alignment term is derived from the same Lyapunov functions used for classification. No explicit loss definition or proof sketch is given to demonstrate that the guarantees are independent rather than tautological with the loss construction.
- [Abstract] Abstract (stochastic convex separability paragraph): The justification for the convex design in Lyapunov functions via stochastic convex separability supplies tighter probability bounds and lower dimensionality requirements but provides no explicit convergence rate showing that the soft surrogate consistency loss reaches the precise Zubov solution under gradient descent, which is required for the margin proofs to hold.
minor comments (1)
- The acronym PRoAs is introduced with a parenthetical definition, but the manuscript would benefit from an early dedicated section or table explicitly listing all loss terms and their weighting coefficients to improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments on the abstract and theoretical claims. We address each point below with references to the manuscript sections and indicate revisions where we will strengthen the presentation of the loss formulation, derivations, and independence arguments.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on Zubov-driven stability region matching mechanism): The central claim that reformulating Zubov's equation into a differentiable consistency loss produces non-overlapping and accurately aligned PRoAs without new fitting artifacts or post-hoc adjustments is load-bearing, yet the abstract supplies no explicit loss formulation, derivation steps, or convergence analysis. This leaves open whether residual mismatches from finite-capacity networks and numerical ODE integration (e.g., adaptive step-size tolerances) violate the non-overlap or certified-margin proofs.
Authors: The abstract is intentionally concise. The explicit consistency loss is defined in Section 3.2 (Equation 5) as the integrated squared residual of the reformulated Zubov PDE over sampled trajectories. Derivation steps from the original PDE to this differentiable surrogate appear in Appendix A.1. Theorem 1 proves that any minimizer of the full tripartite loss satisfies PRoA-RoA alignment and non-overlap in the continuous setting. We acknowledge that finite network capacity and adaptive ODE solvers introduce approximation error; the certified margin in Theorem 3 already incorporates a Lipschitz-based tolerance term, but we will add an explicit remark on discretization effects and empirical verification of the margin under standard solvers in the revised manuscript. revision: partial
-
Referee: [Abstract] Abstract: The claim that minimizing the tripartite loss guarantees consistency alignment of PRoAs-RoAs, non-overlapping PRoAs, trajectory stability, and a certified robustness margin risks circularity because the alignment term is derived from the same Lyapunov functions used for classification. No explicit loss definition or proof sketch is given to demonstrate that the guarantees are independent rather than tautological with the loss construction.
Authors: The classification term uses the Lyapunov function values as logits, while the consistency term enforces the Zubov PDE on the vector field independently of the label assignment. The proof of Theorem 1 proceeds by showing that at a global minimum the consistency loss reaches zero (implying the PDE holds), which in turn forces the sublevel sets to coincide with the true RoAs regardless of how the level sets are labeled. The non-overlap and stability properties then follow from the Lyapunov decrease condition and the convex separability argument in Section 4. We will insert a compact proof sketch of this separation into the main text (new paragraph after Theorem 1) and expand the independence argument in Appendix B. revision: yes
-
Referee: [Abstract] Abstract (stochastic convex separability paragraph): The justification for the convex design in Lyapunov functions via stochastic convex separability supplies tighter probability bounds and lower dimensionality requirements but provides no explicit convergence rate showing that the soft surrogate consistency loss reaches the precise Zubov solution under gradient descent, which is required for the margin proofs to hold.
Authors: Section 4 derives the stochastic convex separability result (Theorem 4) to justify the convex parameterization with explicit probability bounds that improve on prior work. The convergence of gradient descent on the surrogate loss to the exact Zubov solution is not given a new rate; it inherits standard non-convex optimization bounds under the smoothness assumptions stated in Assumption 2. Because the margin proofs in Theorem 3 rely only on the loss reaching a sufficiently small value (not on a specific rate), the existing analysis remains valid. We will add a short remark clarifying this reliance and note that empirical convergence is verified in the experiments. revision: partial
Circularity Check
Tripartite loss guarantees partly tautological with embedded Zubov consistency term
specific steps
-
self definitional
[Abstract]
"Theoretically, we prove that minimizing the tripartite loss guarantees consistency alignment of PRoAs-RoAs, non-overlapping PRoAs, trajectory stability, and a certified robustness margin."
The tripartite loss contains a dedicated consistency loss obtained by reformulating Zubov's equation specifically to align PRoAs with RoAs. Therefore the claimed guarantee of alignment upon minimization is equivalent to the loss construction itself rather than an independent derivation from first principles or external bounds.
full rationale
The paper's central theoretical claim states that minimizing the tripartite loss (classification + consistency + stability) directly yields PRoA-RoA alignment, non-overlapping regions, and certified margins. However, the consistency term is explicitly constructed by reformulating Zubov's equation into a differentiable surrogate whose minimization enforces the alignment by design. This makes the 'guarantee' reduce to restating the loss objective rather than providing an independent verification outside the loss definition. The convex separability argument appears additive and does not rescue the core reduction. No self-citations or external uniqueness theorems are load-bearing in the provided text, keeping the circularity moderate rather than total.
Axiom & Free-Parameter Ledger
free parameters (2)
- parameters of learnable Lyapunov functions
- loss weighting coefficients in tripartite loss
axioms (2)
- standard math Lyapunov stability theory provides sufficient conditions for trajectory stability when a positive-definite function decreases along trajectories.
- domain assumption Zubov's equation can be reformulated as a differentiable consistency loss without introducing additional approximation errors that invalidate the alignment guarantees.
invented entities (1)
-
Prescribed Regions of Attraction (PRoAs)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reformulating Zubov’s equation into a differentiable consistency loss... L_con(θf,θW)=∑sup li_con(h)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Input-Attention-based Convex Neural Network... Proposition 1... convexity guarantee
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Convolutional hough matching networks,
J. Min and M. Cho, “Convolutional hough matching networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 2940–2950
work page 2021
-
[2]
Y . Yan, J. Li, J. Qin, S. Bai, S. Liao, L. Liu, F. Zhu, and L. Shao, “Anchor-free person search,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 7690–7699
work page 2021
-
[3]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceed- ings of the North American chapter of the association for computational linguistics: human language technologies, vol. 1, 2019, pp. 4171–4186
work page 2019
-
[4]
Constructing neural network based models for simulating dynamical systems,
C. Legaard, T. Schranz, G. Schweiger, J. Drgo ˇna, B. Falay, C. Gomes, A. Iosifidis, M. Abkar, and P. Larsen, “Constructing neural network based models for simulating dynamical systems,”ACM Computing Surveys, vol. 55, pp. 1–34, 2023
work page 2023
-
[5]
Adversarial eigen attack on blackbox models,
L. Zhou, P. Cui, X. Zhang, Y . Jiang, and S. Yang, “Adversarial eigen attack on blackbox models,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 15 233– 15 241
work page 2022
-
[6]
Mixup inference: Better exploiting mixup to defend adversarial attacks,
T. Pang, K. Xu, and J. Zhu, “Mixup inference: Better exploiting mixup to defend adversarial attacks,” inInternational Conference on Learning Representations, 2020
work page 2020
-
[7]
Provable unrestricted adversarial training without compromise with generalizability,
L. Zhang, N. Yang, Y . Sun, and P. S. Yu, “Provable unrestricted adversarial training without compromise with generalizability,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, pp. 8302–8319, 2024
work page 2024
-
[8]
Aucpro: Auc- oriented provable robustness learning,
S. Bao, Q. Xu, Z. Yang, Y . He, X. Cao, and Q. Huang, “Aucpro: Auc- oriented provable robustness learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, pp. 4579–4596, 2025
work page 2025
-
[9]
Neu- ral ordinary differential equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neu- ral ordinary differential equations,” inAdvances in Neural Information Processing Systems, vol. 31, 2018, p. 6572–6583
work page 2018
-
[10]
How does noise help robustness? explanation and exploration under the neural SDE framework,
X. Liu, T. Xiao, S. Si, Q. Cao, S. Kumar, and C.-J. Hsieh, “How does noise help robustness? explanation and exploration under the neural SDE framework,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 279–287
work page 2020
-
[11]
On the robustness to adversarial examples of neural ODE image classifiers,
F. Carrara, R. Caldelli, F. Falchi, and G. Amato, “On the robustness to adversarial examples of neural ODE image classifiers,” in2019 IEEE International Workshop on Information Forensics and Security (WIFS), 2019, pp. 1–6
work page 2019
-
[12]
On robustness of neural ordinary differential equations,
H. Y AN, J. DU, V . TAN, and J. FENG, “On robustness of neural ordinary differential equations,” inInternational Conference on Learning Representations, 2020
work page 2020
-
[13]
On robustness of neural ODEs image classifiers,
W. Cui, H. Zhang, H. Chu, P. Hu, and Y . Li, “On robustness of neural ODEs image classifiers,”Information Sciences, vol. 632, pp. 576–593, 2023
work page 2023
-
[14]
The general problem of the stability of motion,
A. M. LY APUNOV , “The general problem of the stability of motion,” International Journal of Control, vol. 55, pp. 531–534, 1992
work page 1992
-
[15]
LyaNet: A Lyapunov framework for training neural ODEs,
I. D. J. Rodriguez, A. Ames, and Y . Yue, “LyaNet: A Lyapunov framework for training neural ODEs,” inProceedings of the 39th International Conference on Machine Learning, vol. 162, 2022, pp. 18 687–18 703
work page 2022
-
[16]
FI-ODE: Certifiably robust forward invariance in neural ODEs,
Y . Huang, I. D. J. Rodriguez, H. Zhang, Y . Shi, and Y . Yue, “FI-ODE: Certifiably robust forward invariance in neural ODEs,”arXiv preprint arXiv:2210.16940, 2022
-
[17]
FxTS-Net: Fixed-time stable learning framework for neural ODEs,
C. Luo, Y . Zou, W. Li, and N. Huang, “FxTS-Net: Fixed-time stable learning framework for neural ODEs,”Neural Networks, vol. 185, p. 107219, 2025
work page 2025
-
[18]
Stable neural ODE with Lyapunov-Stable equilibrium points for defending against adversarial attacks,
Q. Kang, Y . Song, Q. Ding, and W. P. Tay, “Stable neural ODE with Lyapunov-Stable equilibrium points for defending against adversarial attacks,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 14 925–14 937
work page 2021
-
[19]
Defending against adversarial attacks via neural dynamic system,
X. Li, Z. Xin, and W. Liu, “Defending against adversarial attacks via neural dynamic system,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 6372–6383
work page 2022
-
[20]
Adversarially robust out-of-distribution detection using Lyapunov-Stabilized embeddings,
H. Mirzaei and M. W. Mathis, “Adversarially robust out-of-distribution detection using Lyapunov-Stabilized embeddings,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[21]
J. Liu, Y . Meng, M. Fitzsimmons, and R. Zhou, “Physics-informed neural network Lyapunov functions: PDE characterization, learning, and verification,”Automatica, vol. 175, p. 112193, 2025
work page 2025
-
[22]
Towards learning and verifying maximal neural Lyapunov func- tions,
——, “Towards learning and verifying maximal neural Lyapunov func- tions,” in2023 62nd IEEE Conference on Decision and Control (CDC), 2023, pp. 8012–8019
work page 2023
-
[23]
Data-driven computational methods for the domain of attraction and Zubov’s equation,
W. Kang, K. Sun, and L. Xu, “Data-driven computational methods for the domain of attraction and Zubov’s equation,”IEEE Transactions on Automatic Control, vol. 69, pp. 1600–1611, 2023
work page 2023
-
[24]
Lipschitz constant estimation of neural networks via sparse polynomial optimization,
F. Latorre, P. Rolland, and V . Cevher, “Lipschitz constant estimation of neural networks via sparse polynomial optimization,” inInternational Conference on Learning Representations, 2020
work page 2020
-
[25]
Stable neural stochastic differential equa- tions in analyzing irregular time series data,
Y . Oh, D. Lim, and S. Kim, “Stable neural stochastic differential equa- tions in analyzing irregular time series data,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[26]
Maximal Lyapunov functions and domains of attraction for autonomous nonlinear systems,
A. Vannelli and M. Vidyasagar, “Maximal Lyapunov functions and domains of attraction for autonomous nonlinear systems,”Automatica, vol. 21, pp. 69–80, 1985
work page 1985
-
[27]
Contributions to stability theory,
J. L. Massera, “Contributions to stability theory,”Annals of Mathematics, vol. 64, pp. 182–206, 1956
work page 1956
-
[28]
V . I. Zubov,Methods of AM Lyapunov and their application. US Atomic Energy Commission, 1961
work page 1961
-
[29]
Better diffusion models further improve adversarial training,
Z. Wang, T. Pang, C. Du, M. Lin, W. Liu, and S. Yan, “Better diffusion models further improve adversarial training,” inProceedings of the 40th International Conference on Machine Learning, vol. 202, 2023, pp. 36 246–36 263
work page 2023
-
[30]
A Self- supervised Approach for Adversarial Robustness ,
M. Naseer, S. Khan, M. Hayat, F. S. Khan, and F. Porikli, “ A Self- supervised Approach for Adversarial Robustness ,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 259–268
work page 2020
-
[31]
Online adversarial purification based on self-supervised learning,
C. Shi, C. Holtz, and G. Mishne, “Online adversarial purification based on self-supervised learning,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[32]
Improving adversarial training from the perspective of class-flipping distribution,
D. Zhou, N. Wang, T. Liu, and X. Gao, “Improving adversarial training from the perspective of class-flipping distribution,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, pp. 4330–4342, 2025
work page 2025
-
[33]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inInternational Conference on Learning Representations, 2018
work page 2018
-
[34]
Adversarial weight perturbation helps robust generalization,
D. Wu, S.-T. Xia, and Y . Wang, “Adversarial weight perturbation helps robust generalization,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 2958–2969
work page 2020
-
[35]
Adversarial robustness of stabilized neural ODE might be from obfuscated gradients,
Y . Huang, Y . Yu, H. Zhang, Y . Ma, and Y . Yao, “Adversarial robustness of stabilized neural ODE might be from obfuscated gradients,” in Proceedings of the 2nd Mathematical and Scientific Machine Learning Conference, vol. 145, 2022, pp. 497–515
work page 2022
-
[36]
Robust classification using contractive hamiltonian neural ODEs,
M. Zakwan, L. Xu, and G. Ferrari-Trecate, “Robust classification using contractive hamiltonian neural ODEs,”IEEE Control Systems Letters, vol. 7, pp. 145–150, 2023
work page 2023
-
[37]
Lyapunov-stable deep equilibrium models,
H. Chu, S. Wei, T. Liu, Y . Zhao, and Y . Miyatake, “Lyapunov-stable deep equilibrium models,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 11 615–11 623, 2024
work page 2024
-
[38]
B. Amos, L. Xu, and J. Z. Kolter, “Input convex neural networks,” in Proceedings of the 34th International Conference on Machine Learning, vol. 70, 2017, pp. 146–155
work page 2017
-
[39]
Asymmetric certified robustness via feature-convex neural networks,
S. Pfrommer, B. Anderson, J. Piet, and S. Sojoudi, “Asymmetric certified robustness via feature-convex neural networks,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 52 365–52 400. LUOet al.: ZUBOV-NET: ADAPTIVE STABILITY FOR NEURAL ODES RECONCILING ACCURACY WITH ROBUSTNESS 12
work page 2023
-
[40]
P. Kidger, R. T. Q. Chen, and T. J. Lyons, “”Hey, that’s not an ODE”: Faster ODE adjoints via seminorms,” inProceedings of the 38th International Conference on Machine Learning, vol. 139, 2021, pp. 5443–5452
work page 2021
-
[41]
Adversarial training and provable de- fenses: Bridging the gap,
M. Balunovi ´c and M. Vechev, “Adversarial training and provable de- fenses: Bridging the gap,” inInternational Conference on Learning Representations, 2020
work page 2020
-
[42]
IBP regularization for verified adversarial robustness via branch-and- bound,
A. De Palma, R. Bunel, K. Dvijotham, M. P. Kumar, and R. Stanforth, “IBP regularization for verified adversarial robustness via branch-and- bound,”arXiv preprint arXiv:2206.14772, 2022
-
[43]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Nget al., “Reading digits in natural images with unsupervised feature learning,” inNIPS workshop on deep learning and unsupervised feature learning,
-
[44]
Available: http://ufldl.stanford.edu/housenumbers
[Online]. Available: http://ufldl.stanford.edu/housenumbers
-
[45]
Learning multiple layers of features from tiny images,
A. Krizhevskyet al., “Learning multiple layers of features from tiny images,” 2009. [Online]. Available: https://www.cs.toronto.edu/ ∼kriz/ cifar.html
work page 2009
-
[46]
Benchmarking neural network ro- bustness to common corruptions and perturbations,
D. Hendrycks and T. Dietterich, “Benchmarking neural network ro- bustness to common corruptions and perturbations,” inInternational Conference on Learning Representations, 2019
work page 2019
-
[47]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[48]
A. Kurakin, I. J. Goodfellow, and S. Bengio,Adversarial examples in the physical world. Chapman and Hall/CRC, 2018
work page 2018
-
[49]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks,
F. Croce and M. Hein, “Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks,” inProceedings of the 37th International Conference on Machine Learning, vol. 119, 2020, pp. 2206–2216
work page 2020
-
[50]
Exploring misclassifications of robust neural networks to enhance adversarial attacks,
L. Schwinn, R. Raab, A. Nguyen, D. Zanca, and B. Eskofier, “Exploring misclassifications of robust neural networks to enhance adversarial attacks,”Applied Intelligence, vol. 53, pp. 19 843–19 859, 2023
work page 2023
-
[51]
Torchattacks: A pytorch repository for adversarial attacks,
H. Kim, “Torchattacks: A pytorch repository for adversarial attacks,” arXiv preprint arXiv:2010.01950, 2020
-
[52]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
work page 2016
-
[53]
S. P. Boyd and L. Vandenberghe,Convex Optimization. Cambridge University Press, 2004
work page 2004
-
[54]
H. K. Khalil,Nonlinear Systems; 3rd ed.Upper Saddle River, NJ: Prentice-Hall, 2002. LUOet al.: ZUBOV-NET: ADAPTIVE STABILITY FOR NEURAL ODES RECONCILING ACCURACY WITH ROBUSTNESS 13 APPENDIX PROOF OFPROPOSITION1 Proof.We prove the convexity ofg k(x, c)by mathematical induction over the network depthk. It is easy to see the following fact: for any convex no...
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.