RedNote-Vibe: A Dataset for Capturing Temporal Dynamics of AI-Generated Text in Lifestyle Social Media
Pith reviewed 2026-05-18 13:42 UTC · model grok-4.3
The pith
A five-year lifestyle social media dataset shows human posts keep an emotional edge while strategic AI use can lift engagement for some creators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RedNote-Vibe supplies five years of lifestyle posts with engagement data to track how AI-generated text has evolved on the platform. The PsychoLinguistic AIGT Detection Framework (PLAD) uses deep psychological signatures to identify AI text more effectively than prior tools. Tests show PLAD performs better and the data indicate human content outperforms AI in emotionally resonant areas, AI text is more homogeneous and seldom breaks through, the human-AI difference narrows for higher-investment interactions, and a small set of users who apply AI strategically reach higher engagement.
What carries the argument
The PsychoLinguistic AIGT Detection Framework (PLAD), which extracts psychological signatures grounded in cognitive psychology to detect AI-generated text in short posts.
If this is right
- Human posts continue to hold an advantage when emotional resonance matters most.
- AI-generated content tends to be uniform and rarely produces the most engaging or novel posts.
- The gap between human and AI performance shrinks when users invest more in interactions.
- A minority of creators who combine AI tools with their own input achieve higher engagement than typical users.
Where Pith is reading between the lines
- Detection methods like PLAD could be adapted to track AI influence on other social platforms over time.
- Platforms focused on lifestyle or emotional topics might prioritize or label human-created posts to maintain audience connection.
- Everyday creators could test simple strategies for blending AI assistance with personal voice to improve reach without losing authenticity.
Load-bearing premise
The dataset labels correctly separate human from AI posts across the full five-year span and the chosen psychological markers stay distinct and measurable in brief social media text.
What would settle it
A manual check that reveals many posts labeled human or AI are actually the opposite, or new verified posts where PLAD loses the accuracy reported in the experiments.
Figures







read the original abstract
We introduce RedNote-Vibe, a dataset spanning five years (pre-LLM to July 2025) sourced from lifestyle platform RedNote (Xiaohongshu), capturing the temporal dynamics of content creation and is enriched with comprehensive engagement metrics. To address the detection challenge posed by RedNote-Vibe, we propose the \textbf{PsychoLinguistic AIGT Detection Framework (PLAD)}. Grounded in cognitive psychology, PLAD leverages deep psychological signatures for robust and interpretable detection. Our experiments demonstrate PLAD's superior performance and reveal insights into content dynamics: (1) human content continues to outperform AI in emotionally resonant domains; (2) AI content is more homogeneous and rarely produces breaking posts, however, this human-AI gap narrows for arousing higher-investment interactions; and (3) most interestingly, a small group of users who strategically utilize AI tools can achieve higher engagement outcomes. The dataset is available at https://github.com/ydli-ai/RedNote-Vibe
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RedNote-Vibe, a five-year dataset of lifestyle posts from the RedNote (Xiaohongshu) platform that includes engagement metrics and binary AI-generated versus human-authored labels. It proposes the PsychoLinguistic AIGT Detection Framework (PLAD), which applies cognitive-psychology-derived signatures for interpretable detection of AI-generated text. Experiments are reported to show PLAD outperforming baselines, together with three main findings: human content retains an edge in emotionally resonant domains, AI content is more homogeneous and rarely produces breaking posts (with the gap narrowing for higher-investment interactions), and a small subset of users who strategically combine AI tools achieve higher engagement.
Significance. If the labeling procedure proves reliable and the psychological features remain stable, the dataset supplies a valuable longitudinal resource for studying temporal shifts in AI-generated social-media content, while PLAD offers an interpretable alternative to purely statistical detectors. The engagement analyses could inform platform design and creator strategies, particularly the observation that strategic AI use can close or reverse performance gaps.
major comments (3)
- Dataset Construction section: the procedure used to assign AI versus human labels across the full five-year span (pre-LLM through July 2025) is not specified in sufficient detail. It is unclear whether labels derive from self-reports, platform metadata, post-hoc application of modern detectors, or a hybrid method, and whether any temporal calibration was performed. Because every reported insight (emotional superiority, homogeneity, strategic-user gains) rests on this partition, any systematic bias in early-period labeling would propagate directly into the PLAD performance numbers and the three headline claims.
- PLAD Framework and Experiments sections: the manuscript asserts that the psychological signatures are both distinct and reliably extractable from short posts, yet provides no quantitative validation (e.g., feature ablation, inter-rater reliability on signature annotation, or checks for platform-specific stylistic artifacts). Without such evidence, the claimed superiority of PLAD and the interpretation of engagement gaps remain difficult to evaluate.
- Results and Analysis sections: the headline finding that 'a small group of users who strategically utilize AI tools can achieve higher engagement outcomes' is presented without a clear operational definition of 'strategic utilization' or controls for confounding variables such as user popularity, posting frequency, or topic selection. This weakens the causal interpretation offered in the abstract.
minor comments (3)
- Abstract: the phrase 'comprehensive engagement metrics' is used without enumeration; listing the primary metrics (likes, comments, saves, etc.) would improve immediate readability.
- Figure captions and tables: several engagement-gap plots lack error bars or sample-size annotations, making it hard to judge the statistical robustness of the reported narrowing of the human-AI gap in higher-investment interactions.
- Related Work: the discussion of prior AIGT detectors would benefit from explicit comparison tables that include both detection accuracy and interpretability metrics alongside PLAD.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment below and revised the manuscript to improve clarity, reproducibility, and the strength of our claims.
read point-by-point responses
-
Referee: Dataset Construction section: the procedure used to assign AI versus human labels across the full five-year span (pre-LLM through July 2025) is not specified in sufficient detail. It is unclear whether labels derive from self-reports, platform metadata, post-hoc application of modern detectors, or a hybrid method, and whether any temporal calibration was performed. Because every reported insight (emotional superiority, homogeneity, strategic-user gains) rests on this partition, any systematic bias in early-period labeling would propagate directly into the PLAD performance numbers and the three headline claims.
Authors: We agree that the original description of the labeling procedure was insufficiently detailed. The revised manuscript now expands the Dataset Construction section to explicitly describe the hybrid approach: platform metadata and available user disclosures for post-2023 content, combined with calibrated post-hoc detection using contemporary models for earlier periods. We also added a dedicated subsection on temporal calibration, including threshold adjustments based on LLM capability timelines and a limitations discussion addressing potential propagation of labeling bias into the reported findings. revision: yes
-
Referee: PLAD Framework and Experiments sections: the manuscript asserts that the psychological signatures are both distinct and reliably extractable from short posts, yet provides no quantitative validation (e.g., feature ablation, inter-rater reliability on signature annotation, or checks for platform-specific stylistic artifacts). Without such evidence, the claimed superiority of PLAD and the interpretation of engagement gaps remain difficult to evaluate.
Authors: We accept that additional quantitative validation is required. The revised Experiments section now includes feature ablation results demonstrating the incremental contribution of each cognitive-psychology signature, inter-rater reliability statistics on a manually annotated subset of posts, and explicit checks comparing signature distributions against non-RedNote social-media corpora to rule out platform-specific artifacts. These additions directly support the interpretability and performance claims for PLAD. revision: yes
-
Referee: Results and Analysis sections: the headline finding that 'a small group of users who strategically utilize AI tools can achieve higher engagement outcomes' is presented without a clear operational definition of 'strategic utilization' or controls for confounding variables such as user popularity, posting frequency, or topic selection. This weakens the causal interpretation offered in the abstract.
Authors: We acknowledge the need for greater precision here. The revised Results section now provides an explicit operational definition of strategic utilization (users who post AI-assisted content with documented human editing and timing optimization). We further added multivariate regression models that control for follower count, posting frequency, and topic category. The updated analysis retains the reported engagement advantage while clarifying that the evidence remains observational rather than strictly causal. revision: yes
Circularity Check
No circularity; derivation grounded in external literature
full rationale
The paper introduces RedNote-Vibe dataset and PLAD detection framework explicitly grounded in cognitive psychology literature rather than self-referential fitting or equations. No load-bearing steps reduce by construction to inputs, fitted predictions, or self-citation chains; the central claims rest on external psychological signatures and dataset construction details that are presented as independent. This is the most common honest finding for dataset papers without mathematical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cognitive psychology supplies distinct, extractable signatures that reliably separate AI-generated from human text in lifestyle social media posts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PLAD quantifies text into a suite of psycholinguistic features... decision tree-based model for classification
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
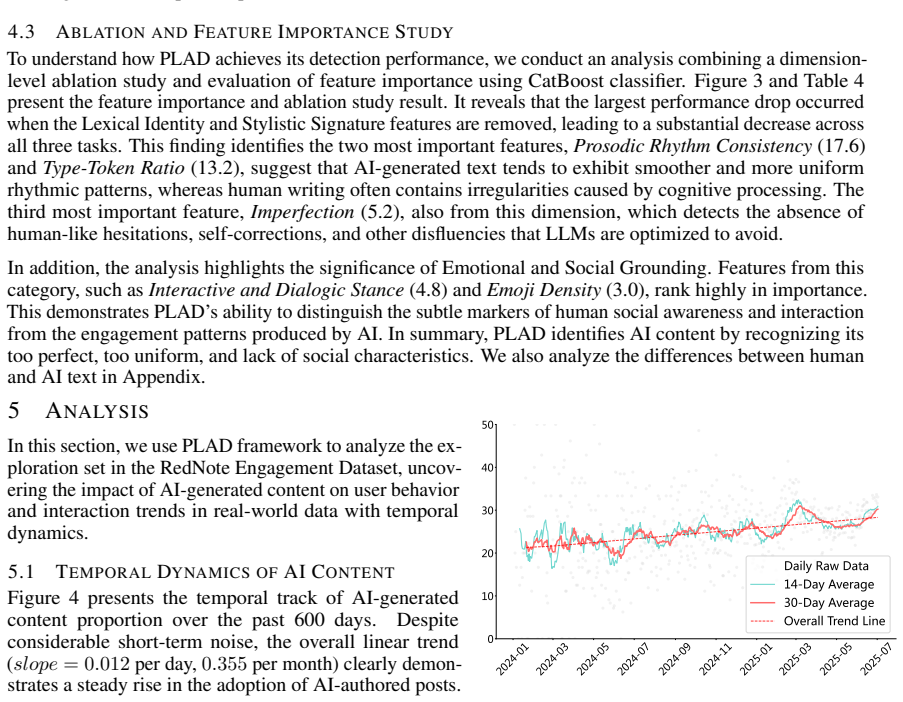
Temporal evolution of AI content proportion... steady rise in the adoption of AI-authored posts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Who said that? benchmarking social media ai detection.arXiv preprint arXiv:2310.08240,
Wanyun Cui, Linqiu Zhang, Qianle Wang, and Shuyang Cai. Who said that? benchmarking social media ai detection.arXiv preprint arXiv:2310.08240,
-
[3]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
work page 2019
-
[4]
Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad Rahwan, and Sune Lehmann. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm.arXiv preprint arXiv:1708.00524,
-
[5]
German Gritsai, Anastasia V oznyuk, Andrey Grabovoy, and Yury Chekhovich. Are ai detectors good enough? a survey on quality of datasets with machine-generated texts.arXiv preprint arXiv:2410.14677,
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Spotting llms with binoculars: Zero-shot detection of machine-generated text
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Spotting llms with binoculars: Zero-shot detection of machine-generated text.arXiv preprint arXiv:2401.12070,
-
[8]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations.arXiv preprint arXiv:1909.11942,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[9]
Origin tracing and detecting of llms
Linyang Li, Pengyu Wang, Ke Ren, Tianxiang Sun, and Xipeng Qiu. Origin tracing and detecting of llms. arXiv preprint arXiv:2304.14072,
-
[10]
Shengchao Liu, Xiaoming Liu, Yichen Wang, Zehua Cheng, Chengzhengxu Li, Zhaohan Zhang, Yu Lan, and Chao Shen. Does detectgpt fully utilize perturbation? bridging selective perturbation to fine-tuned contrastive learning detector would be better.arXiv preprint arXiv:2402.00263,
-
[11]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[12]
URL https://developers.googleblog.com/zh-hans/gemini-2-family-expands/ . Accessed: 2025-05-
work page 2025
-
[13]
Named entity recognition for chinese social media with jointly trained embeddings
Nanyun Peng and Mark Dredze. Named entity recognition for chinese social media with jointly trained embeddings. InProceedings of the 2015 conference on empirical methods in natural language processing, pp. 548–554,
work page 2015
-
[14]
Can AI-Generated Text be Reliably Detected?
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. Can ai-generated text be reliably detected?arXiv preprint arXiv:2303.11156,
-
[15]
Joseph S Schafer, Kayla Duskin, Stephen Prochaska, Morgan Wack, Anna Beers, Lia Bozarth, Taylor Agajanian, Mike Caulfield, Emma S Spiro, and Kate Starbird. Electionrumors2022: A dataset of election rumors on twitter during the 2022 us midterms.arXiv preprint arXiv:2407.16051,
-
[16]
Yuhui Shi, Qiang Sheng, Juan Cao, Hao Mi, Beizhe Hu, and Danding Wang. Ten words only still help: Improving black-box ai-generated text detection via proxy-guided efficient re-sampling.arXiv preprint arXiv:2402.09199,
-
[17]
Evangelia Spiliopoulou, Riccardo Fogliato, Hanna Burnsky, Tamer Soliman, Jie Ma, Graham Horwood, and Miguel Ballesteros. Play favorites: A statistical method to measure self-bias in llm-as-a-judge.arXiv preprint arXiv:2508.06709,
-
[18]
Idiosyncrasies in large language models
Mingjie Sun, Yida Yin, Zhiqiu Xu, J Zico Kolter, and Zhuang Liu. Idiosyncrasies in large language models. arXiv preprint arXiv:2502.12150,
-
[19]
Machine-generated text localization
Zhongping Zhang, Wenda Qin, and Bryan Plummer. Machine-generated text localization. InFindings of the Association for Computational Linguistics ACL 2024, pp. 8357–8371,
work page 2024
-
[20]
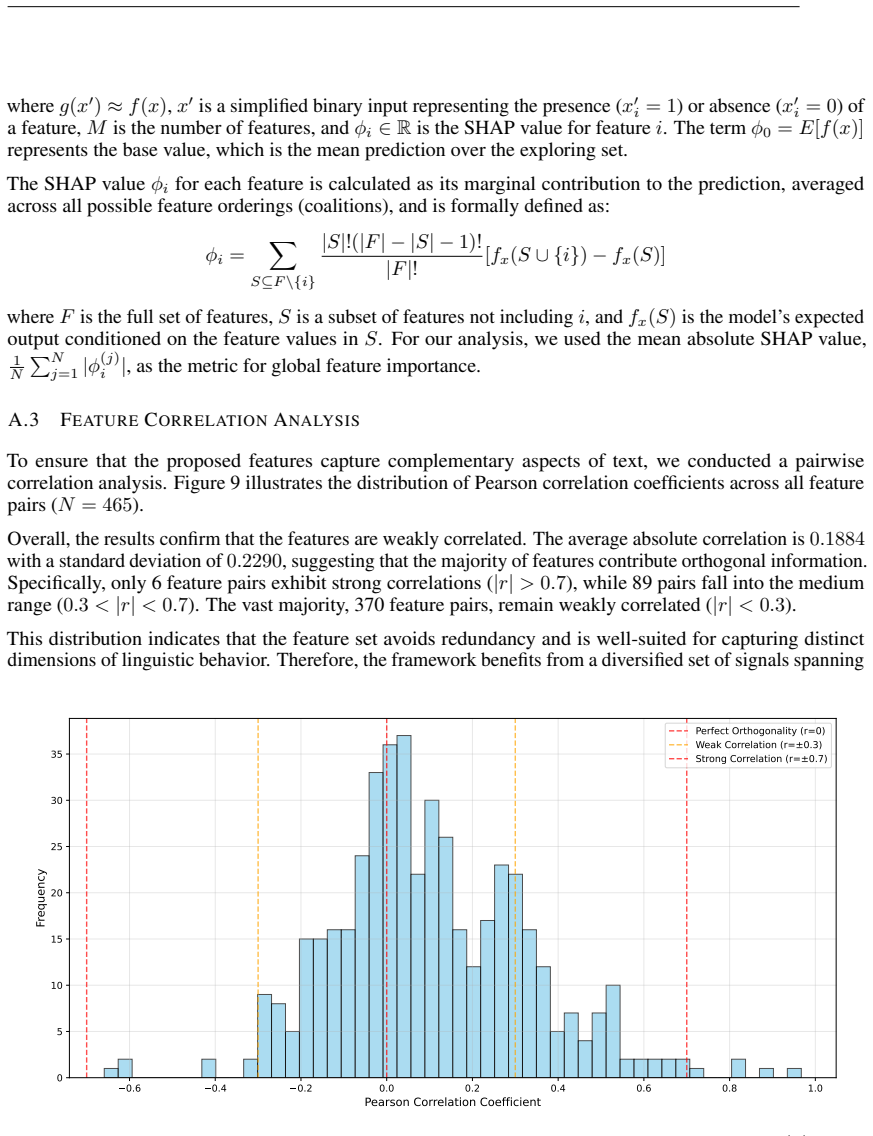
13 APPENDIX In the Appendix, we provide further analysis, including the differences between human-written text and AI-generated text from the perspective of the PLAD framework (Section A.1) and how these features affect the engagement metrics of posts (Section A.2). In addition, we analyze the correlation between features, reflecting the orthogonality of ...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.