Guidance Watermarking for Diffusion Models
Pith reviewed 2026-05-18 12:58 UTC · model grok-4.3
The pith
By using gradients from any off-the-shelf watermark decoder to guide the diffusion process, post-hoc watermarking schemes can be converted into in-generation embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that guiding the diffusion sampling process with the gradient computed from a watermark decoder, incorporating image augmentations, effectively embeds the watermark along the generation trajectory. This converts post-hoc schemes into in-generation embeddings without requiring model-specific tuning or retraining. The method is shown to be complementary to techniques that modify the variational autoencoder at the end of the diffusion process and preserves both diversity and quality of generated images for a given seed and prompt.
What carries the argument
The watermarking guidance mechanism that computes gradients from the decoder after applying various image augmentations to steer the diffusion trajectory.
If this is right
- The watermark becomes embedded during generation rather than applied afterward.
- Robustness to attacks increases because augmentations are included in the gradient computation.
- No retraining or fine-tuning of the diffusion model or decoder is needed.
- The approach complements VAE modification techniques at the end of diffusion.
- Generated image quality and diversity remain largely unchanged.
Where Pith is reading between the lines
- This guidance approach could extend to other generative models by adapting the gradient computation for their sampling processes.
- Watermarking might become a built-in step in standard generation pipelines for better traceability of AI content.
- Further tests with different attack types or augmentation combinations could identify additional robustness benefits.
Load-bearing premise
The gradient signal from an unmodified off-the-shelf watermark decoder remains sufficiently strong and stable throughout the diffusion trajectory even after image augmentations.
What would settle it
Showing that watermark detection rates drop sharply or that images deviate noticeably in quality or diversity for fixed seeds and prompts when the guidance is applied.
Figures











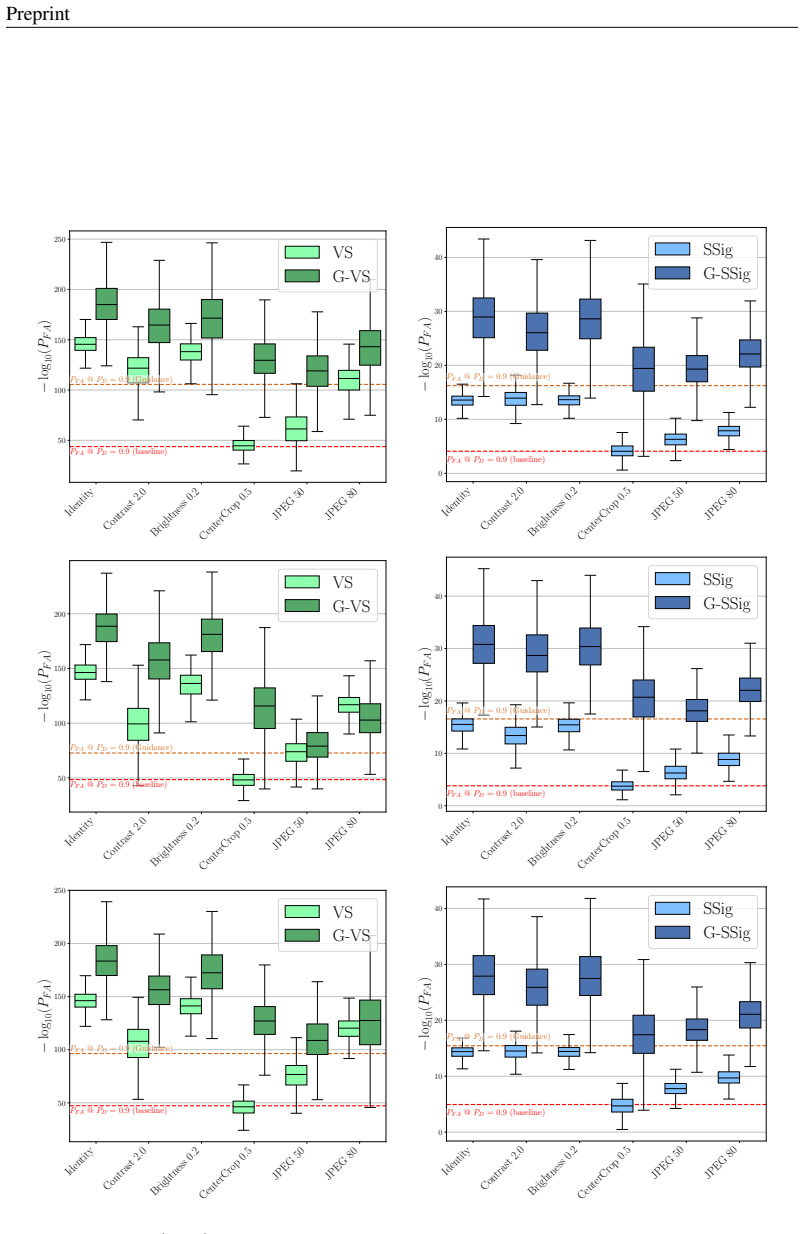




read the original abstract
This paper introduces a novel watermarking method for diffusion models. It is based on guiding the diffusion process using the gradient computed from any off-the-shelf watermark decoder. The gradient computation encompasses different image augmentations, increasing robustness to attacks against which the decoder was not originally robust, without retraining or fine-tuning. Our method effectively convert any \textit{post-hoc} watermarking scheme into an in-generation embedding along the diffusion process. We show that this approach is complementary to watermarking techniques modifying the variational autoencoder at the end of the diffusion process. We validate the methods on different diffusion models and detectors. The watermarking guidance does not significantly alter the generated image for a given seed and prompt, preserving both the diversity and quality of generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Guidance Watermarking for diffusion models, which embeds watermarks by guiding the denoising process with gradients computed from any off-the-shelf watermark decoder. Augmentations are applied during gradient computation to improve robustness without retraining the decoder or the diffusion model. The central claim is that this converts any post-hoc watermarking scheme into an in-generation embedding along the full diffusion trajectory; the method is presented as complementary to VAE-based watermarking and is claimed to preserve generation quality and diversity, with validation across multiple diffusion models and detectors.
Significance. If the central claim holds with quantitative support, the approach would provide a practical, model-agnostic route to integrate watermarking into existing diffusion pipelines, avoiding the need for decoder or model retraining. The use of augmentations to strengthen the guidance signal and the complementarity to VAE modifications are potentially useful contributions to generative-model security. However, the absence of metrics in the high-level description limits the assessed significance at present.
major comments (2)
- Abstract: the claim that the method 'effectively convert[s] any post-hoc watermarking scheme into an in-generation embedding along the diffusion process' and works 'without model-specific tuning' rests on the unexamined assumption that the unmodified decoder gradient supplies a usable signal even at high-noise early timesteps; no analysis, scaling schedule, or ablation addressing timestep dependence is referenced, which is load-bearing for the full-trajectory conversion claim.
- Abstract: validation is asserted 'across models and detectors' with 'no significant quality loss,' yet the description supplies no quantitative metrics (e.g., FID, CLIP score, watermark detection rates, or attack success rates), ablation results, or experimental details; this prevents evaluation of whether the guidance actually achieves reliable embedding throughout the trajectory.
minor comments (2)
- Abstract: grammatical error in 'Our method effectively convert any post-hoc...'; should read 'converts'.
- Abstract: the phrase 'the watermarking guidance does not significantly alter the generated image for a given seed and prompt' would benefit from a brief statement of the quantitative threshold used to define 'significant' alteration.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our contributions. We respond to each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: Abstract: the claim that the method 'effectively convert[s] any post-hoc watermarking scheme into an in-generation embedding along the diffusion process' and works 'without model-specific tuning' rests on the unexamined assumption that the unmodified decoder gradient supplies a usable signal even at high-noise early timesteps; no analysis, scaling schedule, or ablation addressing timestep dependence is referenced, which is load-bearing for the full-trajectory conversion claim.
Authors: We thank the referee for this observation. The guidance signal is applied at every timestep of the reverse process, and our experiments demonstrate that the unmodified decoder produces a sufficiently informative gradient to achieve reliable embedding without per-model tuning. Nevertheless, we agree that an explicit analysis of signal strength and effectiveness at high-noise timesteps would better substantiate the full-trajectory claim. In the revised manuscript we will add an ablation examining gradient magnitude and watermark success rate across timesteps together with the guidance-weight scaling schedule used in all reported experiments. revision: yes
-
Referee: Abstract: validation is asserted 'across models and detectors' with 'no significant quality loss,' yet the description supplies no quantitative metrics (e.g., FID, CLIP score, watermark detection rates, or attack success rates), ablation results, or experimental details; this prevents evaluation of whether the guidance actually achieves reliable embedding throughout the trajectory.
Authors: The abstract is written as a high-level summary; the full manuscript reports quantitative results in the Experiments section, including FID and CLIP scores for quality, detection rates under clean and attacked conditions, and comparisons across multiple diffusion models and watermark decoders. To improve immediate readability we will revise the abstract to incorporate a small number of representative metrics (e.g., average detection rate and FID delta) while preserving conciseness. revision: partial
Circularity Check
No circularity: guidance defined directly from external decoder gradients
full rationale
The paper's central construction uses the gradient signal from any unmodified off-the-shelf watermark decoder (with augmentations) to steer the diffusion trajectory. This mechanism is defined independently of the target embedding result and does not reduce to a fitted parameter, self-referential loop, or self-citation chain. The conversion of post-hoc schemes into in-generation embedding is presented as an empirical outcome of the guidance process rather than an input by construction. No uniqueness theorems, ansatzes smuggled via prior author work, or renaming of known results appear in the derivation. The method remains self-contained against external benchmarks such as existing decoders and diffusion models.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our method resorts to conditional sampling ... ˆϵ(zt, t) := ϵθ(zt, t) − ω / √(1−ᾱt) ∇zt log L(zt, um)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The gradient computation encompasses different image augmentations ... PCGrad algorithm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
https://media.defense.gov/2025/Jan/29/2003634788/-1/-1/0/CSI-CONTENT-CREDENTIALS.PDF, 2025
Content credentials: Strengthening multimedia integrity in the generative AI era. https://media.defense.gov/2025/Jan/29/2003634788/-1/-1/0/CSI-CONTENT-CREDENTIALS.PDF, 2025. USA National Security Agency, Australian Signals Directorate’s Australian Cyber Security Centre, Canadian Centre for Cyber Security, and United Kingdom National Cyber Security Centre
work page 2025
-
[3]
The AI Waterfall : A Case Study in Integrating Machine Learning and Security
Patrick Bas and Jan Butora. The AI Waterfall : A Case Study in Integrating Machine Learning and Security . working paper or preprint, April 2025. URL https://hal.science/hal-05011387
work page 2025
-
[4]
Black Forest Labs . Flux. https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[5]
Nepotistically trained generative image models collapse
Maty Bohacek and Hany Farid. Nepotistically trained generative image models collapse. In ICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models, 2025. URL https://openreview.net/forum?id=mkZB0fKLX8
work page 2025
-
[6]
Tu Bui, Shruti Agarwal, and John Collomosse. TrustMark : Universal Watermarking for Arbitrary Resolution Images , November 2023. URL http://arxiv.org/abs/2311.18297. arXiv:2311.18297 [cs]
-
[7]
C2PA : The coalition for content provenance and authenticity
C2PA. C2PA : The coalition for content provenance and authenticity. https://c2pa.org, 2024
work page 2024
-
[8]
China. Chinese AI governance rules. http://www.cac.gov.cn/2023-07/13/c_1690898327029107.htm, 2023
work page 2023
-
[9]
Asymptotically optimum universal watermark embedding and detection in the high-snr regime
Pedro Comesana, Neri Merhav, and Mauro Barni. Asymptotically optimum universal watermark embedding and detection in the high-snr regime. IEEE Transactions on Information Theory, 56 0 (6): 0 2804--2815, 2010. doi:10.1109/TIT.2010.2046223
-
[10]
On the detection of synthetic images generated by diffusion models
Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. On the detection of synthetic images generated by diffusion models. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5. IEEE, 2023
work page 2023
-
[11]
M. Costa. Writing on dirty paper (corresp.). IEEE Transactions on Information Theory, 29 0 (3): 0 439--441, 1983. doi:10.1109/TIT.1983.1056659
-
[12]
Ingemar J. Cox. Digital watermarking and steganography. The Morgan Kaufmann series in multimedia information and systems. Morgan Kaufmann Publishers, Amsterdam Boston, 2nd ed edition, 2008. ISBN 978-0-12-372585-1
work page 2008
-
[13]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=mZn2Xyh9Ec
work page 2024
-
[14]
Diffusion models beat GAN s on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GAN s on image synthesis. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=AAWuCvzaVt
work page 2021
-
[15]
Digital watermarking applications
Digital Watermarking Alliance DWA. Digital watermarking applications. https://digitalwatermarkingalliance.org/digital-watermarking-applications/
-
[16]
Europe. European AI Act . https://artificialintelligenceact.eu/, 2023
work page 2023
-
[17]
Watermarking Images in Self-Supervised Latent Spaces
Pierre Fernandez, Alexandre Sablayrolles, Teddy Furon, Herv \'e J \'e gou, and Matthijs Douze. Watermarking Images in Self-Supervised Latent Spaces . In IEEE (ed.), ICASSP 2022 - IEEE International Conference on Acoustics, Speech and Signal Processing , pp.\ 1--5, Singapore, Singapore, May 2022. IEEE , IEEE . URL https://inria.hal.science/hal-03591396
work page 2022
-
[18]
The stable signature: Rooting watermarks in latent diffusion models
Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. The stable signature: Rooting watermarks in latent diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, 2023
work page 2023
-
[19]
Video seal: Open and efficient video watermarking
Pierre Fernandez, Hady Elsahar, I. Zeki Yalniz, and Alexandre Mourachko. Video Seal : Open and Efficient Video Watermarking , December 2024 a . URL http://arxiv.org/abs/2412.09492. arXiv:2412.09492 [cs]
-
[20]
What lies ahead for generative ai watermarking
Pierre Fernandez, Anthony Level, and Teddy Furon. What lies ahead for generative ai watermarking. In 2nd Workshop on Generative AI and Law (GenLaw ’24), ICML, 2024 b
work page 2024
-
[21]
About zero bit watermarking error exponents
Teddy Furon. About zero bit watermarking error exponents . In ICASSP2017 - IEEE International Conference on Acoustics, Speech and Signal Processing , New Orleans, United States, March 2017. IEEE . URL https://inria.hal.science/hal-01512705
work page 2017
-
[22]
Byzantine machine learning: A primer
Rachid Guerraoui, Nirupam Gupta, and Rafael Pinot. Byzantine machine learning: A primer. ACM Computing Surveys, 56 0 (7): 0 1--39, 2024
work page 2024
-
[23]
CLIPS core: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPS core: A reference-free evaluation metric for image captioning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 7514--7528, Online and Punta Cana, D...
-
[24]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017
work page 2017
-
[25]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
work page 2020
-
[26]
Robin: Robust and invisible watermarks for diffusion models with adversarial optimization
Huayang Huang, Yu Wu, and Qian Wang. Robin: Robust and invisible watermarks for diffusion models with adversarial optimization. Advances in Neural Information Processing Systems, 37: 0 3937--3963, 2025
work page 2025
-
[27]
Diffusion models for counterfactual explanations
Guillaume Jeanneret, Loic Simon, and Frederic Jurie. Diffusion models for counterfactual explanations. In Proceedings of the Asian Conference on Computer Vision (ACCV), pp.\ 858--876, December 2022
work page 2022
-
[28]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learnin...
work page 2023
-
[29]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll \'a r, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer vision--ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13, pp.\ 740--755. Springer, 2014
work page 2014
-
[30]
Conflict-averse gradient descent for multi-task learning
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning. Advances in Neural Information Processing Systems, 34: 0 18878--18890, 2021
work page 2021
-
[31]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in Neural Information Processing Systems, 35: 0 5775--5787, 2022
work page 2022
-
[32]
Improved denoising diffusion probabilistic models, 2021
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models, 2021. URL https://openreview.net/forum?id=-NEXDKk8gZ
work page 2021
-
[33]
Channel coding rate in the finite blocklength regime
Yury Polyanskiy, H Vincent Poor, and Sergio Verd \'u . Channel coding rate in the finite blocklength regime. IEEE Transactions on Information Theory, 56 0 (5): 0 2307--2359, 2010
work page 2010
-
[34]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1 0 (2): 0 3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022 a
work page 2022
-
[36]
Masked feature prediction for self-supervised visual pre-training
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High- Resolution Image Synthesis with Latent Diffusion Models . In 2022 IEEE / CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , pp.\ 10674--10685, New Orleans, LA, USA, June 2022 b . IEEE. ISBN 978-1-6654-6946-3. doi:10.1109/CVPR52688.2022.01042. URL http...
-
[37]
Harold Ruben. Probability content of regions under spherical normal distributions, iv: The distribution of homogeneous and non-homogeneous quadratic functions of normal variables. The Annals of Mathematical Statistics, Ann. Math. Statist, 33 0 (2): 0 542--570, 1962
work page 1962
-
[38]
Proactive detection of voice cloning with localized watermarking
Robin San Roman, Pierre Fernandez, Hady Elsahar, Alexandre D \'e fossez, Teddy Furon, and Tuan Tran. Proactive detection of voice cloning with localized watermarking. In ICML 2024-41st International Conference on Machine Learning, volume 235, pp.\ 1--17, 2024
work page 2024
-
[39]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=St1giarCHLP
work page 2021
-
[40]
Ensuring safe, secure, and trustworthy AI
USA . Ensuring safe, secure, and trustworthy AI . https://www.whitehouse.gov/wp-content/uploads/2023/07/Ensuring-Safe-Secure-and-Trustworthy-AI.pdf, July 2023. Accessed: [july 2023]
work page 2023
-
[41]
FABRIC : Personalizing diffusion models with iterative feedback, 2024
Dimitri von R \"u tte, Elisabetta Fedele, Jonathan Thomm, and Lukas Wolf. FABRIC : Personalizing diffusion models with iterative feedback, 2024. URL https://openreview.net/forum?id=zsfrzYWoOP
work page 2024
-
[42]
Tree-rings watermarks: Invisible fingerprints for diffusion images
Yuxin Wen, John Kirchenbauer, Jonas Geiping, and Tom Goldstein. Tree-rings watermarks: Invisible fingerprints for diffusion images. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=Z57JrmubNl
work page 2023
-
[43]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. Sana: Efficient high-resolution image synthesis with linear diffusion transformer, 2024. URL https://arxiv.org/abs/2410.10629
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Oona Rainio, Jarmo Teuho, and Riku Klén
Rui Xu, Mengya Hu, Deren Lei, Yaxi Li, David Lowe, Alex Gorevski, Mingyu Wang, Emily Ching, and Alex Deng. Invismark: Invisible and robust watermarking for ai-generated image provenance. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp.\ 909--918, 2025. doi:10.1109/WACV61041.2025.00098
-
[45]
Gaussian shading: Provable performance-lossless image watermarking for diffusion models
Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weiming Zhang, and Nenghai Yu. Gaussian shading: Provable performance-lossless image watermarking for diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 12162--12171, 2024
work page 2024
-
[46]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 5824--5836. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_...
work page 2020
-
[47]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 3836--3847, 2023
work page 2023
-
[48]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 586--595, 2018
work page 2018
-
[49]
Hidden: Hiding data with deep networks
Jiren Zhu, Russell Kaplan, Justin Johnson, and Li Fei-Fei. Hidden: Hiding data with deep networks. In Proceedings of the European conference on computer vision (ECCV), pp.\ 657--672, 2018
work page 2018
-
[50]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[51]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[52]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.