MARCH: Evaluating the Intersection of Ambiguity Interpretation and Multi-hop Inference
Pith reviewed 2026-05-18 13:53 UTC · model grok-4.3
The pith
Models struggle when ambiguity appears at multiple stages of multi-hop reasoning, and a new benchmark plus two-stage framework expose and address the gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
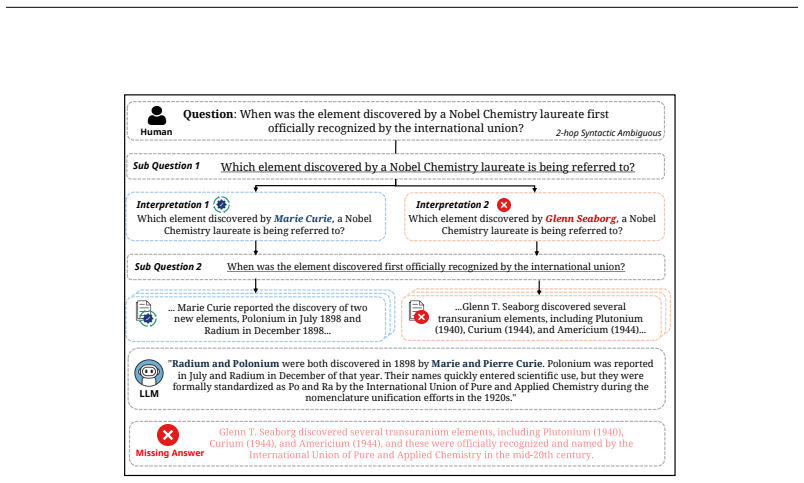
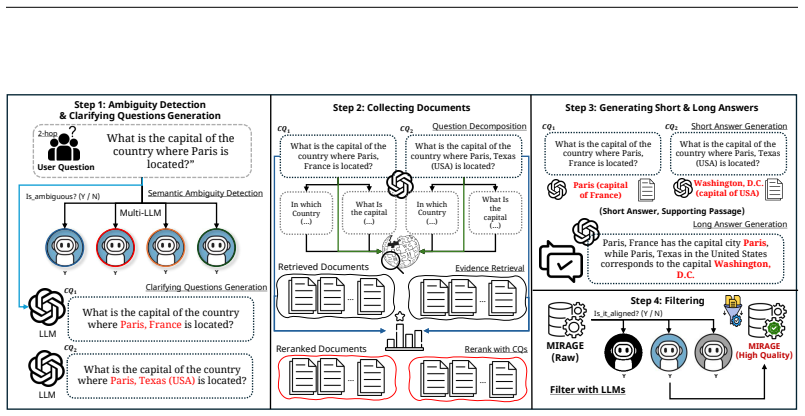
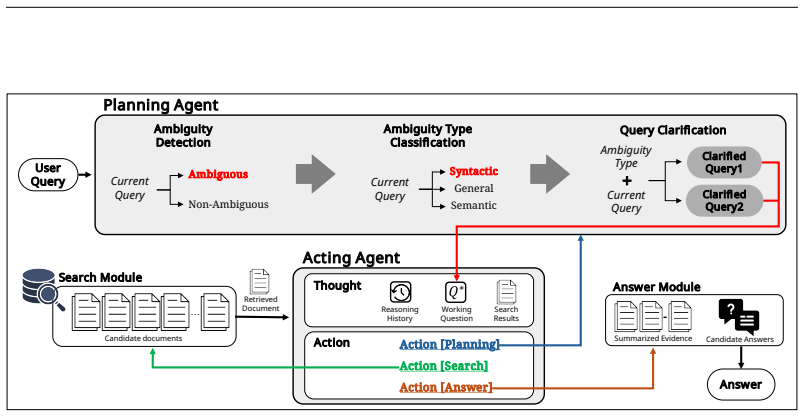
Real-world multi-hop QA naturally involves ambiguity that can arise at any stage and therefore demands navigation of layered uncertainty throughout the chain. The MARCH benchmark, built from multi-LLM verification and human validation, shows that state-of-the-art models struggle with this combination. CLARION, a two-stage agentic framework that explicitly decouples ambiguity planning from evidence-driven reasoning, significantly outperforms prior methods on the benchmark.
What carries the argument
MARCH benchmark of multi-hop ambiguous questions paired with the CLARION two-stage framework that separates ambiguity planning from subsequent evidence-based reasoning.
If this is right
- Systems able to handle MARCH would show improved capacity to manage uncertainty that surfaces at different points in longer reasoning chains.
- Decoupling ambiguity planning from evidence collection can serve as a template for other agentic setups that face similar layered decisions.
- Future multi-hop benchmarks should include ambiguity at multiple stages to match the structure of real user questions.
- Better performance on MARCH-style tasks would support more reliable answers in domains where queries routinely contain multiple possible interpretations.
Where Pith is reading between the lines
- The same separation of planning and execution could be tested on multi-hop tasks outside question answering, such as planning or code generation under incomplete specifications.
- Adding explicit ambiguity tracking might reduce error propagation in long reasoning traces even when the base model is not changed.
- Scaling the benchmark to include more languages or domains would clarify whether the observed difficulty is language-specific or structural.
Load-bearing premise
The curation process using multi-LLM verification and human annotation with strong agreement produces questions that genuinely capture layered uncertainty in real multi-hop queries rather than generation artifacts.
What would settle it
A model that reaches high accuracy on the full MARCH test set while using only single-stage prompting or standard chain-of-thought without any explicit ambiguity-planning step would indicate that the claimed interaction between ambiguity and multi-hop reasoning is not as hard as the benchmark suggests.
Figures















read the original abstract
Real-world multi-hop QA is naturally linked with ambiguity, where a single query can trigger multiple reasoning paths that require independent resolution. Since ambiguity can occur at any stage, models must navigate layered uncertainty throughout the entire reasoning chain. Despite its prevalence in real-world user queries, previous benchmarks have primarily focused on single-hop ambiguity, leaving the complex interaction between multi-step inference and layered ambiguity underexplored. In this paper, we introduce MARCH, a benchmark for their intersection, with 2,209 multi-hop ambiguous questions curated via multi-LLM verification and validated by human annotation with strong agreement. Our experiments reveal that even state-of-the-art models struggle with MARCH, confirming that combining ambiguity resolution with multi-step reasoning is a significant challenge. To address this, we propose CLARION, a two-stage agentic framework that explicitly decouples ambiguity planning from evidence-driven reasoning, significantly outperforms existing approaches, and paves the way for robust reasoning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MARCH, a benchmark of 2,209 multi-hop ambiguous questions curated via multi-LLM verification and human annotation with strong agreement. It shows that state-of-the-art models struggle on these questions, confirming the challenge of combining ambiguity resolution with multi-step reasoning. The authors propose CLARION, a two-stage agentic framework that decouples ambiguity planning from evidence-driven reasoning and significantly outperforms existing approaches.
Significance. If the MARCH questions genuinely require resolution of layered, path-dependent ambiguity across multi-hop chains, the benchmark would address a clear gap left by prior single-hop ambiguity or standard multi-hop datasets. The reported model failures and CLARION gains would then indicate a meaningful direction for agentic systems. The multi-LLM-plus-human validation pipeline with strong agreement is a methodological strength that supports reproducibility of the data.
major comments (2)
- [Section 3] Section 3 (Benchmark Construction): The description of the multi-LLM verification and human annotation process does not specify the exact prompts, exclusion criteria, or decision rules used to ensure that selected questions contain ambiguity that must be resolved at multiple distinct stages of a reasoning chain rather than at a single isolated point. This detail is load-bearing for the central claim that MARCH evaluates the intersection of ambiguity interpretation and multi-hop inference.
- [Section 4] Section 4 (Experiments): The manuscript reports outperformance by CLARION and strong human agreement on the 2,209 questions but does not include statistical significance tests (e.g., p-values or confidence intervals) for the performance deltas versus baselines, nor full details on how question generation rules avoid LLM-induced surface artifacts. These omissions prevent full verification of the robustness of the headline claims.
minor comments (2)
- [Abstract] The abstract states 'strong agreement' without reporting the specific inter-annotator agreement metric or numerical value; adding this would improve clarity.
- [Figure 1] Figure 1 (CLARION overview): The two-stage decoupling could be labeled more explicitly on the diagram to make the architectural distinction immediately visible.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important areas for improving the clarity and rigor of the manuscript, and we have revised accordingly to address them while preserving the core contributions of MARCH and CLARION.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Benchmark Construction): The description of the multi-LLM verification and human annotation process does not specify the exact prompts, exclusion criteria, or decision rules used to ensure that selected questions contain ambiguity that must be resolved at multiple distinct stages of a reasoning chain rather than at a single isolated point. This detail is load-bearing for the central claim that MARCH evaluates the intersection of ambiguity interpretation and multi-hop inference.
Authors: We agree that greater specificity is required to substantiate the central claim. In the revised manuscript, Section 3 has been expanded with a dedicated subsection that now includes the exact prompts used for multi-LLM verification, the full set of exclusion criteria (e.g., discarding questions whose ambiguity resolves in a single hop via explicit decision rules), and the multi-stage filtering logic that prioritizes path-dependent ambiguity across hops. These details were documented in our curation pipeline and are now presented in the main text and appendix to ensure reproducibility and to directly support the benchmark's focus on layered ambiguity in multi-hop reasoning. revision: yes
-
Referee: [Section 4] Section 4 (Experiments): The manuscript reports outperformance by CLARION and strong human agreement on the 2,209 questions but does not include statistical significance tests (e.g., p-values or confidence intervals) for the performance deltas versus baselines, nor full details on how question generation rules avoid LLM-induced surface artifacts. These omissions prevent full verification of the robustness of the headline claims.
Authors: We concur that statistical tests and additional artifact-mitigation details strengthen the claims. The revised Section 4 now reports p-values and 95% confidence intervals for all performance deltas, obtained via bootstrap resampling to account for dataset characteristics. We have also added explicit details on question generation rules, including cross-model consistency filtering, human review for surface-level artifacts, and specific heuristics to promote natural ambiguity, with these procedures now fully documented in the main text and supplementary material. revision: yes
Circularity Check
No circularity in empirical benchmark creation or framework evaluation
full rationale
The paper introduces the MARCH benchmark via multi-LLM verification and human annotation with reported strong agreement, then evaluates model performance and proposes the CLARION two-stage framework. No equations, fitted parameters, predictions, or derivations appear in the provided text. All claims rest on new data curation and direct empirical comparisons rather than any reduction to prior definitions, self-citations, or ansatzes by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce MIRAGE... curated via multi-LLM verification... CLARION, a two-stage agentic framework that explicitly decouples ambiguity planning from evidence-driven reasoning
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Jcost uniqueness, phi-ladder, 8-tick period, parameter-free constants
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.63. URL https://aclanthology.org/2023.emnlp-main.63/. Dongryeol Lee, Segwang Kim, Minwoo Lee, Hwanhee Lee, Joonsuk Park, Sang-Woo Lee, and Kyomin Jung. Asking clarification questions to handle ambiguity in open-domain qa. InFindings of the Association for Computational Linguistics...
-
[2]
Read the sentence below
-
[3]
Decide whether it is syntactically ambiguous under any of the 18 phenomena
-
[4]
If ambiguous, list all applicable phenomenon numbers (ascending). Phenomena (1–18)
-
[5]
PP Attachment (including instrument vs. attribute ”with”); 2. Relative-Clause Attachment; 3. Coordination Scope (and/or); 4. Comparative Attachment / Ellipsis
-
[6]
Dangling / Misplaced Modifier; 7
Quantifier / Negation Scope; 6. Dangling / Misplaced Modifier; 7. Genitive-Chain Attachment; 8. Complement vs. Adjunct; 9. Gerund vs. Participle; 10. Ellipsis / Gapping; 11. If-clause Attachment; 12. Right-Node Raising; 13. Adjective Stacking / Coordination; 14. Inclusive vs. Exclusive ”or”; 15. Adverbial Attachment (VP vs. S); 16. Focus / Only-scope; 17....
-
[7]
Read the search query and three RAW metric values
-
[8]
Decide if the query shows general ambiguity (over-specific constraints harming recall)
-
[9]
Output ONLY the JSON object in the required format. A query with general ambiguity (over-specific) is narrowly constrained (dates, version numbers, quoted strings, etc.), likely missing the broader intent. Metrics 19 Total hits: Result count for the literal query. KL divergence: D KL between top-k snippet unigrams and the whole corpus. Relax delta ratio: ...
-
[10]
Identify the core question (fact or relationship truly sought)
-
[11]
Resolve or drop cascading indirections (replace ”the country where X was born” with the direct entity if obvious; else use a neutral placeholder)
-
[12]
Remove or soften excessive constraints (exact dates, versions, quoted titles)
-
[13]
Keep the answer type the same; do not over-broaden. Write concise English. Question: QUESTION Output (JSON): ”clarified queries”: [”...”, ”...”] Key must be exactly ”clarified queries”; provide at least 2 strings; no extra keys. Figure 10: Prompt template for general clarification. You are a linguistics expert. Semantically ambiguous lacks sufficient cont...
-
[14]
Output ”Y” if semantically ambiguous, else ”N”. Question: QUESTION Output (JSON): ”is ambiguous”: ”Y” // ”N” if unambiguous Key must be exactly ”is ambiguous”. No extra text. Figure 11: Prompt template for semantic ambiguity detection. 20 You are a linguistics expert. Rewrite the semantically ambiguous question into at least 2 distinct clarified questions...
-
[15]
Provide brief reasoning
-
[16]
Is the query ambiguous?
-
[17]
Which specific aspects make it ambiguous?
-
[18]
What extra information would clarify it?
-
[19]
Classify the ambiguity as one of:”syntactic”,”general”,”semantic”, or”none”. Definitions: *syntactic: multiple plausible grammatical parses (attachment/scope/coordination/pronoun reference). *general: over-specific query where a broader, closely related formulation better matches the user’s need. *semantic: syntax is clear but meaning/intent admits multip...
-
[20]
THINK about the next best step
-
[21]
If more evidence is needed, chooseSEARCH[very specific query]
-
[22]
If sufficient, chooseANSWER[concise, well-supported answer]
-
[23]
If you have already reached the maximum allowed searches, youmustoutput ANSWER[...]now. Respond inEXACTformat: THOUGHT: <your internal reasoning, one short paragraph> ACTION: SEARCH[...specific query...]OR ACTION: PLANNING[...call planning agent...]OR ACTION: ANSWER[...final answer...] Figure 18: Prompt template for ReAct-style retrieval and answering wit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.