MDP modeling for multi-stage stochastic programs
Pith reviewed 2026-05-18 12:47 UTC · model grok-4.3
The pith
Multi-stage stochastic programs incorporate MDP features by extending policy graphs to handle decision-dependent uncertainty and limited statistical learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By extending policy graphs to include decision-dependent uncertainty for one-step transition probabilities as well as a limited form of statistical learning, the approach allows multi-stage stochastic programs to represent structured MDPs with continuous action and state spaces. New variants of stochastic dual dynamic programming are developed as solution methods, with approximations introduced to address the non-convexities that arise.
What carries the argument
Extended policy graphs that encode decision-dependent one-step transition probabilities together with limited statistical learning, solved approximately by new variants of stochastic dual dynamic programming.
If this is right
- Structured MDPs with continuous spaces become expressible as multi-stage stochastic programs.
- Decision-dependent uncertainty can be modeled directly in the transition structure.
- Limited statistical learning integrates into the policy graph without requiring full retraining at each stage.
- Approximate solutions remain available through adapted stochastic dual dynamic programming despite non-convexities.
Where Pith is reading between the lines
- This modeling style could improve sequential planning in domains such as inventory control or energy systems where actions alter risk distributions.
- The limited learning component might be tested by comparing learned transitions against held-out data on real sequential decision traces.
- Similar extensions could be explored for other forms of state-dependent or history-dependent uncertainty beyond one-step transitions.
Load-bearing premise
The new variants of stochastic dual dynamic programming can effectively approximate solutions for the non-convex models that arise from the extended policy graphs with decision-dependent uncertainty.
What would settle it
A concrete numerical test on a problem with known optimal policy where the proposed SDDP variants produce policies whose expected cost deviates by more than a small tolerance from the true optimum under decision-dependent transitions.
Figures









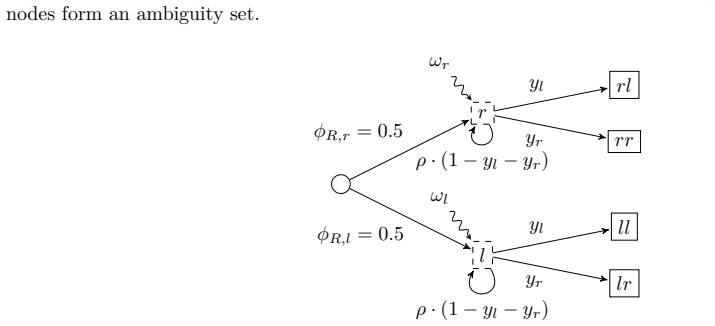




read the original abstract
We study a class of multi-stage stochastic programs, which incorporate modeling features from Markov decision processes (MDPs). This class includes structured MDPs with continuous action and state spaces. We extend policy graphs to include decision-dependent uncertainty for one-step transition probabilities as well as a limited form of statistical learning. We focus on the expressiveness of our modeling approach, illustrating ideas with a series of examples of increasing complexity. As a solution method, we develop new variants of stochastic dual dynamic programming, including approximations to handle non-convexities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a modeling framework that integrates features from Markov decision processes into multi-stage stochastic programs, including structured MDPs with continuous action and state spaces. It extends policy graphs to incorporate decision-dependent uncertainty in one-step transition probabilities along with a limited form of statistical learning. The work emphasizes expressiveness through a series of illustrative examples of increasing complexity and develops new variants of stochastic dual dynamic programming that include approximations to handle resulting non-convexities.
Significance. If the modeling extensions and SDDP variants are shown to be effective with rigorous analysis, the paper could meaningfully increase the expressiveness of multi-stage stochastic programs by allowing decision-dependent uncertainties and learning elements, potentially connecting MDP and stochastic optimization literature. The emphasis on illustrative examples is a constructive element for demonstrating applicability. However, the absence of detailed derivations, identification of non-convexity sources, or convergence properties for the approximations reduces the assessed significance at present.
major comments (1)
- The central claim that new SDDP variants can effectively approximate solutions for the non-convex models arising from extended policy graphs with decision-dependent transitions is load-bearing but unsupported by any specification of the non-convexity source (e.g., bilinear terms in kernels or learned parameters in recourse), the form of the approximation (e.g., outer approximation or sampling-based cuts), or convergence/bound-quality guarantees. This directly affects validation of the algorithmic contribution.
minor comments (1)
- The abstract would benefit from a brief statement clarifying the precise scope and assumptions of the 'limited form of statistical learning' component to aid reader expectations.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments on our manuscript. We provide a point-by-point response to the major comment below and will incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: The central claim that new SDDP variants can effectively approximate solutions for the non-convex models arising from extended policy graphs with decision-dependent transitions is load-bearing but unsupported by any specification of the non-convexity source (e.g., bilinear terms in kernels or learned parameters in recourse), the form of the approximation (e.g., outer approximation or sampling-based cuts), or convergence/bound-quality guarantees. This directly affects validation of the algorithmic contribution.
Authors: We thank the referee for highlighting this important point. The primary source of non-convexity arises from the decision-dependent one-step transition probabilities in the extended policy graphs, which introduce nonlinear dependencies (potentially bilinear when kernels depend linearly on decisions). Our SDDP variants employ sampling-based cut generation combined with outer linearizations to handle these during forward and backward passes. We acknowledge that the current manuscript does not include detailed derivations or formal convergence guarantees, as the emphasis is on modeling expressiveness through illustrative examples rather than full algorithmic analysis. We will revise the paper to add a dedicated subsection explicitly identifying the non-convexity sources, describing the approximation forms used, and discussing bound quality where applicable. revision: yes
Circularity Check
No circularity: modeling extensions and algorithmic variants remain independent of fitted inputs or self-referential definitions
full rationale
The paper's core contribution is an extension of policy graphs to decision-dependent transition probabilities and limited statistical learning, illustrated via examples of increasing complexity, followed by development of new SDDP variants that include approximations for resulting non-convexities. No load-bearing step reduces a claimed prediction or result to a parameter fitted from the same data, a self-citation chain, or an ansatz smuggled in by definition. The derivation chain is self-contained against external benchmarks of SDDP and MDP modeling, with the abstract and described approach showing independent content rather than tautological renaming or construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-stage stochastic programs can incorporate MDP features such as policy graphs while preserving solvability via extended SDDP methods.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop new variants of stochastic dual dynamic programming, including approximations to handle non-convexities.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Decision-dependent one-step transition probabilities introduce non-convexities.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Adiga, R.: Optimizing geothermal well planning under reservoir uncertainty with stochastic programming. Ph.D. thesis, University of Auckland (2024)
work page 2024
-
[2]
Ahmed, S.: Strategic planning under uncertainty: Stochastic integer programming approaches. Ph.D. thesis, University of Illinois at Urbana-Champaign (2000)
work page 2000
-
[3]
In: 2024 Winter Simulation Conference, pp
Arslan, N., Dowson, O., Morton, D.P.: An SDDP algorithm for multistage stochastic programs with decision-dependent uncertainty. In: 2024 Winter Simulation Conference, pp. 3288–3299 (2024) 24
work page 2024
-
[4]
In: Proceedings of the Eighteenth Yale Workshop on Adaptive and Learning Systems (2017)
Barto, A.G., Thomas, P.S., Sutton, R.S.: Some recent applications of reinforcement learning. In: Proceedings of the Eighteenth Yale Workshop on Adaptive and Learning Systems (2017)
work page 2017
-
[5]
Manufacturing & Service Operations Management26(6), 2121–2141 (2024)
Basciftci, B., Ahmed, S., Gebraeel, N.: Adaptive two-stage stochastic programming with an analysis on capacity expansion planning problem. Manufacturing & Service Operations Management26(6), 2121–2141 (2024)
work page 2024
-
[6]
Princeton University Press, Princeton, NJ (1957)
Bellman, R.: Dynamic programming. Princeton University Press, Princeton, NJ (1957)
work page 1957
-
[7]
SIAM Review59(1), 65–98 (2017)
Bezanson, J., Edelman, A., Karpinski, S., Shah, V.B.: Julia: A fresh approach to numerical computing. SIAM Review59(1), 65–98 (2017)
work page 2017
-
[8]
Mathematical Methods of Operations Research98(2), 231–268 (2023)
Bielecki, T.R., Cialenco, I., Ruszczyński, A.: Risk filtering and risk-averse control of Markovian systems subject to model uncertainty. Mathematical Methods of Operations Research98(2), 231–268 (2023)
work page 2023
-
[9]
Springer Science & Business Media, New York, NY (2011)
Birge, J.R., Louveaux, F.: Introduction to stochastic programming. Springer Science & Business Media, New York, NY (2011)
work page 2011
-
[10]
Journal of the Royal Statistical Society Series B: Statistical Methodology78(5), 1103–1130 (2016)
Bissiri, P.G., Holmes, C.C., Walker, S.G.: A general framework for updating belief distributions. Journal of the Royal Statistical Society Series B: Statistical Methodology78(5), 1103–1130 (2016)
work page 2016
-
[11]
Chang, H.S., Hu, J., Fu, M.C., Marcus, S.I.: Simulation-based algorithms for Markov decision processes. Springer, London (2013)
work page 2013
-
[12]
Operations Research51(6), 850–865 (2003)
de Farias, D.P., van Roy, B.: The linear programming approach to approximate dynamic programming. Operations Research51(6), 850–865 (2003)
work page 2003
-
[13]
Dowson, O.: The policy graph decomposition of multistage stochastic programming problems. Networks 76(1), 3–23 (2020)
work page 2020
-
[14]
INFORMS Journal on Computing33(1), 27–33 (2021)
Dowson, O., Kapelevich, L.: SDDP.jl: a Julia package for stochastic dual dynamic programming. INFORMS Journal on Computing33(1), 27–33 (2021)
work page 2021
-
[15]
Operations Research Letters48(4), 505–512 (2020)
Dowson, O., Morton, D.P., Pagnoncelli, B.K.: Partially observable multistage stochastic programming. Operations Research Letters48(4), 505–512 (2020)
work page 2020
-
[16]
In: Proceedings of MME06, University of West Bohemia in Pilsen (2006)
Dupacová, J.: Optimization under exogenous and endogenous uncertainty. In: Proceedings of MME06, University of West Bohemia in Pilsen (2006)
work page 2006
-
[17]
Elliott, R.J., Aggoun, L., Moore, J.B.: Hidden Markov models: estimation and control, vol. 29. Springer Science & Business Media, New York, NY (2008)
work page 2008
-
[18]
Füllner, C., Rebennack, S.: Stochastic dual dynamic programming and its variants. SIAM Review67, 415–539 (2025)
work page 2025
-
[19]
IISE Transactions55(6), 588–601 (2023)
Ghatrani, Z., Ghate, A.: Inverse Markov decision processes with unknown transition probabilities. IISE Transactions55(6), 588–601 (2023)
work page 2023
-
[20]
Mathematics of Operations Research40(1), 130–145 (2015)
Girardeau, P., Leclère, V., Philpott, A.B.: On the convergence of decomposition methods for multistage stochastic convex programs. Mathematics of Operations Research40(1), 130–145 (2015)
work page 2015
-
[21]
Mathe- matical programming108(2), 355–394 (2006)
Goel, V., Grossmann, I.E.: A class of stochastic programs with decision dependent uncertainty. Mathe- matical programming108(2), 355–394 (2006)
work page 2006
-
[22]
In: International Conference on Algorithmic Learning Theory, pp
Grünwald, P.: The safe Bayesian: learning the learning rate via the mixability gap. In: International Conference on Algorithmic Learning Theory, pp. 169–183. Springer (2012)
work page 2012
-
[23]
SIAM Journal on Optimization26(4), 2468–2494 (2016)
Guigues, V.: Convergence analysis of sampling-based decomposition methods for risk-averse multistage stochastic convex programs. SIAM Journal on Optimization26(4), 2468–2494 (2016)
work page 2016
-
[24]
Contextual Markov Decision Processes
Hallak, A., Di Castro, D., Mannor, S.: Contextual Markov decision processes. arXiv preprint arXiv:1502.02259 (2015) 25
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Computational Management Science15, 369–395 (2018)
Hellemo, L., Barton, P.I., Tomasgard, A.: Decision-dependent probabilities in stochastic programs with recourse. Computational Management Science15, 369–395 (2018)
work page 2018
-
[26]
MIT Press, Cambridge, MA (1960)
Howard, R.: Dynamic programming and Markov processes. MIT Press, Cambridge, MA (1960)
work page 1960
-
[27]
Ibrahim, J.G., Chen, M.H.: Power prior distributions for regression models. Statistical Science pp. 46–60 (2000)
work page 2000
-
[28]
Artificial Intelligence101, 99–134 (1998)
Kaelbling, L.P., Littman, M.L., Cassandra, A.R.: Planning and acting in partially observable stochastic domains. Artificial Intelligence101, 99–134 (1998)
work page 1998
-
[29]
King, A.J., Wallace, S.W.: Modeling with stochastic programming. Springer (2012)
work page 2012
-
[30]
European Journal of Operational Research314(2), 792–806 (2024)
Lamas, P., Goycoolea, M., Pagnoncelli, B., Newman, A.: A target-time-windows technique for project scheduling under uncertainty. European Journal of Operational Research314(2), 792–806 (2024)
work page 2024
-
[31]
Mathematical Programming198(1), 1059–1106 (2023)
Lan, G.: Policy mirror descent for reinforcement learning: Linear convergence, new sampling complexity, and generalized problem classes. Mathematical Programming198(1), 1059–1106 (2023)
work page 2023
-
[32]
European Journal of Operational Research271(3), 1037–1054 (2018)
Lara, C.L., Mallapragada, D.S., Papageorgiou, D.J., Venkatesh, A., Grossmann, I.E.: Deterministic electric power infrastructure planning: Mixed-integer programming model and nested decomposition algorithm. European Journal of Operational Research271(3), 1037–1054 (2018)
work page 2018
-
[33]
Optimization and Engineering21, 1243–1281 (2020)
Lara, C.L., Siirola, J.D., Grossmann, I.E.: Electric power infrastructure planning under uncertainty: stochastic dual dynamic integer programming (SDDiP) and parallelization scheme. Optimization and Engineering21, 1243–1281 (2020)
work page 2020
-
[34]
IEEE Access6, 49089–49102 (2018)
Le, T.P., Vien, N.A., Chung, T.: A deep hierarchical reinforcement learning algorithm in partially observable Markov decision processes. IEEE Access6, 49089–49102 (2018)
work page 2018
- [35]
-
[36]
arXiv preprint arXiv:1908.06973 (2019)
Li, Y.: Reinforcement learning applications. arXiv preprint arXiv:1908.06973 (2019)
-
[37]
Mathematical Programming Computation (2023)
Lubin, M., Dowson, O., Dias Garcia, J., Huchette, J., Legat, B., Vielma, J.P.: JuMP 1.0: Recent improvements to a modeling language for mathematical optimization. Mathematical Programming Computation (2023). DOI 10.1007/s12532-023-00239-3
-
[38]
Mamon, R.S., Elliott, R.J.: Hidden Markov models in finance, vol. 4. Springer, New York, NY (2007)
work page 2007
-
[39]
INFORMS Journal on Computing22(2), 266–281 (2010)
Maxwell, M.S., Restrepo, M., Henderson, S.G., Topaloglu, H.: Approximate dynamic programming for ambulance redeployment. INFORMS Journal on Computing22(2), 266–281 (2010)
work page 2010
-
[40]
Journal of the Royal Statistical Society: Series B (Methodological)57(1), 99–118 (1995)
O’Hagan, A.: Fractional Bayes factors for model comparison. Journal of the Royal Statistical Society: Series B (Methodological)57(1), 99–118 (1995)
work page 1995
-
[41]
Mathematical Programming52, 359–375 (1991)
Pereira, M.V.F., Pinto, L.M.V.G.: Multi-stage stochastic optimization applied to energy planning. Mathematical Programming52, 359–375 (1991)
work page 1991
-
[42]
Operations Research Letters36, 450–455 (2008)
Philpott, A.B., Guan, Z.: On the convergence of sampling-based methods for multi-stage stochastic linear programs. Operations Research Letters36, 450–455 (2008)
work page 2008
-
[43]
Wiley Series in Probability and Statistics
Powell, W.B.: Approximate dynamic programming: Solving the curses of dimensionality, 2nd ed edn. Wiley Series in Probability and Statistics. Wiley, Hoboken, N.J (2011)
work page 2011
-
[44]
In: Bridging data and decisions, pp
Powell, W.B.: Clearing the jungle of stochastic optimization. In: Bridging data and decisions, pp. 109–137. INFORMS (2014)
work page 2014
-
[45]
John Wiley & Sons, Hoboken, NJ (2014) 26
Puterman, M.L.: Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, Hoboken, NJ (2014) 26
work page 2014
-
[46]
IEEE Transactions on Sustainable Energy13(1), 196–206 (2022)
Rosemberg, A., Street, A., Garcia, J.D., Silva, T., Valladão, D., Dowson, O.: Assessing the cost of network simplifications in hydrothermal power systems. IEEE Transactions on Sustainable Energy13(1), 196–206 (2022)
work page 2022
-
[47]
Seranilla, B.K.: On the applications of stochastic dual dynamic programming. Ph.D. thesis, Université du Luxembourg, Luxembourg City, Luxembourg (2023)
work page 2023
-
[48]
Shapiro, A., Dentcheva, D., Ruszczynski, A.: Lectures on stochastic programming: Modeling and theory. SIAM, Philadelphia, PA (2021)
work page 2021
-
[49]
In: Proceedings of the 2021 IISE Annual Conference (2021)
Siddig, M., Song, Y., Khademi, A.: Maximum-posterior evaluation for partially observable multistage stochastic programming. In: Proceedings of the 2021 IISE Annual Conference (2021)
work page 2021
-
[50]
IISE Transactions 53(10), 1124–1139 (2021)
Steimle, L.N., Kaufman, D.L., Denton, B.T.: Multi-model Markov decision processes. IISE Transactions 53(10), 1124–1139 (2021)
work page 2021
-
[51]
INFORMS Journal on Computing18(1), 31–42 (2006)
Topaloglu, H., Powell, W.B.: Dynamic-programming approximations for stochastic time-staged integer multicommodity-flow problems. INFORMS Journal on Computing18(1), 31–42 (2006)
work page 2006
-
[52]
Advances in Neural Information Processing Systems34, 8795–8806 (2021)
Wang, K., Shah, S., Chen, H., Perrault, A., Doshi-Velez, F., Tambe, M.: Learning MDPs from features: Predict-then-optimize for sequential decision making by reinforcement learning. Advances in Neural Information Processing Systems34, 8795–8806 (2021)
work page 2021
-
[53]
Mathematics of Operations Research38(1), 153–183 (2013)
Wiesemann, W., Kuhn, D., Rustem, B.: Robust Markov decision processes. Mathematics of Operations Research38(1), 153–183 (2013)
work page 2013
-
[54]
IEEE Systems Journal17(2), 2247–2258 (2022)
Yin, W., Li, Y., Hou, J., Miao, M., Hou, Y.: Coordinated planning of wind power generation and energy storage with decision-dependent uncertainty induced by spatial correlation. IEEE Systems Journal17(2), 2247–2258 (2022)
work page 2022
-
[55]
Mathematical Program- ming175(1-2), 461–502 (2019) 27
Zou, J., Ahmed, S., Sun, X.A.: Stochastic dual dynamic integer programming. Mathematical Program- ming175(1-2), 461–502 (2019) 27
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.