Structured In-context Environment Scaling for Large Language Model Reasoning
Pith reviewed 2026-05-18 12:18 UTC · model grok-4.3
The pith
Large language models learn generalizable reasoning skills from environments built automatically from structured data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
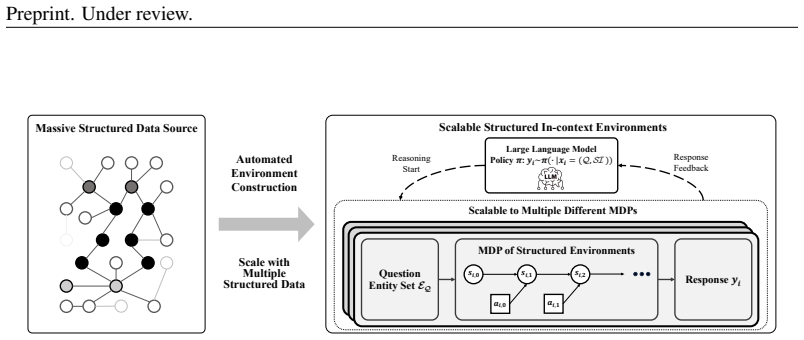
SIE achieves scalability by automatically constructing reasoning environments from large-scale structured data. The rich compositional patterns in such data naturally support generalizable reasoning. The explicit schemas and reasoning chains provide a foundation for rule-based verifiability. This leads to substantial improvements in in-domain structured reasoning and effective generalization to out-of-domain mathematical and logical reasoning tasks. In partial SIEs, LLMs infer missing information through environmental exploration to achieve robust reasoning improvements.
What carries the argument
The Structured In-context Environment (SIE) framework, which automatically builds reasoning environments from structured data for scalable and verifiable LLM training.
If this is right
- Improvements in performance on in-domain structured reasoning tasks.
- Generalization of learned skills to out-of-domain mathematical and logical reasoning.
- Ability to achieve robust improvements by inferring missing information in partial environments.
- Scalable environment construction without reliance on heavy expert annotation.
- Rule-based verification enabled by explicit schemas and reasoning chains in the data.
Where Pith is reading between the lines
- This framework could allow training on much larger volumes of data by repurposing existing structured sources.
- The exploration-based inference in partial settings may help models deal with noisy or incomplete real-world information.
- Future work could test whether SIE-style environments improve performance in domains beyond math and logic.
- Integration with other RL methods might further enhance the generalization effects observed.
Load-bearing premise
Rich compositional patterns in structured data naturally support the development of generalizable reasoning in LLMs through exploration.
What would settle it
A controlled experiment where models trained via SIE show no gains over standard methods on out-of-domain reasoning benchmarks, or fail to infer missing information in partial SIE setups.
Figures

read the original abstract
Large language models (LLMs) have achieved significant advancements in reasoning capabilities through reinforcement learning (RL) via environmental exploration. As the intrinsic properties of the environment determine the abilities that LLMs can learn, the environment plays a important role in the RL finetuning process. An ideal LLM reasoning environment should possess three core characteristics: scalability, generalizable reasoning, and verifiability. However, existing mathematical and coding environments are difficult to scale due to heavy reliance on expert annotation, while the skills learned in game-based environments are too specialized to generalize. To bridge this gap, we introduce the \textbf{S}tructured \textbf{I}n-context \textbf{E}nvironment (SIE) framework. SIE achieves scalability by automatically constructing reasoning environments from large-scale structured data, where the rich compositional patterns naturally support generalizable reasoning. Moreover, the explicit schemas and reasoning chains in structured data provide a foundation for rule-based verifiability. Experimental results show that SIE framework not only achieves substantial improvements in in-domain structured reasoning, but also enables the learned compositional reasoning skills to generalize effectively to out-of-domain mathematical and logical reasoning tasks. We further explored learning in information-limited partial SIEs and found that LLMs can infer the missing information through exploring the environment, leading to robust reasoning improvements and generalization performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Structured In-context Environment (SIE) framework, which automatically constructs reasoning environments for LLMs from large-scale structured data. It claims that the rich compositional patterns in such data enable scalable RL finetuning, support generalizable reasoning skills that transfer to out-of-domain mathematical and logical tasks, and provide explicit schemas for rule-based verifiability. The authors further report that LLMs can infer missing information through exploration in partial (information-limited) SIEs, yielding robust improvements.
Significance. If the empirical results hold under rigorous controls, SIE would offer a scalable, annotation-light alternative to existing mathematical, coding, and game-based environments, potentially advancing generalizable reasoning in LLMs by leveraging compositional structure in real-world data. The combination of automatic construction, verifiability, and reported cross-domain transfer is a substantive contribution to environment design for LLM training.
major comments (2)
- [Abstract] Abstract: The central generalization claim—that compositional patterns in structured data enable transferable reasoning skills and that LLMs reliably infer missing schema elements via environmental exploration in partial SIEs—is load-bearing but rests on an untested assumption. No ablations are described that preserve data scale while removing compositional structure, nor are there reported measurements of inference accuracy on deliberately incomplete schemas; without these, surface-level pattern matching or training-data overlap remain viable alternative explanations for the out-of-domain gains.
- [Experimental results] Experimental results (as summarized in the abstract): The reported substantial improvements and generalization lack accompanying details on baselines, exact metrics, statistical tests, model sizes, or controls for confounds such as data contamination. This omission prevents assessment of whether the observed gains are attributable to the SIE mechanism rather than other factors.
minor comments (2)
- [Abstract] Abstract: Quantitative effect sizes, specific out-of-domain tasks, and the structured data sources used are not stated, reducing the reader's ability to gauge the practical significance of the results.
- [Introduction] Introduction/Methods: Ensure the three core characteristics (scalability, generalizable reasoning, verifiability) are explicitly mapped to concrete design choices in SIE construction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important areas for strengthening the generalization claims and experimental reporting. We address each point below and will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central generalization claim—that compositional patterns in structured data enable transferable reasoning skills and that LLMs reliably infer missing schema elements via environmental exploration in partial SIEs—is load-bearing but rests on an untested assumption. No ablations are described that preserve data scale while removing compositional structure, nor are there reported measurements of inference accuracy on deliberately incomplete schemas; without these, surface-level pattern matching or training-data overlap remain viable alternative explanations for the out-of-domain gains.
Authors: We agree that targeted ablations isolating compositional structure (while holding data scale fixed) and direct measurements of inference accuracy on incomplete schemas would more convincingly rule out alternatives such as pattern matching. In the revised manuscript we will add (1) an ablation that disrupts compositional relations in the structured data while preserving scale, statistics, and domain coverage, and (2) quantitative results on inference accuracy for missing schema elements during partial-SIE exploration. These additions will be placed in the experimental analysis section and will directly address the concern about alternative explanations. revision: yes
-
Referee: [Experimental results] Experimental results (as summarized in the abstract): The reported substantial improvements and generalization lack accompanying details on baselines, exact metrics, statistical tests, model sizes, or controls for confounds such as data contamination. This omission prevents assessment of whether the observed gains are attributable to the SIE mechanism rather than other factors.
Authors: We acknowledge the need for fuller experimental transparency. The revision will expand the experimental section to report: complete baseline descriptions and implementation details, precise metric definitions and formulas, statistical significance tests (including p-values and run counts), exact model sizes and training configurations, and explicit contamination controls (e.g., n-gram overlap analysis between SIE data and downstream evaluation sets). These details will allow readers to evaluate whether gains are attributable to the SIE framework. revision: yes
Circularity Check
No circularity: SIE claims rest on external data construction and empirical results
full rationale
The paper's central claims derive from automatically building environments from independent large-scale structured data sources and then reporting experimental outcomes on in-domain and out-of-domain tasks. No equations, parameter fits, or definitions reduce the reported generalization performance to the input data by construction. The framework description in the abstract and methods relies on the observable properties of the chosen data rather than self-referential renaming or self-citation chains that would force the conclusions. This is the most common honest finding for a methodological paper whose validity is intended to be checked against external benchmarks and ablations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Structured data possesses rich compositional patterns that naturally support generalizable reasoning.
- domain assumption LLMs can infer missing information through environmental exploration in partial SIEs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SIE achieves scalability by automatically constructing reasoning environments from large-scale structured data, where the rich compositional patterns naturally support generalizable reasoning... We further explored learning in information-limited partial SIEs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Freebase: a collab- oratively created graph database for structuring human knowledge
Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. Freebase: a collab- oratively created graph database for structuring human knowledge. InProceedings of the 2008 ACM SIGMOD international conference on Management of data, pp. 1247–1250,
work page 2008
-
[2]
Yongchao Chen, Yueying Liu, Junwei Zhou, Yilun Hao, Jingquan Wang, Yang Zhang, and Chuchu Fan. R1-code-interpreter: Training llms to reason with code via supervised and reinforcement learning.arXiv preprint arXiv:2505.21668,
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Bhishma Dedhia, Yuval Kansal, and Niraj K Jha. Bottom-up domain-specific superintelligence: A reliable knowledge graph is what we need.arXiv preprint arXiv:2507.13966,
-
[6]
Towards general agentic intelligence via environ- ment scaling.arXiv preprint arXiv:2509.13311,
Runnan Fang, Shihao Cai, Baixuan Li, Jialong Wu, Guangyu Li, Wenbiao Yin, Xinyu Wang, Xi- aobin Wang, Liangcai Su, Zhen Zhang, et al. Towards general agentic intelligence via environ- ment scaling.arXiv preprint arXiv:2509.13311,
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Beyond iid: three levels of generalization for question answering on knowledge bases
Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su. Beyond iid: three levels of generalization for question answering on knowledge bases. InProceedings of the web conference 2021, pp. 3477–3488,
work page 2021
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
10 Preprint. Under review. Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. Reinforce++: An efficient rlhf algorithm with robustness to both prompt and reward models.arXiv preprint arXiv:2501.03262, 2025a. Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up rein...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Valentin Lacombe, Valentin Quesnel, and Damien Sileo. Reasoning core: A scalable rl environment for llm symbolic reasoning.arXiv preprint arXiv:2509.18083,
-
[13]
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji-Rong Wen, and Zhicheng Dou. Webthinker: Empowering large reasoning models with deep research capability. arXiv preprint arXiv:2504.21776,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Reasoning on graphs: Faithful and interpretable large language model reasoning
Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. Reasoning on graphs: Faithful and interpretable large language model reasoning.arXiv preprint arXiv:2310.01061,
-
[15]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel M Ni, Heung-Yeung Shum, and Jian Guo. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph.arXiv preprint arXiv:2307.07697,
-
[18]
The web as a knowledge-base for answering complex questions
Alon Talmor and Jonathan Berant. The web as a knowledge-base for answering complex questions. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long Papers), pp. 641– 651,
work page 2018
-
[19]
Weihao Tan, Wentao Zhang, Shanqi Liu, Longtao Zheng, Xinrun Wang, and Bo An. True knowledge comes from practice: Aligning llms with embodied environments via reinforcement learning. arXiv preprint arXiv:2401.14151,
-
[20]
Paths-over-graph: Knowledge graph empowered large language model reasoning
Xingyu Tan, Xiaoyang Wang, Qing Liu, Xiwei Xu, Xin Yuan, and Wenjie Zhang. Paths-over-graph: Knowledge graph empowered large language model reasoning. InProceedings of the ACM on Web Conference 2025, pp. 3505–3522,
work page 2025
-
[21]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
11 Preprint. Under review. Yuyao Wang, Bowen Liu, Jianheng Tang, Nuo Chen, Yuhan Li, Qifan Zhang, and Jia Li. Graph-r1: Unleashing llm reasoning with np-hard graph problems.arXiv preprint arXiv:2508.20373,
-
[23]
Juncheng Wu, Wenlong Deng, Xingxuan Li, Sheng Liu, Taomian Mi, Yifan Peng, Ziyang Xu, Yi Liu, Hyunjin Cho, Chang-In Choi, et al. Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs.arXiv preprint arXiv:2504.00993,
-
[24]
Y.; Li, B.; Ghazi, B.; and Kumar, R
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. On memorization of large language models in logical reasoning.arXiv preprint arXiv:2410.23123,
-
[25]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2502.14768,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models.arXiv preprint arXiv:2308.01825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Shao Zhang, Xihuai Wang, Wenhao Zhang, Chaoran Li, Junru Song, Tingyu Li, Lin Qiu, Xuezhi Cao, Xunliang Cai, Wen Yao, et al. Leveraging dual process theory in language agent framework for real-time simultaneous human-ai collaboration.arXiv preprint arXiv:2502.11882,
-
[31]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025a. Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. Deepresearcher: Scaling deep research via reinforcement learnin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.