AudioMoG: Guiding Audio Generation with Mixture-of-Guidance
Pith reviewed 2026-05-18 13:05 UTC · model grok-4.3
The pith
A mixture-of-guidance sampling method outperforms single-guidance techniques in diffusion-based audio generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
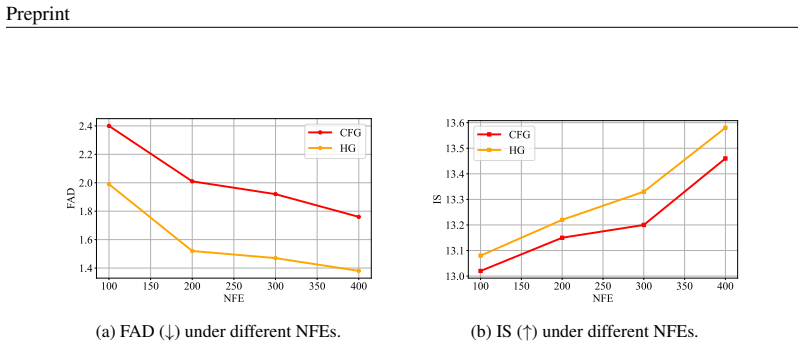
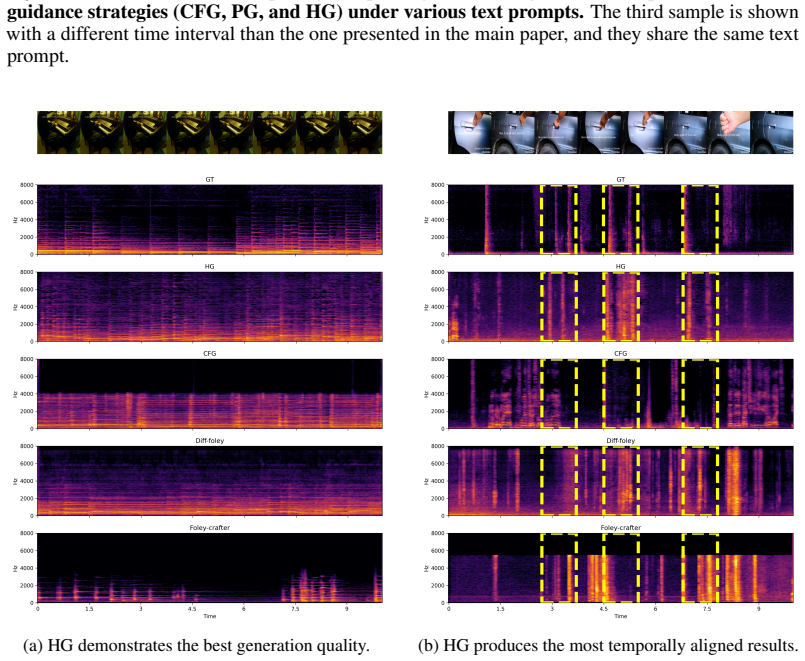
By integrating diverse guidance signals with their interaction terms in a mixture-of-guidance framework, the method delivers better generation quality than single-guidance baselines in text-to-audio tasks across sampling steps while also showing gains in video-to-audio, text-to-music, and image generation at identical inference speeds.
What carries the argument
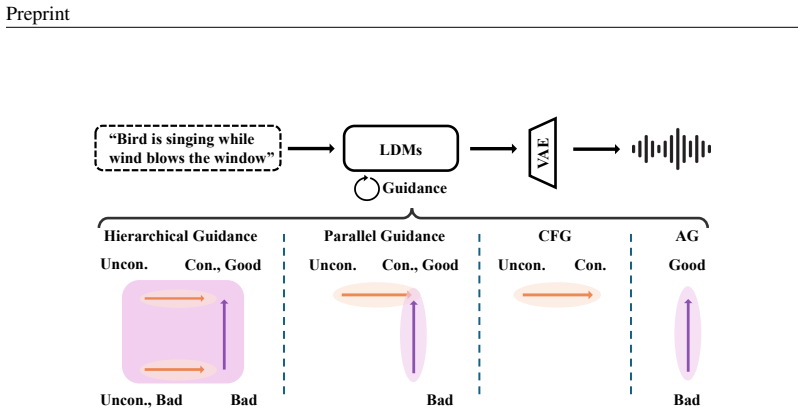
Mixture-of-guidance framework that combines classifier-free guidance, autoguidance, and interaction terms such as unconditional model outputs to accumulate their respective advantages during the sampling process.
If this is right
- The method produces higher quality text-to-audio results than single-guidance approaches at the same inference speed across different sampling steps.
- Performance advantages appear in video-to-audio generation as well.
- The benefits carry over to text-to-music and image generation tasks.
- No model retraining is required to obtain the improvements.
Where Pith is reading between the lines
- The same mixing strategy could be tested on video or 3D generation models to check whether the quality-diversity balance improves in those domains too.
- One could measure whether the optimal mix of guidance weights stays stable when the underlying diffusion model changes size or training data.
- Future work might examine if the interaction terms reduce the amount of manual tuning needed when moving the method to new conditioning types such as audio captions.
- This framework suggests a path toward adaptive sampling that selects or weights guidance signals on the fly based on intermediate generation quality.
Load-bearing premise
Combining the different guidance signals and their interaction terms will add up their benefits without creating inconsistencies that demand heavy per-model adjustments.
What would settle it
Running the mixture-of-guidance sampler on a standard text-to-audio diffusion model and measuring no improvement in objective quality metrics over the strongest single-guidance baseline when both use the same number of sampling steps.
Figures






read the original abstract
The design of diffusion-based audio generation systems has been investigated from diverse perspectives, such as data space, network architecture, and conditioning techniques, while most of these innovations require model re-training. In sampling, classifier-free guidance (CFG) has been uniformly adopted to enhance generation quality by strengthening condition alignment. However, CFG often compromises diversity, resulting in suboptimal performance. Although the recent autoguidance (AG) method proposes another direction of guidance that maintains diversity, its direct application in audio generation has so far underperformed CFG. In this work, we introduce AudioMoG, an improved sampling method that enhances text-to-audio (T2A) and video-to-audio (V2A) generation quality without requiring extensive training resources. We start with an analysis of both CFG and AG, examining their respective advantages and limitations for guiding diffusion models. Building upon our insights, we introduce a mixture-of-guidance framework that integrates diverse guidance signals with their interaction terms (e.g., the unconditional bad version of the model) to maximize cumulative advantages. Experiments show that, given the same inference speed, our approach consistently outperforms single guidance in T2A generation across sampling steps, concurrently showing advantages in V2A, text-to-music, and image generation. Demo samples are available at: https://audiomog.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AudioMoG, a mixture-of-guidance sampling method for diffusion-based audio generation. It analyzes classifier-free guidance (CFG) and autoguidance (AG), identifies their respective advantages and limitations, and introduces a framework that combines multiple guidance signals along with interaction terms (explicitly including the unconditional bad model) to improve condition alignment while preserving diversity. The central empirical claim is that, at fixed inference speed, AudioMoG consistently outperforms single-guidance baselines in text-to-audio (T2A) across sampling steps and shows advantages in video-to-audio (V2A), text-to-music, and image generation tasks, all without requiring model retraining.
Significance. If the reported gains are reproducible and general, the work would supply a practical, training-free enhancement to the sampling stage of audio diffusion models. By explicitly incorporating interaction terms rather than treating CFG and AG as mutually exclusive, the approach could help resolve the quality-diversity trade-off that currently limits CFG and the underperformance of direct AG in audio domains. The extension to V2A and cross-modal tasks further suggests broader applicability.
major comments (2)
- [Section 4] Section 4 (Experiments): the abstract and results claim consistent outperformance in T2A across sampling steps, yet no information is provided on the datasets employed, the precise evaluation metrics (e.g., CLAP, FAD, or subjective scores), the number of evaluation samples, or error bars from multiple random seeds. Without these details the statistical reliability of the cross-method comparison cannot be assessed and the central claim remains under-supported.
- [Section 3.2] Section 3.2 (Mixture-of-Guidance formulation): the mixing rule incorporates interaction terms such as the unconditional bad model, but the manuscript does not specify whether the guidance mixing coefficients are held constant across models and datasets or require per-model/per-dataset calibration. This directly affects the claim that the method avoids extensive tuning resources and raises the possibility that reported gains depend on favorable hyper-parameter choices rather than an intrinsic property of the framework.
minor comments (2)
- [Abstract] The term 'unconditional bad version of the model' appears in the abstract and method description without an immediate forward reference to its precise definition or computation; adding a brief parenthetical or citation to the relevant equation would improve readability.
- [Figures] Figure captions and axis labels in the experimental plots should explicitly state the guidance scales and mixing weights used for each curve to allow direct replication of the reported comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps improve the clarity and reproducibility of our work. We provide point-by-point responses to the major comments below and have incorporated revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments): the abstract and results claim consistent outperformance in T2A across sampling steps, yet no information is provided on the datasets employed, the precise evaluation metrics (e.g., CLAP, FAD, or subjective scores), the number of evaluation samples, or error bars from multiple random seeds. Without these details the statistical reliability of the cross-method comparison cannot be assessed and the central claim remains under-supported.
Authors: We agree that the initial manuscript lacked sufficient experimental details to fully substantiate the claims. In the revised version, we will expand Section 4 to explicitly describe the datasets (e.g., AudioCaps for T2A evaluations), the precise metrics including CLAP for semantic alignment, FAD for perceptual quality, and any subjective scores used. We will also report the number of evaluation samples and include error bars derived from multiple random seeds to enable assessment of statistical reliability. These additions directly strengthen support for the consistent outperformance results across sampling steps. revision: yes
-
Referee: [Section 3.2] Section 3.2 (Mixture-of-Guidance formulation): the mixing rule incorporates interaction terms such as the unconditional bad model, but the manuscript does not specify whether the guidance mixing coefficients are held constant across models and datasets or require per-model/per-dataset calibration. This directly affects the claim that the method avoids extensive tuning resources and raises the possibility that reported gains depend on favorable hyper-parameter choices rather than an intrinsic property of the framework.
Authors: The mixing coefficients in AudioMoG are designed to be held constant and were applied uniformly without per-model or per-dataset recalibration in all reported experiments, including T2A, V2A, text-to-music, and image generation tasks. We will revise Section 3.2 to explicitly state this fixed-coefficient approach and note the specific values used, thereby reinforcing that the method requires no extensive tuning resources beyond the standard sampling procedure. This clarification addresses the concern that gains might stem from favorable hyper-parameter choices. revision: yes
Circularity Check
No significant circularity; AudioMoG framework is empirically validated rather than self-referential
full rationale
The paper begins with an analysis of existing CFG and AG techniques, identifies their respective strengths and weaknesses for audio generation, and then proposes a new mixture-of-guidance construction that combines signals and interaction terms. The claimed outperformance is presented as an experimental result at fixed inference speed across sampling steps, not as a mathematical identity or fitted quantity that reduces to the inputs by definition. No equations or steps equate the mixture result to a self-defined quantity, and no load-bearing premise relies on a self-citation chain or imported uniqueness theorem. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- guidance mixing coefficients
axioms (1)
- domain assumption Interaction terms from unconditional model versions provide beneficial guidance signals that can be additively combined.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AudioMoG ... mixture-of-guidance framework that integrates diverse guidance signals with their interaction terms (e.g., the unconditional bad version of the model)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I Denk, Zal \'a n Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. Musiclm: Generating music from text. arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Thierry Bertin-Mahieux, Daniel PW Ellis, Brian Whitman, and Paul Lamere. The million song dataset. In Ismir, volume 2, pp.\ 10, 2011
work page 2011
-
[3]
Classifier-free guidance is a predictor-corrector
Arwen Bradley and Preetum Nakkiran. Classifier-free guidance is a predictor-corrector. arXiv preprint arXiv:2408.09000, 2024
-
[4]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. Vggsound: A large-scale audio-visual dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 721--725. IEEE, 2020
work page 2020
-
[5]
Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji. Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis. In CVPR, pp.\ 28901--28911, 2025
work page 2025
-
[6]
What does guidance do? a fine-grained analysis in a simple setting
Muthu Chidambaram, Khashayar Gatmiry, Sitan Chen, Holden Lee, and Jianfeng Lu. What does guidance do? a fine-grained analysis in a simple setting. arXiv preprint arXiv:2409.13074, 2024
-
[7]
Scaling instruction-finetuned language models
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25 0 (70): 0 1--53, 2024
work page 2024
-
[8]
Syncfusion: Multimodal onset-synchronized video-to-audio foley synthesis
Marco Comunit \`a , Riccardo F Gramaccioni, Emilian Postolache, Emanuele Rodol \`a , Danilo Comminiello, and Joshua D Reiss. Syncfusion: Multimodal onset-synchronized video-to-audio foley synthesis. In ICASSP, pp.\ 936--940. IEEE, 2024
work page 2024
-
[9]
Simple and controllable music generation
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre D \'e fossez. Simple and controllable music generation. Advances in Neural Information Processing Systems, 36: 0 47704--47720, 2023
work page 2023
-
[10]
Text-to-audio generation using instruction tuned LLM and latent diffusion model,
Ghosal Deepanway, Majumder Navonil, Mehrish Ambuj, and Poria Soujanya. Text-to-audio generation using instruction-tuned llm and latent diffusion model. arXiv preprint arXiv:2304.13731, 2023
-
[11]
FMA: A Dataset For Music Analysis
Micha \"e l Defferrard, Kirell Benzi, Pierre Vandergheynst, and Xavier Bresson. Fma: A dataset for music analysis. arXiv preprint arXiv:1612.01840, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Clotho: An audio captioning dataset
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 736--740. IEEE, 2020
work page 2020
-
[13]
Conditional generation of audio from video via foley analogies
Yuexi Du, Ziyang Chen, Justin Salamon, Bryan Russell, and Andrew Owens. Conditional generation of audio from video via foley analogies. In Conference on Computer Vision and Pattern Recognition 2023, 2023
work page 2023
-
[14]
Fast timing-conditioned latent audio diffusion
Zach Evans, CJ Carr, Josiah Taylor, Scott H Hawley, and Jordi Pons. Fast timing-conditioned latent audio diffusion. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[15]
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5. IEEE, 2025
work page 2025
-
[16]
Fsd50k: an open dataset of human-labeled sound events
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra. Fsd50k: an open dataset of human-labeled sound events. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30: 0 829--852, 2021
work page 2021
-
[17]
Riffusion-stable diffusion for real-time music generation
Seth Forsgren and Hayk Martiros. Riffusion-stable diffusion for real-time music generation. URL https://riffusion. com, 2022
work page 2022
-
[18]
Audio set: An ontology and human-labeled dataset for audio events
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp.\ 776--780. IEEE, 2017
work page 2017
-
[19]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 15180--15190, 2023
work page 2023
-
[20]
Shawn Hershey, Sourish Chaudhuri, Daniel PW Ellis, Jort F. Gemmeke, Aren Jansen, R. Channing Moore, Manoj Plakal, Devin Platt, Rif A. Saurous, Bryan Seybold, Malcolm Slaney, Ron J. Weiss, and Kevin Wilson. Cnn architectures for large-scale audio classification. In Proc. ICASSP, pp.\ 131--135, 2017
work page 2017
-
[21]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proc. NeurIPS, pp.\ 6626--6637, 2017
work page 2017
-
[22]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Improving sample quality of diffusion models using self-attention guidance
Susung Hong, Gyuseong Lee, Wooseok Jang, and Seungryong Kim. Improving sample quality of diffusion models using self-attention guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 7462--7471, 2023
work page 2023
-
[24]
Make-An-Audio 2: Temporal-enhanced text-to- audio generation,
Jiawei Huang, Yi Ren, Rongjie Huang, Dongchao Yang, Zhenhui Ye, Chen Zhang, Jinglin Liu, Xiang Yin, Zejun Ma, and Zhou Zhao. Make-an-audio 2: Temporal-enhanced text-to-audio generation. arXiv preprint arXiv:2305.18474, 2023 a
-
[25]
Masked autoencoders that listen
Po-Yao Huang, Hu Xu, Juncheng Li, Alexei Baevski, Michael Auli, Wojciech Galuba, Florian Metze, and Christoph Feichtenhofer. Masked autoencoders that listen. Advances in Neural Information Processing Systems, 35: 0 28708--28720, 2022
work page 2022
-
[26]
Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models
Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models. In International Conference on Machine Learning, pp.\ 13916--13932. PMLR, 2023 b
work page 2023
-
[27]
Chia-Yu Hung, Navonil Majumder, Zhifeng Kong, Ambuj Mehrish, Rafael Valle, Bryan Catanzaro, and Soujanya Poria. Tangoflux: Super fast and faithful text to audio generation with flow matching and clap-ranked preference optimization. arXiv preprint arXiv:2412.21037, 2024
-
[28]
Spatiotemporal skip guidance for enhanced video diffusion sampling
Junha Hyung, Kinam Kim, Susung Hong, Min - Jung Kim, and Jaegul Choo. Spatiotemporal skip guidance for enhanced video diffusion sampling. In CVPR, 2025
work page 2025
-
[29]
Spg: Improving motion diffusion by smooth perturbation guidance
Boseong Jeon. Spg: Improving motion diffusion by smooth perturbation guidance. arXiv preprint arXiv:2503.02577, 2025
-
[30]
Read, watch and scream! sound generation from text and video
Yujin Jeong, Yunji Kim, Sanghyuk Chun, and Jiyoung Lee. Read, watch and scream! sound generation from text and video. arXiv preprint arXiv:2407.05551, 2024
-
[31]
Freeaudio: Training-free timing planning for controllable long-form text-to-audio generation
Yuxuan Jiang, Zehua Chen, Zeqian Ju, Chang Li, Weibei Dou, and Jun Zhu. Freeaudio: Training-free timing planning for controllable long-form text-to-audio generation. arXiv preprint arXiv:2507.08557, 2025
-
[32]
Guiding a diffusion model with a bad version of itself
Tero Karras, Miika Aittala, Tuomas Kynk \"a \"a nniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. Advances in Neural Information Processing Systems, 37: 0 52996--53021, 2024 a
work page 2024
-
[33]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 24174--24184, 2024 b
work page 2024
-
[34]
Autolora: Autoguidance meets low-rank adaptation for diffusion models
Artur Kasymov, Marcin Sendera, Michal Stypulkowski, Maciej Zieba, and Przemysław Spurek. Autolora: Autoguidance meets low-rank adaptation for diffusion models. ArXiv, abs/2410.03941, 2024. URL https://api.semanticscholar.org/CorpusID:273186941
-
[35]
Kevin Kilgour, Robin Clark, Kyu J. Sim, and Paris Smaragdis. Fréchet audio distance: A metric for evaluating music enhancement algorithms. In Proc. Interspeech, pp.\ 2350--2354, 2019
work page 2019
-
[36]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp.\ 119--132, 2019
work page 2019
-
[37]
Auto-encoding variational bayes, 2013
Diederik P Kingma, Max Welling, et al. Auto-encoding variational bayes, 2013
work page 2013
- [38]
-
[39]
Improving text-to-audio models with synthetic captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, and Bryan Catanzaro. Improving text-to-audio models with synthetic captions. arXiv preprint arXiv:2406.15487, 2024
-
[40]
Audiogen: Textually guided audio generation.arXiv preprint arXiv:2209.15352,
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre D \'e fossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. Audiogen: Textually guided audio generation. arXiv preprint arXiv:2209.15352, 2022
-
[41]
Solomon Kullback and Richard A. Leibler. On information and sufficiency. The Annals of Mathematical Statistics, 22 0 (1): 0 79--86, 1951
work page 1951
-
[42]
Efficient neural music generation
Max WY Lam, Qiao Tian, Tang Li, Zongyu Yin, Siyuan Feng, Ming Tu, Yuliang Ji, Rui Xia, Mingbo Ma, Xuchen Song, et al. Efficient neural music generation. Advances in Neural Information Processing Systems, 36: 0 17450--17463, 2023
work page 2023
-
[43]
Evaluation of algorithms using games: The case of music tagging
Edith Law, Kris West, Michael I Mandel, Mert Bay, and J Stephen Downie. Evaluation of algorithms using games: The case of music tagging. In ISMIR, pp.\ 387--392. Citeseer, 2009
work page 2009
-
[44]
Etta: Elucidating the design space of text-to-audio models
Sang-gil Lee, Zhifeng Kong, Arushi Goel, Sungwon Kim, Rafael Valle, and Bryan Catanzaro. Etta: Elucidating the design space of text-to-audio models. In ICML, 2025
work page 2025
-
[45]
Quality-aware masked diffusion transformer for enhanced music generation
Chang Li, Ruoyu Wang, Lijuan Liu, Jun Du, Yixuan Sun, Zilu Guo, Zhenrong Zhang, and Yuan Jiang. Quality-aware masked diffusion transformer for enhanced music generation. arXiv e-prints, pp.\ arXiv--2405, 2024 a
work page 2024
-
[46]
Jen-1: Text-guided universal music generation with omnidirectional diffusion models
Peike Patrick Li, Boyu Chen, Yao Yao, Yikai Wang, Allen Wang, and Alex Wang. Jen-1: Text-guided universal music generation with omnidirectional diffusion models. In 2024 IEEE Conference on Artificial Intelligence (CAI), pp.\ 762--769. IEEE, 2024 b
work page 2024
-
[47]
Self-guidance: Boosting flow and diffusion generation on their own
Tiancheng Li, Weijian Luo, Zhiyang Chen, Liyuan Ma, and Guo-Jun Qi. Self-guidance: Boosting flow and diffusion generation on their own. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[48]
Audioldm: Text-to-audio generation with latent diffusion models.arXiv preprint arXiv:2301.12503,
Haohe Liu, Zehua Chen, Zejia Yuan, et al. Audioldm: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503, 2023
-
[49]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D Plumbley. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024 a
work page 2024
-
[50]
Tell what you hear from what you see - video to audio generation through text
Xiulong Liu, Kun Su, and Eli Shlizerman. Tell what you hear from what you see - video to audio generation through text. In NeurIPS, 2024 b . URL https://openreview.net/forum?id=kr7eN85mIT
work page 2024
-
[51]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv preprint arXiv:2211.01095, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models. Advances in Neural Information Processing Systems, 36: 0 48855--48876, 2023
work page 2023
-
[54]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, and Soujanya Poria. Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization. In Proceedings of the 32nd ACM International Conference on Multimedia, pp.\ 564--572, 2024
work page 2024
-
[55]
Foleygen: Visually-guided audio generation
Xinhao Mei, Varun Nagaraja, Gael Le Lan, Zhaoheng Ni, Ernie Chang, Yangyang Shi, and Vikas Chandra. Foleygen: Visually-guided audio generation. In 2024 IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP), pp.\ 1--6. IEEE, 2024
work page 2024
-
[56]
Mubert-Inc. Mubert. URL https://mubert.com/, https://github.com/MubertAI/ Mubert-Text-to-Music, 2022
work page 2022
-
[57]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 4195--4205, 2023
work page 2023
-
[58]
Unconditional priors matter! improving conditional generation of fine-tuned diffusion models
Prin Phunyaphibarn, Phillip Y Lee, Jaihoon Kim, and Minhyuk Sung. Unconditional priors matter! improving conditional generation of fine-tuned diffusion models. arXiv preprint arXiv:2503.20240, 2025
-
[59]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[60]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36: 0 53728--53741, 2023
work page 2023
-
[61]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
work page 2022
-
[62]
arXiv preprint arXiv:2407.02687 , year =
Seyedmorteza Sadat, Manuel Kansy, Otmar Hilliges, and Romann M Weber. No training, no problem: Rethinking classifier-free guidance for diffusion models. arXiv preprint arXiv:2407.02687, 2024
-
[63]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Proc. NeurIPS, pp.\ 2234--2242, 2016
work page 2016
-
[64]
Mo \^ usai: Text-to-music generation with long-context latent diffusion
Flavio Schneider, Ojasv Kamal, Zhijing Jin, and Bernhard Sch \"o lkopf. Mo \^ usai: Text-to-music generation with long-context latent diffusion. arXiv preprint arXiv:2301.11757, 2023
-
[65]
I hear your true colors: Image guided audio generation
Roy Sheffer and Yossi Adi. I hear your true colors: Image guided audio generation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5. IEEE, 2023
work page 2023
-
[66]
From vision to audio and beyond: A unified model for audio-visual representation and generation
Kun Su, Xiulong Liu, and Eli Shlizerman. From vision to audio and beyond: A unified model for audio-visual representation and generation. arXiv preprint arXiv:2409.19132, 2024
-
[67]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017
work page 2017
-
[68]
V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foundation models
Heng Wang, Jianbo Ma, Santiago Pascual, Richard Cartwright, and Weidong Cai. V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foundation models. In AAAI, volume 38, pp.\ 15492--15501, 2024 a
work page 2024
-
[69]
Tiva: Time-aligned video-to-audio generation
Xihua Wang, Yuyue Wang, Yihan Wu, Ruihua Song, Xu Tan, Zehua Chen, Hongteng Xu, and Guodong Sui. Tiva: Time-aligned video-to-audio generation. In ACM Multimedia, 2024 b
work page 2024
-
[70]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In ICASSP, pp.\ 1--5. IEEE, 2023
work page 2023
-
[71]
Sonicvisionlm: Playing sound with vision language models
Zhifeng Xie, Shengye Yu, Qile He, and Mengtian Li. Sonicvisionlm: Playing sound with vision language models. In CVPR, pp.\ 26866--26875, 2024
work page 2024
-
[72]
Video-to-audio generation with hidden alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, and Dong Yu. Video-to-audio generation with hidden alignment. arXiv preprint arXiv:2407.07464, 2024
-
[73]
Diffsound: Discrete diffusion model for text-to-sound generation
Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. Diffsound: Discrete diffusion model for text-to-sound generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31: 0 1720--1733, 2023
work page 2023
-
[74]
Foley- crafter: Bring silent videos to life with lifelike and synchro- nized sounds,
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, and Kai Chen. Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds. arXiv preprint arXiv:2407.01494, 2024
-
[75]
Domain guidance: A simple transfer approach for a pre-trained diffusion model
Jincheng Zhong, Xiangcheng Zhang, Jianmin Wang, and Mingsheng Long. Domain guidance: A simple transfer approach for a pre-trained diffusion model. arXiv preprint arXiv:2504.01521, 2025
-
[76]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[77]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[78]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[79]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.