Localizing Task Recognition and Task Learning in In-Context Learning via Attention Head Analysis
Pith reviewed 2026-05-18 13:23 UTC · model grok-4.3
The pith
Attention heads in large language models localize into separate groups for recognizing tasks from examples and for learning to apply them during in-context learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that attention heads can be partitioned into TR heads, which align hidden states with a task subspace, and TL heads, which rotate states inside that subspace toward the correct label; these roles are isolated by Task Subspace Logit Attribution and verified through ablation and geometric steering experiments that also reconcile induction-head and task-vector findings.
What carries the argument
Task Subspace Logit Attribution (TSLA), which scores attention heads by their contribution to logits projected onto the task subspace and thereby isolates heads responsible for task recognition versus task learning.
If this is right
- TR heads align hidden states with the task subspace while TL heads rotate states inside the subspace toward the correct label.
- Ablating the localized TR or TL heads impairs the corresponding component of in-context learning.
- Earlier observations on induction heads and task vectors fit inside the TR-TL decomposition at the level of individual attention heads.
- The same framework accounts for in-context learning across varied tasks and model settings.
Where Pith is reading between the lines
- Targeted editing of TR or TL heads during inference could selectively enhance or suppress task recognition or label selection.
- The same localization technique might be applied to study other emergent behaviors such as chain-of-thought reasoning.
- Repeating the analysis on models of different sizes or architectures could show whether the same heads or different ones carry the TR and TL roles.
Load-bearing premise
Task Subspace Logit Attribution isolates heads whose contributions causally produce the task-recognition versus task-learning split rather than merely correlating with it.
What would settle it
An ablation experiment in which removing the identified TR heads leaves task-recognition accuracy intact or in which steering the TL heads fails to shift predictions toward the correct label.
Figures















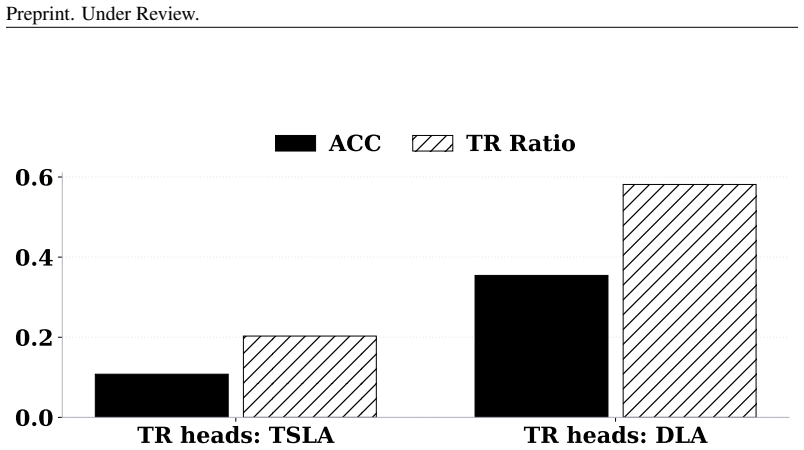
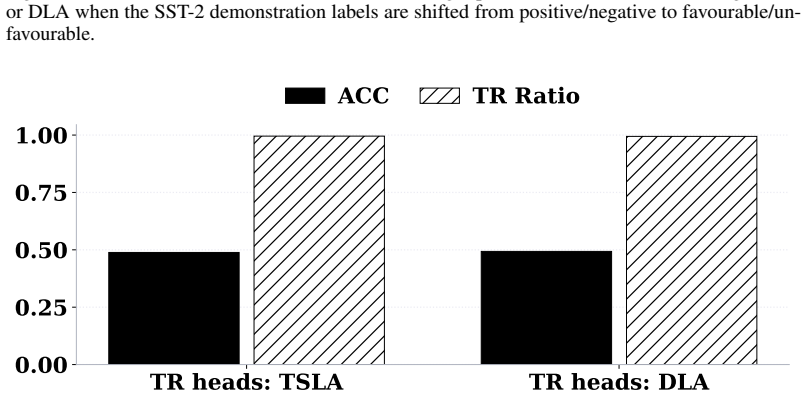
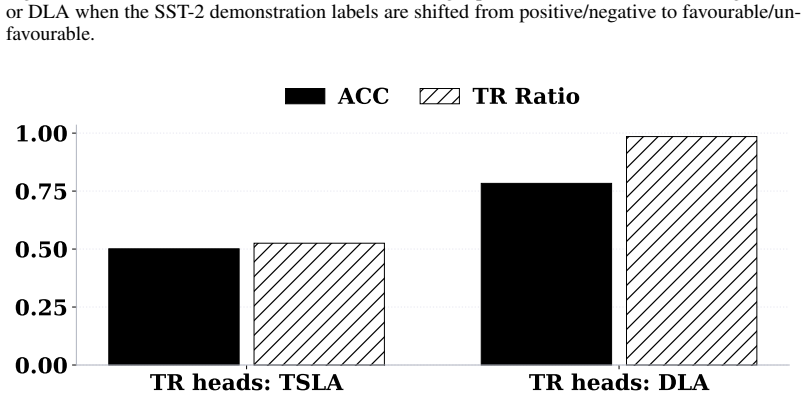





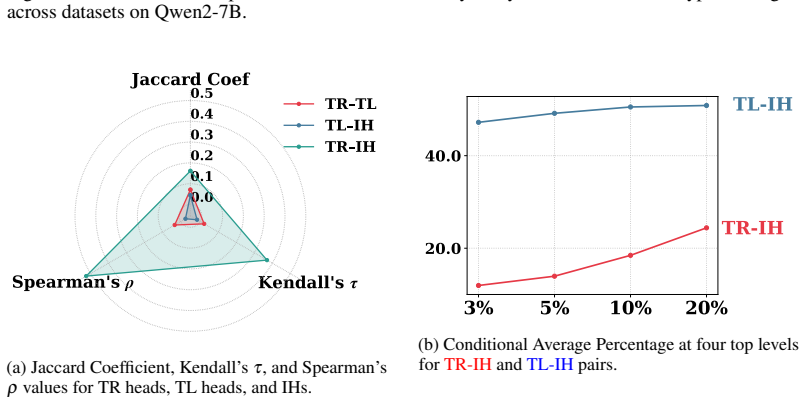







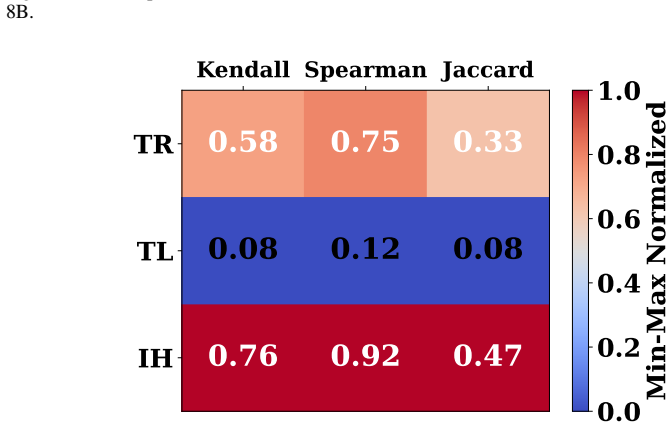


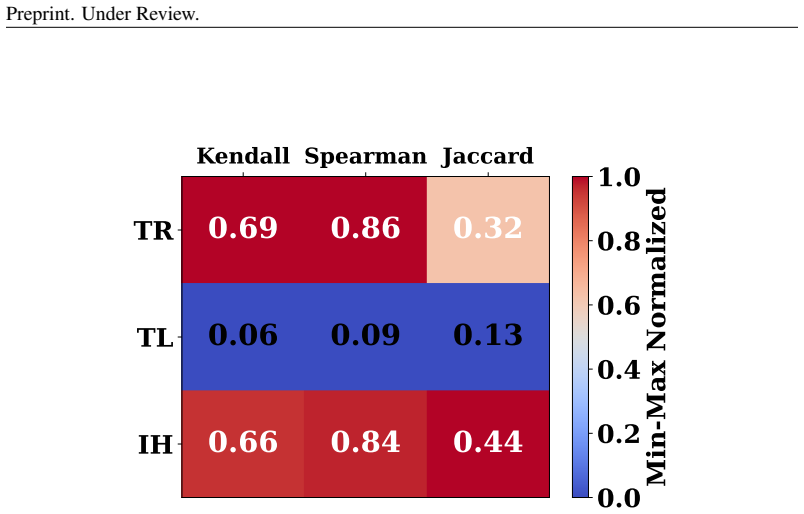
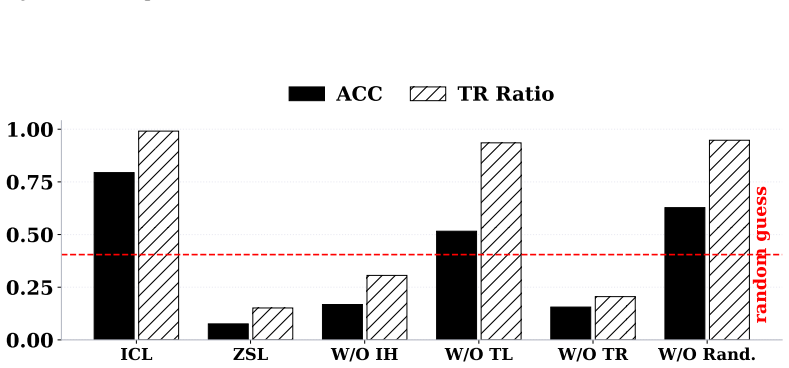

















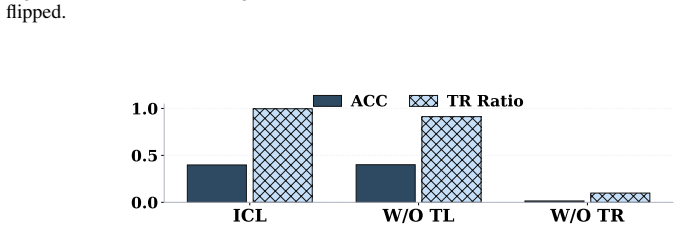


































read the original abstract
We investigate the mechanistic underpinnings of in-context learning (ICL) in large language models by reconciling two dominant perspectives: the component-level analysis of attention heads and the holistic decomposition of ICL into Task Recognition (TR) and Task Learning (TL). We propose a novel framework based on Task Subspace Logit Attribution (TSLA) to identify attention heads specialized in TR and TL, and demonstrate their distinct yet complementary roles. Through correlation analysis, ablation studies, and input perturbations, we show that the identified TR and TL heads independently and effectively capture the TR and TL components of ICL. Using steering experiments with geometric analysis of hidden states, we reveal that TR heads promote task recognition by aligning hidden states with the task subspace, while TL heads rotate hidden states within the subspace toward the correct label to facilitate prediction. We further show how previous findings on ICL mechanisms, including induction heads and task vectors, can be reconciled with our attention-head-level analysis of the TR-TL decomposition. Our framework thus provides a unified and interpretable account of how large language models execute ICL across diverse tasks and settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the mechanistic basis of in-context learning (ICL) by reconciling attention-head component analysis with the Task Recognition (TR) / Task Learning (TL) decomposition. It introduces Task Subspace Logit Attribution (TSLA) to identify specialized TR and TL heads, then uses correlation analysis, ablation, input perturbations, and steering experiments with geometric analysis of hidden states to argue that TR heads align representations to the task subspace while TL heads rotate them within the subspace toward the correct label. The work also reconciles these findings with prior results on induction heads and task vectors.
Significance. If the causal claims hold, the framework offers a unified, head-level account of ICL that bridges two previously separate lines of work and could improve mechanistic interpretability across diverse tasks. The geometric steering results and reconciliation with induction heads and task vectors would be particularly valuable contributions if supported by rigorous controls.
major comments (2)
- [Abstract and §3] Abstract and §3 (TSLA definition): the task subspace used for logit attribution is constructed from model activations that include the very heads under test. This creates a potential circularity risk in which TSLA surfaces heads whose activations co-vary with the subspace rather than causally producing the alignment or rotation. The ablation and steering experiments described in the abstract are consistent with either interpretation; an explicit test that the subspace is estimated from a held-out set of heads or layers is needed to establish causality.
- [§4.3] §4.3 (steering experiments): the geometric analysis claims TR heads promote alignment and TL heads promote rotation toward the correct label, yet no quantitative metrics (e.g., cosine similarity deltas, rotation angles with error bars, or comparison to random-head controls) are referenced in the abstract. Without these numbers it is difficult to judge whether the observed effects are large enough to support the central mechanistic claim.
minor comments (2)
- [Introduction] The abstract states that previous findings on induction heads and task vectors are reconciled, but the specific mapping (which heads correspond to which prior mechanism) is not previewed; a brief table or diagram in the introduction would improve readability.
- [Methods] Post-hoc head selection procedure is mentioned but not detailed in the abstract; the criteria for declaring a head “TR” versus “TL” (thresholds, statistical tests) should be stated explicitly in the methods.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas to strengthen the causal interpretation and quantitative rigor of our work. We address each point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (TSLA definition): the task subspace used for logit attribution is constructed from model activations that include the very heads under test. This creates a potential circularity risk in which TSLA surfaces heads whose activations co-vary with the subspace rather than causally producing the alignment or rotation. The ablation and steering experiments described in the abstract are consistent with either interpretation; an explicit test that the subspace is estimated from a held-out set of heads or layers is needed to establish causality.
Authors: We appreciate the referee's identification of this potential circularity. To mitigate this concern, we have re-estimated the task subspace using activations from held-out heads and layers, excluding those being evaluated by TSLA. The identified TR and TL heads remain consistent, and the ablation and steering results hold. We will include these additional controls and results in the revised manuscript to establish the causal nature of our findings. revision: yes
-
Referee: [§4.3] §4.3 (steering experiments): the geometric analysis claims TR heads promote alignment and TL heads promote rotation toward the correct label, yet no quantitative metrics (e.g., cosine similarity deltas, rotation angles with error bars, or comparison to random-head controls) are referenced in the abstract. Without these numbers it is difficult to judge whether the observed effects are large enough to support the central mechanistic claim.
Authors: We agree that explicit quantitative metrics would aid in evaluating the effect sizes. We will enhance the abstract and §4.3 with explicit quantitative metrics, including cosine similarity deltas, rotation angles with error bars, and comparisons to random-head controls. These additions will strengthen the support for our central mechanistic claims. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper defines TR/TL heads via TSLA logit attribution onto a task subspace estimated from activations, then validates the claimed alignment/rotation roles through separate correlation, ablation, steering, and geometric analyses. No equation or step reduces the identification or the causal claims to a fitted parameter or self-citation by construction; the subspace derivation and head selection are distinct from the intervention-based tests that support the mechanistic interpretation. The framework therefore does not collapse into its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A task subspace exists in the model's hidden-state geometry that can be used to separate recognition from learning components.
invented entities (1)
-
Task Subspace Logit Attribution (TSLA)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel framework based on Task Subspace Logit Attribution (TSLA) to identify attention heads specialized in TR and TL... TR heads promote task recognition by aligning hidden states with the task subspace, while TL heads rotate hidden states within the subspace toward the correct label
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1... projected norm onto span(W^Y_U)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
01. AI , Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, Kaidong Yu, Peng Liu, Qiang Liu, Shawn Yue, Senbin Yang, Shiming Yang, Tao Yu, Wen Xie, Wenhao Huang, Xiaohui Hu, Xiaoyi Ren, Xinyao Niu, Pengcheng Nie, Yuchi Xu, Yudong Liu, Yue Wang, Yuxuan Cai, Zhenyu Gu, Zhiyuan Liu, and Z...
work page 2024
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, et al. Language models are few-shot le...
-
[4]
Iteration head: A mechanistic study of chain-of-thought
Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Xingyu Yang, Francois Charton, and Julia Kempe. Iteration head: A mechanistic study of chain-of-thought. Advances in Neural Information Processing Systems, 37: 0 109101--109122, 2024
work page 2024
-
[5]
Revisiting in-context learning inference circuit in large language models
Hakaze Cho, Mariko Kato, Yoshihiro Sakai, and Naoya Inoue. Revisiting in-context learning inference circuit in large language models. In The Thirteenth International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=xizpnYNvQq
work page 2025
-
[6]
Token-based decision criteria are suboptimal in in-context learning
Hakaze Cho, Yoshihiro Sakai, Mariko Kato, Kenshiro Tanaka, Akira Ishii, and Naoya Inoue. Token-based decision criteria are suboptimal in in-context learning. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolog...
work page 2025
-
[7]
Summing up the facts: Additive mechanisms behind factual recall in llms
Bilal Chughtai, Alan Cooney, and Neel Nanda. Summing up the facts: Additive mechanisms behind factual recall in llms. arXiv preprint arXiv:2402.07321, 2024
-
[8]
Induction heads as an essential mechanism for pattern matching in in-context learning
Joy Crosbie and Ekaterina Shutova. Induction heads as an essential mechanism for pattern matching in in-context learning. arXiv preprint arXiv:2407.07011, 2024
-
[9]
The pascal recognising textual entailment challenge
Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Machine learning challenges workshop, pp.\ 177--190. Springer, 2005. URL https://link.springer.com/chapter/10.1007/11736790_9
-
[10]
The commitmentbank: Investigating projection in naturally occurring discourse
Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. The commitmentbank: Investigating projection in naturally occurring discourse. In proceedings of Sinn und Bedeutung, volume 23, pp.\ 107--124, 2019. URL https://ojs.ub.uni-konstanz.de/sub/index.php/sub/article/view/601
work page 2019
-
[11]
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. A survey on in-context learning, 2024. URL https://arxiv.org/abs/2301.00234
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 1 0 (1): 0 12, 2021. URL https://transformer-circuits.pub/2021/framework/index.html
work page 2021
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, and Abhinav Pandey et al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Overthinking the truth: Understanding how language models process false demonstrations, 2024
Danny Halawi, Jean-Stanislas Denain, and Jacob Steinhardt. Overthinking the truth: Understanding how language models process false demonstrations, 2024. URL https://arxiv.org/abs/2307.09476
-
[15]
In-context learning creates task vectors
Roee Hendel, Mor Geva, and Amir Globerson. In-context learning creates task vectors. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 9318--9333, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.findings-emnlp.624. URL https://aclanthol...
-
[16]
From compression to expansion: A layerwise analysis of in-context learning, 2025
Jiachen Jiang, Yuxin Dong, Jinxin Zhou, and Zhihui Zhu. From compression to expansion: A layerwise analysis of in-context learning, 2025. URL https://arxiv.org/abs/2505.17322
-
[17]
Zhuoran Jin, Pengfei Cao, Hongbang Yuan, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao. Cutting off the head ends the conflict: A mechanism for interpreting and mitigating knowledge conflicts in language models, 2024. URL https://arxiv.org/abs/2402.18154
-
[18]
The atlas of in-context learning: How attention heads shape in-context retrieval augmentation
Patrick Kahardipraja, Reduan Achtibat, Thomas Wiegand, Wojciech Samek, and Sebastian Lapuschkin. The atlas of in-context learning: How attention heads shape in-context retrieval augmentation. arXiv preprint arXiv:2505.15807, 2025
-
[19]
The geometry of prompting: Unveiling distinct mechanisms of task adaptation in language models
Artem Kirsanov, Chi-Ning Chou, Kyunghyun Cho, and SueYeon Chung. The geometry of prompting: Unveiling distinct mechanisms of task adaptation in language models. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Findings of the Association for Computational Linguistics: NAACL 2025, pp.\ 1855--1888, Albuquerque, New Mexico, April 2025. Association for Comp...
work page 2025
-
[20]
In-context learning state vector with inner and momentum optimization, 2024
Dongfang Li, Zhenyu Liu, Xinshuo Hu, Zetian Sun, Baotian Hu, and Min Zhang. In-context learning state vector with inner and momentum optimization, 2024. URL https://arxiv.org/abs/2404.11225
-
[21]
Xin Li and Dan Roth. Learning question classifiers. In COLING 2002: The 19th International Conference on Computational Linguistics , 2002. URL https://www.aclweb.org/anthology/C02-1150
work page 2002
-
[22]
Tom Lieberum, Matthew Rahtz, János Kramár, Neel Nanda, Geoffrey Irving, Rohin Shah, and Vladimir Mikulik. Does circuit analysis interpretability scale? evidence from multiple choice capabilities in chinchilla, 2023. URL https://arxiv.org/abs/2307.09458
-
[23]
Sheng Liu, Haotian Ye, Lei Xing, and James Zou. In-context vectors: Making in context learning more effective and controllable through latent space steering, 2024. URL https://arxiv.org/abs/2311.06668
-
[24]
Bill MacCartney and Christopher D. Manning. Modeling semantic containment and exclusion in natural language inference. In Donia Scott and Hans Uszkoreit (eds.), Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008), pp.\ 521--528, Manchester, UK, August 2008. Coling 2008 Organizing Committee. URL https://aclanthology....
work page 2008
-
[25]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets, 2024. URL https://arxiv.org/abs/2310.06824
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Language models implement simple word2vec-style vector arithmetic, 2024
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Language models implement simple word2vec-style vector arithmetic, 2024. URL https://arxiv.org/abs/2305.16130
-
[27]
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? arXiv preprint arXiv:2202.12837, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, et al. Gpt-4 technical report, 2024. URL https://arxiv.org/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
What in-context learning learns in-context: Disentangling task recognition and task learning
Jane Pan, Tianyu Gao, Howard Chen, and Danqi Chen. What in-context learning learns in-context: Disentangling task recognition and task learning. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, pp.\ 8298--8319, Toronto, Canada, July 2023. Association for Computational Lingu...
-
[31]
Bo Pang and Lillian Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. arXiv preprint cs/0506075, 2005
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[32]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI blog, 2019. URL https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
work page 2019
-
[34]
Identifying semantic induction heads to understand in-context learning, 2024 b
Jie Ren, Qipeng Guo, Hang Yan, Dongrui Liu, Quanshi Zhang, Xipeng Qiu, and Dahua Lin. Identifying semantic induction heads to understand in-context learning, 2024 b . URL https://arxiv.org/abs/2402.13055
-
[35]
Large language models encode semantics in low-dimensional linear subspaces, 2025
Baturay Saglam, Paul Kassianik, Blaine Nelson, Sajana Weerawardhena, Yaron Singer, and Amin Karbasi. Large language models encode semantics in low-dimensional linear subspaces, 2025. URL https://arxiv.org/abs/2507.09709
-
[36]
Aaditya K Singh, Ted Moskovitz, Felix Hill, Stephanie CY Chan, and Andrew M Saxe. What needs to go right for an induction head? a mechanistic study of in-context learning circuits and their formation. In Forty-first International Conference on Machine Learning, 2024. URL https://arxiv.org/abs/2404.07129
-
[37]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and Steven Bethard (eds.), Proceedings of the 2013 Conference on Empirical Methods in Natural Langu...
work page 2013
-
[38]
Out-of-distribution generalization via composition: a lens through induction heads in transformers
Jiajun Song, Zhuoyan Xu, and Yiqiao Zhong. Out-of-distribution generalization via composition: a lens through induction heads in transformers. Proceedings of the National Academy of Sciences, 122 0 (6): 0 e2417182122, 2025. URL https://arxiv.org/abs/2408.09503
-
[39]
Interpret and improve in-context learning via the lens of input-label mappings
Chenghao Sun, Zhen Huang, Yonggang Zhang, Le Lu, Houqiang Li, Xinmei Tian, Xu Shen, and Jieping Ye. Interpret and improve in-context learning via the lens of input-label mappings. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 3873--3895, 2025
work page 2025
-
[40]
Black-box tuning for language-model-as-a-service
JTianxiang Sun, Yunfan Shao, Hong Qian, Xuanjing Huang, and Xipeng Qiu. Black-box tuning for language-model-as-a-service. In Proceedings of the 39th International Conference on Machine Learning, pp.\ 20841--20855, Baltimore, Maryland, USA, 2022. ACM. URL https://proceedings.mlr.press/v162/sun22e/sun22e.pdf
work page 2022
-
[41]
Function vectors in large language models
Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. Function vectors in large language models, 2024. URL https://arxiv.org/abs/2310.15213
-
[42]
Baselines and bigrams: Simple, good sentiment and topic classification
Sida Wang and Christopher Manning. Baselines and bigrams: Simple, good sentiment and topic classification. In Haizhou Li, Chin-Yew Lin, Miles Osborne, Gary Geunbae Lee, and Jong C. Park (eds.), Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 90--94, Jeju Island, Korea, July 2012. Assoc...
work page 2012
-
[43]
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. Larger language models do in-context learning differently, 2023. URL https://arxiv.org/abs/2303.03846
-
[44]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Unifying attention heads and task vectors via hidden state geometry in in-context learning, 2025
Haolin Yang, Hakaze Cho, Yiqiao Zhong, and Naoya Inoue. Unifying attention heads and task vectors via hidden state geometry in in-context learning, 2025. URL https://arxiv.org/abs/2505.18752
-
[46]
Which attention heads matter for in-context learning? arXiv preprint arXiv:2502.14010, 2025
Kayo Yin and Jacob Steinhardt. Which attention heads matter for in-context learning? arXiv preprint arXiv:2502.14010, 2025
-
[47]
Zeping Yu and Sophia Ananiadou. How do large language models learn in-context? query and key matrices of in-context heads are two towers for metric learning. arXiv preprint arXiv:2402.02872, 2024
-
[48]
Beyond single concept vector: Modeling concept subspace in llms with gaussian distribution, 2025
Haiyan Zhao, Heng Zhao, Bo Shen, Ali Payani, Fan Yang, and Mengnan Du. Beyond single concept vector: Modeling concept subspace in llms with gaussian distribution, 2025. URL https://arxiv.org/abs/2410.00153
-
[49]
Attention heads of large language models: A survey
Zifan Zheng, Yezhaohui Wang, Yuxin Huang, Shichao Song, Mingchuan Yang, Bo Tang, Feiyu Xiong, and Zhiyu Li. Attention heads of large language models: A survey. arXiv preprint arXiv:2409.03752, 2024
-
[50]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[51]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[52]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.