Interactive Program Synthesis for Modeling Collaborative Physical Activities from Narrated Demonstrations
Pith reviewed 2026-05-18 13:24 UTC · model grok-4.3
The pith
Collaborative physical tasks like soccer tactics can be taught to AI systems as editable programs using only narrated physical demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
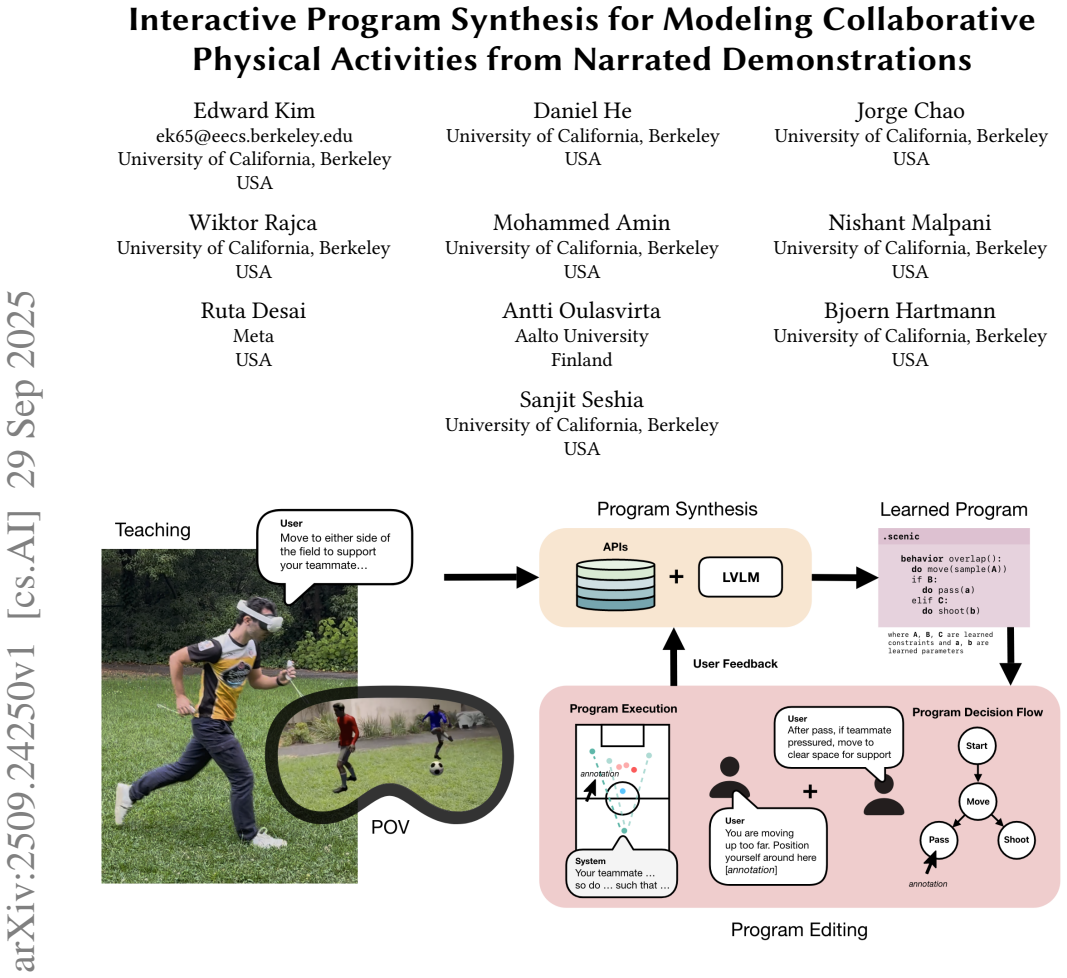
Framing collaborative task learning as program synthesis yields editable programs that represent behavior from narrated demonstrations, allowing users to teach, inspect, and correct system logic in the same natural modality of physical actions paired with language, without requiring code.
What carries the argument
Narrated demonstrations as a unified input and output modality that drives program synthesis to produce editable representations of collaborative physical behavior.
If this is right
- Users without programming skills can still inspect and refine the system's model of collaborative intent.
- The system communicates its current understanding back to users through the same narrated-demonstration format.
- Representing behavior as programs makes dynamic teammate assumptions explicit and revisable.
- The approach surfaces specific representation challenges when modeling collaborative physical activities.
Where Pith is reading between the lines
- The same synthesis method might apply to other team-based physical tasks such as assembly lines or emergency response drills.
- Integrating richer language understanding could reduce the number of correction cycles needed for complex intents.
- Program representations could be combined with simulation environments to let users test collaborative scenarios before real-world deployment.
Load-bearing premise
Narrated demonstrations supply enough information for the synthesis process to recover ambiguous and dynamic teammate intents in a form that remains accurate and directly correctable by the same natural actions and language.
What would settle it
A follow-up study in which users supply narrated demonstrations for a new collaborative task yet cannot refine the output programs to match their actual intent after repeated correction attempts using the same modality.
Figures









read the original abstract
Teaching systems physical tasks is a long standing goal in HCI, yet most prior work has focused on non collaborative physical activities. Collaborative tasks introduce added complexity, requiring systems to infer users assumptions about their teammates intent, which is an inherently ambiguous and dynamic process. This necessitates representations that are interpretable and correctable, enabling users to inspect and refine system behavior. We address this challenge by framing collaborative task learning as a program synthesis problem. Our system represents behavior as editable programs and uses narrated demonstrations, i.e. paired physical actions and natural language, as a unified modality for teaching, inspecting, and correcting system logic without requiring users to see or write code. The same modality is used for the system to communicate its learning to users. In a within subjects study, 20 users taught multiplayer soccer tactics to our system. 70 percent (14/20) of participants successfully refined learned programs to match their intent and 90 percent (18/20) found it easy to correct the programs. The study surfaced unique challenges in representing learning as programs and in enabling users to teach collaborative physical activities. We discuss these issues and outline mitigation strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames collaborative physical task learning as a program synthesis problem, representing behaviors as editable programs learned from narrated demonstrations that pair physical actions with natural language. This unified modality supports teaching, inspecting, and correcting system logic without requiring users to view or write code. A within-subjects study with 20 participants teaching multiplayer soccer tactics reports that 70% (14/20) successfully refined the learned programs to match their intent and 90% (18/20) found correction easy, while surfacing challenges in program-based representation of collaborative activities.
Significance. If the results hold, the work advances HCI and interactive AI by addressing the added complexity of collaborative tasks, where teammate intents are ambiguous and dynamic, through interpretable and correctable program representations. The quantitative user-study outcomes (clear success and ease metrics) directly support the central claim of effective teaching and correction via narrated demonstrations. Credit is due for the empirical system-building approach with reproducible study protocol elements and discussion of mitigation strategies for identified challenges.
major comments (1)
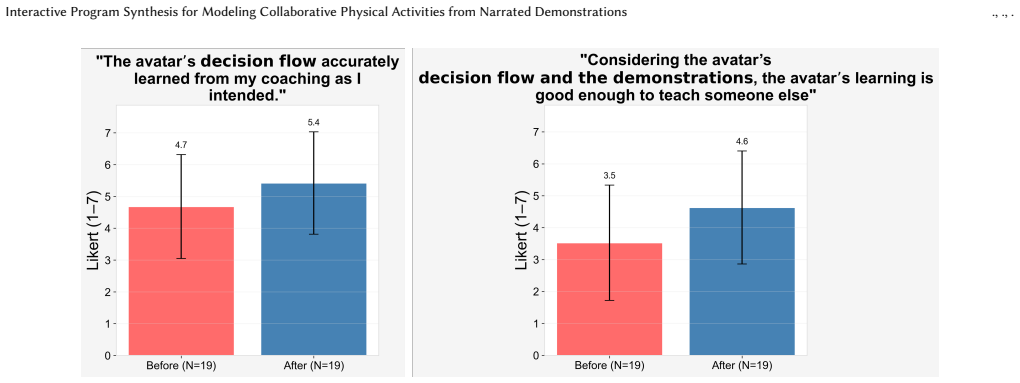
- [User study / evaluation] The user study reports that 14/20 participants 'successfully refined' programs 'to match their intent' and 18/20 found correction easy, but provides no objective success criterion (e.g., behavioral equivalence to held-out demonstration segments, expert rating of intent fidelity, or inter-rater agreement on whether the final program reproduces the narrated collaboration). This is load-bearing for interpreting the 70% figure as evidence of faithful recovery of ambiguous teammate intents rather than interface usability or user acceptance of any working program.
minor comments (1)
- [Abstract] The abstract notes that the study 'surfaced unique challenges in representing learning as programs' but does not enumerate them; a brief listing would improve clarity on the contributions.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which highlights important considerations for interpreting our user study results. We address the major comment below and will revise the manuscript to improve clarity on the evaluation criteria while preserving the integrity of the reported findings.
read point-by-point responses
-
Referee: [User study / evaluation] The user study reports that 14/20 participants 'successfully refined' programs 'to match their intent' and 18/20 found correction easy, but provides no objective success criterion (e.g., behavioral equivalence to held-out demonstration segments, expert rating of intent fidelity, or inter-rater agreement on whether the final program reproduces the narrated collaboration). This is load-bearing for interpreting the 70% figure as evidence of faithful recovery of ambiguous teammate intents rather than interface usability or user acceptance of any working program.
Authors: We appreciate this observation on the need for explicit success criteria. In the study, 'successful refinement to match their intent' was determined through a combination of direct observation and participant confirmation: after using the natural language correction interface, participants executed the updated program in the simulation and verbally verified that the collaborative behaviors (e.g., teammate positioning and actions in the soccer scenario) aligned with their original narrated demonstration. Experimenters logged these confirmations and noted cases where the final program produced the intended multi-agent interactions without further changes. The 90% ease rating was collected via post-task Likert-scale questionnaires. While this approach is grounded in the interactive, user-driven nature of the system and is common in HCI evaluations of teachable agents, we acknowledge that it does not include independent expert ratings or quantitative behavioral equivalence metrics against held-out segments. We will revise the manuscript to explicitly describe this operationalization of success, including the verification protocol and any logged alignment checks, and will add a limitations section discussing the value of future objective measures such as inter-rater agreement on program fidelity. revision: yes
Circularity Check
No circularity: empirical user study with independent results
full rationale
The paper frames collaborative task learning as a program synthesis problem and evaluates it via a within-subjects user study with 20 participants teaching multiplayer soccer tactics. Reported outcomes (70% successful refinement, 90% found correction easy) are direct counts from participant feedback and do not reduce to any fitted parameters, self-referential equations, or prior self-citations. No derivation chain, uniqueness theorems, or ansatzes appear; the work is self-contained system-building whose central claims rest on observable study metrics rather than definitional or fitted inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Narrated demonstrations contain sufficient signal to disambiguate teammate intent for program synthesis
invented entities (1)
-
editable program representation of collaborative behavior
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tyler Angert, Miroslav Ivan Suzara, Jenny Han, Christopher Lawrence Pondoc, and Hariharan Subramonyam. 2023. Spellburst: A Node-based Interface for Exploratory Creative Coding with Natural Language Prompts. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (San Francisco, CA, USA)(UIST ’23). Association for Computing...
-
[2]
Stavros Antifakos, Florian Michahelles, and Bernt Schiele. 2002. Proactive Instruc- tions for Furniture Assembly. InUbiquitous Computing (UbiComp 2002) (LNCS, Vol. 2498). Springer, Göteborg, Sweden, 351–360. doi:10.1007/3-540-45809-3_27
-
[3]
Baker, Julian Jara-Ettinger, Rebecca Saxe, and Joshua B
Chris L. Baker, Julian Jara-Ettinger, Rebecca Saxe, and Joshua B. Tenenbaum
-
[4]
Rational quantitative attribution of beliefs, desires and percepts in human mentalizing.Nature Human Behaviour1 (March 2017), 0064. doi:10.1038/s41562- 017-0064
-
[5]
Yonatan Bisk, Ari Holtzman, Jesse Thomason, Jacob Andreas, Yoshua Bengio, Joyce Chai, Mirella Lapata, Angeliki Lazaridou, Jonathan May, Aleksandr Nis- nevich, Nicolas Pinto, and Joseph Turian. 2020. Experience Grounds Language. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Pro- cessing (EMNLP). Association for Computationa...
work page 2020
-
[6]
Rao, Manav Wadhawan, Ke Huo, and Karthik Ramani
Yuanzhi Cao, Tianyi Wang, Xun Qian, Pawan S. Rao, Manav Wadhawan, Ke Huo, and Karthik Ramani. 2019. GhostAR: A Time-space Editor for Embodied Authoring of Human-Robot Collaborative Task with Augmented Reality. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology (UIST ’19). Association for Computing Machinery, New Orle...
-
[7]
Chasins, Maria Mueller, and Rastislav Bodík
Sarah E. Chasins, Maria Mueller, and Rastislav Bodík. 2018. Rousillon: Scrap- ing Distributed Hierarchical Web Data. InProceedings of the 31st Annual ACM Symposium on User Interface Software and Technology (UIST ’18). ACM, Berlin, Germany, 963–975. doi:10.1145/3242587.3242661
-
[8]
Weihao Chen, Xiaoyu Liu, Jiacheng Zhang, Ian Iong Lam, Zhicheng Huang, Rui Dong, Xinyu Wang, and Tianyi Zhang. 2023. MIWA: Mixed-Initiative Web Automation for Better User Control and Confidence. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). ACM, San Francisco, CA, USA, Article 75, 15 pages. doi:10.114...
-
[9]
Morariu, Anh Truong, and Zhicheng Liu
Yuexi Chen, Vlad I. Morariu, Anh Truong, and Zhicheng Liu. 2024. TutoAI: A Cross-domain Framework for AI-assisted Mixed-media Tutorial Creation on Physical Tasks. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, Honolulu, HI, USA, Article 161, 17 pages. doi:10.1145/3613904.3642443
-
[10]
Liqi Cheng, Hanze Jia, Lingyun Yu, Yihong Wu, Shuainan Ye, Dazhen Deng, Hui Zhang, Xiao Xie, and Yingcai Wu. 2024. VisCourt: In-Situ Guidance for Interactive Tactic Training in Mixed Reality. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). Association for Computing Machinery, Pittsburgh, PA, USA, Articl...
-
[11]
1993.Watch What I Do: Programming by Demonstration
Allen Cypher (Ed.). 1993.Watch What I Do: Programming by Demonstration. MIT Press, Cambridge, MA
work page 1993
-
[12]
Guo, Robert DeLine, and Sumit Gulwani
Ian Drosos, Titus Barik, Philip J. Guo, Robert DeLine, and Sumit Gulwani. 2020. Wrex: A Unified Programming-by-Example Interaction for Synthesizing Readable Code for Data Scientists. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20). ACM, Honolulu, HI, USA, 12 pages. doi:10.1145/3313831.3376442
-
[13]
England Football Learning. 2025.Sessions. The Football Association. https: //learn.englandfootball.com/sessions Library of football training drills and session plans by The FA
work page 2025
-
[14]
Steven Feiner, Blair MacIntyre, and Dorée D. Seligmann. 1993. Knowledge-Based Augmented Reality.Commun. ACM36, 7 (1993), 53–62. doi:10.1145/159544.159587
-
[15]
Fremont, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L
Daniel J. Fremont, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L. Sangiovanni-Vincentelli, and Sanjit A. Seshia. 2019. Scenic: A Language for Scenario Specification and Scene Generation. InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). ACM, New York, NY, USA, 63–78. doi:10.1145/3314221.3314633
-
[16]
Fremont, Edward Kim, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L
Daniel J. Fremont, Edward Kim, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L. Sangiovanni-Vincentelli, and Sanjit A. Seshia. 2023. Scenic: A Language for Scenario Specification and Data Generation.Machine Learning112, 10 (2023), 3805–3849
work page 2023
-
[17]
Sumit Gulwani. 2011. Automating String Processing in Spreadsheets Using Input- Output Examples. InProceedings of the 38th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL ’11). Association for Computing Machinery, Austin, TX, USA, 317–330. doi:10.1145/1926385.1926423
-
[18]
Stevan Harnad. 1990. The Symbol Grounding Problem.Physica D: Nonlinear Phenomena42, 1-3 (1990), 335–346. doi:10.1016/0167-2789(90)90087-6
-
[19]
Gaoping Huang, Xun Qian, Tianyi Wang, Fagun Patel, Maitreya Sreeram, Yuanzhi Cao, Karthik Ramani, and Alexander J. Quinn. 2021. AdapTutAR: An Adaptive Tutoring System for Machine Tasks in Augmented Reality. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. ACM, Yokohama, Japan, 15 pages. doi:10.1145/3411764.3445283
-
[20]
Ellen Jiang, Edwin Toh, Alejandra Molina, Kristen Olson, Claire Kayacik, Aaron Donsbach, Carrie J. Cai, and Michael Terry. 2022. Discovering the Syntax and Strategies of Natural Language Programming with Generative Language Models. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems (New Orleans, LA, USA)(CHI ’22). Association f...
-
[21]
Hen- ley, Carina Negreanu, and Advait Sarkar
Majeed Kazemitabaar, Jack Williams, Ian Drosos, Tovi Grossman, Austin Z. Hen- ley, Carina Negreanu, and Advait Sarkar. 2024. Improving Steering and Veri- fication in AI-Assisted Data Analysis with Interactive Task Decomposition. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Associ...
-
[22]
Bigham, Amy Pavel, and Anhong Guo
Junhan Kong, Dena Sabha, Jeffrey P. Bigham, Amy Pavel, and Anhong Guo
-
[23]
InProceedings of the 2021 ACM Symposium on Spatial User Interaction (SUI ’21)
TutorialLens: Authoring Interactive Augmented Reality Tutorials Through Narration and Demonstration. InProceedings of the 2021 ACM Symposium on Spatial User Interaction (SUI ’21). ACM, New York, NY, USA, 11 pages. doi:10. 1145/3485279.3485289
-
[24]
Balasaravanan Thoravi Kumaravel, Cuong Nguyen, Stephen DiVerdi, and Björn Hartmann. 2019. TutoriVR: A Video-Based Tutorial System for Design Appli- cations in Virtual Reality. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI ’19). Association for Computing Machinery, Glasgow, UK, 12 pages. doi:10.1145/3290605.3300514
-
[25]
Laird, Kevin Gluck, John Anderson, Kenneth D
John E. Laird, Kevin Gluck, John Anderson, Kenneth D. Forbus, Odest Chadwicke Jenkins, Christian Lebiere, Dario Salvucci, Matthias Scheutz, Andrea Thomaz, Greg Trafton, Robert E. Wray, Shiwali Mohan, and James R. Kirk. 2017. Interactive Task Learning.IEEE Intelligent Systems32, 4 (2017), 6–21. doi:10.1109/MIS.2017. 3121552
-
[26]
Lane Lawley and Christopher J. MacLellan. 2024. VAL: Interactive Task Learning with GPT Dialog Parsing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 18 pages. doi:10.1145/3613904.3641915
-
[27]
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yi Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. 2022. Grounded language-image pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, Piscataway, NJ, USA, 10965– 10975
work page 2022
-
[28]
Toby Jia-Jun Li, Amos Azaria, and Brad A. Myers. 2017. SUGILITE: Creating Multimodal Smartphone Automation by Demonstration. InProceedings of the 2017 CHI Conference on Human Factors in Computing Systems (CHI ’17). ACM, Denver, CO, USA, 6038–6049. doi:10.1145/3025453.3025483
-
[29]
Toby Jia-Jun Li, Marissa Radensky, Justin Jia, Kirielle Singarajah, Tom M. Mitchell, and Brad A. Myers. 2019. PUMICE: A Multi-Modal Agent that Learns Concepts and Conditionals from Natural Language and Demonstrations. InProceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology (UIST Interactive Program Synthesis for Modeling C...
-
[30]
Wang, Dominik Moritz, Mary Beth Kery, and Fred Hohman
Michael Xieyang Liu, Advait Sarkar, Carina Negreanu, Benjamin Zorn, Jack Williams, Neil Toronto, and Andrew D. Gordon. 2023. “What It Wants Me To Say”: Bridging the Abstraction Gap Between End-User Programmers and Code- Generating Large Language Models. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’2...
-
[31]
Ziyi Liu, Zhengzhe Zhu, Enze Jiang, Feichi Huang, Ana Villanueva, Tianyi Wang, Xun Qian, and Karthik Ramani. 2023. InstruMentAR: Auto-Generation of Augmented Reality Tutorials for Operating Digital Instruments Through Recording Embodied Demonstration. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. ACM, Hamburg, Germany, 17...
-
[32]
Mikaël Mayer, Gustavo Soares, Maxim Grechkin, Vu Le, Mark Marron, Oleksandr Polozov, Rishabh Singh, Benjamin Zorn, and Sumit Gulwani. 2015. User Inter- action Models for Disambiguation in Programming by Example. InProceedings of the 28th Annual ACM Symposium on User Interface Software and Technology. ACM, x, 291–301. doi:10.1145/2807442.2807459
-
[33]
David Premack and Guy Woodruff. 1978. Does the chimpanzee have a the- ory of mind?Behavioral and Brain Sciences1, 4 (1978), 515–526. doi:10.1017/ S0140525X00076512
work page 1978
-
[34]
Kevin Pu, Jim Yang, Angel Yuan, Minyi Ma, Rui Dong, Xinyu Wang, Yan Chen, and Tovi Grossman. 2023. DiLogics: Creating Web Automation Programs with Diverse Logics. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). ACM, San Francisco, CA, USA, Article 74, 15 pages. doi:10.1145/3586183.3606822
-
[35]
Neil C. Rabinowitz, Frank Perbet, H. Francis Song, Chiyuan Zhang, S. M. Ali Eslami, and Matthew Botvinick. 2018. Machine Theory of Mind. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80), Jennifer Dy and Andreas Krause (Eds.). PMLR, New York, NY, USA, 4218–4227. https://proceedings.m...
work page 2018
-
[36]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InProceedings of the International Conference on Machine Learning. PMLR, PMLR, New York, NY, USA, 8748–8763
work page 2021
-
[37]
Marcel Ruoff, Brad A. Myers, and Alexander Maedche. 2023. ONYX: Assisting Users in Teaching Natural Language Interfaces Through Multi-Modal Interactive Task Learning. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, Hamburg, Germany, Article 417, 16 pages. doi:10.1145/3544548.3580964
-
[38]
Kummerfeld, Toby Jia-Jun Li, and Tianyi Zhang
Yuan Tian, Jonathan K. Kummerfeld, Toby Jia-Jun Li, and Tianyi Zhang. 2024. SQLucid: Grounding Natural Language Database Queries with Interactive Ex- planations. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. ACM, New York, NY, USA, 20 pages. doi:10.1145/ 3654777.3676368
-
[39]
Anh Truong, Peggy Chi, David Salesin, Irfan Essa, and Maneesh Agrawala. 2021. Automatic Generation of Two-Level Hierarchical Tutorials from Instructional Makeup Videos. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, Yokohama, Japan, Article 108, 16 pages. doi:10.1145/3411764.3445721
-
[40]
Harley, Liang-Kang Huang, and Katerina Fragkiadaki
Hsiao-Yu Tung, Adam W. Harley, Liang-Kang Huang, and Katerina Fragkiadaki
-
[41]
InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Reward Learning from Narrated Demonstrations. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Piscataway, NJ, USA, 7004–7013. https://openaccess.thecvf.com/content_cvpr_2018/papers/ Tung_Reward_Learning_From_CVPR_2018_paper.pdf
-
[42]
Chenglong Wang, Yu Feng, Rastislav Bodík, Isil Dillig, Alvin Cheung, and Amy J. Ko. 2021. Falx: Synthesis-Powered Visualization Authoring. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). ACM, Yokohama, Japan, 15 pages. doi:10.1145/3411764.3445249
-
[43]
Barton, Vernon Lawhern, and Garrett Warnell
Nicholas Waytowich, Sean L. Barton, Vernon Lawhern, and Garrett Warnell
-
[44]
InProceedings of the 36th International Conference on Machine Learning (ICML)
A Narration-based Reward Shaping Approach Using Grounded Natural Language Commands. InProceedings of the 36th International Conference on Machine Learning (ICML). PMLR, New York, NY, USA, 13 pages. https://arxiv. org/abs/1911.00497
-
[45]
Robert F. Woolson. 2007. Wilcoxon Signed-Rank Test. InWiley Encyclopedia of Clinical Trials, Ralph B. D’Agostino, Lisa M. Sullivan, and Joseph M. Massaro (Eds.). John Wiley & Sons, Inc., Hoboken, NJ. doi:10.1002/9780471462422.eoct979
-
[46]
Liwenhan Xie, Chengbo Zheng, Haijun Xia, Huamin Qu, and Chen Zhu-Tian
-
[47]
WaitGPT: Monitoring and Steering Conversational LLM Agent in Data Analysis with On-the-Fly Code Visualization. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA) (UIST ’24). Association for Computing Machinery, New York, NY, USA, 14 pages. doi:10.1145/3654777.3676374
-
[48]
Masahiro Yamaguchi, Shohei Mori, Peter Mohr, Markus Tatzgern, Ana Stanescu, Hideo Saito, and Denis Kalkofen. 2020. Video-Annotated Augmented Reality Assembly Tutorials. InProceedings of the 33rd Annual ACM Symposium on User In- terface Software and Technology (UIST ’20). Association for Computing Machinery, Virtual Event, USA, 13 pages. doi:10.1145/337933...
-
[49]
Ryan Yen, Jiawen Stefanie Zhu, Sangho Suh, Haijun Xia, and Jian Zhao. 2024. CoLadder: Manipulating Code Generation via Multi-Level Blocks. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (Pittsburgh, PA, USA)(UIST ’24). Association for Computing Machinery, New York, NY, USA, 20 pages. doi:10.1145/3654777.3676357
-
[50]
Albert Yu and Raymond J. Mooney. 2023. Using Both Demonstrations and Lan- guage Instructions to Efficiently Learn Robotic Tasks. InInternational Conference on Learning Representations (ICLR). x, x, 24 pages. doi:10.48550/arXiv.2210.04476
-
[51]
Lu Yuan, Dong Chen, Yi-Lin Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xinying Huang, Bing Li, Chunyuan Li, et al. 2021. Florence: A new foundation model for computer vision.arXiv preprint arXiv:2111.11432xx, xx (2021), 17 pages
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[52]
Tianyi Zhang, London Lowmanstone, Xinyu Wang, and Elena L. Glassman. 2020. Interactive Program Synthesis by Augmented Examples. InProceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology (UIST ’20). ACM, Virtual Event, USA, 627–648. doi:10.1145/3379337.3415900
-
[53]
the worker’s bucket is running low on assembly parts. Fetch another bucket from the supply station
Ada Yi Zhao, Aditya Gunturu, Ellen Yi-Luen Do, and Ryo Suzuki. 2025. Guided Reality: Generating Visually-Enriched AR Task Guidance with LLMs and Vision Models. arXiv:2508.03547. UIST 2025 (to appear). A User Study Supplement A.1 Tutorial Video Here is the link to the tutorial video that all participants watched at the beginning of the study. This video co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.